Science des données
La science des données est l'étude de l’extraction automatisée de connaissance à partir de grands ensembles de données[1] - [2].
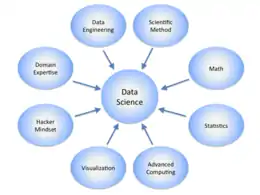
Plus précisément, la science des données est un domaine interdisciplinaire qui utilise des méthodes, des processus, des algorithmes et des systèmes scientifiques pour extraire des connaissances et des idées à partir de nombreuses données structurées ou non . Elle est souvent associée aux données massives et à l'analyse des données.
Elle utilise des techniques et des théories tirées de nombreux domaines dans le contexte des mathématiques, des statistiques, de l'informatique, de la théorie et des technologies de l'information, parmi lesquelles : l’apprentissage automatique, la compression de données et le calcul à haute performance.
Rôle de la science des données
La science des données produit des méthodes de tri et d’analyse de données de masse afin d’en extraire des informations utiles. Pour cela, elle se met en œuvre selon quatre étapes :
- La fouille,
- Le nettoyage/formatage,
- Le traitement :
- L'exploitation des résultats sous forme
- de tableaux de bord et d'outils d'aide à la décision,
- de la publication de résultats (interne à l'entreprise, ou publics)
Le spécialiste de science de données est donc souvent appelé à faire appel aux statistiques et au traitement du signal. Il s'attelle donc à la classification, au nettoyage, à l'exploration et à l'analyse de bases de données plus ou moins interopérables.
Histoire
Cette discipline est issue de l'apparition et du développement des bases de données et de l'Internet et répond aussi à la complexité croissante et au volume en croissance exponentielle du nombre de données numériques disponibles dans le monde (infobésité).
Elle a reçu beaucoup d'attention dernièrement grâce à l’intérêt grandissant pour les "données massives". Cependant, la science des données ne se limite pas à l’étude de bases de données pouvant être qualifiées de "données massives".
Par ailleurs, l'essor de techniques d’apprentissage automatique et d’intelligence artificielle a également participé à la croissance de cette discipline et à son ouverture vers de nouveaux champs en passant, par exemple, de l’analyse statistique pure de données fortement structurées à l’analyse de données semi-structurées (XML par exemple) pour notamment mettre « en correspondance des bases de données et de données textuelles »[3].
Impact sur la formation
Comme toute discipline, cette science nouvelle a naturellement engendré de nouvelles filières de formation[4].
En France
Cette science s’inscrit dans les efforts d’accompagnement du numérique, en lien depuis qu’elle existe avec la mission Etalab, dont le directeur, Henri Verdier, est aussi « administrateur général des données de l’État », assisté par des scientifiques de données recrutés pour « accélérer la possibilité de politiques publiques « augmentées » par les données et leur analyse ».
Domaines d'utilisation
Parmi les plus grands utilisateurs de la science des données figurent (par ordre alphabétique)
- Aéronautique
- Automobile[4]
- Agriculture[4]
- Assurance[4]
- Banque & finance, dont "Trading financier"[4]
- Distribution[4]
- Econométrie, économie
- Énergie[4]
- Géographie[5]
- Industrie manufacturière [4]
- Médias (ex : journalisme de données) & loisirs[4]
- Météorologie
- Moteurs de recherche
- Services (industrie des services)[4]
- Santé publique[4] (ex : épidémiologie, toxicologie, écotoxicologie...)
- TIC, télécommunications[4]
- Tourisme
- Transport
- Urbanisme, villes intelligentes, smartgrid
- Publicité
- commerce électronique
- Environnement
- Climat
Compétences métier
À ne pas confondre avec l’analyse métier et l’ingénierie des données, le scientifique de données va plus loin que l’analyste de données, notamment en utilisant l’apprentissage automatique. Un maître en science des données est quelqu'un qui peut utiliser un certain nombre de méthodes, d'outils et de technologies différents dans le traitement des données pour extraire des observations précieuses à partir de données confuses[6].
Pour cela, il doit être rigoureux, mais curieux et créatif, capable de trouver les données les plus adéquates pour une question et avoir une pensée structurée lui permettant de décomposer et organiser les questions et les processus[7].
Il doit savoir manipuler et nettoyer les données et les préparer dans un format adapté à l’analyse. Il doit aussi maitriser les sciences des données qui nécessitent une expertise pluridisciplinaire[7]. Son expertise recouvre les domaines scientifiques, méthodologiques, statistiques (maitrise des statistiques descriptives ; moyennes, médianes, variance, déviation, distributions de probabilités, échantillonnage, statistiques inférentielles, etc.), des outils d'ingénierie logicielle du domaine (ex. SAS, R), de l'algorithmique de l'apprentissage automatique, de l'apprentissage profond. Pour déduire des tendances prospectives probables et de bons modèles prédictifs, il peut également s'appuyer sur des bibliothèques (ex. TensorFlow, Keras, PyTorch). Évidemment, ces découvertes s'appuient autant sur les données du passé que du présent. Il doit maîtriser au moins un langage de programmation (Python, R, Java, Julia, Perl ou C/C++) et un langage de requête de base de données (SQL)[7]. Le scientifique de données doit aussi maîtriser les questions de régression et de classification, d'apprentissage supervisé ou non supervisé. Il doit aussi avoir de solides compétences en droit des données et une maitrise des aspects éthiques et sociaux, notamment concernant la confidentialité, l'anonymisation, la sécurité des données sensibles (données personnelles et de santé notamment)[7].
La maîtrise de la plateforme Hadoop, d'outils de traitement (ex. Hive, Pig...), d'outils d'infonuagique (ex Amazon S3) et la gestion de données non structurées (ex. données issues des réseaux sociaux, de flux vidéo ou audio) est un avantage et peut être requise par certains employeurs. Des notions d'intelligence artificielle sont de plus en plus requises (réseaux de neurones artificiels, etc.)[7]. In fine, le scientifique de données doit idéalement aussi être pédagogique, notamment par la maîtrise de la visualisation de données, et il doit être en mesure de déployer les modèles d'apprentissage automatique qu'il a mis au point (c'est-à-dire les rendre utilisables par des non-spécialistes)[7]. En rendant les modèles utilisables par les non spécialistes, le scientifique de données crée un « produit de données » (Data product). Celui-ci peut être une application sur un portable ou une application web. Les utilisateurs de R développent généralement leurs produits de données sur Shiny.
Selon Le Big Data 88 % des scientifiques de données ont au moins une maitrise (master) et 46 % un doctorat. Parmi ces scientifiques de données, 32 % proviennent du domaine des mathématiques et des statistiques, 19 % des sciences informatiques et 16 % d'écoles d’ingénieurs[7].
Selon le classement des 25 ou 50 « meilleurs » métiers du monde fait aux États-Unis par le site de recherche d’emploi Glassdoor, celui de Data Scientist arrivait en tête, devant les « ingénieurs DevOps » et les « Data Technicians »[7].
Évolutions attendues du métier
Gartner Inc. estime que plus de 40 % des tâches du scientifique des données seront rapidement automatisées (avant 2020), ce qui devrait favoriser une augmentation de leur productivité, mais aussi l’apparition de « citoyens scientifiques de données » (citizen data scientists en anglais) et d’approches collaboratives (ex. Wikidata, Wikipédia).
Des questions éthiques et de démocratie se posent avec les vols massifs de données personnelles ou les usages manipulateurs de données. Un exemple d'usage qui pose des questions éthiques et qui peut influencer la démocratie est celui du scandale de Facebook et Cambridge Analytica/AggregateIQ. Un usage douteux, voire illégal, de données massives d'utilisateurs de réseaux sociaux a été utilisé au profit de quelques candidats (ex. Donald Trump en contexte d’élections aux États-Unis) ou d’idéologies (ex. en faveur du parti du Brexit lors du référendum sur l’appartenance du Royaume-Uni à l’Union européenne). Des conséquences peuvent s’ensuivre, notamment dans le contexte du Brexit où le Royaume-Uni a finalement quitté l’Union européenne.
Salaires
Selon Glassdoor, le salaire annuel d’un scientifique de données est en moyenne de 116 840 dollars et fin janvier Glassdoor estimait à 1 736 le nombre d’offres d’emploi. Le salaire annuel moyen d’un scientifique de données américain serait de 110 000 dollars, tandis qu’en France il serait entre 45 000 et 50 000 euros. Malgré l’apparition de nombreuses formations, les employeurs peinent encore à trouver des profils assez qualifiés[8].
Selon les plateformes de Freelance, le TJM (tarif journalier moyen) pour les "data Scientist" en freelancing se situe à 570 euros en moyenne pour les profils séniors et peut aller jusqu'à 1100 euros pour des projets d'envergure et complexes.
Notes et références
- (en) Vasant Dhar, « Data Science and Prediction », Communications of the ACM, no 12, , p. 64-73 (DOI 10.1145/2500499, lire en ligne).
- (en) « The key word in "Data Science" is not Data, it is Science », sur simplystats, (consulté le ).
- Stage Recherche-M2 : Mise en correspondance debases de données etdedonnées textuelles, encadré par Mathieu Roche (TETIS-Cirad & LIRMM, Montpellier) et Sophie Fortuno (TETIS-Cirad, Montpellier)
- Abiteboul, S., Bancilhon, F., Bourdoncle, F., Clemencon, S., De La Higuera, C., Saporta, G., & Soulié, F. F. (2014). L'émergence d'une nouvelle filière de formation:«d ata scientist s» (Doctoral dissertation, INRIA Saclay)
- « Data Science Blog », sur France Data Science Blog, (consulté le ).
- « Science des données », sur writingstatement.com
- +Bastien L, « Voici toutes les compétences nécessaires pour devenir Data Scientist », sur LeBigData.fr, (consulté le ).
- « Salaire Data Scientist : combien gagne un scientifique des données ? », sur Formation Data Science | DataScientest.com, (consulté le )
Voir aussi
Bibliographie
- (en) William Cleveland, « Data Science : An Action Plan for Expanding the Technical Areas of the Field of Statistics », International Statistical Review / Revue internationale de statistique, vol. 69, , p. 21-26
- Serge Abiteboul, Sciences des données : De la logique du premier ordre à la Toile, Fayard, coll. « Collège de France », (lire en ligne)
- (en) Rachel Schutt et Cathy O'Neil, Doing Data Science : Straight Talk from the Frontline, O'Reilly Media, , 406 p. (ISBN 978-1-4493-5865-5)