Chaîne principale
En chimie macromoléculaire, la chaîne principale d'un polymère est la plus longue série d'atomes liés par covalence qui, ensemble, créent la chaîne continue de la molécule. Cette science est divisée en deux parties : l'étude des polymères organiques, qui se composent uniquement d'un squelette carboné, et celle des polymères inorganiques dont les squelettes ne contiennent que des éléments du groupe principal.
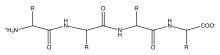
Définition UICPA : chaîne principale ou squelette. Cette chaîne linéaire à laquelle toutes les autres chaînes, longues ou courtes, ou les deux, peuvent être considérées comme étant pendantes.
Remarque : là où deux chaînes ou plus peuvent également être considérées comme la chaîne principale, celle-ci est sélectionnée, ce qui conduit à la représentation la plus simple de la molécule.En biochimie, les chaînes de squelette organiques constituent la structure primaire des macromolécules. Les squelettes de ces macromolécules biologiques sont constitués de chaînes centrales d'atomes qui sont liés de manière covalente. Les caractéristiques et l'ordre des résidus des monomères dans le squelette permettent de faire une carte de la structure complexe des polymères biologiques (voir structure biomoléculaire). Le squelette est donc directement lié à la fonction des molécules biologiques. Les macromolécules présentes dans le corps peuvent être divisées en quatre sous-catégories principales, chacune étant impliquée dans des processus biologiques très différents mais néanmoins importants : les protéines, les glucides, les lipides et les acides nucléiques[1]. Chacune de ces molécules a un squelette différent et se compose de différents monomères, chacun avec des résidus et des fonctions distinctes. C'est le facteur déterminant de leurs différentes structures et fonctions dans le corps. Bien que les lipides aient un « squelette », ils ne sont pas de vrais polymères biologiques car leur squelette n'est qu'une seule molécule à trois carbones, le glycérol, avec des « chaînes latérales » substituantes plus longues. Pour cette raison, seuls les protéines, les glucides et les acides nucléiques doivent être considérés comme des macromolécules biologiques à squelette polymérique[2].
Caractéristiques
Chimie des polymères
Le caractère de la chaîne de squelette dépend du type de polymérisation : dans la polymérisation par croissance par étapes, le fragment du monomère devient le squelette, et ainsi le squelette est typiquement fonctionnel. Il s'agit notamment des polythiophènes ou des polymères à faible bande interdite dans les semi-conducteurs organiques[3]. Dans la polymérisation par croissance de chaîne, généralement appliquée pour les alcènes, le squelette n'est pas fonctionnel, mais porte des chaînes latérales fonctionnelles ou des groupes pendants.
Le caractère du squelette, c'est-à-dire sa flexibilité, détermine les propriétés thermiques du polymère (comme la température de transition vitreuse). Par exemple, dans les polysiloxanes (silicone), la chaîne principale est très flexible, ce qui se traduit par une température de transition vitreuse très basse de −123 °C[4]. Les polymères à squelettes rigides sont sujets à la cristallisation (par exemple les polythiophènes) en couches minces et en solution. La cristallisation à son tour affecte les propriétés optiques des polymères, sa bande interdite optique et les niveaux électroniques[5].
Biochimie
Il existe certaines similitudes mais aussi de nombreuses différences intrinsèque au caractère des squelettes biopolymères. Le squelette des trois différents polymères biologiques : les protéines, les glucides et les acides nucléiques sont formés par une réaction de condensation. Dans cette dernière, les unités monomères sont liées de manière covalente avec la perte d'une petite molécule, le plus souvent de l'eau[6]. Parce qu'ils sont polymérisés par des mécanismes enzymatiques complexes, aucun des squelettes des biopolymères n'est formé par l'élimination d'eau mais par l'élimination d'autres petites molécules biologiques. Chacun de ces biopolymères peut être caractérisé soit comme un hétéropolymère, ce qui signifie qu'il se compose de plus d'une unité monomère ordonné dans la chaîne principale, soit comme un homopolymère, qui consiste en la répétition d'une seule unité monomère. Les polypeptides et les acides nucléiques sont très souvent des hétéropolymères, tandis que les macromolécules glucidiques courantes telles que le glycogène peuvent être des homopolymères. En effet, les différences chimiques des monomères peptidiques et nucléotidiques déterminent la fonction biologique de leurs polymères, tandis que les monomères glucidiques communs ont une fonction générale telle que le stockage et la délivrance d'énergie.
Vue d'ensemble des épines dorsales communes
Chimie des polymères
- Alcane saturé (typique des polymères vinyliques).
- Squelette des polymères de croissance par étapes (polyaniline, polythiophène, PEDOT). Ceux-ci ont souvent des hétérocycles dérivés en tant que monomères, tels que des thiophènes, des diazoles ou des pyrroles.
- Squelette fullerène[7].
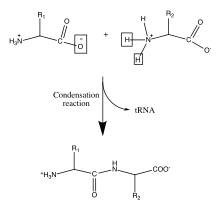
Protéines (polypeptides)
Les protéines sont des molécules biologiques importantes qui jouent un rôle principal dans la structure et la fonction des virus, des bactéries et des cellules eucaryotes. Leurs squelettes sont caractérisés par des liaisons amide formées par la polymérisation entre des groupes acides aminés et carboxyliques attachés au carbone alpha de chacun des vingt acides aminés. Ces séquences d'acides aminés sont traduites à partir des ARNm cellulaires par des ribosomes dans le cytoplasme de la cellule[8]. Les ribosomes ont une activité enzymatique qui dirige la réaction vers la condensation formant la liaison amide entre chaque acide aminé successif. Cela se produit au cours d'un processus biologique appelé traduction. Dans ce mécanisme enzymatique, une navette d'ARNt lié de manière covalente agit comme groupe partant pour la réaction de condensation. L'ARNt nouvellement libéré peut « capter » un autre peptide et participer en continu à cette réaction[9]. La séquence des acides aminés dans le squelette polypeptidique est connue comme la structure primaire de la protéine. Cette structure primaire conduit au repliement de la protéine dans la structure secondaire, formée par une liaison hydrogène entre les oxygènes carbonyle et les hydrogènes aminés dans le squelette. D'autres interactions entre les résidus des acides aminés individuels forment la structure tertiaire de la protéine. Pour cette raison, la structure primaire des acides aminés dans le squelette polypeptidique est la carte de la structure finale d'une protéine, et elle indique donc sa fonction biologique[10] - [1]. Les positions spatiales des atomes du squelette peuvent être reconstruites à partir des positions des carbones alpha en utilisant des outils de calcul pour la reconstruction du squelette[11].

Glucides
Les glucides jouent de nombreux rôles dans le corps, notamment en tant qu'unités structurelles, cofacteurs enzymatiques et sites de reconnaissance de la surface cellulaire. Leur rôle principal est de stocker de l'énergie puis de la livrer dans les voies métaboliques cellulaires. Les glucides les plus simples sont des résidus de sucre uniques appelés monosaccharides comme le glucose, la molécule de livraison d'énergie de notre corps. Les oligosaccharides (jusqu'à 10 résidus) et les polysaccharides (jusqu'à environ 50 000 résidus) sont constitués de résidus saccharidiques liés dans une chaîne principale, qui est caractérisée par une liaison éther connue sous le nom de liaison glycosidique. Lors de la formation du glycogène par l'organisme, le polymère de stockage d'énergie, cette liaison glycosidique est formée par l'enzyme glycogène synthase. Le mécanisme de cette réaction de condensation enzymatique n'est pas bien étudié mais il est connu que la molécule UDP agit comme un connecteur intermédiaire et est perdue dans la synthèse[12]. Ces chaînes de squelette peuvent être non ramifiées (contenant une chaîne linéaire) ou ramifiées (contenant plusieurs chaînes). Les liaisons glycosidiques sont désignées par alpha ou bêta en fonction de la stéréochimie relative du carbone anomérique (ou le plus oxydé). Dans une projection de Fischer, si la liaison glycosidique est du même côté ou face que le carbone 6 d'un saccharide biologique commun, le glucide est désigné comme bêta et si la liaison est du côté opposé, il est désigné comme alpha. Dans une projection traditionnelle à « structure de chaise », si la liaison est sur le même plan (équatorial ou axial) que le carbone 6, elle est désignée bêta et sur le plan opposé, elle est désignée alpha. Ceci est illustré par le saccharose (sucre de table) qui contient une liaison alpha au glucose et bêta au fructose. Généralement, les glucides que décompose notre corps sont liés en alpha (exemple : glycogène) et ceux qui ont une fonction structurelle sont liés en bêta (exemple : cellulose)[1] - [13].
Acides nucléiques
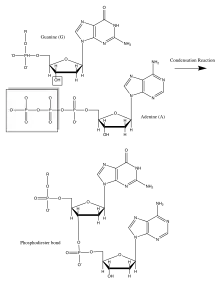
L'acide désoxyribonucléique (ADN) et l'acide ribonucléique (ARN) ont d'une grande importance car ils codent la production de toutes les protéines cellulaires. Ils sont constitués de monomères appelés nucléotides qui consistent en une base organique : A, G, C et T ou U, un sucre pentose et un groupe phosphate. Ils ont des squelettes dans lesquels le carbone 3' du sucre de ribose est relié au groupe phosphate via une liaison phosphodiester. Cette liaison est formée à l'aide d'une classe d'enzymes cellulaires appelées polymérases. Dans cette réaction de condensation enzymatique, tous les nucléotides entrants ont un ribose triphosphorylé qui perd un groupe pyrophosphate pour former la liaison intrinsèque de phosphodiester. Cette réaction est provoquée par le grand changement d'énergie libre négative associé à la libération de pyrophosphate. La séquence de bases dans le squelette d'acide nucléique est également connue sous le nom de structure primaire. Les acides nucléiques peuvent être des millions de nucléotides différents, conduisant ainsi à la diversité génétique de la vie. Les bases sortent du squelette du polymère pentose-phosphate dans l'ADN et sont liées par paires hydrogène à leurs partenaires complémentaires (A avec T et G avec C). Cela crée une double hélice avec des squelettes pentose phosphate de chaque côté, formant ainsi une structure secondaire[14] - [1] - [15].
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Backbone chain » (voir la liste des auteurs).
- Donald Voet, Judith G. Voet et Charlotte W. Pratt, Fundamentals of Biochemistry: Life at the Molecular Level, , 5e éd. (ISBN 978-1-118-91840-1, lire en ligne).
- Clinical Methods: The History, Physical, and Laboratory Examinations, , 3e éd. (ISBN 0-409-90077-X, PMID 21250192, lire en ligne), « 31 Cholesterol, Triglycerides, and Associated Lipoproteins ».
- Eva Budgaard et Frederik Krebs, « Low band gap polymers for organic photovoltaics », Solar Energy Materials and Solar Cells, vol. 91, no 11, , p. 954–985 (DOI 10.1016/j.solmat.2007.01.015).
- « Polymers » [archive du ] (consulté le ).
- C.J. Brabec, C. Winder, M.C Scharber et S.N. Sarıçiftçi, « Influence of disorder on the photoinduced excitations in phenyl substituted polythiophenes », Journal of Chemical Physics, vol. 115, no 15, , p. 7235 (DOI 10.1063/1.1404984, Bibcode 2001JChPh.115.7235B, lire en ligne).
- (en) « condensation reaction », IUPAC, Compendium of Chemical Terminology [« Gold Book »], Oxford, Blackwell Scientific Publications, 1997, version corrigée en ligne : (2019-), 2e éd. (ISBN 0-9678550-9-8)
- Andreas Hirsch, « Fullerene polymers », Advanced Materials, vol. 5, no 11, , p. 859–861 (DOI 10.1002/adma.19930051116).
- H.F. Noller, « The parable of the caveman and the Ferrari: protein synthesis and the RNA world », Phil. Trans. R. Soc. B, vol. 372, no 1716, , p. 20160187 (PMID 28138073, PMCID 5311931, DOI 10.1098/rstb.2016.0187).
- Joshua Weinger, « Participation of the tRNA A76 hydroxyl groups throughout translation », Biochemistry, vol. 45, no 19, , p. 5939–5948 (PMID 16681365, PMCID 2522371, DOI 10.1021/bi060183n).
- Biochemistry, , 5e éd. (ISBN 0-7167-3051-0, lire en ligne), « 3.2 Primary Structure: Amino Acids Are Linked by Peptide Bonds to Form Polypeptide Chains ».
- Aleksandra E. Badaczewska-Dawid, Andrzej Kolinski et Sebastian Kmiecik, « Computational reconstruction of atomistic protein structures from coarse-grained models », Computational and Structural Biotechnology Journal, vol. 18, , p. 162–176 (ISSN 2001-0370, PMID 31969975, PMCID 6961067, DOI 10.1016/j.csbj.2019.12.007).
- Alejandro Buschiazzo, « Crystal structure of glycogen synthase: homologous enzymes catalyze glycogen synthesis and degradation », The EMBO Journal, vol. 23, no 16, , p. 3196–3205 (PMID 15272305, PMCID 514502, DOI 10.1038/sj.emboj.7600324).
- Essentials of Glycobiology, , 2e éd. (ISBN 9780879697709, PMID 20301274, lire en ligne), « Structural Basis of Glycan Diversity ».
- Molecular Biology of the Cell, , 4e éd. (ISBN 0-8153-3218-1, lire en ligne), « DNA Replication Mechanisms ».
- Molecular Cell Biology, , 4e éd. (ISBN 0-7167-3136-3, lire en ligne), « 4.1, Structure of Nucleic Acids ».
Articles connexes
- Groupe pendentif
- Peptide