Big data
Mégadonnées
Le big data /ˌbɪɡ ˈdeɪtə/[1] (litt. « grosses données » en anglais), les mégadonnées[2] - [3] ou les données massives[2], désigne les ressources d’informations dont les caractéristiques en termes de volume, de vélocité et de variété imposent l’utilisation de technologies et de méthodes analytiques particulières pour créer de la valeur[4] - [5], et qui dépassent en général les capacités d'une seule et unique machine et nécessitent des traitements parallélisés.
L’explosion quantitative (et souvent redondante) des données numériques permet une nouvelle approche pour analyser le monde[6]. Le volume colossal de données numériques disponibles, implique de mettre en oeuvre de nouveaux ordres de grandeur concernant la capture, le stockage, la recherche, le partage, l'analyse et la visualisation des données. Le traitement des big data[7] permet de nouvelles possibilités d'exploration de l'information et des données, celles-ci proviennent de nombreuses sources numériques : les réseaux sociaux, les médias[8], l'OpenData, le Web, des bases de données privées, publiques à caractère commercial ou scientifique. Cela permet des recoupements et des analyses prédictives dans de nombreux domaines : scientifique, santé, économique, commercial… La multiplicité des applications a été comprise et développée par les plus gros acteurs du secteur des technologies de l'information[9].
Divers experts, grandes institutions (comme le MIT[10] aux États-Unis, le Collège de France[11] en Europe), administrations[12] et spécialistes sur le terrain des technologies ou des usages[13] considèrent le phénomène big data comme l'un des grands défis informatiques de la décennie 2010-2020 et en ont fait une de leurs nouvelles priorités de recherche et développement, qui pourrait notamment conduire à l'Intelligence artificielle en étant exploré par des réseaux de neurones artificiels autoapprenants[14].
Histoire
Le big data a une histoire récente et pour partie cachée, en tant qu'outil des technologies de l'information et comme espace virtuel prenant une importance volumique croissante dans le cyberespace .
L'expression « big data » serait apparue en octobre 1997 selon les archives de la bibliothèque numérique de l'Association for Computing Machinery (ACM), dans un article scientifique sur les défis technologiques à relever pour visualiser les « grands ensembles de données »[18].
La naissance du Big Data est liée aux progrès des capacités des systèmes de stockage, de fouille et d'analyse de l'information numérique, qui ont vécu une sorte de big bang des données[19]. Mais ses prémices sont à trouver dans le croisement de la cybernétique et de courants de pensée nés durant la Seconde Guerre mondiale, selon lesquels l’homme et le monde peuvent être représentés comme « des ensembles informationnels, dont la seule différence avec la machine est leur niveau de complexité. La vie deviendrait alors une suite de 0 et de 1, programmable et prédictible »[20].
Les évolutions qui caractérisent le big data et ses algorithmes, ainsi que celles de la science des données sont en partie cachées (au sein des services de renseignement des grands États) et si rapides et potentiellement profondes que peu de prospectivistes se risquent à pronostiquer son devenir à moyen ou long terme[21], mais la plupart des observateurs y voient des enjeux majeurs pour l'avenir, tant en termes d'opportunités commerciales[22] que de bouleversements sociopolitiques et militaires, avec en particulier le risque de voir émerger des systèmes ubiquistes, orwelliens[23] et totalitaires capables de fortement contrôler, surveiller et/ou influencer les individus et groupes.
Les risques de dérives de la part de gouvernements ou d'entreprises[24] ont surtout d'abord été décrits par Orwell à la fin de la dernière guerre mondiale, puis souvent par la science fiction. Avec l'apparition de grandes banques de données dans les années 1970 (et durant toute la période de la guerre froide) de nombreux auteurs s'inquiètent des risques pris concernant la protection de la vie privée[25], en particulier Arthur R. Miller (en) qui cite l'exemple de la croissance des données stockées relatives à la santé physique et psychique des individus[26] - [27] - [28].
En 2000, Froomkin, dans un article paru dans la revue Stanford Law Review, se demande si la vie privée n'est pas déjà morte[29], mais ce sont surtout les révélations d'Edward Snowden (2013) qui ont suscité une nouvelle prise de conscience et d'importants mouvements de protestation citoyenne.
Les quatre droits et « états de base de la vie privée » tels qu'énoncés par Westin en 1962 (droit à la solitude[30], à l'intimité, à l'anonymat dans la foule et à la réserve) sont menacés dans un nombre croissant de situations[31], de même que la protection du contenu des courriers électroniques[32] qui fait partie du droit à la vie privée[33].
Dimensions
Le big data s'accompagne du développement d'applications à visée analytique, qui traitent les données pour en tirer du sens[34]. Ces analyses sont appelées big analytics[35] ou « broyage de données ». Elles portent sur des données quantitatives complexes à l'aide de méthodes de calcul distribué et de statistiques.
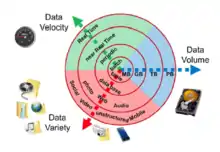
En 2001, un rapport de recherche du META Group (devenu Gartner)[36] définit les enjeux inhérents à la croissance des données comme étant tri-dimensionnels : les analyses complexes répondent en effet à la règle dite « des 3V » (volume, vélocité et variété[37]). Ce modèle est encore largement utilisé aujourd’hui pour décrire ce phénomène[38]. Aux 3 V initiaux, sont parfois ajoutés d'autres V comme : Véracité, Valeur et Visualisation[39] - [40].
Volume
C'est une dimension relative : le big data, comme le notait Lev Manovitch en 2011[41], définissait autrefois « les ensembles de données suffisamment grands pour nécessiter des super-ordinateurs », mais il est rapidement (dans les années 1990/2000) devenu possible d'utiliser des logiciels standards sur des ordinateurs de bureau pour analyser ou co-analyser de vastes ensembles de données[42].
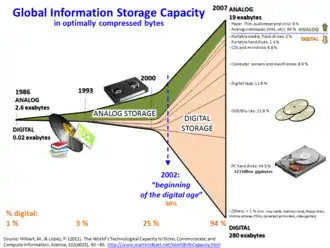
Le volume des données stockées est en pleine expansion : les données numériques créées dans le monde seraient passées de 1,2 zettaoctet par an en 2010 à 1,8 zettaoctet en 2011[43], puis 2,8 zettaoctets en 2012 et s'élèveront à 64 zettaoctets en 2020[44], et 2 142 zettaoctets en 2035[44]. À titre d'exemple, Twitter générait en janvier 2013, 7 téraoctets de données chaque jour et Facebook 10 téraoctets[45]. En 2014, Facebook Hive générait 4 000 To de data par jour[46].
Les installations technico-scientifiques (météorologie, etc.) produiraient le plus de données. De nombreux projets de dimension pharaonique sont en cours. Le radiotélescope Square Kilometre Array par exemple produira 50 téraoctets de données analysées par jour, tirées de données brutes produites à un rythme de 7 000 téraoctets par seconde[47].
Variété
Le volume des big data met les centres de données face à un réel défi : la variété des données.
Il ne s'agit pas uniquement de données relationnelles traditionnelles, mais surtout de données brutes, semi-structurées, voire non structurées (cependant, les données non structurées devront être analysées et structurées ultérieurement si nécessaire pour leur utilisation[48]).
Ce sont des données complexes qui proviennent de multiples sources : du web (Web mining), de bases publiques (open data, Web des données), géo-démographiques par îlot (adresses IP), machines ou objets connectés (IoT), ou relever de la propriété des entreprises et des consommateurs, ce qui les rend inaccessibles aux outils traditionnels.
La démultiplication des outils de collecte sur les individus et sur les objets permet d’amasser toujours plus de données[49]. Les analyses sont d’autant plus complexes qu’elles portent de plus en plus sur les liens entre des données de natures différentes.
Vélocité
La vélocité représente la fréquence à laquelle les données sont à la fois engendrées, capturées, partagées et mises à jour[50].
Des flux croissants de données doivent être analysés en quasi-temps réel (fouille de flots de données) pour répondre aux besoins des processus chrono-sensibles[51]. Par exemple, les systèmes mis en place par la bourse et les entreprises doivent être capables de traiter ces données avant qu’un nouveau cycle de génération n’ait commencé, avec le risque pour l'Homme de perdre une grande partie de la maîtrise du système quand les principaux opérateurs deviennent des machines sans disposer de tous les critères pertinents d'analyse pour le moyen et long terme.
Véracité
La véracité fait référence à la fiabilité et à la dimension qualitative des données. Traiter et gérer l’incertitude et les erreurs rencontrées dans certaines données, représente un challenge de taille pour fiabiliser et minimiser les biais[39] - [40].
Valeur
Les efforts et les investissements dans l'utilisation et application Big Data n’ont de sens que si elles apportent de la valeur ajoutée[39] - [40].
Visualisation
La mise en forme et mise à disposition des données et des résultats de l'analyse des données, permet de faciliter sa compréhension et son interprétation, afin d'améliorer la prise de décisions[39].
Différence avec l'informatique décisionnelle
Si la définition du Gartner en 3V est encore largement reprise (voire augmentée de « V » supplémentaires selon l’inspiration des services marketing), la maturation du sujet fait apparaître un autre critère plus fondamental de différence avec l'informatique décisionnelle et concernant les données et leur utilisation[52] :
- Informatique décisionnelle : utilisation de statistique descriptive, sur des données à forte densité en information afin de mesurer des phénomènes, détecter des tendances… ;
- Big data : utilisation de statistique inférentielle, sur des données à faible densité en information[53] dont le grand volume permet d’inférer des corrélations et lois mathématiques ou statistiques (régressions…) donnant dès lors au big data (avec les limites de l’inférence) des capacités de généralisation pouvant être qualifiées de prédictives[54].
Synthétiquement :
- l'informatique traditionnelle, informatique décisionnelle comprise, est basée sur un modèle du monde ;
- le big data vise à ce que les mathématiques trouvent un modèle dans les données[55] - .
Représentation
Modèles
Les bases de données relationnelles classiques ne permettent pas de gérer les volumes de données du big data. De nouveaux modèles de représentation permettent de garantir les performances sur les volumétries en jeu. Ces technologies, dites de business analytics and optimization (BAO) permettent de gérer des bases massivement parallèles[56]. Des patrons d’architecture (« big data architecture framework », BDAF)[57] sont proposés par les acteurs de ce marché comme MapReduce créé par Google et utilisé dans le framework Hadoop. Avec ce système, les requêtes sont séparées et distribuées à des nœuds parallélisés, puis exécutées en parallèle (map). Les résultats sont ensuite rassemblés et récupérés (reduce). Teradata, Oracle ou EMC (via le rachat de Greenplum) proposent également de telles structures, basées sur des serveurs standards dont les configurations sont optimisées. Ils sont concurrencés par des éditeurs comme SAP et plus récemment Microsoft[58]. Les acteurs du marché s’appuient sur des systèmes à forte évolutivité horizontale et sur des solutions basées sur du NoSQL (MongoDB, Cassandra) plutôt que sur des bases de données relationnelles classiques[59].
Stockage
Pour répondre aux problématiques big data, l’architecture de stockage des systèmes doit être repensée et les modèles de stockage se multiplient en conséquence.
- Lac de données : moyen de stockage de données massives en clusters, et gardées dans leurs formats originaux, pour pouvoir stocker tout format de données de manière rapide et peu coûteuse.
- Cloud computing[60] : l’accès se fait via le réseau, les services sont accessibles à la demande et en libre service sur des ressources informatiques partagées et configurables[61]. Les services les plus connus sont ceux de Google BigQuery, Big Data sur Amazon Web Services et Microsoft Windows Azure.
- Super calculateurs hybrides : les HPC pour high performance computing, peuvent être utilisés dans le domaine des Big Data pour leur puissance de calcul et d'analyse. On en retrouve en France dans les centres nationaux de calculs universitaire tels que l’IDRIS, le CINES, mais aussi au CEA ou encore le HPC-LR[62] ou à Météo France[63] - [64].
- Systèmes de fichiers distribués (ou DFS pour distributed file system) : les données ne sont plus stockées sur une seule machine car la quantité est beaucoup trop importante. Les données sont réparties sur une machine bien précise utilisant du stockage local[65]. Le stockage local est préféré au stockage SAN et NAS pour des raisons de goulots d'étranglement au niveau du réseau et des interfaces réseaux des SAN. De plus, utiliser un stockage de type SAN coûte bien plus cher pour des performances bien moindres. Dans les systèmes de stockage distribué pour le big data, l'on introduit le principe de data locality[65]. Les données sont sauvegardées là où elles peuvent être traitées.
- Virtualisation du stockage : La virtualisation des données est un moyen de rassembler des données provenant de plusieurs sources dans une seule « vue ». L'assemblage est virtuel : contrairement à d'autres méthodes, la plupart des données restent en place et sont extraites des sources brutes à la demande[66].
Applications
Le big data trouve des applications dans de nombreux domaines : programmes scientifiques (CERN28 Mastodons), outils d'entreprises (IBM29, Amazon Web Services, BigQuery, SAP HANA) parfois spécialisées (Teradata, Jaspersoft30, Pentaho31…) ou startups, ainsi que dans le domaine de l'open source (Apache Hadoop, Infobright32, Talend33…) et de logiciels d'exploitation ouverts (avec par exemple le logiciel ouvert d'analyse de big data H2O).
Les applications du BigData sont très nombreuses : il permet des recoupements et des analyses prédictives dans les domaines de connaissance et d'évaluation, d'analyse tendancielle et prospective (climatiques, environnementales ou encore sociopolitiques, etc.) et de gestion des risques (commerciaux, assuranciels, industriels, naturels) et de prise de décisions, et de phénomènes religieux, culturels, politiques[67], mais aussi en termes de génomique ou métagénomique[68], pour la médecine (compréhension du fonctionnement du cerveau, épidémiologie, écoépidémiologie…), la météorologie et l'adaptation aux changements climatiques, la gestion de réseaux énergétiques complexes (via les smartgrids ou un futur « internet de l'énergie »), l'écologie (fonctionnement et dysfonctionnement des réseaux écologiques, des réseaux trophiques avec le GBIF par exemple), ou encore la sécurité et la lutte contre la criminalité[69], ou encore améliorer l'« expérience client » en la rendant plus personnalisée et contextualisée[70]. La multiplicité de ces applications laisse d'ailleurs déjà poindre un véritable écosystème économique impliquant, d'ores et déjà, les plus gros acteurs du secteur des technologies de l'information[9].
Recherche scientifique
Le big data en est issu et il alimente une partie de la recherche. Ainsi le Large Hadron Collider du CERN utilise environ 150 millions de capteurs délivrant des données 40 millions de fois par seconde ; Pour 600 millions de collisions par seconde, il reste après filtrage 100 collisions d'intérêt par seconde, soit 25 Po de données à stocker par an, et 200 Po après réplication[71] - [72] - [73]. Les outils d'analyse du big data pourraient affiner l'exploitation de ces données.
Quand le Sloan Digital Sky Survey (SDSS) a commencé à collecter des données astronomiques en 2000, il a amassé en quelques semaines plus de données que toutes celles précédemment collectées dans l’histoire de l’astronomie. Il continue à un rythme de 200 Go par nuit, et a en 10 ans (2000-2010) stocké plus de 140 téraoctets d’information. Le Large Synoptic Survey Telescope prévu pour 2015 devrait en amasser autant tous les cinq jours[74].
Décoder le premier génome humain a nécessité dix ans, mais prend aujourd'hui moins d'une semaine : les séquenceurs d'ADN ont progressé d'un facteur 10 000 les dix dernières années, soit 100 fois la loi de Moore (qui a progressé d'un facteur 100 environ sur 10 ans)[75]. En biologie, les approches massives basées sur une logique d’exploration des données et de recherche d’induction sont légitimes et complémentaires des approches classiques basées sur l'hypothèse initiale formulée[76]. Le big data s'est aussi introduit dans le domaine des protéines.
Le NASA Center for Climate Simulation (NCCS) stocke 32 Po de données d’observations et de simulations climatiques[77].
Les sciences sociales explorent des corpus aussi variés que le contenu de Wikipédia dans le monde ou les millions de publications et de tweets sur Internet.
Planète et climat
Le big data mondial contient des données essentielles « pour résoudre l'équation climatique », et notamment pour améliorer l'efficacité énergétique des villes et bâtiments, pour les smartgrids, pour vérifier l'application de règlementations visant à lutter contre la déforestation, la surpêche, la dégradation des sols, le gaspillage alimentaire ou à mieux gérer les déchets, éco-consommer ou inciter les investisseurs à créer des villes intelligentes[78], etc.
Lors de la COP 23 (Bonn, 2017) un événement parallèle de haut niveau organisé par le « Forum sur l'innovation durable » et le PNUD a réuni des dirigeants de sociétés de données du secteur privé et des représentants des Nations unies. Ce groupe a appelé à développer la « philanthropie des données », c'est-à-dire à massivement et de manière altruiste partager les données[79] - [80] pour stimuler l'efficacité, l'innovation et le soutien aux actions de protection du climat et de résilience face au changement climatique. Une meilleure collecte, mise à disposition de tous, analyse et utilisation des données volumineuses est une condition selon ce groupe pour atteindre l'objectif 2030 no 13 (pour le climat) de l'ONU[81] et les objectifs de l'Accord de Paris sur le climat[78].
C'est ce qu'y a rappelé Amina J. Mohammed, Secrétaire générale adjointe des Nations unies, dans son discours d'ouverture. C'est le cas notamment des données météo nécessaires à l'agriculture, à la protection de l'économie et des infrastructures vulnérables aux aléas climatiques[78].
En 2017, le PNUD aide plus de 75 pays à moderniser leurs systèmes de surveillance météorologique et climatiques. Dans les pays dits émergents, un effort reste à faire pour le « dernier kilomètre » ; par exemple, les « opérateurs mobiles » pourraient mieux recevoir l'information météorologique et aider à un partage des données sur les récoltes et problèmes de culture via des téléphones portables ; les antennes relais pourraient elles-mêmes, en lien avec des sociétés de Big Data devenir des plates-formes de regroupement de données utiles à l'élaboration de plans locaux et nationaux d'adaptation au changement climatique, et utiles à l'élaboration de stratégies sectorielles de résilience climatique[78].
Les difficultés d'anonymisation de la donnée privée restent cependant un important frein au partage efficace de données massives entre les décideurs et le grand-public. La « philanthropie des données » vise à faire des secteurs public et privé deux partenaires égaux[78].
- En 2016, le PNUD a organisé un concours d'innovation (Climate Action Hackathon) qui a attribué des bourses à 23 développeurs Web pour créer des applications mobiles de terrain en Afrique, utilisant les données climatiques et météorologiques[78].
- En 2017 un concours « Data for Climate Action Challenge » a été lancé début 2017 par Global Pulse (Onu) pour susciter l'innovation en matière de données ouvertes axée sur l'exploitation du Big Data et de l'analyse de données au service du bien commun. Ce concours vise à catalyser l'action sur le changement climatique. Il a mis en relation 97 équipes de recherche (semi-finalistes) avec des jeux de données venant de 11 entreprises[78].
En 2016 Taylor s'interroge : Quand le big data est présenté comme un commun ou un bien public ; de quel bien parle-t-on ? et à quel public le destine-t-on réellement[82] ? en citant notamment Robert Kirkpatrick (directeur de UN Global Pulse) pour qui « le big data est comme un nouveau type de ressource naturelle (ou non-naturelle) infiniment renouvelable, de plus en plus omniprésente - mais qui est tombée entre les mains d'une industrie extractive opaque et largement non réglementée, qui commence seulement à se rendre compte qu'il existe une opportunité sociale - et peut-être une responsabilité sociale - à s'assurer que ces données atteignent les personnes qui en ont le plus besoin »[79] - [82].
Politique, élections, et renseignement
L’analyse du big data a joué un rôle important dans la campagne de réélection de Barack Obama, notamment pour analyser les opinions politiques de la population[83] - [84] - [85].
Depuis 2012, le département de la Défense américain investit annuellement sur les projets big data plus de 250 millions de dollars[86]. Le gouvernement américain possède six des dix plus puissants supercalculateurs de la planète[87]. La National Security Agency a notamment construit le Utah Data Center qui stocke depuis septembre 2014 jusqu'à un yottaoctet d’informations collectées par la NSA sur internet[88]. En 2013, le big data faisait partie des sept ambitions stratégiques de la France déterminées par la Commission innovation 2030[89].
Profilage des utilisateurs par le secteur privé
La revente de fichier de profil utilisateur peut participer au big data.
Walmart traite plus d'un million de transactions client par heure, importées dans des bases de données qui contiendraient plus de 2,5 Po d’information[90]. Facebook traite 50 milliards de photos. D’une manière générale l'exploration de données de big data permet l’élaboration de profils clients dont on ne supposait pas l’existence[91].
Le musée Solomon R. Guggenheim construit sa stratégie en analysant des données massives : dans les salles des transmetteurs électroniques suivent les visiteurs tout au long de leur visite. Le musée détermine ainsi de nouveaux parcours de visite en fonction des œuvres les plus appréciées, ou décider des expositions à mettre en place[92].
Secteur énergétique
Les bâtiments intelligents (éventuellement au sein de villes intelligentes) sont caractérisés par une « hybridation » entre numérique et énergie.
Ces bâtiments ou logements individuels peuvent produire de l'énergie (voire être positifs en énergie). Ils peuvent aussi produire des données sur cette énergie et/ou sur leur consommation d'énergies. Ces données une fois agrégées et analysées peuvent permettre d'appréhender voire d'anticiper la consommation des usagers, des quartiers, villes, etc. en fonction des variations du contexte, météorologique notamment.
L'analyse des données collectées de production (solaire, microéolien…) et de consommation dans un bâtiment, par le biais des objets connectés et du smartgrid, permet aussi potentiellement de mieux gérer la consommation des usagers (de manière personnalisée).
En attendant un développement plus large du stockage de l'énergie, les jours nuageux et sans vent il faut encore faire appel à des centrales conventionnelles, et les jours exceptionnellement beaux et venteux (ex. : en Allemagne, 8 mai 2016 où durant 4 heures le vent et le soleil ont engendré plus de 90 % de l'électricité du pays, les centrales électriques au charbon et au gaz doivent réduire à temps leur production). Un cas extrême est celui d’une éclipse solaire (prévisible). La gestion de ces pics et intermittences coûte aujourd’hui plus de 500 millions €/an à l’Allemagne et conduit à des émissions de CO2 et autres gaz à effet de serre que l’on voudrait éviter[93]. Grâce aux corrélations pouvant émerger de l'analyse fine des mégadonnées, les opérateurs de l'énergie peuvent mieux appréhender les variations fines du gisement des énergies renouvelables et les croiser avec la demande réelle.
Exemples
- En 2009 la Centre national pour la recherche atmosphérique (NCAR) de Boulder dans le Colorado a lancé un tel système. Il est mi-2016 opérationnel dans huit États américains. Au sein de Xcel Energy (entreprise basée à Denver, (Colorado) qui dispose de la première capacité éolienne des États-Unis), cette approche a amélioré la prévision, assez pour que depuis 2009, les clients aient évité US $ 60 millions/an de dépenses, et l’émission de plus d'un quart d'un million de tonnes CO2/an grâce à un moindre recours aux énergies fossiles[93] ;
- En 2016, l’Allemagne a fait un pas important vers l’internet de l'énergie tel que proposé par le prospectiviste Jeremy Rifkin en expérimentant un processus (EWeLiNE[94]) d’analyse automatique du big data énergétique et météorologique.
Contexte : Avec 45 000 mégawatts, la capacité éolienne de l'Allemagne est la 3e au monde, derrière la Chine et les États-Unis, et seule la Chine rivalise avec l’Allemagne en termes de capacité solaire. Un tiers de l'électricité est en 2016 d’origine renouvelable et le gouvernement cible au 80 % du total avant 2050 et 35 % avant 2020[93]. Cela va demander de développer un « smartgrid » permettant une répartition et un stockage encore plus intelligent et réactif de l’énergie.
L'expérimentation : En juin 2016, pour mieux adapter le réseau électrique (réseau électrique intelligent) au caractère intermittent du solaire et de l'éolien, ainsi qu’aux variations instantanées, quotidiennes et saisonnières de la demande, et pour limiter l’appel aux énergies fossiles, l’Allemagne a lancé un processus (baptisé EWeLiNE) d’analyse automatique du big data.
- EWeLiNE associe trois opérateurs (TSOs Amprion GmbH, TenneT TSO GmbH et 50 Hertz)[93]. Ils bénéficient de 7 M€ (déboursés par le ministère fédéral des affaires économiques et de l'énergie)[93]. Des logiciels vont exploiter le big data des données météo et des données d'intérêt énergétique pour prévoir avec une précision croissante la capacité productive instantanée des ENR (car quand le vent augmente ou qu’un nuage passe au-dessus d'une ferme solaire, la production augmente ou chute localement et le réseau doit s’adapter). EWeLiNE doit améliorer la gestion anticipée et en temps réel de la production et de la consommation grâce à la prévision énergético-météorologique via un système « apprenant » de prévision statistiquement avancée de la force du vent (au niveau du moyeu d'une turbine) et de la puissance solaire (au niveau des modules photovoltaïque).
Les grandes éoliennes mesurent souvent elles-mêmes en temps réel la vitesse du vent au niveau des turbines, et certains panneaux solaires intègrent des capteurs d’intensité lumineuse[93]. EWeLiNE combine ces données avec les données météo classiques (terrestre, radar et satellitale) et les transfère dans des modèles informatiques sophistiqués (« systèmes apprenants ») pour mieux prédire la production d'électricité durant les prochaines 48 heures (ou plus)[93]. L'équipe scientifique vérifie ces prévisions de puissance, et les ordinateurs « apprennent » de leurs erreurs, permettant aux modèles prédictifs d’être de plus en plus précis.
EWeLiNE a d’abord été testé (en juin 2016) sur quelques réseaux de panneaux solaires et d'éoliennes équipés de capteurs. À partir de juillet, les opérateurs vont peu à peu étendre le système en se connectant à un nombre croissant d’installations solaires et éoliennes qui leur transmettront en temps réel leurs données pour ajuster la quantité d'énergie produite à l’échelle du pays (l’objectif est de le faire en 2 ans)[93]. On s’approchera alors de ce que J Rifkin a nommé l’internet de l’énergie, si ce n’est qu’il y intègre aussi les usages domestiques et individuels (ce qui devrait être permis par la diffusion des compteurs intelligents et de systèmes intelligents et locaux ou mobiles de stockage de l’énergie).
Premiers retours : Les premiers résultats allemands laissent penser que l’approche fonctionnera, car le travail des modélisateurs allemand avait déjà permis de bonnes améliorations avant l’accès à ces données. EWeLiNE n’est pas une déclinaison ni une traduction du systems américain du NCAR ; les modèles météorologiques et les algorithmes convertissant les prévisions météorologiques en prévisions de puissance diffèrent[93]
Utilisation par le secteur privé
Dans la majorité des cas, les entreprises peuvent utiliser les données pour mieux connaitre leur marché. En effet les données collectées par les cartes de fidélité et les historiques d’achat permettent de mieux comprendre le marché de manière générale, d’en faire une meilleure segmentation[95] . Les entreprises vont pouvoir proposer des articles qui correspondent aux envies du clients par le ciblage. Le meilleur exemple serait Amazon qui, grâce au big data, a réussi à accroitre la pertinence de ses recommandations[96]. Le Big Data permet donc de dégager un schéma global aidant à comprendre le marché. L’entreprise saura alors quels produits proposés ou sur quels produits il faut davantage accentuer la communication afin de les rendre plus attrayants[97]. Tout cela peut être crucial pour l’entreprise. Mais elles peuvent aussi utiliser les données dans un autre registre : améliorer leurs technologies. Par exemple Rolls-Royce met des capteurs dans les moteurs de leurs réacteurs afin de d’avoir de multiples informations pendant le vol[96]. Cet auteur explique qu’avant le boom du big data, les informations jugées superflues étaient détruites par les ordinateurs mais maintenant elles sont collectées dans des serveurs centraux afin de créer des modèles permettant de prévoir des pannes et/ou des défaillances. Elle a donc renforcé la sureté de ses réacteurs et a pu transformer ces données en profit.
Perspectives et évolutions
L'un des principaux enjeux de productivité du big data dans son évolution va porter sur la logistique de l'information, c'est-à-dire sur la manière de garantir que l'information pertinente arrive au bon endroit au bon moment. Il s'agit d'une approche micro-économique. Son efficacité dépendra ainsi de celle de la combinaison entre les approches micro- et macro-économique d'un problème.
Selon certaines sources, les données numériques créées dans le monde atteindraient 47 zettaoctets d'ici 2020[44] et 175 zettaoctets en 2035[44]. À titre de comparaison, Facebook générait environ 10 téraoctets de données par jour au début 2013. Le développement de l'hébergement massif de données semble avoir été accéléré par plusieurs phénomènes simultanément : la pénurie de disques durs à la suite des inondations en Thaïlande en 2011, l'explosion du marché des supports mobiles (smartphones et tablettes notamment), etc. Ajouté à cela, la démocratisation du cloud-computing de plus en plus proche, grâce à des outils comme Dropbox, amène le big data au centre de la logistique de l'information.
Afin de pouvoir exploiter au maximum le big data, de nombreuses avancées doivent être faites, et ce en suivant trois axes.
Modélisation de données
Les méthodes de modélisation de données ainsi que les systèmes de gestion de base de données relationnelles classiques ont été conçus pour des volumes de données très inférieurs. La fouille de données a des caractéristiques fondamentalement différentes et les technologies actuelles ne permettent pas de les exploiter.
Dans le futur il faudra des modélisations de données et des langages de requêtes permettant :
- une représentation des données en accord avec les besoins de plusieurs disciplines scientifiques ;
- de décrire des aspects spécifiques à une discipline (modèles de métadonnées) ;
- de représenter la provenance des données ;
- de représenter des informations contextuelles sur la donnée ;
- de représenter et supporter l’incertitude ;
- de représenter la qualité de la donnée[98] ;
- de réaliser l'approximation d'un gros volume de données[99].
De très nombreux autres thèmes de recherche sont liés à ce thème, citons notamment : la réduction de modèle pour les EDP, l'acquisition comprimée en imagerie, l'étude de méthodes numériques d'ordre élevé… Probabilités, statistiques, analyse numérique, équations aux dérivées partielles déterministes et stochastiques, approximation, calcul haute performance, algorithmique… Une grande partie de la communauté scientifique, notamment en mathématiques appliquées et en informatique, est concernée par ce thème porteur.
Gestion de données
Le besoin de gérer des données extrêmement volumineuses est flagrant et les technologies d’aujourd’hui ne permettent pas de le faire. Il faut repenser des concepts de base de la gestion de données qui ont été déterminés dans le passé. Pour la recherche scientifique, par exemple, il sera indispensable de reconsidérer le principe qui veut qu’une requête sur un SGBD fournisse une réponse complète et correcte sans tenir compte du temps ou des ressources nécessaires. En effet la dimension exploratoire de la fouille de données fait que les scientifiques ne savent pas nécessairement ce qu’ils cherchent. Il serait judicieux que le SGBD puisse donner des réponses rapides et peu coûteuses qui ne seraient qu’une approximation, mais qui permettraient de guider le scientifique dans sa recherche[98].
Dans le domaine des données clients, il existe également de réels besoins d'exploitation de ces données, en raison notamment de la forte augmentation de leur volume des dernières années[100]. Le big data et les technologies associées permettent de répondre à différents enjeux tels que l'accélération des temps d’analyse des données clients, la capacité à analyser l’ensemble des données clients et non seulement un échantillon de celles-ci ou la récupération et la centralisation de nouvelles sources de données clients à analyser afin d’identifier des sources de valeur pour l’entreprise.
Outils de gestion des données
Les outils utilisés au debut des années 2010 ne sont pas en adéquation avec les volumes de données engendrés dans l’exploration du big data. Il est nécessaire de concevoir des instruments permettant de mieux visualiser, analyser, et cataloguer les ensembles de données afin de permettre une optique de recherche guidée par la donnée[98]. La recherche en big data ne fait que commencer. La quantité de données évolue beaucoup plus rapidement que nos connaissances sur ce domaine. Le site The Gov Lab prévoit qu'il n y aura pas suffisamment de scientifiques du data. En 2018, les États-Unis auraient besoin de 140 000 à 190 000 scientifiques spécialisés en big data[86].
Gestion de l'entropie
Le déluge de données qui alimente le big data (et dont certaines sont illégales ou incontrôlées) est souvent métaphoriquement comparé à la fois à un flux continu de nourriture, de pétrole ou d’énergie (qui alimente les entreprises du data mining et secondairement la société de l’information[101]) qui expose au risque d’infobésité et pourrait être comparé à l’équivalent d’une « pollution »[42] du cyberespace et de la noosphère (métaphoriquement, le big data correspondrait pour partie à une sorte de grande marée noire informationnelle, ou à une eutrophisation diffuse mais croissante et continue du monde numérique pouvant conduire à une dystrophisation, voire à des dysfonctions au sein des écosystèmes numériques)[102].
Face à cette « entropie informationnelle » quelques réponses de type néguentropique sont nées (Wikipédia en fait partie en triant et restructurant de l’information déjà publiée).
D’autres réponses ont été la création de moteurs de recherche et d’outils d’analyse sémantique et de fouille de flots de données, de plus en plus puissants et rapides.
Néanmoins, l'analyse du big data tend elle-même à engendrer du big data, avec un besoin de stockage et de serveurs qui semble exponentiel.
Bilan énergétique
Parallèlement à la croissance de la masse et du flux de données, une énergie croissante est dépensée d'une part dans la course aux outils de datamining, au chiffrement/déchiffrement et aux outils analytiques et d’authentification, et d'autre part dans la construction de fermes de serveurs qui doivent être refroidis ; au détriment du bilan énergétique et électrique du Web.
Idées reçues
En 2010, les jeux de données produites par l’homme sont de plus en plus complétés par d'autres données, massivement acquises de manière passive et automatique par un nombre croissant de capteurs électroniques et sous des formes de plus en plus interopérables et compréhensibles par les ordinateurs. Le volume de données stockées dans le monde fait plus que doubler tous les deux ans, et en migrant de plus en plus sur internet, les uns voient dans le big data intelligemment utilisé une source d’information qui permettrait de lutter contre la pauvreté, la criminalité ou la pollution. Et à l'autre extrémité du spectre des avis, d'autres, souvent défenseurs de la confidentialité de la vie privée, en ont une vision plus sombre, craignant ou affirmant que le big data est plutôt un Big Brother se présentant dans de « nouveaux habits »[103], « dans des vêtements de l’entreprise »[104].
En 2011 à l'occasion d'un bilan sur 10 ans d'Internet pour la société, Danah Boyd (de Microsoft Research) et Kate Crawford (University of New South Wales) dénonçaient de manière provocatrice six problèmes liés à des idées reçues sur le big data[105] : « L’automatisation de la recherche change la définition du savoir (…) Les revendications d’objectivité et d’exactitude sont trompeuses (…) De plus grosses données ne sont pas toujours de meilleures données (…) Toutes les données ne sont pas équivalentes (…) Accessible ne signifie pas éthique (…) L’accès limité aux big data crée de nouvelles fractures numériques »[42] entre les chercheurs ayant accès aux données de l'intérieur ou en payant ce droit d'accès[42].
Risques et problèmes
Plusieurs types de risques d'atteinte à la vie privée et aux droits fondamentaux sont cités par la littérature :
- Déshumanisation : dans ce que Bruce Schneier dénomme « l’âge d’or de la surveillance », la plupart des individus peuvent se sentir déshumanisés et ils ne peuvent plus protéger les données personnelles ou non qui les concernent, et qui sont collectées, analysées et vendues à leur insu. Alors qu'il devient difficile de se passer de carte bleue, de smartphone ou de consultation de l'internet, ils peuvent avoir le sentiment de ne pas pouvoir échapper à une surveillance constante où à des pressions visant à les faire consommer, voter, etc.
- Faille de sécurité informatique : dans un monde de plus en plus interconnecté et lié à l’Internet, la sécurité en ligne devient cruciale, pour la protection de la vie privée, mais aussi pour l'économie (ex. : en cas de problème grave, des risques existent de perte de confiance, concernant la sécurité des processus d’achat en ligne par exemple ; ils pourraient avoir des conséquences économiques importantes).
- « Vassalisation de la recherche scientifique par des sociétés commerciales et leurs services de marketing »[42].
- Apophénie (déductions indues)[42] : les biais d’accès et d’interprétation sont nombreux (« un corpus n’est pas plus scientifique ou objectif parce que l’on est en mesure d’aspirer toutes les données d’un site. D’autant qu’il existe de nombreux biais (techniques avec les API, mais aussi organisationnels) dans l’accès même à ces données qu’on aurait tort de considérer comme totales. Cet accès ne repose en effet que sur le bon vouloir de sociétés commerciales et sur les moyens financiers dont disposent chercheurs et universités) »[42] ;
De plus, un biais lié au genre existe : la grande majorité des chercheurs experts en informatique sont aujourd’hui des hommes, or des historiennes féministes et les philosophes des sciences ont montré que le sexe de celui qui pose les questions détermine souvent les questions qui seront posées[106]. - Mésinterprétation de certaines données liées à l'altérité, avec d'éventuelles conséquences sociopsychologiques, par exemple et de mauvaise compréhension ou interprétation de l’autre (« l’autre n’est pas une donnée » rappelle D. Pucheu[107]).
Un autre risque est celui d'une « raréfaction des occasions d’exposition des individus à des choses qui n’auraient pas été pré-vues pour eux, et donc un assèchement de l’espace public (comme espace de délibération, de formation de projets non rabattus sur la seule concurrence des intérêts individuels), ces choses non pré-vues, étant précisément constitutives du commun, ou de l’espace public »[108]. - Exacerbation de la fracture numérique, car les outils de data mining offrent à quelques entreprises un accès croissant et presque instantané à des milliards de données et de documents numérisés. Pour ceux qui savent utiliser ces données, et avec certaines limites, elles offrent aussi une certaine capacité à produire, trier ou distinguer des informations jugées stratégiques, permettant alors aussi de retenir ou au contraire de libérer avant d’autres certaines informations stratégiques[109]. Cet accès très privilégié et peu transparent à l'information peut favoriser des situations de conflits d'intérêt ou des délits d'initiés. Il existe un risque d'inégalités croissante face aux données et au pouvoir que l'on a sur elles : Manovich distingue ainsi 3 catégories d’acteurs, foncièrement inégaux face à la donnée : « ceux qui créent les données (que ce soit consciemment ou en laissant des traces numériques), ceux qui ont les moyens de les recueillir, et ceux qui ont la compétence de les analyser »(2011) .
Ces derniers sont en faible nombre, mais très privilégiés (ils sont souvent employés par les entreprises et autres entités du big data et ont donc le meilleur accès à la donnée; ils contribuent à produire ou orienter les règles qui vont les encadrer et cadrer l’exploitation des big data. Des inégalités institutionnelles sont a priori inéluctables mais elles peuvent être minimisées et devraient au moins être étudiées, car elles orientent les données et les types de recherches et applications qui en découleront. - Monopole exclusif ou commercial de certains jeux de mégadonnées collectées par quelques grandes entreprises (GAFA) ou par les outils publics ou secrets de grands États et leurs services de surveillance et collecte de données mondialisés(ex. : PRISM pour la NSA) visant à « capter le réel pour l'influencer »[20]) ; une énorme quantité de données est discrètement (et la plupart du temps légalement) collectée par des entreprises spécialisées ou des agences d’État ou de renseignement, dont les discussions et échanges, les comportements d’achat et les centres d’intérêt sur l’Internet de tous les groupes et d’individus. Ces données sont stockées, et parfois piratées (Ainsi, en 2003, lors d'une recherche de failles de sécurité la société Acxiom, l'un des principaux courtiers en données s'est rendu compte que 1,6 milliard d'enregistrements de consommateurs avaient été piratés via 137 attaques informatiques faites de janvier à juillet 2003 ; les informations volées incluaient des noms, adresses et des adresses e-mail de plusieurs millions d'Américains[110] - [111] - [112] - [113]). Ces données sont ensuite plus ou moins mises à jour, et éventuellement louées ou vendues pour le marketing et la publicité ciblée, des études scientifiques des organismes de sondage, des groupes d’influence ou des partis politiques (qui peuvent ainsi plus facilement contacter leurs électeurs potentiels), etc. Les personnes dont les données circulent ainsi n’en sont généralement pas informées, n’ont pas donné de consentement éclairé et peuvent difficilement vérifier ces données ou surtout les retirer des bases de données qui les conservent pour une durée potentiellement illimitée. Des risques de production d’erreur et de mauvais usages existent (dans le domaine des assurances et prêts bancaires par exemple). Jusqu'à 80 % des données personnelles mondiales seraient détenues par quatre grands acteurs américains du Web que sont les GAFA[114].
- Dérives éthiques, déjà constatées dans la partie grise ou sombre[115] de l’internet, y compris dans les grands réseaux sociaux (dont Facebook et Twitter, qui collectent un grand nombre de données et informations sur leurs utilisateurs et les réseaux dans lesquels ils s’inscrivent[116] - [117]) ; D’autres invitent à l’adoption de bonnes pratiques[118] et de règles éthiques plus strictes pour le data mining[119] et la gestion de ces mégadonnées[120] - [121].
Notamment depuis les révélations du lanceur d'alerte américain Edward Snowden[122], certains s’inquiètent de voir outre une surveillance de plus en plus invasive (voire pervasive[123]) de nos activités par les fournisseurs d’accès à Internet[124], puis fleurir des législations facilitant (sous prétexte de facilités économiques et/ou de sécurité nationale) l’usage d’outils de traçage (via les cartes de paiement, cartes de fidélité, cartes de santé, cartes de transport, cartes de pointage, les systèmes de videosurveillance, certains smartgrids ou outils domotiques, certains objets connectés géolocalisant leur propriétaire, etc.). Certaines de ces législations facilitent ou légitiment explicitement les écoutes électroniques (écoute et analyse de conversations téléphoniques ; interception et analyse d’emails et de réseaux) et le suivi général des activités sur le Net, ce qui leur semble être un contexte pouvant préparer une surveillance orweillienne généralisée des individus. Ces auteurs dénoncent l’apparition de processus et d’un contexte de plus en plus orweillien[23] intrinsèquement difficiles à contrôler, et insistent sur l’importance de la protection de la vie privée[125], « même quand on n'a rien à cacher »[126] - [127] ou (comme B. Schneier en 2008[128] ou Culnan & Williams en 2009[129]) rappellent que les notions de sécurité et de protection de la vie privée et d’autonomie de l’individu ne sont pas opposées. - Influence aux groupes de pressions des industriels qui participent au développement des techniques de captation et d'usage de multiples données en utilisant des concepts de ville intelligente et de ville sûre plus socialement acceptés.
- Cybersécurité : Les données d'une entreprise comptent parmi les actifs plus importants d'une entreprise, explique Lambert Sonna Momo en 2014[130]. Depuis, la question des données privées de tout à chacun, stockées de manière massive, fait régulièrement l'objet de débats sur les sujets d'éthique et de respect de la sphère privée.
Critiques
La Commissaire européenne à la Concurrence, Margrethe Vestager, a considéré auprès du Wall Street Journal que les grandes sociétés pouvaient utiliser des masses gigantesques de données d’utilisateurs pour entraver la concurrence[131].
Dans un rapport du CIB (Comité International de Bioéthique) sur les mégadonnées et la santé, publié en 2015, il mentionne que « L’enthousiasme suscité par le phénomène des mégadonnées risque d’entraîner des suréstimations et des prévisions irréalistes »[132]. Cela peut « mener à un déséquilibre des priorités en termes de politiques de santé, notamment dans les pays où l'accès à ces services essentiels n'est pas garanti ». En conclusion de la proposition 45, le CIB précise qu'« Il est par conséquent essentiel de gérer avec bon sens l’optimisme suscité par ce phénomène ».
Gouvernance et mégadonnées
La gouvernance des données peut se faire au niveau des entreprises, dans l'objectif de gérer efficacement leurs données; et aussi des états, pour réguler le bon usage des données. Elle nécessite un débat citoyen constant[133] ainsi que des modes de gouvernance et de surveillance adaptés[134] car des États, des groupes ou des entreprises ayant des accès privilégiés au big data peuvent en extraire très rapidement un grand nombre de « données personnelles diffuses » qui, par croisement et analyse, permettent un profilage de plus en plus précis, intrusif et parfois illégal (faisant fi de la protection de la vie privée) des individus, des groupes, des entreprises, et en particulier de leur statut social, culturel, religieux ou professionnel (exemple du programme PRISM de la NSA), de leurs activités personnelles, leurs habitudes de déplacement, d’achat et de consommation, ou encore de leur santé. Cette question renvoie directement à la Déclaration Universelle des droits de l'Homme qui indique, dans l'article 12, que « Nul ne sera l'objet d'immixtions arbitraires dans sa vie privée, sa famille, son domicile ou sa correspondance, ni d'atteintes à son honneur et à sa réputation. Toute personne a droit à la protection de la loi contre de telles immixtions ou de telles atteintes »[135].« La montée des big data amène aussi de grandes responsabilités »[42]. En matière de santé publique notamment, des enjeux éthiques forts existent[136].
Sur la scène européenne, un nouveau règlement a été mis en place dans le courant de l'année 2015 : le RGPD ou GDPR (General Data Protection Regulation). Il s'agit d'un règlement qui modifie le cadre juridique relatif à la protection des données personnelles au sein de l’union européenne. Le RGPD rappelle que toute personne physique devrait avoir le contrôle de données à caractère personnel la concernant. Toute opération économique se doit, de plus, d'être transparente, le règlement en assure la sécurité juridique (article 13). Enfin la protection des données personnelles est garantie par ce nouveau règlement (article 17)[137].
Big data temps réel
Les plateformes big data sont conçues pour traiter une quantité de données massive, en revanche elles sont très rarement conçues pour traiter ces données en temps réel. Les nouveaux usages et les nouvelles technologies engendrent des données au quotidien et sans interruption, il est donc nécessaire de faire évoluer ces plateformes pour traiter les données temps réel afin de répondre aux exigences métiers qui demandent d’aller vers plus de réactivité et de personnalisation. C’est la raison pour laquelle les architectures lambda et kappa ont vu le jour. Ces architectures permettent de prendre en compte les flux de données temps réel pour répondre à ces nouvelles exigences[138].
Notes et références
- Prononciation en anglais standard retranscrite selon la norme API.
- [PDF] Commission générale de terminologie et de néologie, Journal officiel de la République française du [lire en ligne].
- « mégadonnées », Grand Dictionnaire terminologique, Office québécois de la langue française (consulté le ).
- (en) Andrea De Mauro, Marco Greco et Michele Grimaldi, « A formal definition of Big Data based on its essential features », Library Review, vol. 65, no 3, , p. 122–135 (ISSN 0024-2535, DOI 10.1108/LR-06-2015-0061, lire en ligne, consulté le )
- « Conférence : voyage au cœur du Big Data », sur CEA/Médiathèque, (consulté le )
- (en) Cukier, K., & Mayer-Schoenberger, V. (2013). Rise of Big Data: How it's Changing the Way We Think about the World, The. Foreign Aff., 92, 28.
- « Qu’est-ce que le Big Data ? », sur lebigdata.ma
- Les médias dans la moulinette du « big data », 6 janvier 2014, consulté 12 janvier 2014.
- Michel Cartier, « Le "Big Data" », sur 21e siècle
- (en)CSAIL Researchers to Teach MIT's First Online Professional Course on Big Data, Tackling the Challenges of Big Data, janvier 2014, consulté 2014-01-12
- Création au Collège de France d'une Chaire « Sciences des données » en 2018., college-de-france.fr.
- [PDF]Gouvernement français (2012) - Investissements d’avenir – Fonds national pour la société numérique, Appel à projets no 3 - Big Data.
- Big Data Paris, conférence-exposition, 20-21 mars 2012.
- (en) « The AI revolution in science », Science | AAAS, (lire en ligne, consulté le )
- Non accessible le 31 mars 2019, sur ibm.com
- Watters, Audrey, Visualize Big Data with Flowing Media, ReadWriteWeb. 15 avril 2010
- (en) The World’s Technological Capacity to Store, Communicate, and Compute Information tracking the global capacity of 60 analog and digital technologies during the period from 1986 to 2007
- (en) Gil Press, « A Very Short History Of Big Data », Forbes, (lire en ligne, consulté le )
- Gil Press (2013) « une très courte histoire du big data » Forbes.com, daté du 5 mai 2013,
- Tréguier, V. (2014). « Mondes de données et imaginaires: vers un monde cybernétique » et Résumé ; Library and information sciences. 2014, [PDF], 53 p.
- Borkar, V. R., Carey, M. J., & Li, C. (2012). Big data platforms: what's next?. XRDS: Crossroads, The ACM Magazine for Students, 19(1), 44-49
- (en) Che, D., Safran, M., & Peng, Z. (2013, January). From big data to big data mining: challenges, issues, and opportunities. In Database Systems for Advanced Applications (p. 1-15). Springer Berlin Heidelberg
- Larsen, K. (2009). Orwellian state of security. Infosecurity, 6(6), 16-19 (résumé)
- (en) Sanders, E. (2001). Firms renew assault on privacy rules. Los Angeles Times C, 1.
- Boeth R (1970). The Assault on Privacy: Snoops, Bugs, Wiretaps, Dossiers, Data Bann Banks, and Specters of 1984. Newsweek, Incorporated.
- Miller, A. R. (1971). The assault on privacy: computers, data banks, and dossiers. University of Michigan Press.
- Arthur Miller (1975) "Assault on privacy" ; Psychiatric Opinion ; Vol 12(1), janvier 1975, 6-14.
- (en)Christie, G. C. (1971). The Right to Privacy and the Freedom to Know: A Comment on Professor Miller's" The Assault on Privacy". University of Pennsylvania Law Review, 970-991.
- (en) Froomkin, A. M. (2000). The death of privacy ? ; Stanford Law Review, 1461-1543.
- (en) Ernst M.L & Schwartz, A.U (1962) Privacy: The right to be let alone. New York: Macmillan.
- Askland, A. (2006). What, Me Worry? The Multi-Front Assault on Privacy. St. Louis University Public Law Review, 25(33), et résumé
- Griffin, J. J. (1990). Monitoring of Electronic Mail in the Private Sector Workplace: An Electronic Assault on Employee Privacy Rights, The. Software LJ, 4, 493 (Griffin, J. J. (1990). Monitoring of Electronic Mail in the Private Sector Workplace: An Electronic Assault on Employee Privacy Rights, The. Software LJ, 4, 493. résumé]).
- Warren, S. D., & Brandeis, L. D. (1890). The right to privacy. Harvard law review, 193-220.
- « Big Data Paris - les 11 & 12 mars prochains au Palais des Congrès », sur Big Data Paris 2019 (consulté le ).
- (en) Michael Minelli, Michele Chambers et Ambiga Dhiraj, Big Data, Big Analytics : Emerging Business Intelligence and Analytic Trends for Today's Businesses, Wiley, (ISBN 978-1-118-14760-3)
- (en) « Application Delivery Strategies » [PDF], sur blogs.gartner.com,
- « Les 3 V du Big Data : Volume, Vitesse et Variété », JDN, (lire en ligne, consulté le )
- (en-US) « Big Data Analytics | IBM Analytics », sur 01.ibm.com (consulté le )
- « Lumière sur… les 6V du Big Data », sur e-marketing.fr (consulté le )
- « Le Big data et la règle des 5V », sur blogrecrutement.bpce.fr (consulté le )
- (en) Manovich L (2011) ‘Trending: The Promises and the Challenges of Big Social Data’, Debates in the Digital Humanities, ed M.K.Gold. The University of Minnesota Press, Minneapolis, MN.[15 juillet 2011].
- Big data : la nécessité d’un débat (traduction collaborative d’un essai de Danah boyd et Kate Crawford présentant “Six provocations au sujet du phénomène des big data”, présenté lors du Symposium sur les dynamiques de l’internet et de la société : “Une décennie avec Internet”, organisé par l’Oxford Internet Institute, le 21 septembre 2011), FING, Internet.Actu.Net
- « Étude IDC-EMC, « Extracting value from chaos » », sponsorisée par EMC Gartner, citée par Delphine Cuny sous le titre « "Big data" : la nouvelle révolution », Virginia Rometty, La tribune, no 42, 29 mars au 4 avril 2013, p. 4
- « Infographie: Le big bang du big data », sur Statista Infographies (consulté le )
- « The Big Data révolution », Le journal, CNRS, no 28, (lire en ligne).
- (en-US) Janet Wiener et Nathan Bronson, « Facebook’s Top Open Data Problems », sur Facebook Research, (consulté le )
- (en) Shaun de Witt, Richard Sinclair, Andrew Sansum et Michael Wilson, « Managing Large Data Volumes from Scientific Facilities », ERCIM News, (lire en ligne)
- « Big data : du concept à la mise en œuvre. Premiers bilans. », sur blog.dataraxy.com, (consulté le )
- (en) Lee Gomes, « Data Analysis Is Creating New Business Opportunities », MIT Technology Review, (lire en ligne, consulté le )
- Pierre Brunelle, Déchiffrer le big data, Simplement : Acquérir les outils pour agir, de la réflexion à l'usage. (French Edition), Sceaux, Pierre Brunelle, , 129 p. (ISBN 978-1-5394-0933-5), p. 12
- (en-US) « IBM Understanding Big Data 2017/12/13 15:54:47 », sur www14.software.ibm.com, (consulté le )
- http://www.afdit.fr/media/pdf/27%20sept%202013/AFDIT%20BIG%20DATA%20Pierre%20Delort.pdf#13
- (en-US) « le Blog ANDSI » DSI Big Data », sur andsi.fr (consulté le )
- Pierre Delort, « Big Data car Low-Density Data ? La faible densité en information comme facteur discriminant », lesechos.fr, (lire en ligne, consulté le )
- Delort, Le Big Data, Paris, Presses Universitaires de France, , 128 p. (ISBN 978-2-13-065211-3, lire en ligne)
- http://www.ujf-grenoble.fr/recherche/college-des-ecoles-doctorales/les-formations-proposees/du-calcul-parallele-au-massivement-parallele--1442974.htm?RH=UJF
- http://www.oracle.com/technetwork/topics/entarch/articles/oea-big-data-guide-1522052.pdf
- Thierry Lévy-Abégnoli, « Explosion des volumes de données : de nouvelles architectures s’imposent », ZDNet France, (lire en ligne, consulté le )
- http://www.fermigier.com/assets/pdf/bigdata-opensource.pdf
- « Conception et optimisation du Mobile Cloud Computing avec des plateformes virtuelles en réseau », sur lebigdata.ma,
- http://www.cs.ucsb.edu/~sudipto/edbt2011/CloudTutorialPart1.pptx
- https://www.hpc-lr.univ-montp2.fr/
- « Les supercalculateurs de Météo France », sur meteofrance.fr (consulté le )
- Alain Beuraud, « Le calcul intensif temps réel, un outil décisif pour la performance d’un service météorologique », sur https://jcad2019.sciencesconf.org
- (en) Michel Sumbul, « HDFS », sur http://whatsbigdata.be/hdfs, (consulté le )
- Voir Data virtualization (en).
- « Le Big Data dans la campagne présidentielle US », sur 123opendata.com (consulté le )
- Pierre Delort, « Big Data : un ADN utilisateur séquençable pour moins de 1000 $ », lesechos.fr, (lire en ligne, consulté le )
- « La sécurité se met résolument au «Big Data» », LeMagIT, (lire en ligne, consulté le )
- (en-US) « Big data : l’expérience client ultime ? », Tech Page One, (lire en ligne, consulté le )
- (en) « LHC Brochure, English version. A presentation of the largest and the most powerful particle accelerator in the world, the Large Hadron Collider (LHC), which started up in 2008. Its role, characteristics, technologies, etc. are explained for the general public. », CERN-Brochure-2010-006-Eng. LHC Brochure, English version., CERN (consulté le )
- (en) « LHC Guide, English version. A collection of facts and figures about the Large Hadron Collider (LHC) in the form of questions and answers », CERN-Brochure-2008-001-Eng. LHC Guide, English version., CERN (consulté le )
- (en) Geoff Brumfiel, « High-energy physics: Down the petabyte highway », Nature, vol. 469, , p. 282–83 (DOI 10.1038/469282a, lire en ligne).
- Data, data everywhere Information has gone from scarce to superabundant. That brings huge new benefits, says Kenneth Cukier (interviewed here)—but also big headaches, The Economist, publié 25 février 2010
- Delort Pierre (2014) ICCP Technology Foresight Forum "Harnessing data as a new source of growth: Big data analytics and policies, en ligne sur le site de l'OCDE, mis à jour 21 juillet 2014, PDF, 14 p
- Delort Pierre (2012), Big data, Association Nationale des DSI, PDF 12p
- (en) « NASA Goddard Introduces the NASA Center for Climate Simulation », sur nasa.gov (consulté le )
- Acclimatise (2017) Data philanthropy will drive climate resilient development ; Acclimatise News 27 novembre 2017 Development, Earth Observation & Climate Data
- Kirkpatrick, R. (2011). Data philanthropy: Public & private sector data Sharing for global resilience. UN Global Pulse, 16, 2011.
- Pawelke, A., & Tatevossian, A. R. (2013). Data philanthropy: Where are we now. United Nations Global Pulse Blog.
- Kshetri, N. (2014). The emerging role of Big Data in key development issues: Opportunities, challenges, and concerns. Big Data & Society, 1(2), 2053951714564227.
- (en) Taylor L (2016). The ethics of big data as a public good: which public ? Whose good ?. Phil. Trans. R. Soc. A, 374(2083), 2016012 résumé ; l'un des 15 thèmes traités par ‘The ethical impact of data science’ (2016).
- « Election américaine: «Big data», l'arme secrète d'Obama », sur 20minutes.fr (consulté le )
- « Le pouvoir du "Big data" : Obama premier Président élu grâce à sa maîtrise de traitement de données ? », sur Atlantico.fr (consulté le )
- « Dossier Big data (2/5) Barack Obama, premier président big data », sur InformatiqueNews.fr, (consulté le )
- The GovLab Index: The Data Universe, sur thegovlab.org, consulté le 31 mars 2019.
- (en) « Government IT News, Analysis, & Advice - InformationWeek », sur InformationWeek (consulté le ).
- 2012 Energy Summit sur le site de l'État de l'Utah
- http://www.innovation2030.org/fr/
- (en) « Data, data everywhere », The Economist, (lire en ligne, consulté le )
- Non trouvé le 31 mars 2019, sur bayesia.com
- (en) « When the Art Is Watching You », sur Wall Street Journal,
- Schiermeier, Quirin (2016) Germany enlists machine learning to boost renewables revolution ; Grids struggle to cope with erratic nature of wind and solar power, 13 juillet 2016.
- Development of innovative weather and power forecast models for the grid integration of weather dependent energy sources, EWeLiNE, consulté 2016-07-14
- Aurélie Dudezert, « Big Data : Mise en perspective et enjeux pour les entreprises », Ingénierie des Systèmes d’Information, (lire en ligne)
- Viktor Mayer-Schönberger, « La révolution Big Data », Politique étrangère, (lire en ligne)
- (en) Russom, Philip, « TDWI BEST PRACTICES REPORT Introduction to Big Data Analytics », TDWI Research, (lire en ligne)
- http://ercim-news.ercim.eu/images/stories/EN89/EN89-web.pdf.
- (en) Christian Gout, Zoé Lambert et Dominique Apprato, Data approximation : mathematical modelling and numerical simulations, Paris, EDP Sciences, , 168 p. (ISBN 978-2-7598-2367-3)
- Infographie - l’exploitation des données clients à l’ère du Big Data, blog MARKESS International
- M. Hilbert, Big data for development: From information-to knowledge societies. SSRN 2205145, 2013.
- Bruce Schneier on the Hidden Battles to Collect Your Data and Control Your World et partie 2 et transcriptions écrites (en anglais), Democracy Now » (consulté 8 mai 2015).
- Webb, M., & Caron, C. (2015). Les nouveaux habits de Big Brother. Relations, (776), 14-17.
- (en) The Age of Big Data, article de STEVE LOHRFEB. Publié le 11, 2012 par le New-York Times
- (en) Danah Boyd et Kate Crawford, « CRITICAL QUESTIONS FOR BIG DATA », Information, Communication & Society, vol. 15, no 5, , p. 662–679 (lire en ligne [PDF])
- Harding, S. (2010) « Feminism, science and the anti-Enlightenment critiques », in Women, knowledge and reality: explorations in feminist philosophy, eds A. Garry and M. Pearsall, Boston: Unwin Hyman, 298–320.
- Pucheu David, « L'altérité à l'épreuve de l'ubiquité informationnelle », Hermès, La Revue 1/2014 (no 68), p. 115-122 Lien vers Cairn Info
- Antoinette Rouvroy. (2014). "Des données sans personne: le fétichisme de la donnée à caractère personnel à l'épreuve de l'idéologie des big data" Contribution en marge de l'Étude annuelle du Conseil d'État. Le numérique et les droits et libertés fondamentaux. (résumé)
- Schneier, B. (2011). Secrets and lies: digital security in a networked world. John Wiley & Sons
- (en) « Acxiom Hacker Gets Prison Sentence », DMN, (lire en ligne, consulté le )
- Appeals court: Stiff prison sentence in Acxiom data theft case stands ; Snipermail owner Scott Levine was sentenced to eight years in prison, consulté 2015-05-08
- en anglais : largest ever invasion and theft of personal data
- (en) John Leyden, « Acxiom database hacker jailed for 8 years », The Register, (lire en ligne, consulté le )
- reportage diffusé par Canal+ « Big Data : les nouveaux devins ».
- Morozov, E. (2012). The net delusion: The dark side of Internet freedom ; What Comes After Internet Utopia?. PublicAffairs, juin 2012
- Raynes-Goldie, K. (2010). Aliases, creeping, and wall cleaning: Understanding privacy in the age of Facebook. First Monday, 15(1).
- Hull, G., Lipford, H. R., & Latulipe, C. (2011). Contextual gaps: Privacy issues on Facebook. Ethics and information technology, 13(4), 289-302
- What Big Data Needs
- Ethical issues in data mining
- Ethics of Big Data.
- Ethical Questions around Big Data
- Jean-Paul Deléage, « Avec Edward Snowden, l'homme sorti de l'ombre qui voulait éclairer le monde ! », Écologie & politique 1/2014 (No 48), p. 5-12 URL : http://www.cairn.info/revue-ecologie-et-politique-2014-1-page-5.htm. ; DOI : 10.3917/ecopo.048.0005
- Michael, M. G., & Michael, K. (2009). Uberveillance: microchipping people and the assault on privacy. Faculty of Informatics-Papers, 711
- Ohm, P. (2009). The rise and fall of invasive ISP surveillance. University of Illinois Law Review, 30 aout 2008
- Tene, O., & Polonetsky, J. (2012). « Big data for all: Privacy and user control in the age of analytics”. Nw. J. Tech. & Intell. Prop., 11, xxvii
- Solove, D. J. (2011). Why privacy matters even if you have ‘nothing to hide’. Chronicle of Higher Education, 15
- Solove, D. J. (2007). ['http://scholarship.law.gwu.edu/cgi/viewcontent.cgi?article=1159&context=faculty_publications I've Got Nothing to Hide' and Other Misunderstandings of Privacy]. San Diego law review, 44, 745.
- Schneier, B (2008). What our top spy doesn’t get: Security and privacy aren’t opposites. Wired. com.
- Culnan, M. J., & Williams, C. C. (2009). How ethics can enhance organizational privacy: lessons from the choicepoint and TJX data breaches. Mis Quarterly, 673-687 (résumé).
- Digital Business Africa, « Les données d’une entreprise comptent parmi les actifs les plus importants »,
- La commissaire en chef de la concurrence au sein de l'UE estime que les données massives affectent négativement la concurrence, sur developpez.com du 3 janvier 2018, consulté le 31 mars 2019.
- « Rapport du CIB sur les mégadonnées et la santé », rapport scientifique, (lire en ligne)
- Laurence Allard, Pierre Grosdemouge et Fred Pailler, « Big Data: la nécessité d’un débat », sur blog du Monde, .
- Maxime Ouellet, André Mondoux, Marc Ménard, Maude Bonenfant et Fabien Richert, "Big Data", gouvernance et surveillance, Montréal, Université du Québec à Montréal, , 65 p. (ISBN 978-2-920752-11-5, lire en ligne).
- « Déclaration universelle des droits de l'Homme », sur textes.justice.gouv.fr, .
- Vayena, E., Salathé, M., Madoff, L. C., & Brownstein, J.S. (2015). Ethical challenges of big data in public health. PLoS computational biology, 11(2), e1003904
- « RÈGLEMENT DU PARLEMENT EUROPÉEN ET DU CONSEIL du 27 avril 2016 relatif à la protection des personnes physiques à l'égard du traitement des données à caractère personnel et à la libre circulation de ces données », sur eur-lex.europa.eu, .
- « Architecture data temps réel, par où commencer ? », sur nexworld.fr, (consulté le )
Voir aussi
Articles connexes
Liens externes
- Notice dans un dictionnaire ou une encyclopédie généraliste :
- Ressource relative à la santé :
- Dossier sur la Big Data sur SAVOIRS-ENS les conférences de l'École normale supérieure.
- Le Big Data, c'est quoi ?, 5e épisode du documentaire d'Arte Do not track diffusé le 16 février 2016.
Bibliographie
- Big data Dossier spécial de la revue Pour la Science ; no 98 - Février - Mars 2018
- Le traitement BigData : du cloud computing à l'internet des objets Catalogue général de La Bibliothèque nationale de France ; n° FRBNF46933611 - Septembre - Octobre 2021