Analyse en composantes indépendantes
L'analyse en composantes indépendantes (en anglais, independent component analysis ou ICA) est une méthode d'analyse des données (voir aussi Exploration de données) qui relève des statistiques, des réseaux de neurones et du traitement du signal. Elle est notoirement et historiquement connue en tant que méthode de séparation aveugle de source mais a par suite été appliquée à divers problèmes. Les contributions principales ont été rassemblées dans un ouvrage édité en 2010 par P.Comon et C.Jutten[1].
Historique
La première formulation du problème de l'extraction d'entités primitives indépendantes mélangées dans des signaux composites a été effectuée dès 1984[2] par Jeanny Hérault et Bernard Ans, deux chercheurs en neurosciences et traitement du signal, pour modéliser sous la forme d'un réseau neuromimétique auto-adaptatif le codage et le décodage du mouvement chez l'humain[3]. Ces premiers travaux[2] - [4] - [5] ouvraient la voie à la formulation du problème de séparation de source aveugle[6]. Une communauté a émergé autour de cette thématique dans la seconde moitié des années 1980 essentiellement en France et en Finlande[7]. La communauté française du traitement du signal adopta un formalisme statistique tandis que les chercheurs finlandais visaient à étendre l'analyse en composantes principales au moyen d'un formalisme connexionniste. L'algorithme proposé en 1985 était étonnamment robuste mais les explications théoriques de ses propriétés étaient incomplètes. Un premier formalisme du problème de séparation de source aveugle, ainsi qu'un algorithme permettant d'en obtenir une solution, a été proposé par C. Jutten et J. Hérault en 1991[6]. La formalisation mathématique dans le cas le plus simple (mélange linéaire instantané) a été effectuée en 1994 par P. Comon[8] aboutissant au concept d' analyse en composantes indépendantes.
La recherche dans ce domaine devint très active à partir des années 1990 et des chercheurs du monde entier s'intéressèrent au problème. En plus des équipes européennes précédemment évoquées, des chercheurs américains et japonais s'intéressèrent au lien entre l'ACI et le codage neuronal. Il existe plusieurs ouvrages spécialisés donnant les détails de certaines solutions proposées[9], ainsi que les développements théoriques s'y rattachant.
Une conférence internationale portant spécifiquement sur le sujet existe depuis 1999. Devant avoir initialement lieu tous les 18 mois, elle est désormais annuelle. Les premières éditions ont eu lieu à Aussois (France, 1999), Helsinki (Finlande, 2000), San Diego (Californie, 2001), Nara (Japon, 2003), Grenade (Espagne, 2004), Charleston (Caroline du Sud, États-Unis, 2006), Londres (Royaume-Uni, 2007) et Paraty (Brésil, 2009).
Séparation de source (problème de la soirée cocktail)
L'illustration classique de la séparation de sources est le problème de la soirée cocktail (cocktail party problem). Lors d'une telle soirée, on dispose microphones dans une salle dense, où personnes discutent par groupes de tailles diverses. Chaque microphone enregistre la superposition des discours des personnes à ses alentours et le problème consiste à retrouver la voix de chaque personne (« débarrassée » des autres voix considérées comme parasites).



L'ACI permet de résoudre ce problème en considérant simplement que les personnes qui parlent à un instant donné ont des discours « indépendants ». Il ne s'agit pas de prendre en compte la sémantique de ces discours (on peut en effet espérer que certaines voix soient concordantes à ce niveau !) ni même l'acoustique (ce qui serait faux, ne serait-ce que lorsque les interlocuteurs ont des langues identiques...), mais de les considérer comme des signaux aléatoires statistiquement indépendants. Au contraire d'une chorale, les gens qui parlent en même temps à un instant donné émettent des sons indépendants.
La théorie assurant ce résultat pose néanmoins certaines hypothèses, en particulier que « le nombre de micros est supérieur ou égal au nombre de personnes ». Symétriquement, il reste aussi des indéterminations sur le résultat (les voix séparées). Celles-ci peuvent être interprétées de la façon suivante :
- on ne peut pas attribuer les voix aux personnes avec la seule connaissance des signaux retrouvés (mais un auditeur humain le pourrait). Autrement dit, on ne connaît pas l'ordre des signaux retrouvés.
- on ne connaît pas l'intensité de la voix des locuteurs. Celle-ci sera attribuée arbitrairement et un auditeur humain ne pourrait se fier qu'au ton de la voix et à la connaissance de la personne pour le déterminer.
Pour des raisons historiques et pédagogiques, l'ACI est souvent introduite comme permettant de résoudre le problème de séparation de sources. Néanmoins, il existe d'autres méthodes pour résoudre ce problème, ne faisant pas appel strictement à l'hypothèse d'indépendance statistique entre sources (la parcimonie par exemple).
Formalisme mathématique
Dans le cas le plus simple (modèle linéaire instantané non bruité), la théorie est très bien maîtrisée. Néanmoins, ce modèle de mélange semble souvent trop restrictif pour modéliser les cas pratiques. Les travaux sur les modèles de mélange plus complexes font l'objet de recherches actives à ce jour.
Modèle linéaire instantané non bruité[8]
Quand l'information mutuelle est choisie comme fonction de contraste particulière, l'analyse en composantes indépendantes du vecteur aléatoire revient à identifier le modèle génératif linéaire instantané non bruité suivant :


où les composantes du vecteur sont mutuellement indépendantes et la matrice est de taille fixe . Néanmoins, les conditions d'identifiabilité suivantes doivent être vérifiées pour que l'on soit assuré de pouvoir retrouver le modèle (théoriquement):




- au plus une des sources (composantes de ) peut suivre une distribution normale (gaussienne),
- le rang de la matrice doit être égal au nombre de sources (à retrouver).

La première condition résulte de la nullité des moments et cumulants d'ordres supérieurs à deux pour une distribution gaussienne. L'indépendance revient alors à une simple décorrélation et l'hypothèse d'indépendance statistique ne permet pas de séparer les sources gaussiennes. Il est cependant possible de retrouver les autres sources non gaussiennes.
La seconde condition impose d'observer au moins autant de données qu'il y a de sources à identifier. Les travaux sur les représentations parcimonieuses ont cependant montré qu'il était possible d'extraire plus de sources que d'observations disponibles. Réciproquement, il est toujours possible de réduire la dimension des observations disponibles, au moyen d'une analyse en composantes principales (ACP) par exemple.
Quand ces deux conditions d'identifiabilité sont vérifiées, il reste cependant deux indéterminations:
- Changer l'ordre des sources ne modifie pas leur indépendance mutuelle. En conséquence, les sources identifiées par ACI ne sont pas ordonnées (au contraire de l'ACP où les sources sont ordonnées selon les valeurs propres de la matrice de variance/covariance)
- L'indépendance statistique est conservée quand les composantes sont multipliées par une constante non nulle. Autrement dit, il y a une indétermination sur l'amplitude des sources.
Ces deux indéterminations ne sont pas propres au modèle linéaire instantané non bruité et se vérifient dans le cas général.
Modèle linéaire instantané bruité
Plus réaliste que le modèle précédent, cela revient à identifier le modèle suivant :

où est le bruit.

Modèle linéaire non instantané
Le mélange peut être convolutif. Néanmoins on peut alors se ramener à un modèle linéaire, en utilisant une transformée de Fourier par exemple.
Mélanges non linéaires
Il s'agit du cas le plus général où les observations résultent d'une transformation non linéaire des sources:

où est une fonction non linéaire quelconque. Nous ne connaissons pas de méthode générale dans ce cas. Certains auteurs ont néanmoins proposé des méthodes pour des cas particuliers. Il s'agit d'un domaine de recherche très actif. Dans le cas le plus général, le problème étant mal-posé la solution est loin d'être unique[10].

Principaux algorithmes
Le but de cette section est de donner les principales idées des algorithmes les plus connus permettant de résoudre le problème d'ACI. Ces algorithmes ont été choisis de manière à présenter un panel varié d'approches. On trouvera de nombreuses autres méthodes dans la littérature scientifique.
Nous considérons ici le modèle linéaire instantané non bruité[8] et cherchons une estimation des sources indépendantes ainsi qu'une matrice de séparation vérifiant :



Algorithme HJ
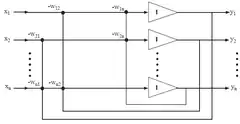
Le premier algorithme d'ACI (du nom de deux de ses auteurs[2] - [4] - [5] - [6]) procède d'une approche neuromimétique: il s'agit d'une utilisation des outils du traitement du signal pour modéliser un phénomène inspiré du fonctionnement neuronal. Cet algorithme était de type Robins-Monro, et recherchait itérativement des zéros communs de deux fonctions[11]. Il est basé sur un réseau de neurones récursif dont les poids sont les termes non diagonaux de la matrice de séparation , les termes diagonaux étant contraints à la nullité. L'estimation des sources est ainsi donnée par :

Avec la règle d'adaptation suivante pour les termes non diagonaux :

et étant des fonctions non linéaires impaires différentes à choisir en fonction des densités de probabilité des sources à estimer. Des travaux ultérieurs[12] ont justifié la forme de cette règle d'apprentissage et ont montré que la fonction non linéaire devait être choisie au sens du maximum de vraisemblance. La mesure d'indépendance sous-jacente à cet algorithme est l'annulation des cumulants d'ordre supérieur.


Maximisation de Contraste (CoM)
Cette famille d'algorithmes a été proposée par Comon en 1991. Ces algorithmes procèdent en balayant toutes les paires de sorties à tour de rôle. L'algorithme CoM peut calculer soit tous les cumulants des observations (comme JADE), soit à la demande, à chaque fois qu'une rotation optimale est calculée. Le choix peut être fait de manière à minimiser la complexité numérique.
Plusieurs versions ont été proposées, suivant le contraste utilisé. En 1991, il s'agissait par exemple de la somme des modules carrés des cumulants marginaux des sorties: ce contraste est maintenant appelé CoM2. Plus tard, un autre contraste, CoM1, a été proposé par Moreau: la somme des modules des cumulants marginaux des sorties. Lorsque les sources ont des cumulants marginaux toutes de même signe, il a été montré que la valeur absolue peut être retirée. Cette simplification a donné lieu à une autre solution algébrique compacte, développée par Comon.
D'autres formes plus générales de contraste basés sur les cumulants ont été ensuite proposées dans la littérature[13].
JADE
(Joint Approximate Diagonalization of Eigenmatrices)
Un tenseur de cumulants (à l'ordre quatre) est une matrice à quatre dimensions contenant tous les cumulants croisés d'ordre quatre. C'est aussi une application linéaire d'un espace de matrice de taille dans un autre espace de matrice de même taille. La diagonalisation de cette application linéaire permet d'effectuer la séparation voulue sous certaines conditions[14]. En effet, l'indépendance statistique est vue ici comme la recherche à tendre vers la nullité de tous les moments et cumulants (à tous les ordres), ce qui revient à annuler tous les éléments non diagonaux de la matrice associée à l'application linéaire sus-citée. Cardoso et Souloumiac ont proposé[15] une méthode de diagonalisation jointe permettant de mettre en pratique ce principe. Cela revient à minimiser la somme du carrés de tous les cumulants (à l'ordre quatre) « hors diagonale » (cumulant entre deux signaux différents). En pratique, JADE nécessite le calcul de tous les cumulants d'ordre quatre, et a donc une complexité en .


Fast-ICA
Hyvärinen et Oja proposent d'estimer les composantes indépendantes au moyen d'une mesure de « non gaussianité »[9]. En effet, le théorème central limite stipule que la somme de variables indépendantes tend asymptotiquement vers une distribution normale. Dans le cas considéré, les estimations sont une telle somme de variables indépendantes () et tendent donc vers une distribution gaussienne. En cherchant à maximiser la non gaussianité de , chacune de ses composantes tendra vers une estimation des sources indépendantes (aux deux indéterminations près). Plusieurs mesures de « non gaussianité » ont été proposées, la plus usitée étant la néguentropie qui est la différence entre l'entropie d'une variable gaussienne et l'entropie du vecteur mesuré. Hyvärinen a proposé différentes approximations de cette mesure permettant une mise en œuvre algorithmique du principe exposé.


Pour éviter que toutes les estimations convergent vers la même source, il est nécessaire d'imposer l'orthogonalité des (sous contrainte de blanchiment, cela revient à décorréler les données, au moyen d'une analyse en composantes principales par exemple). Deux méthodes existent pour imposer cette orthogonalité. La version dite « par déflation » estime itérativement les sources et orthogonalise chaque estimation au moyen d'un procédé de Gram-Schmidt. La version « symétrique » orthogonalise simultanément toutes les estimations.
« Fast-ICA » met ainsi en évidence de forts liens entre l'analyse en composantes indépendantes et la poursuite de projection.
Infomax
Formulé par Linsker[16], ce principe stipule que l'implémentation d'un modèle des capacités cognitives des mammifères au moyen d'un réseau de neurones artificiel doit être telle que le taux d'information transmis d'une couche de neurones à la suivante soit maximal. Ce taux d'information peut notamment être mesuré par l'entropie lorsque l'on se place dans le formalisme de Shannon.
Nadal et Parga ont montré[17] que sous certaines conditions, ce principe était équivalent au principe de réduction de redondance[18] qui énonce que le but des systèmes sensoriels des mammifères est de coder efficacement les stimuli (visuels, sonores...). En se plaçant à nouveau dans le formalisme de Shannon, cela revient à minimiser la redondance d'information de leur environnement et obtenir un codage factoriel (i.e un codage qui minimise les dépendances statistiques entre dimensions, aussi appelé codage à entropie minimale).
Bell et Sejnowsky ont exploité cette équivalence[19] en l'écrivant:

où est l'information mutuelle entre les sorties et les entrées d'un réseau de neurones, les paramètres de ce réseau et l'entropie des sorties. La relation ci-dessus exprime exactement que rendre maximale l'information mutuelle des sorties des réseaux (i.e obtenir un code factoriel le plus efficace possible) est identique à rendre maximale l'information qui « passe » à travers le réseau.





Ils en déduisirent une règle d'apprentissage des paramètres du réseau qui, après quelques simplifications et l'exploitation d'une règle du type « gradient relatif »[20], revient à :
![\Delta W=[I-Ktanh(y)y^{T}-yy^{T}]W](https://img.franco.wiki/i/807b75d1858d146385ea992a652f7f06c2602ff2.svg)
K étant une matrice diagonale dont les éléments valent 1 pour les sources sur-gaussiennes et -1 pour les sources sous-gaussiennes.
Il a été montré une équivalence de cette approche et de l'approche par maximum de vraisemblance.
Voir aussi
Liens externes
- (fr) Analyse en Composantes Indépendantes par J.-F Cardoso
- (fr) Analyse en Composantes Indépendantes État de l'art (2003)[21]
- (en) What is independent component analysis? by A. Hyvärinen
- (en) Tutoriel par Aapo Hyvärinen.
Références
- P.Comon, C.Jutten, Handbook of Blind Source Separation, Independent Component Analysis and Applications, Academic Press, 2010. (ISBN 978-0-12-374726-6)
- J. Hérault and B. Ans, "Réseau de neurones à synapses modifiables: décodage de messages sensoriels composites par apprentissage non supervisé et permanent", Comptes Rendus de l'Académie des Sciences Paris, série 3, 299: 525-528, 1984.
- B. Ans, J.-C. Gilhodes, and J. Hérault, "Simulation de réseaux neuronaux (SIRENE). II. Hypothèse de décodage du message de mouvement porté par les afférences fusoriales IA et II par un mécanisme de plasticité synaptique.", Comptes Rendus de l'Académie des Sciences Paris, série 3, 297: 419-422, 1983.
- B. Ans, J. Hérault, and C. Jutten, “Architectures neuromimétiques adaptatives : Détection de primitives”, in Actes du colloque Cognitiva 85, CESTA, vol. 2, Paris, 1985, pp. 593-597.
- J. Hérault, C. Jutten, and B. Ans, “Détection de grandeurs primitives dans un message composite par une architecture de calcul neuromimétique en apprentissage non supervisé”, in Actes du Xe colloque GRETSI, vol. 2, Nice, France, mai 1985, pp. 1017–1022.
- C. Jutten and H. Hérault, “Blind separation of sources, part i: an adaptative algorithm based on neuromimetic architecture”, Signal Processing, vol. 24, pp. 1–10, 1991.
- Jutten, Ch. and Taleb, A. Source separation: From dusk till dawn ICA 2000, pages 15-26 (invited paper), Helsinki, Finland, June 2000.
- P. Comon, “Independent component analysis - a new concept?” Signal Processing, vol. 36, no. 3, pp. 287–314, 1994.
- A. Hyvärinen, J. Karhunen, and E. Oja, “Independent Component Analysis”. John Wiley and Son, 2001
- C. Jutten and J. Karhunen, Advances in blind source separation (BSS) and independent component analysis (ICA) for nonlinear mixtures. International Journal of Neural Systems, Vol. 14, No. 5, 2004, pp. 267-292.
- P.Comon, C. Jutten and H. Hérault, “Blind separation of sources, part II: problem statement”, Signal Processing, vol. 24, pp. 11-20, 1991
- D.T. Pham, P. Garat. IEEE T Signal Processing, 45(7):1712-1725, 1997
- P. Comon, Contrasts, Independent Component Analysis, and Blind Deconvolution, "Int. Journal Adapt. Control Sig. Proc.", Wiley, Apr. 2004. HAL link
- Tong L., Inouye Y., Liu R-W, wavefomr-preserving blind estimation of multiple independent sources, IEEE T. Signal Processing, 41(7):2461-2470, 1993
- Cardoso J.-F, Souloumiac A., Blind beamforming for non-gaussian signals, IEE proceedings-F, 140(6):362-370, 1993
- Linsker R., "Self-organisation in a perceptual network", IEEE Computer, 21:105-117, 1988
- Nadal J;-P., Parga N., Network: computation in neural systems, 5:565-581, 1994
- Barlow H.B., Sensory Communication, ed. WA Rosenblith, pp 217-34. Cambridge, MA:MIT press, 1961
- Bell T, Sejnowsky T.J., Neural Computation, 7:1129-1159, 1995
- Cardoso J.-F, Laheld, IEEE T. Signal Processing, 44(12):3017-3030, 1996
- H. Le Borgne, Analyse de scènes par composantes indépendantes, thèse de doctorat, INP Grenoble, 2004. Chapitre 3.