K-moyennes
Le partitionnement en k-moyennes (ou k-means en anglais) est une méthode de partitionnement de données et un problème d'optimisation combinatoire. Étant donnés des points et un entier k, le problème est de diviser les points en k groupes, souvent appelés clusters, de façon à minimiser une certaine fonction. On considère la distance d'un point à la moyenne des points de son cluster ; la fonction à minimiser est la somme des carrés de ces distances.
| Type |
Algorithme de partitionnement de données (d), partitionnement de données |
|---|
Il existe une heuristique classique pour ce problème, souvent appelée méthodes des k-moyennes, utilisée pour la plupart des applications. Le problème est aussi étudié comme un problème d'optimisation classique, avec par exemple des algorithmes d'approximation.
Les k-moyennes sont notamment utilisées en apprentissage non supervisé où l'on divise des observations en k partitions. Les nuées dynamiques sont une généralisation de ce principe, pour laquelle chaque partition est représentée par un noyau pouvant être plus complexe qu'une moyenne. Un algorithme classique de k-means est le même que l'algorithme de quantification de Lloyd-Max.
Définition
Étant donné un ensemble de points (x1, x2, …, xn), on cherche à partitionner les n points en k ensembles S = {S1, S2, …, Sk} (k ≤ n) en minimisant la distance entre les points à l'intérieur de chaque partition :

où μi est le barycentre des points dans Si.
Historique
Le terme « k-means » a été utilisé pour la première fois par James MacQueen en 1967[1], bien que l'idée originale ait été proposée par Hugo Steinhaus en 1957[2]. L'algorithme classique a été proposé par Stuart Lloyd en 1957 à des fins de modulation par impulsions et codage, mais il n'a pas été publié en dehors des Laboratoires Bell avant 1982[3]. En 1965, E. W. Forgy publia une méthode essentiellement similaire, raison pour laquelle elle est parfois appelée « méthode de Lloyd-Forgy »[4]. Une version plus efficace, codée en Fortran, a été publiée par Hartigan et Wong en 1975/1979[5] - [6].
Algorithme classique
Il existe un algorithme classique pour le problème, parfois appelé méthode des k-moyennes, très utilisé en pratique et considéré comme efficace bien que ne garantissant ni l'optimalité, ni un temps de calcul polynomial[7].
Description
- Choisir k points qui représentent la position moyenne des partitions m1(1), …, mk(1) initiales (au hasard par exemple) ;
- Répéter jusqu'à ce qu'il y ait convergence :
- – affecter chaque observation à la partition la plus proche (c.-à-d. effectuer une partition de Voronoï selon les moyennes) :
- ,
- – mettre à jour la moyenne de chaque cluster :
- .


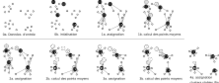
Initialisation
On commence par choisir une valeur pour k ; il est possible d'estimer une valeur pertinente à partir des partitions existantes dans les données[8].
Une fois le nombre k de valeurs choisi, on procède à leur initialisation. L'initialisation est un facteur déterminant dans la qualité des résultats (minimum local). De nombreux travaux traitent ce point. Il existe deux méthodes d'initialisation habituelles: la méthode de Forgy d'une part et le partitionnement aléatoire d'autre part. La méthode de Forgy affecte les k points des moyennes initiales à k données d'entrée choisies aléatoirement. Le partitionnement aléatoire affecte aléatoirement un cluster à chaque donnée et procède ensuite au (avant-premier) calcul des points de moyennes initiales.
K-moyennes++[9] est un algorithme d’initialisation des k points qui propose une initialisation améliorant la probabilité d'obtenir la solution optimale (minimum global). L'intuition derrière cette approche consiste à répartir les k points des moyennes initiales. Le point de moyenne initial du premier cluster est choisi aléatoirement parmi les données. Puis chaque point de moyenne initiale est choisi parmi les points restants, avec une probabilité proportionnelle au carré de la distance entre le point et le cluster le plus proche.
Analyse
Il y a un nombre fini de partitions possibles à k classes[10]. De plus, chaque étape de l'algorithme fait strictement diminuer la fonction de coût, positive, et fait découvrir une meilleure partition. Cela permet d'affirmer que l'algorithme converge toujours en temps fini, c'est-à-dire termine.
Le partitionnement final n'est pas toujours optimal. De plus le temps de calcul peut être exponentiel en le nombre de points, même dans le plan[11]. Dans la pratique, il est possible d'imposer une limite sur le nombre d’itérations ou un critère sur l'amélioration entre itérations.
À k fixé, la complexité lisse est polynomiale pour certaines configurations, dont des points dans un espace euclidien[7] et le cas de la divergence de Kullback-Leibler[12]. Si k fait partie de l'entrée, la complexité lisse est encore polynomiale pour le cas euclidien[13]. Ces résultats expliquent en partie l'efficacité de l'algorithme en pratique.
Autres aspects algorithmiques
Le problème des k-moyennes est NP-difficile dans le cas général[14]. Dans le cas euclidien, il existe un algorithme d'approximation polynomial, de ratio 9, par recherche locale[15].
Applications
Avantages et inconvénients pour l'apprentissage
Un inconvénient possible des k-moyennes pour le partitionnement est que les clusters dépendent de l'initialisation et de la distance choisie.
Le fait de devoir choisir a priori le paramètre k peut être perçu comme un inconvénient ou un avantage. Dans le cas du calcul des sac de mots par exemple, cela permet de fixer exactement la taille du dictionnaire désiré. Au contraire, dans certains partitionnements de données, on préférera s'affranchir d'une telle contrainte.
Réduction du nombre de couleurs d'une image

L'algorithme des k-moyennes peut être utilisé pour réduire le nombre de couleurs d'une image sans que cela ne nuise trop à sa qualité[16]. L'espace de couleur du système RGB de codage des couleurs consiste essentiellement à représenter une couleur par trois nombres entiers compris entre 0 et 255 qui représentent les intensités respectives du rouge, du vert et du bleu dans la couleur à afficher. Cela donne 2563 couleurs possibles, soit environ 16 millions. L'œil humain non-entraîné peine à distinguer autant de couleurs et il est donc possible de remplacer deux couleurs proches par une seule sans grande perte de qualité ; ce peut être utile à des fins de compression ou pour permettre l'affichage optimal d'une image sur un écran ou une imprimante n'offrant pas une grande variété de couleurs.
L'algorithme des k-moyennes peut être utilisé pour réduire le nombre de couleurs (en) à seulement k couleurs. On initialise une liste de k couleurs puis chaque pixel de l'image est associé à celle des k couleurs dont il est le plus proche. La couleur de tous les pixels d'une catégorie est alors remplacée par la moyenne de leurs couleurs[16]. Le partitionnement des pixels puis le remplacement de leur couleur par une couleur moyenne est itéré jusqu'à ce que l'image ne soit plus modifiée par le procédé[16]. L'utilisation des k-moyennes pour cette application a été longtemps considérée comme peu efficace, mais il a été avancé que l'algorithme pouvait être implémenté de façon efficace[17].
Les paramètres qui influent sur le résultat sont[16]:
- la valeur de k ;
- le choix d'initialisation des couleurs ;
- l'arrêt éventuel de l'exécution avant que les couleurs ne soient complètement stabilisées.
Nombre d'itérations
La complexité de l'algorithme des k-moyennes est linéaire en le nombre d'itérations des partitionnements et des moyennes. Cependant le nombre d'itérations à effectuer avant la convergence de l'image, bien que généralement bas, peut être très élevé dans le pire des cas. L'influence des dernières itérations peuvent cependant ne pas engendrer de grandes différences de rendu.
- Évolution d'une image réduite à 15 couleurs au fil des itérations de l'algorithme.
 Initialisation avec couleurs aléatoires.
Initialisation avec couleurs aléatoires. Fin de l'itération 1.
Fin de l'itération 1. Fin de l'itération 2.
Fin de l'itération 2. Fin de l'itération 3.
Fin de l'itération 3. Fin de l'itération 4.
Fin de l'itération 4. Fin de l'itération 5.
Fin de l'itération 5. Résultat final (itération 48).
Résultat final (itération 48).
Choix d'initialisation des couleurs
L'exécution de l'algorithme des k-moyennes dépend du choix d'initialisation des k couleurs qui servent à effectuer la première partition. Deux initialisations différentes peuvent en effet donner deux résultats différents dont la proximité n'est en théorie pas garantie. En pratique cependant deux exécutions initialisées différemment donneront généralement un résultat proche.
|
|


Choix du nombre de couleurs
Le choix de la valeur de k résulte généralement d'un compromis entre d'une part le fait de ne pas avoir de couleurs superflues et d'autre part le fait de limiter la baisse de qualité de l'image. Dans la pratique, on choisit généralement k de telle sorte qu'une valeur plus petite diminuerait sensiblement la qualité de l'image tandis qu'une valeur plus grande ne l'améliorerait que peu[16].
Ainsi l'exemple ci-dessous montre qu'en dessous de 10 couleurs, changer la valeur de k modifie grandement le rendu final tandis que l'on n'observe que peu de variations lorsque k est au-delà de 15. Un bon compromis se situerait donc pour k entre 10 et 15.
- Différence de rendu suivant le nombre k de couleurs à réduire.
 2 couleurs.
2 couleurs.
(17 itérations) 5 couleurs.
5 couleurs.
(42 itérations) 10 couleurs.
10 couleurs.
(48 itérations)- 15 couleurs.
(48 itérations)  20 couleurs.
20 couleurs.
(79 itérations) 25 couleurs.
25 couleurs.
(144 itérations) 100 couleurs.
100 couleurs.
(295 itérations)
Notes et références
- (en) J. B. MacQueen « Some Methods for classification and Analysis of Multivariate Observations » () (MR 0214227, zbMATH 0214.46201, lire en ligne, consulté le )
— « (ibid.) », dans Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability, vol. 1, University of California Press, p. 281–297 - H. Steinhaus, « Sur la division des corps matériels en parties », Bull. Acad. Polon. Sci., vol. 4, no 12, , p. 801–804 (MR 0090073, zbMATH 0079.16403).
- (en) S. P. Lloyd, « Least square quantization in PCM », Bell Telephone Laboratories Paper, Rendu public beaucoup plus tard: dans une revue : (en) S. P. Lloyd., « Least squares quantization in PCM », IEEE Transactions on Information Theory, vol. 28, no 2, , p. 129–137 (DOI 10.1109/TIT.1982.1056489, lire en ligne, consulté le ).
- (en) E.W. Forgy, « Cluster analysis of multivariate data: efficiency versus interpretability of classifications », Biometrics, vol. 21, , p. 768–769 (JSTOR 2528559).
- (en) J. A. Hartigan, Clustering algorithms, John Wiley & Sons, Inc., .
- (en) J. A. Hartigan et M. A. Wong, « Algorithm AS 136: A K-Means Clustering Algorithm », Journal of the Royal Statistical Society, Series C, vol. 28, no 1, , p. 100–108 (JSTOR 2346830).
- (en) David Arthur et Sergei Vassilvitskii, « Worst-Case and Smoothed Analysis of the ICP Algorithm, with an Application to the k-Means Method », SIAM J. Comput., vol. 39, no 2, , p. 766-782.
- (en) Le Hong Trang, Nguyen Phan Dang Khoa et Nguyen Minh Khoi, « Automatically Finding the Number of Clusters for Large Datasets based on Coresets », Proceedings of the 2020 4th International Conference on Big Data and Internet of Things, Association for Computing Machinery, bDIOT '20, , p. 1–6 (ISBN 978-1-4503-7550-4, DOI 10.1145/3421537.3421538)
- (en) Arthur, David et Vassilvitskii, Sergei, « k-means++: the advantages of careful seeding », ACM-SIAM symposium on Discrete algorithms, (lire en ligne).
- Voir Nombre de Stirling pour plus de détails.
- (en) Andrea Vattani, « k-means Requires Exponentially Many Iterations Even in the Plane », Discrete & Computational Geometry, vol. 45, no 4, , p. 596-616
- (en) Bodo Manthey et Heiko Röglin, « Worst-Case and Smoothed Analysis of k-Means Clustering with Bregman Divergences », JoCG, vol. 4, no 1, , p. 94-132.
- (en) David Arthur, Bodo Manthey et Heiko Röglin, « Smoothed Analysis of the k-Means Method », Journal of the ACM, vol. 58, no 5, , p. 19 (lire en ligne)
- (en) Sanjoy Dasgupta, « The Hardness of Kmeans Clustering » (Technical Report CS2008-06), sur Department of Computer Science and Engineering, University of California, San Diego
- (en) Tapas Kanungo, David M. Mount, Nathan S. Netanyahu, Christine D. Piatko, Ruth Silverman et Angela Y. Wu, « A local search approximation algorithm for k-means clustering », Comput. Geom., vol. 28, nos 2-3, , p. 89-112 (lire en ligne)
- Joël Grus (trad. de l'anglais), Data Science par la pratique : Fondamentaux avec Python [« Data Science from Scratch »], Eyrolles, , 2e éd. (1re éd. 2017), 385 p. (ISBN 978-2212679076), chap. 20 (« Partitionnement de données »).
- (en) Celebi, M. E., « Improving the performance of k-means for color quantization », Image and Vision Computing, vol. 29, no 4, , p. 260–271 (DOI 10.1016/j.imavis.2010.10.002, Bibcode 2011arXiv1101.0395E, arXiv 1101.0395, S2CID 9557537)
Voir aussi
Bibliographie
- (en) Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, Wiley-interscience, (ISBN 0-471-05669-3) [détail des éditions]