Apprentissage non supervisé
Dans le domaine informatique et de l'intelligence artificielle, l'apprentissage non supervisé désigne la situation d'apprentissage automatique où les données ne sont pas étiquetées (par exemple étiquetées comme « balle » ou « poisson »). Il s'agit donc de découvrir les structures sous-jacentes à ces données non étiquetées. Puisque les données ne sont pas étiquetées, il est impossible à l'algorithme de calculer de façon certaine un score de réussite. Ainsi, les méthodes non supervisées présentent une auto-organisation qui capture les modèles comme des densités de probabilité ou, dans le cas des réseaux de neurones, comme combinaison de préférences de caractéristiques neuronales encodées dans les poids et les activations de la machine.
Les autres niveaux du spectre de supervision sont l'apprentissage par renforcement où la machine ne reçoit qu'un score de performance numérique comme guide, et l'apprentissage semi-supervisé où une petite partie des données est étiquetée.
L'introduction dans un système d'une approche d'apprentissage non supervisé est un moyen d'expérimenter l'intelligence artificielle. En général, des systèmes d'apprentissage non supervisé permettent d'exécuter des tâches plus complexes que les systèmes d'apprentissage supervisé, mais ils peuvent aussi être plus imprévisibles. Même si un système d'IA d'apprentissage non supervisé parvient tout seul, par exemple, à faire le tri entre des chats et des chiens, il peut aussi ajouter des catégories inattendues et non désirées, et classer des races inhabituelles, introduisant plus de bruit que d'ordre[1].
Apprentissage non supervisé et apprentissage supervisé
L'apprentissage non supervisé consiste à apprendre sans superviseur. Il s’agit d’extraire des classes ou groupes d’individus présentant des caractéristiques communes[2]. La qualité d'une méthode de classification est mesurée par sa capacité à découvrir certains ou tous les motifs cachés.
On distingue l'apprentissage supervisé et l'apprentissage non supervisé. Dans le premier apprentissage, il s’agit d’apprendre à classer un nouvel individu parmi un ensemble de classes prédéfinies : on connaît les classes a priori. À l'inverse, dans l'apprentissage non supervisé, le nombre et la définition des classes ne sont pas donnés a priori[3].
Exemple
Différence entre les deux types d'apprentissage.
Apprentissage supervisé
- On dispose d'éléments déjà classés
Exemple : articles en rubrique cuisine, sport, culture...
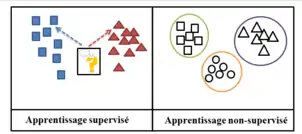
- On veut classer un nouvel élément
Exemple : lui attribuer un nom parmi cuisine, sport, culture...
Apprentissage non supervisé
- On dispose d'éléments non classés
Exemple : une fleur
- On veut les regrouper en classes
Exemple : si deux fleurs ont la même forme, elles sont en rapport avec une même plante correspondante.
Il existe deux principales méthodes d'apprentissage non supervisées[4] :
- Les méthodes par partitionnement telles que les algorithmes des k-moyennes ou k-médoïdes.
- Les méthodes de regroupement hiérarchique.
Utilisations
Les techniques d'apprentissage non supervisé peuvent être utilisées pour résoudre, entre autres, les problèmes suivants[5] :
- le partitionnement de données (par exemple avec l'algorithme des k-moyennes, le regroupement hiérarchique ou les auto-encodeur),
- l'estimation de densité de distribution (distribution de mélange, estimation par noyau),
- la réduction de dimension (analyse en composantes principales, carte auto-adaptative, analyse en composantes indépendantes)
L'apprentissage non supervisé peut aussi être utilisé en conjonction avec une inférence bayésienne pour produire des probabilités conditionnelles pour chaque variable aléatoire étant donné les autres.
Partitionnement de données
Le partitionnement de données, regroupement ou clustering est la technique la plus utilisée pour résoudre les problèmes d'apprentissage non supervisé. La mise en cluster consiste à séparer ou à diviser un ensemble de données en un certain nombre de groupes, de sorte que les ensembles de données appartenant aux mêmes groupes se ressemblent davantage que ceux d’autres groupes. En termes simples, l’objectif est de séparer les groupes ayant des traits similaires et de les assigner en grappes.
Voyons cela avec un exemple. Supposons que vous soyez le chef d’un magasin de location et que vous souhaitiez comprendre les préférences de vos clients pour développer votre activité. Vous pouvez regrouper tous vos clients en 10 groupes en fonction de leurs habitudes d’achat et utiliser une stratégie distincte pour les clients de chacun de ces 10 groupes. Et c’est ce que nous appelons le Clustering[6].
Méthodes
Le clustering consiste à grouper des points de données en fonction de leurs similitudes, tandis que l’association consiste à découvrir des relations entre les attributs de ces points de données:
Les techniques de clustering cherchent à décomposer un ensemble d'individus en plusieurs sous ensembles les plus homogènes possibles
- On ne connaît pas la classe des exemples (nombre, forme, taille)
- Les méthodes sont très nombreuses, typologies généralement employées pour les distinguer Méthodes de partitionnement / Méthodes hiérarchiques
- Avec recouvrement / sans recouvrement
- Autre : incrémental / non incrémental
- D'éventuelles informations sur les classes ou d'autres informations sur les données n'ont pas d'influence sur la formation des clusters, seulement sur leur interprétation[7].
L'un des algorithmes le plus connu et utilisé en clustering est la K-moyenne. Cet algorithme va mettre dans des “zones” (Cluster), les données qui se ressemblent. Les données se trouvant dans le même cluster sont similaires.
L’approche de K-Means consiste à affecter aléatoirement des centres de clusters (appelés centroids), et ensuite assigner chaque point de nos données au centroid qui lui est le plus proche. Cela s’effectue jusqu’à assigner toutes les données à un cluster[8].
Réseaux de neurones
Tâches vs méthodes
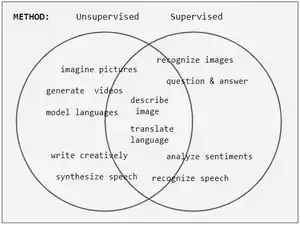
Les tâches du réseau de neurones sont souvent classées comme discriminatives (reconnaissance) ou génératives (imagination). Les tâches discriminatives utilisent souvent (mais pas toujours) des méthodes supervisées et les tâches génératives utilisent des méthodes non supervisées (voir diagramme de Venn); cependant, la séparation est très floue. Par exemple, la reconnaissance d'objets favorise l'apprentissage supervisé, mais l'apprentissage non supervisé peut également regrouper des objets en groupes. De plus, au fur et à mesure que des progrès, certaines tâches utilisent les deux méthodes, et certaines tâches oscillent de l'une à l'autre. Par exemple, la reconnaissance d'images a commencé comme étant fortement supervisée, mais est devenue hybride en employant un pré-entrainement non supervisée, puis est revenue à la supervision avec l'avènement de l'abandon, de ReLU et des taux d'apprentissage adaptatifs.
Apprentissage
Pendant la phase d'apprentissage, un réseau non supervisé essaie d'imiter les données qui lui sont fournies et utilise l'erreur dans sa sortie imitée pour se corriger (c'est-à-dire corriger ses poids et ses biais). Parfois, l'erreur est exprimée comme une faible probabilité que la sortie erronée se produise, ou elle peut être exprimée comme un état de haute énergie instable dans le réseau.
Contrairement à l'utilisation dominante de la rétropropagation par les méthodes supervisées, l'apprentissage non supervisé utilise également d'autres méthodes, notamment : la règle d'apprentissage de Hopfield, la règle d'apprentissage de Boltzmann, la divergence contrastive, le sommeil éveillé, l'inférence variationnelle, la vraisemblance maximale, le maximum A Posteriori, l'échantillonnage de Gibbs, et la rétropropagation des erreurs de reconstruction ou des reparamétrisations d'état caché. Voir le tableau ci-dessous pour plus de détails.
Énergie
Une fonction énergétique est une mesure macroscopique de l'état d'activation d'un réseau. Dans les machines Boltzmann, il joue le rôle de la fonction de coût. Cette analogie avec la physique est inspirée de l'analyse par Ludwig Boltzmann de l'énergie macroscopique d'un gaz à partir des probabilités microscopiques du mouvement des particules , où k est le Constante de Boltzmann et T est la température. Dans le réseau RBM, la relation est [9], où p & E varient sur chaque schéma d'activation possible et . Pour être plus précis, , où a est un modèle d'activation de tous les neurones (visibles et cachés). Par conséquent, les premiers réseaux de neurones portent le nom de Boltzmann Machine. Paul Smolensky appelle l'Harmonie. Un réseau cherche énergie basse qui correspond à une Harmonie haute.





Types de réseaux
Nous soulignons ici certaines caractéristiques de certains réseaux. Des détails sont également donnés dans le tableau comparatif ci-dessous. Au fur et à mesure que la conception des réseaux change, des fonctionnalités sont ajoutées pour activer de nouvelles fonctionnalités ou supprimées pour accélérer l'apprentissage. Par exemple, les neurones changent entre déterministe (Hopfield) et stochastique (Boltzmann) pour permettre une sortie robuste, les poids sont supprimés dans une couche (RBM) pour accélérer l'apprentissage, ou les connexions peuvent devenir asymétriques (Helmholtz). Les connexion symétriques permettent une formulation énergétique globale.
Notations
Un réseaux est composé de neurones, on note la matrice de connexion du réseau , l'énergie du réseaux .



| Publication | 1982[10] |
| Neurone | Neurone formel binaire
|
| Énergie | |
| Formation | avec :
|









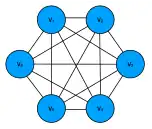
Un réseau basé sur des domaines magnétiques dans le fer avec une seule couche auto-connectée. Il peut être utilisé comme mémoire adressable par le contenu. Un neurone correspond à un domaine de fer avec des moments magnétiques binaires Up et Down, et les connexions neuronales correspondent à l'influence des domaines les uns sur les autres.
Un réseaux est composé de neurones binaires dont l'état ou pour le neurone . On apprend aux réseaux les motifs , . Pendant l'inférence, on présente au réseau des motifs appris mais incomplet ou bruité, le réseau met à jour chaque état en utilisant la fonction d'activation standard et conduit à un état appris.




Des poids symétriques et les bonnes fonctions d'énergie garantissent la convergence vers un modèle d'activation stable. Les poids asymétriques sont difficiles à analyser. Les réseaux Hopfield sont utilisés comme des mémoires adressables par le contenu (CAM).
Machine de Boltzmann
| Publication | 1975[11] |
| Neurone | Les probabilité d'activation sont données par :
avec : |
| Énergie | |
| Formation | minimiser la divergence KL avec :
|




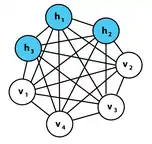
Un réseaux est composé de neurones stochastiques, d'état pour le neurone et dont la probabilité d'activation dépend des activations des autres neurones. Il est séparé en 2 couches (caché vs visible), mais utilise toujours des poids symétriques à 2 voies. Les neurones visibles reçoivent l'entrée qui sont des vecteurs aux valeurs binaires.

Leur valeur d'état est échantillonnée à partir de cette densité de probabilité comme suit : supposons qu'un neurone binaire se déclenche avec une probabilité de Bernoulli et se repose avec . On échantillonne dans ce dernier en prenant un nombre aléatoire uniformément distribué y, et en le plaçant dans la fonction de distribution cumulative inverse, qui dans ce cas est la fonction seuil à 2/3. La fonction inverse



Suivant la thermodynamique de Boltzmann, les probabilités individuelles donnent lieu à des énergies macroscopiques.
Machine de Boltzmann restreinte
| Publications | 1986[12], 2002[13] |
| Neurone | Les probabilité d'activation sont donnée par :
avec
|
| Énergie | |
| Formation | Algorithme de divergence contrastive:
où désigne des moyennes |










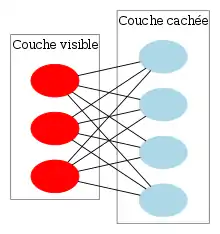
Il s'agit d'une machine Boltzmann où les connexions latérales au sein d'une couche sont interdites. On a donc à nouveau des neurones stochastiques, d'état pour le neurone de la couche visible et pour le neurone de la couche caché.


Le réseaux est entrainé pour maximiser produit des probabilité .

Les machines de Boltzmann "non restreintes" peuvent avoir des connexions entre les unités cachées. Cette restriction permet d'utiliser des algorithmes d'apprentissage plus efficaces que ceux disponibles pour la classe générale des machines de Boltzmann, en particulier l'algorithme de divergence contrastive basé sur le gradient
Réseau de croyance sigmoïde
| Énergie | |
| Formation | , pour +1/-1 neurone |

Introduit par Radford Neal en 1992, ce réseau applique les idées des modèles graphiques probabilistes aux réseaux neuronaux. La principale différence réside dans le fait que les nœuds des modèles graphiques ont des significations pré-attribuées, alors que les caractéristiques des neurones du Belief Net sont déterminées après la formation. Le réseau est un graphe acyclique dirigé faiblement connecté composé de neurones stochastiques binaires. La règle d'apprentissage provient du maximum de vraisemblance sur , où Les sont des activations provenant d'un échantillon non biaisé de la distribution postérieure, ce qui pose problème en raison du problème d'explication de l'éloignement soulevé par Judea Perl. Les méthodes bayésiennes variationnelles utilisent un postérieur de substitution et ignorent manifestement cette complexité.



Réseau de croyance profond et machine de Boltzman restreintes empilés
| Énergie | |
| Formation | divergence contrastive itérative en prenant
le précédent réseaux comme entrée |
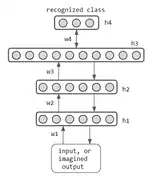
Introduit par Hinton, ce réseau est un hybride de RBM et de réseau de croyance sigmoïde. Les deux couches supérieures sont un RBM et la deuxième couche vers le bas forme un réseau de croyance sigmoïde. On l'entraîne par la méthode du RBM empilé, puis on jette les poids de reconnaissance sous le RBM supérieur. En 2009, 3-4 couches semblent être la profondeur optimale[14].
Ce réseau comporte plusieurs RBM pour coder une hiérarchie de caractéristiques cachées. Après la formation d'un seul RBM, une autre couche cachée bleue (voir RBM de gauche) est ajoutée, et les deux couches supérieures sont formées comme un RBM rouge et bleu.
Machine de Helmholtz
| Publication | 1995[15] |
| Énergie | |
| Formation | minimiser la divergence KL |
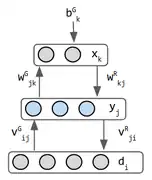
Au lieu de la connexion symétrique bidirectionnelle des machines Boltzmann empilées, nous avons des connexions unidirectionnelles séparées pour former une boucle. Il fait à la fois génération et discrimination.
Ce sont les premières inspirations des encodeurs automatiques variationnels. Il s'agit de 2 réseaux combinés en un seul - les poids vers l'avant opèrent la reconnaissance et les poids vers l'arrière mettent en œuvre l'imagination. C'est peut-être le premier réseau à faire les deux. Helmholtz n'a pas travaillé dans l'apprentissage automatique mais il a inspiré la vision d'un "moteur d'inférence statistique dont la fonction est d'inférer les causes probables des entrées sensorielles" (3). le neurone binaire stochastique génère une probabilité que son état soit 0 ou 1. L'entrée de données n'est normalement pas considérée comme une couche, mais dans le mode de génération de la machine Helmholtz, la couche de données reçoit l'entrée de la couche intermédiaire a des poids séparés à cet effet, donc il est considéré comme une couche. Ce réseau comporte donc 3 couches.
| Publication | 1991[16] |
| Énergie | |
| Formation | rétropropagation du gradient |
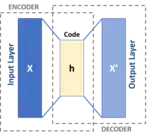
Un réseau feed-forward qui vise à trouver une bonne représentation de la couche intermédiaire de son monde d'entrée. Ce réseau est déterministe, il n'est donc pas aussi robuste que son successeur le VAE.
| Publication | 2016[17] |
| Inférence & énergie | minimiser l'erreur de reconstruction - minimiser la divergence KL |
| Formation | rétropropagation du gradient |
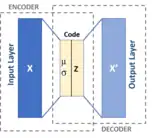
Applique l'inférence variationnelle à l'autoencodeur. La couche intermédiaire est un ensemble de moyennes et de variances pour les distributions gaussiennes. La nature stochastique permet une imagination plus robuste que l'auto-encodeur déterministe.
Celles-ci sont inspirées des machines de Helmholtz[18] et combinent un réseau de probabilité avec des réseaux de neurones. Un Autoencoder est un réseau CAM à 3 couches, où la couche intermédiaire est censée être une représentation interne des modèles d'entrée. Le réseau neuronal du codeur est une distribution de probabilité (z étant donné x) et le réseau du décodeur est (x étant donné z). Les poids sont nommés et plutôt que W et V comme dans Helmholtz - une différence cosmétique. Ces 2 réseaux ici peuvent être entièrement connectés ou utiliser un autre schéma NN.




Comparaison
Ce tableau présente des schémas de connexion de différents réseaux non supervisés.
| Hopfield | Boltzmann | RBM | Boltzmann empilé | Helmholz | Auto-encodeur | VAE | |
|---|---|---|---|---|---|---|---|
| Usage & notables | mémoires adressables par contenu, problème de voyageur de commerce | mémoires adressables par contenu | reconnaissance de formes. utilisé dans les chiffres et la parole : MNIST. | reconnaissance & imagination. pré-entrainement non supervisée et/ou réglage fin supervisé. | imagination, mimétisme | langue : écriture créative, traduction. vision : débruitage[19] | générer des données réalistes |
| Force | ressemble à des systèmes physiques donc il hérite de leurs équations | ← pareil. les neurones cachés agissent comme une représentation interne du monde extérieur | programme de formation pratique plus rapide que les machines Boltzmann | s'entraîne rapidement. donne une couche hiérarchique de fonctionnalités | légèrement anatomique. analysable avec la théorie de l'information et la mécanique statistique | ||
| Faiblesse | La liberté des connexions rend ce réseau difficile à analyser; difficile à former en raison des connexions latérales | l'équilibre nécessite trop d'itérations | les neurones entiers et à valeur réelle sont plus compliqués. |
Parmi les réseaux portant des noms de personnes, seul Hopfield travaillait directement avec les réseaux de neurones. Boltzmann et Helmholtz ont précédé les réseaux de neurones artificiels, mais leurs travaux en physique et physiologie ont inspiré les méthodes analytiques utilisées.
Historique
| 1969 | Perceptrons de Minsky & Papert montre qu'un perceptron sans couches cachées échoue sur XOR |
| années 1970 | (dates approximatives) Première hibernation de l'IA |
| 1974 | Modèle magnétique d'Ising proposé par WA Little pour la cognition |
| 1980 | Fukushima introduit le néocognitron, appelé plus tard réseau de neurones à convolution. Il est principalement utilisé dans SL, mais mérite une mention ici. |
| 1982 | Le réseau de Hopfield, une variante d'Ising est décrite comme CAM et classificateurs par John Hopfield. |
| 1983 | Machine de Boltzmann variante d'Ising avec neurones probabilistes décrite par Hinton & Sejnowski à la suite des travaux de Sherington & Kirkpatrick de 1975. |
| 1986 | Paul Smolensky publie Harmony Theory, qui est un RBM avec pratiquement la même fonction énergétique de Boltzmann. Smolensky n'a pas donné de programme de formation pratique. Hinton l'a fait au milieu des années 2000 |
| 1995 | Dayan & Hinton présente la machine Helmholtz |
| 1995-2005 | (dates approximatives) Deuxième hibernation de l'IA |
| 2013 | Kingma, Rezende, & co. introduit les auto-encodeurs variationnels en tant que réseau de probabilité graphique bayésien, avec des réseaux de neurones comme composants. |
Apprentissage Hebbien, ART, SOM
L'exemple classique d'apprentissage non supervisé dans l'étude des réseaux de neurones est le principe de Donald Hebb, c'est-à-dire que les neurones qui s'activent ensemble se connectent ensemble[20]. La règle de Hebb stipule que la connexion est renforcée indépendamment d'une erreur, mais est exclusivement en fonction de la coïncidence des potentiels d'action entre les deux neurones[21] - [22]. Une version similaire qui modifie les poids synaptiques prend en compte le temps entre les potentiels d'action (plasticité dépendante du moment du pic ou STDP). L'apprentissage hebbien a été supposé sous-tendre une gamme de fonctions cognitives, telles que la reconnaissance de formes et l'apprentissage expérientiel.
Parmi les modèles de réseau de neurones, la carte autoadaptative (SOM) et la théorie de la résonance adaptative (ART) sont couramment utilisées dans les algorithmes d'apprentissage non supervisé. Le SOM est une organisation topographique dans laquelle les emplacements proches sur la carte représentent des entrées avec des propriétés similaires. Le modèle ART permet au nombre de clusters de varier en fonction de la taille du problème et permet à l'utilisateur de contrôler le degré de similitude entre les membres des mêmes clusters au moyen d'une constante définie par l'utilisateur appelée paramètre de vigilance. Les réseaux ART sont utilisés pour de nombreuses tâches de reconnaissance de formes, telles que la reconnaissance automatique de cibles et le traitement des signaux sismiques[22].
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Unsupervised learning » (voir la liste des auteurs).
- « Apprentissage non supervisé »
- Guillaume Cleuziou, Une méthode de classification non-supervisée pour l’apprentissage de règles et la recherche d’information, (lire en ligne)
- « Classification »
- Pierre-Louis GONZALEZ, MÉTHODES DE CLASSIFICATION, Cnam,
- Zakariyaa ISMAILI, « Apprentissage Supervisé Vs. Non Supervisé », sur BrightCape, (consulté le )
- « Apprentissage Supervisé Vs. Non Supervisé », sur Le DataScientist, (consulté le )
- « Apprentissage non supervisé »
- « L’apprentissage non supervisé – Machine Learning »
- (en) G. Hinton, « A Practical Guide to Training Restricted Boltzmann Machines », dans Neural Networks: Tricks of the Trade, vol. 7700, Springer, (ISBN 978-3-642-35289-8, DOI 10.1007/978-3-642-35289-8_32, lire en ligne [PDF]).
- (en) J J Hopfield, « Neural networks and physical systems with emergent collective computational abilities. », Proceedings of the National Academy of Sciences, vol. 79, no 8, , p. 2554–2558 (ISSN 0027-8424 et 1091-6490, PMID 6953413, PMCID PMC346238, DOI 10.1073/pnas.79.8.2554, lire en ligne, consulté le )
- David Sherrington et Scott Kirkpatrick, « Solvable Model of a Spin-Glass », Physical Review Letters, vol. 35, no 26, , p. 1792–1796 (DOI 10.1103/PhysRevLett.35.1792, lire en ligne, consulté le )
- James L. McClelland et San Diego. PDP Research Group University of California, Parallel distributed processing : explorations in the microstructure of cognition, MIT Press, (ISBN 0-262-18120-7, 978-0-262-18120-4 et 0-262-13218-4, OCLC 12837549, lire en ligne)
- (en) Geoffrey E. Hinton, « Training Products of Experts by Minimizing Contrastive Divergence », Neural Computation, vol. 14, no 8, , p. 1771–1800 (ISSN 0899-7667 et 1530-888X, DOI 10.1162/089976602760128018, lire en ligne, consulté le )
- (en) Hinton, Geoffrey, « Deep Belief Nets », Vidéo,
- (en) Peter Dayan, Geoffrey E. Hinton, Radford M. Neal et Richard S. Zemel, « The Helmholtz Machine », Neural Computation, vol. 7, no 5, , p. 889–904 (ISSN 0899-7667 et 1530-888X, DOI 10.1162/neco.1995.7.5.889, lire en ligne, consulté le )
- (en) Mark A. Kramer, « Nonlinear principal component analysis using autoassociative neural networks », AIChE Journal, vol. 37, no 2, , p. 233–243 (ISSN 0001-1541 et 1547-5905, DOI 10.1002/aic.690370209, lire en ligne, consulté le )
- Nat Dilokthanakul, Pedro A. M. Mediano, Marta Garnelo et Matthew C. H. Lee, « Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders », arXiv:1611.02648 [cs, stat], (lire en ligne, consulté le )
- (en) « Neural Variational Inference: Variational Autoencoders and Helmholtz machines - B.log », sur artem.sobolev.name (consulté le )
- (en) Pascal Vincent, Hugo Larochelle, Yoshua Bengio et Pierre-Antoine Manzagol, « Extracting and composing robust features with denoising autoencoders », Proceedings of the 25th international conference on Machine learning - ICML '08, ACM Press, , p. 1096–1103 (ISBN 978-1-60558-205-4, DOI 10.1145/1390156.1390294, lire en ligne, consulté le )
- (en) J. Buhmann et H. Kuhneln, « [Proceedings 1992] IJCNN International Joint Conference on Neural Networks », dans Unsupervised and supervised data clustering with competitive neural networks, vol. 4, IEEE, (ISBN 0780305590, DOI 10.1109/ijcnn.1992.227220, S2CID 62651220), p. 796–801
- (en) Alberto Comesaña-Campos et José Benito Bouza-Rodríguez, « An application of Hebbian learning in the design process decision-making », Journal of Intelligent Manufacturing, vol. 27, no 3, , p. 487–506 (ISSN 0956-5515, DOI 10.1007/s10845-014-0881-z, S2CID 207171436, lire en ligne).
- (en) Carpenter, G.A. et Grossberg, S., « The ART of adaptive pattern recognition by a self-organizing neural network », Computer, vol. 21, no 3, , p. 77–88 (DOI 10.1109/2.33, S2CID 14625094, lire en ligne)
Voir aussi
Articles connexes
- Réseau de neurones
- Partitionnement de données
- Algorithme espérance-maximisation
- Carte auto adaptative
- Intelligence artificielle
- Extraction de connaissances
- Méthode des nuées dynamiques
- Regroupement hiérarchique
- Algorithme EM
- Analyse en composantes principales
- Régression logistique
- Algorithme des k-moyennes