Analyse des données
L’analyse des données (aussi appelée analyse exploratoire des données ou AED) est une famille de méthodes statistiques dont les principales caractéristiques sont d'être multidimensionnelles et descriptives. Dans l'acception française, la terminologie « analyse des données » désigne donc un sous-ensemble de ce qui est appelé plus généralement la statistique multivariée. Certaines méthodes, pour la plupart géométriques, aident à faire ressortir les relations pouvant exister entre les différentes données et à en tirer une information statistique qui permet de décrire de façon plus succincte les principales informations contenues dans ces données. D'autres techniques permettent de regrouper les données de façon à faire apparaître clairement ce qui les rend homogènes, et ainsi mieux les connaître.
L’analyse des données permet de traiter un nombre très important de données et de dégager les aspects les plus intéressants de la structure de celles-ci. Le succès de cette discipline dans les dernières années est dû, dans une large mesure, aux représentations graphiques fournies. Ces graphiques peuvent mettre en évidence des relations difficilement saisies par l’analyse directe des données ; mais surtout, ces représentations ne sont pas liées à une opinion « a priori » sur les lois des phénomènes analysés contrairement aux méthodes de la statistique classique.
Les fondements mathématiques de l’analyse des données ont commencé à se développer au début du XXe siècle, mais ce sont les ordinateurs qui ont rendu cette discipline opérationnelle, et qui en ont permis une utilisation très étendue. Mathématiques et informatique sont ici intimement liées.

Définition
Dans l'acception française, la terminologie « analyse des données » désigne un sous-ensemble de ce qui est appelé plus généralement la statistique multivariée. L'analyse des données est un ensemble de techniques descriptives, dont l'outil mathématique majeur est l'algèbre matricielle, et qui s'exprime sans supposer a priori un modèle probabiliste[b 1] - [i 1].
Elle comprend l’analyse en composantes principales (ACP), employée pour des données quantitatives, et ses méthodes dérivées : l'analyse factorielle des correspondances (AFC) utilisée sur des données qualitatives (tableau d’association) et l'analyse factorielle des correspondances multiples (AFCM ou ACM) généralisant la précédente. L'analyse canonique et l'analyse canonique généralisée, qui sont plus des cadres théoriques que des méthodes aisément applicables[b 2] - [b 3], étendent plusieurs de ces méthodes et vont au-delà des techniques de description[b 4]. L'Analyse Factorielle Multiple est adaptée aux tableaux dans lesquels les variables sont structurées en groupes et peuvent être quantitative et/ou qualitatives. La classification automatique, l’analyse factorielle discriminante (AFD) ou analyse discriminante permettent d’identifier des groupes homogènes au sein de la population du point de vue des variables étudiées.
En marge de l'analyse des données, l'analyse en composantes indépendantes (ACI), plus récente, issue de la physique du signal et connue initialement comme méthode de séparation aveugle de source, est plus proche intuitivement des méthodes de classification non supervisée. L'iconographie des corrélations pour des données qualitatives et quantitatives, organise les corrélations entre variables sous la forme de graphes. L'analyse inter-batterie de Tucker est intermédiaire entre l'analyse canonique et l'analyse en composantes principales[b 5], l'analyse des redondances appelée aussi analyse en composantes principales sur variables instrumentales se rapproche de la régression puisque les variables d'un des groupes analysés sont considérées comme dépendantes, les autres comme indépendantes, et que la fonction à maximiser est une somme de coefficients de corrélation entre les deux groupes[b 6].
En dehors de l'école française, l'analyse des données multivariée est complétée par la méthode de poursuite de projection de John Tukey, et les méthodes de quantification de Chikio Hayashi, dont la quantification de type III est analogue à l'analyse de correspondances[b 7]. L'analyse factorielle anglo-saxonne, ou « Factor Analysis », est proche de l'analyse en composantes principales, sans être équivalente, car elle utilise les techniques de régression[note 1] - [i 2] - [i 3] pour découvrir les « variables latentes »[note 2].
Ces procédés permettent notamment de manipuler et de synthétiser l’information provenant de tableaux de données de grande taille, à l'aide de l'estimation des corrélations entre les variables que l’on étudie. L'outil statistique utilisé est la matrice des corrélations ou la matrice de variance-covariance.
Histoire
Les pères de l’analyse des données modernes sont Jean-Paul Benzécri, Louis Guttman, Chikio Hayashi (concepteur des méthodes dénommées « Data Sciences »), Douglas Carroll et Roger Newland Shepard[i 4] - [i 1].
Mais bien avant leur temps, les techniques de base de l'analyse des données sont déjà connues. Les tableaux de contingences, par exemple, sont présents tôt dans l'histoire : l'invincible armada est décrite, par Paz Salas et Alvarez dans un livre publié en 1588, sous la forme d'un tableau où les lignes représentent les flottes de navires et les colonnes les caractéristiques telles que le tonnage, le nombre de gens d'armes, etc. Nicolas de Lamoignon de Basville, intendant du roi Louis XIV, compte et caractérise les couvents et le monastères de la région du Languedoc en 1696[i 5].
La classification trouve son maître, entre 1735 et 1758, en la personne de Carl von Linné qui met en place à cette époque les fondements de la nomenclature binomiale et la taxinomie moderne[b 8]. Robert R. Sokal et Peter H. A. Sneath présentent en 1963 des méthodes quantitatives appliquées à la taxinomie[b 9].
Les notions requises pour une analyse des données modernes commencent à être maîtrisées au début du XIXe siècle[i 6]. Adolphe Quetelet, astronome, statisticien belge, exploite ce qu'il connait de la loi gaussienne à l'anthropométrie pour examiner la dispersion autour de la moyenne (la variance) des mesures des tailles d'un groupe d'hommes. Puis, Francis Galton, parce qu'il veut étudier la taille des pères et des fils, s'intéresse à la variation conjointe (la covariance et la corrélation) de deux grandeurs, qui est à l'origine de ce qu'on appelle aujourd'hui la régression.
Quand Karl Pearson et Raphael Weldon s'emparent des travaux de Francis Galton, ils peuvent généraliser la régression de Galton aux données multidimensionnelles, puis Karl Pearson a l'idée de changer les axes de présentation pour les exprimer en fonction de variables indépendantes en 1901, établissant ainsi les prémisses de l’analyse en composantes principales. Celle-ci est développée en 1933 par Harold Hotelling qui définit en 1936 l'Analyse canonique.
Marion Richardson et Frederic Kuder en 1933, cherchant à améliorer la qualité des vendeurs de « Procter & Gamble », utilisent ce qu'on appelle maintenant l'algorithme (« Reciprocal averaging »), bien connu en ACP[i 7]. Herman Otto Hirschfeld, dans sa publication « A connection between correlation and contingency », découvre les équations de l'analyse des correspondances[i 8].
C'est la psychométrie qui développe le plus l'analyse des données. Quand Alfred Binet définit ses tests psychométriques pour mesurer l'intelligence chez l'enfant, Charles Spearman les accapare pour définir, en 1904, sa théorie des facteurs général et spécifique qui mesurent l'aptitude générale et l'aptitude particulière à une activité, nécessaires pour mener à bien cette activité[i 9]. Louis Leon Thurstone met au point sous forme matricielle les équations induites par la théorie des facteurs, en 1931, et la complète par l'étude du terme d'erreur[i 10]. Il introduit aussi la notion d'axes principaux d'inertie. En 1933, Harold Hotelling propose l'utilisation de l'itération pour la diagonalisation des matrices et la recherche des vecteurs propres[i 9].
Jean-Paul Benzécri et Brigitte Escofier-Cordier proposent l'Analyse factorielle des correspondances en 1962-65, mais en 1954 Chikio Hayashi a déjà établi les fondations de cette méthode sous le nom Quantification de type III[i 4].
L'analyse des correspondances multiples est initiée par Louis Guttman en 1941, Cyril Burt en 1950 et à Chikio Hayashi en 1956[i 7]. Cette technique est développée au Japon en 1952 par Shizuhiko Nishisato sous la dénomination « Dual Scaling »[i 7] - [i 11] et aux Pays-Bas en 1990 sous le nom de « Homogeneity analysis »[i 12] par le collectif Albert Gifi[i 7].
L'avènement de l'ordinateur, et surtout du micro-ordinateur, est un saut technologique qui rend possible les calculs complexes, les diagonalisations, les recherches de valeurs propres sur de grands tableaux de données, avec des délais d'obtention de résultats très courts par rapport à ce qui était fait dans le passé[i 9] - [i 1].
Domaines d'application
L'analyse des données est utilisée dans tous les domaines dès lors que les données se présentent en trop grand nombre pour être appréhendées par l'esprit humain.
En sciences humaines, cette technique est utilisée pour cerner les résultats des enquêtes d'opinion par exemple avec l'Analyse des correspondances multiples[b 10] ou l'Analyse factorielle des correspondances[b 11]. La sociologie compte beaucoup sur l'analyse des données pour comprendre la vie et le développement de certaines populations comme celles du Liban dont l'évolution est montrée par deux études faites en 1960 et 1970, présentées par Jean-Paul Benzécri, et dont la structure du niveau de vie et de son amélioration sont décortiquées à l'aide de l'analyse en composantes principales[b 12]. L'analyse des correspondances multiples est souvent utilisée en sociologie pour analyser les réponses à un questionnaire. Les sociologues Christian Baudelot et Michel Gollac utilisent une analyse des correspondances multiples pour étudier le rapport des Français à leur travail[i 13]. S'inspirant de Pierre Bourdieu pour étudier un « champ » spécifique, le sociologue Frédéric Lebaron emploie une ACM pour analyser le champ des économistes français[b 13] et Hjellbrekke et ses coauteurs appliquent la même méthode pour analyser le champ des élites norvégiennes[i 14]. De même, François Denord et ses coauteurs utilisent une ACM pour analyser le champ du pouvoir en France à partir du Who's Who[i 15]. Toujours dans les travaux qui s'inspirent de Pierre Bourdieu, on peut aussi prendre comme exemple l'analyse du champ du cinéma français par Julien Duval[i 16]. Les linguistes utilisent l'analyse de texte et les techniques d'analyse des données pour situer un député sur l'échiquier politique en examinant la fréquence d'usage de certains mots[b 14]. Étienne Brunet a étudié le vocabulaire français depuis 1789 et les grands auteurs comme Hugo, Zola ou Proust de la littérature avec le logiciel Hyperbase[2]. Brigitte Escofier-Cordier a étudié quelques éléments du vocabulaire employé dans la pièce de Racine, Phèdre, pour montrer comment l'auteur se sert des mots pour ancrer ses personnages dans la hiérarchie sociale[i 17]. En économie, les bilans des entreprises ont été étudiés par C. Desroussilles pour décrire la structure et la taille de ces organismes à l'aide de la classification ascendante et de l'analyse des correspondances[i 18]. La structure de la consommation des ménages dans la CEE, est présentée par Jean-Paul Benzécri et al. sur les deux axes d'une analyse des correspondances[b 15] et une première étape dans l'établissement d'une nomenclature des activités économiques dans l'industrie montre l'utilité d'une analyse des correspondances et de la classification hiérarchique dans ce type d'opération[b 16].
L'analyse des données est également une pratique courante en entreprise, pour améliorer la prise de décisions. Au sein des départements marketing, on trouve globalement cinq grands types d'analyses de données [3]: (1) l'analyse du marché (taille du marché, taux de croissance, parts de marché, consommation globale), l'analyse du consommateur (taille et ancienneté des clusters, dépenses moyennes des clusters, CLV, CAC), l'analyse des perceptions (NPS, CSAT, CES), l'analyse commerciale (DN, DV, taux de capture, taux de conversion, panier moyen, géomarketing), et l'analyse du parcours web (PPC, CTR, taux de rebond, coût par acquisition, taux de conversion, taux de transformation globale, taux de rétention).
Dans le domaine des sciences et techniques, certains chercheurs adoptent ces méthodes statistiques pour déchiffrer plusieurs caractéristiques du génome[b 17]. D'autres se servent de l'analyse des données pour mettre en place un processus nécessaire à la reconnaissance des visages[i 19]. En épidémiologie, l'Inserm met à disposition ses données qu'ont exploitées Husson et al. via l'Analyse factorielle des correspondances pour décrire les tranches d'âges en France en fonction de leurs causes de mortalité[b 18]. Jean-Paul Benzécri donne aussi des exemples de l'usage de l'analyse des correspondances dans le cadre de l'apprentissage[b 19], de l'hydrologie[b 20], de la biochimie[b 21]. Un exemple dans les sciences de l'environnement est celui de l'étude des traces de métaux dans le blé en fonction des sols cultivés, qui utilise l'analyse des corrélations canoniques considérée habituellement comme un outil plutôt théorique[i 20]. L'Observatoire des Maladies du Bois de la Vigne a cherché, dans la première décennie de ce siècle, à mesurer l'évolution de trois maladies de la vigne en pratiquant, entre autres méthodes, l'analyse des correspondances multiples et l'analyse en composantes principales dans un projet d'épidémiologie végétale[i 21].
Le domaine du sport est très friand de statistiques : un médecin du sport s'interroge sur l'âge des pratiquants, leurs motivations et le sport qu'ils pratiquent[i 22]. Dans une autre étude le sport s'intéresse aux motivations des sportifs lesquelles vont de l’amitié et la camaraderie à l'affirmation de soi représentées sur un axe, et de la nature et la beauté à la combativité sur un second axe[b 22]. Le sociologue cherche à savoir si la sociabilité des adeptes d'un sport est influencée par sa pratique[i 23], la biométrie humaine caractérise la morphologie du sportif selon le sport qu'il pratique, et dans le cas de sports collectifs le poste qu'il occupe dans l'équipe[i 24], etc.
La microfinance s'est aussi emparée de l'analyse des données pour évaluer les risques et définir les populations emprunteuses[i 25]. L'industrie de l'assurance se sert de l'analyse des données pour la connaissance des risques et la tarification à priori[i 26].
Analyse par réduction des dimensions
La représentation des données multidimensionnelles dans un espace à dimension réduite est le domaine des analyses factorielles, analyse factorielle des correspondances, analyse en composantes principales, analyse des correspondances multiples[b 23]. Ces méthodes permettent de représenter le nuage de points à analyser dans un plan ou dans un espace à trois dimensions, sans trop de perte d'information, et sans hypothèse statistique préalable[i 27]. En mathématiques, elles exploitent le calcul matriciel et l'analyse des vecteurs et des valeurs propres.
Analyse en composantes principales
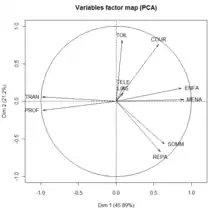
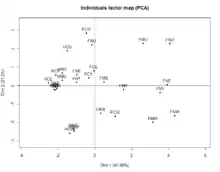
L'analyse en composantes principales est utilisée pour réduire p variables corrélées en un nombre q de variables non corrélées de telles manières que les q variables soient des combinaisons linéaires des p variables initiales, que leur variance soit maximale et que les nouvelles variables soient orthogonales entre elles suivant une distance particulière[i 29] - [i 30] - [i 31]. En ACP, les variables sont quantitatives.
Les composantes, les nouvelles variables, définissent un sous-espace à q dimensions sur lequel sont projetés les individus avec un minimum de pertes d'information. Dans cet espace le nuage de points est plus facilement représentable et l'analyse est plus aisée[b 24]. En analyse des correspondances, la représentation des individus et des variables ne se fait pas dans le même espace.
La mesure de la qualité de représentation des données peut être effectuée à l'aide du calcul de la contribution de l'inertie de chaque composante à l'inertie totale. Dans l'exemple donné sur les deux images ci-contre, la première composante participe à hauteur de 45,89 % à l'inerte totale, la seconde à 21,2 %.
Plus les variables sont proches des composantes et plus elles sont corrélées avec elles. L'analyste se sert de cette propriété pour l'interprétation des axes[b 25]. Dans l'exemple de la fig.01 les deux composantes principales représentent l'activité majeure et l'activité secondaire la plus fréquente dans lesquelles les Femmes (F) et les Hommes (H) mariés (M) ou célibataires (C) aux Usa (U) ou en Europe de l'Ouest (W) partagent leur journée. Sur la fig.02 est illustré le cercle des corrélations où les variables sont représentées en fonction de leur projection sur le plan des deux premières composantes. Plus les variables sont bien représentées et plus elles sont proches du cercle. Le cosinus de l'angle formé par deux variables est égal au coefficient de corrélation entre ces deux variables[b 26].
De même, plus l'angle engendré par l'individu et l'axe de la composante est petit et mieux l'individu est représenté. Si deux individus, bien représentés par un axe, sont proches, ils sont proches dans leur espace. Si deux individus sont éloignés en projection, ils sont éloignés dans leur espace[i 29].
Analyse factorielle des correspondances
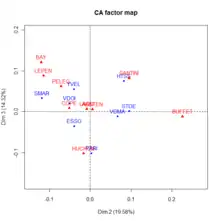
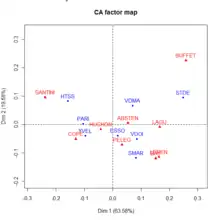
Le but de l'AFC - définie par Jean-Paul Benzécri et ses équipes - est de trouver des liens ou correspondances entre deux variables qualitatives (nominales). Cette technique traite les tableaux de contingence de ces deux variables. En fait, une AFC est une ACP sur ces tableaux dérivés du tableau initial munis de la métrique du [note 3] - [note 4] - [b 28]. Le principe de l'AFC est identique à celui de l'ACP. Les axes explicatifs qui sous-tendent le tableau de fréquences de deux variables qualitatives sont recherchés et présentés dans un graphique.

Il y a au moins deux différences entre une ACP et une AFC : la première est qu'on peut représenter les individus et les variables dans un même graphique, la seconde concerne la similarité[b 29]. Deux points-lignes sont proches dans la représentation graphique, si les profils-colonnes sont similaires. Par exemple sur le graphique de la fig.03, Paris et les Yvelines ont voté d'une manière similaire, ce qui n'est pas évident quand on regarde le tableau de contingence initial puisque le nombre de votants est assez différent dans les deux départements. De même, deux points-colonnes (dans l'exemple des figures 03 et 04 les points colonnes sont les candidats) sont proches graphiquement si les profils-lignes sont similaires. Dans l'exemple (fig.04), les départements ont voté pour Bayrou et Le Pen de la même manière. Les points-lignes et les points-colonnes ne peuvent pas être comparés d'une manière simple[note 5] - [i 33].
En ce qui concerne l'interprétation des facteurs, Jean-Paul Benzécri est très clair :
« ..interpréter un axe, c'est trouver ce qu'il y a d'analogue d'une part entre tout ce qui est écrit à droite de l'origine, d'autre part entre tout ce qui s'écarte à gauche ; et exprimer, avec concision et exactitude, l'opposition entre les deux extrêmes.....Souvent l'interprétation d'un facteur s'affine par la considération de ceux qui viennent après lui. »
— Jean-Paul Benzécri, L'analyse des données : 2 l'analyse des correspondances[b 30]
La qualité de la représentation graphique peut être évaluée globalement par la part du expliquée par chaque axe (mesure de la qualité globale), par l'inertie d'un point projetée sur un axe divisé par l'inertie totale du point (mesure de la qualité pour chaque modalité), la contribution d'un axe à l'inertie totale ou le rapport entre l'inertie d'un nuage (profils_lignes ou profils_colonnes) projeté sur un axe par l'inertie totale du même nuage[b 31].
Analyse des correspondances multiples
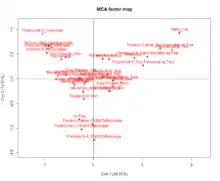
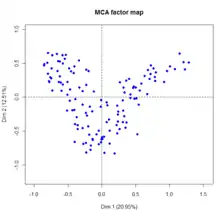
L'Analyse des Correspondances Multiples (ACM) est une extension de l'AFC[b 32] - [note 6].
L'ACM se propose d'analyser p (p ≥ 2) variables qualitatives d'observations sur n individus. Comme il s'agit d'une analyse factorielle elle aboutit à la représentation des données dans un espace à dimensions réduites engendré par les facteurs. L'ACM est l'équivalent de l'ACP pour les variables qualitatives et elle se réduit à l'AFC lorsque le nombre de variables qualitatives est égal à 2[b 33].
Formellement, une ACM est une AFC appliquée sur le tableau disjonctif complet, ou bien une AFC appliquée sur le tableau de Burt, ces deux tableaux étant issus du tableau initial. Un tableau disjonctif complet est un tableau où les variables sont remplacées par leurs modalités et les éléments par 1 si la modalité est remplie 0 sinon pour chaque individu. Un tableau de Burt est le tableau de contingence des p variables prises deux à deux.
L'interprétation se fait au niveau des modalités dont les proximités sont examinées. Les valeurs propres ne servent qu'à déterminer le nombre d'axes soit par la méthode du coude soit en ne prenant que les valeurs propres supérieures à . La contribution de l'inertie des modalités à celle des différents axes est analysée comme en AFC[b 34] - [note 7] - [i 34].

L'utilisation de variables supplémentaires, variables qui ne participent pas à la constitution des axes ni au calcul des valeurs propres, peut aider à interpréter les axes.
La qualité de la représentation d'un individu sur un axe factoriel est mesurée par où est l'angle formé par la projection du vecteur individu sur l'espace factoriel avec l'axe factoriel. Plus la valeur de est proche de 1 plus la qualité est bonne.


Analyse canonique
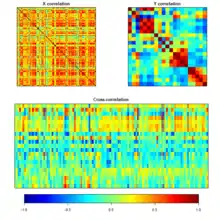
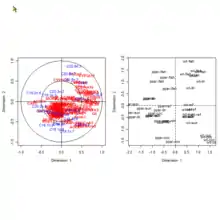
L'analyse canonique[b 35] permet de comparer deux groupes de variables quantitatives appliqués tous deux sur les mêmes individus. Le but de l'analyse canonique est de comparer ces deux groupes de variables pour savoir s'ils décrivent un même phénomène, auquel cas l'analyste pourra se passer d'un des deux groupes de variables.
Un exemple parlant est celui des analyses médicales effectuées sur les mêmes échantillons par deux laboratoires différents[b 36]. L'analyse canonique généralise des méthodes aussi diverses que la régression linéaire, l'analyse discriminante et l'analyse factorielle des correspondances[b 36].
Plus formellement, si et sont deux groupes de variables, l'analyse canonique cherche des couples de vecteurs , combinaisons linéaires des variables de et respectivement, le plus corrélées possibles. Ces variables sont dénommées variables canoniques. Dans l'espace ce sont les vecteurs propres des projections et respectivement sur les sous espace de et , où p et q représentent le nombre de variables des deux groupes, engendrés par les deux ensembles de variables. mesure la corrélation entre les deux groupes. Plus cette mesure est élevée, plus les deux groupes de variables sont corrélés et plus ils expriment le même phénomène sur les individus.








Dans l'illustration de la fig.08, les corrélations entre les variables à l'intérieur des deux groupes sont représentées par les corrélogrammes du haut, la corrélation entre les deux groupes est expliquée au-dessous. Si la couleur dominante était vert clair aucune corrélation n'aurait été détectée. Sur la fig.07, les deux groupes de variables sont rassemblés dans le cercle des corrélations rapportés aux deux premières variables canoniques.
Enfin l'analyse canonique généralisée au sens de Caroll (d'après J.D.Caroll) étend l'analyse canonique ordinaire à l'étude de p groupes de variables (p > 2) appliquées sur le même espace des individus. Elle admet comme cas particuliers l'ACP, l'AFC et l'ACM, l'analyse canonique simple, mais aussi la régression simple, et multiple, l'analyse de la variance, l'analyse de la covariance et l'analyse discriminante[i 36].
Positionnement multidimensionnel
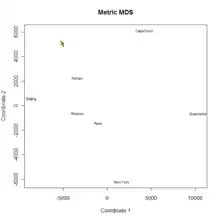
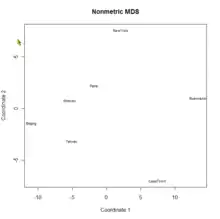
Pour utiliser cette technique les tableaux ne doivent pas être des variables caractéristiques d'individus mais des « distances » entre les individus. L'analyste souhaite étudier les similarités et les dissimilarités entre ces individus.
Le positionnement multidimensionnel (« multidimensional scaling » ou MDS) est donc une méthode factorielle applicable sur des matrices de distances entre individus[i 37]. Cette méthode ne fait pas partie de ce qu'on nomme habituellement l'analyse des données « à la française ». Mais elle a les mêmes caractéristiques que les méthodes précédentes : elle est fondée sur le calcul matriciel et ne demande pas d'hypothèse probabiliste. Les données peuvent être des mesures de p variables quantitatives sur n individus, et dans ce cas l'analyste calcule la matrice des distances ou bien directement un tableau des distances entre individus.

Dans le cas classique dit métrique, la mesure des dissimilarités utilisée est une distance euclidienne. Elle permet d'approximer les dissimilarités entre individus dans l'espace de dimension réduite. Dans le cas non métrique les données sont ordinales, de type rang. L'analyste s'intéresse plus à l'ordre des dissimilarités plutôt qu'à leur étendue. La MDS non métrique utilise un indice de dissimilarité (équivalent à une distance mais sans l'inégalité triangulaire) et permet l'approximation de l'ordre des entrées dans la matrice des dissimilarités par l'ordre des distances dans l'espace de dimension réduite[i 37].
Comme en ACP, il faut déterminer le nombre de dimensions de l'espace cible, et la qualité de la représentation, est mesurée par le rapport de la somme de l'inertie du sous-espace de dimension réduite sur l'inertie totale[i 37]. En fait, MDS métrique est équivalent à une ACP où les objets de l'analyse MDS serait les individus de l'ACP[i 38]. Dans l'exemple ci-contre, les villes seraient les individus de l'ACP et le positionnement GPS remplacerait les distances inter-villes. Mais l'Analyse MDS prolonge l'ACP, puisqu'elle peut utiliser des fonctions de similarité/dissimilarité moins contraignantes que les distances.
Avec le positionnement multidimensionnel, visualiser les matrices de dissimilarités, analyser des benchmarks et effectuer visuellement des partitionnements dans des matrices de données ou de dissimilarités sont des opérations aisées à effectuer.
Analyse Factorielle Multiple
L’analyse factorielle multiple (AFM) est dédiée aux tableaux dans lesquels un ensemble d’individus est décrit par plusieurs groupes de variables, que ces variables soient quantitatives, qualitatives ou mixtes. Cette méthode est moins connue que les précédentes mais son très grand potentiel d’application justifie une mention particulière[note 8].
Exemples d’application
- Dans les enquêtes d’opinion, les questionnaires sont toujours structurés en thèmes. On peut vouloir analyser plusieurs thèmes simultanément.
- Pour une catégorie de produits alimentaires, on dispose, sur différents aspects des produits, de notes données par des experts et de notes données par des consommateurs. On peut vouloir analyser simultanément les données des experts et les données des consommateurs.
- Pour un ensemble de milieux naturels, on dispose de données biologiques (abondance d’un certain nombre d’espèces) et de données environnementales (caractéristiques du sol, du relief, etc.). On peut vouloir analyser simultanément ces deux types de données.
- Pour un ensemble de magasins, on dispose du chiffre d’affaires par produit à différentes dates. Chaque date constitue un groupe de variables. On peut vouloir étudier ces dates simultanément.
Intérêt
Dans tous ces exemples, il est utile de prendre en compte, dans l’analyse elle-même et non seulement lors de l’interprétation, la structure des variables en groupes. C’est ce que fait l’AFM qui :
- pondère les variables de façon à équilibrer l’influence des différents groupes, ce qui est particulièrement précieux lorsque l’on est en présence de groupes quantitatifs et de groupes qualitatifs ;
- fournit des résultats classiques des analyses factorielle : représentation des individus, des variables quantitatives et des modalités des variables qualitatives ;
- fournit des résultats spécifiques de la structure en groupe : représentation des groupes eux-mêmes (un point = un groupe), des individus vus par chacun des groupes (un individu = autant de points que de groupes), des facteurs des analyses séparées des groupes (ACP ou ACM selon la nature des groupes).
Autres méthodes
Ces méthodes, mises au point plus récemment, sont moins bien connues que les précédentes.
- L'Analyse Factorielle Multiple Hiérarchique (« Hierarchical Multiple Factorial Analysis »)[i 39] prend en compte une hiérarchie sur les variables variables et non seulement une partition comme le fait l'AFM
- L'Analyse Procustéenne Généralisée (« Generalized Procustean Analysis ») juxtapose au mieux plusieurs représentations d'un même nuage de points[i 40].
- L'Analyse Factorielle Multiple Duale (« Dual Multiple Factor Analysis ») prend en compte une partition des individus.
- L'Analyse Factorielle de Données Mixtes (« Factor Analysis of Mixed Data »)[i 41] est adaptée aux tableaux dans lesquels figurent à la fois des variables quantitatives et qualitatives.
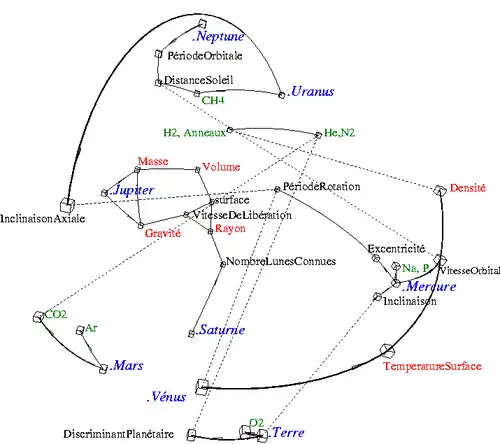
- L'iconographie des corrélations[i 42] représente les corrélations entre variables (qualitatives et quantitatives) ainsi que les individus « remarquables ». Cette méthode non supervisée se prête bien à la restitution d’une organisation, qu’elle soit arborescente ou bouclée, hiérarchique ou non. Quelle que soit la dimension des données, variables et individus remarquables sont à la surface d'une sphère ; il n'est donc pas besoin d'interpréter des axes. Plus que sur la position des points, l'interprétation repose essentiellement sur l'organisation des liens.
- L'ACI décompose une variable multivariée en composantes linéairement et statistiquement indépendantes[i 43] - [note 9].
- L'algorithme t-SNE permet la visualisation des données dans un espace de deux ou trois dimensions en rendant compte des proximités locales.
Analyse par classification
La classification des individus est le domaine de la classification automatique et de l'analyse discriminante. Classifier consiste à définir des classes, classer est l'opération permettant de mettre un objet dans une classe définie au préalable[b 37]. La classification automatique est ce qu'on appelle en exploration de données (« data mining ») la classification non supervisée, l'analyse discriminante fait partie des techniques statistiques connues en exploration de données sous le nom de classification supervisée[b 37].
Classification automatique
Le but de la classification automatique est de découper l'ensemble des données étudiées en un ou plusieurs sous-ensembles nommés classes, chaque sous-ensemble devant être le plus homogène possible. Les membres d'une classe ressemblent plus aux autres membres de la même classe qu'aux membres d'une autre classe. Deux types de classification peuvent être relevés : d'une part la classification (partitionnement ou recouvrement) « à plat » et d'autre part le partitionnement hiérarchique. Dans les deux cas, classifier revient à choisir une mesure de la similarité/dissimilarité, un critère d'homogénéité, un algorithme, et parfois un nombre de classes composant la partition[i 44].
Classification « à plat »
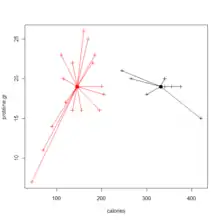

La ressemblance (similarité/dissimilarité) des individus est mesurée par un indice de similarité, un indice de dissimilarité ou une distance[i 45]. Par exemple, pour des données binaires l'utilisation des indices de similarité tels que l'indice de Jaccard, l'indice de Dice, l'indice de concordance ou celui de Tanimoto est fréquente[i 45]. Pour des données quantitatives, la distance euclidienne est la plus appropriée, mais la distance de Mahalanobis est parfois adoptée[i 45]. Les données sont soit des matrices de p variables qualitatives ou quantitatives mesurées sur n individus, soit directement des données de distances ou des données de dissimilarité.
Le critère d'homogénéité des classes est en général exprimé par la diagonale d'une matrice de variances-covariances (l'inertie) inter-classes ou intra-classes. Ce critère permet de faire converger les algorithmes de ré-allocation dynamiques qui minimisent l'inertie intra-classe ou qui maximisent l'inertie inter-classes[b 38].
Les principaux algorithmes utilisent la ré-allocation dynamique en appliquant la méthode de B.W. Forgy des centres mobiles, ou une de ses variantes : la méthode des k-means, la méthode des nuées dynamiques[b 39], ou PAM[i 46] (« Partitioning Around Medoids (PAM) »).
Les méthodes basées sur la méthode de Condorcet, l'algorithme espérance-maximisation, les densités sont aussi utilisées pour bâtir une classification[i 47] - [i 48].
Il n'y a pas de classification meilleure que les autres, en particulier lorsque le nombre de classes de la partition n'est pas prédéterminé. Il faut donc mesurer la qualité de la classification et faire des compromis. La qualité de la classification peut se mesurer à l'aide de l'indice qui est le rapport de l'inertie inter classe sur l'inertie totale, calculé pour plusieurs valeurs du nombre de classe total, le compromis étant obtenu par la méthode du coude[b 40] - [note 11].

L'interprétation des classes, permettant de comprendre la partition, peut s'effectuer en analysant les individus qui composent chaque classe. Le statisticien peut compter les individus dans chaque classe, calculer le diamètre des classes - ie la distance maximum entre individus de chaque classe. Il peut identifier les individus proches du centre de gravité, établir la séparation entre deux classes - opération consistant à mesurer la distance minimum entre deux membres de ces classes[i 49]. Il peut analyser aussi les variables, en calculant par exemple la fréquence de certaines valeurs de variables prises par les individus de chaque classe, ou en caractérisant les classes par certaines valeurs de variables prises par les individus de chaque classe[i 49].
Classification hiérarchique

Les données en entrée d'une classification ascendante hiérarchique (CAH) sont présentées sous la forme d'un tableau de dissimilarités ou un tableau de distances entre individus.
Il a fallu au préalable choisir une distance (euclidienne, Manhattan, Tchebychev ou autre) ou un indice de similarité (Jacard, Sokal, Sorensen, coefficient de corrélation linéaire, ou autre).
La classification ascendante se propose de classer les individus à l'aide d'un algorithme itératif. À chaque étape, l'algorithme produit une partition en agrégeant deux classes de la partition obtenue à l’étape précédente.
Le critère permettant de choisir les deux classes dépend de la méthode d'agrégation. La plus utilisée est la méthode de Ward qui consiste à agréger les deux classes qui font baisser le moins l'inertie interclasse[b 41]. D'autres indices d'agrégation existent comme celui du saut minimum (« single linkage ») où sont agrégées deux partitions pour lesquelles deux éléments - le premier appartenant à la première classe, le second à la seconde - sont le plus proches selon la distance prédéfinie, ou bien celui du diamètre (« complete linkage ») pour lequel les deux classes à agréger sont celles qui possèdent le couple d'éléments le plus éloigné[b 42].
L'algorithme ascendant se termine lorsqu'il ne reste qu'une seule classe.
La qualité de la classification est mesurée par le rapport inertie inter-classe sur inertie totale.
Des stratégies mixtes, alliant une classification « à plat » à une classification hiérarchique, offrent quelques avantages. Effectuer une CAH sur des classes homogènes obtenus par une classification par ré-allocation dynamique permet de traiter les gros tableaux de plusieurs milliers d'individus[i 49], ce qui n'est pas possible par une CAH seule. Effectuer une CAH après un échantillonnage et une analyse factorielle permet d'obtenir des classes homogènes par rapport à l'échantillonnage[i 49].
Analyse factorielle discriminante


L'analyse factorielle discriminante (AFD), qui est la partie descriptive de l'analyse discriminante, est aussi connue sous le nom d'analyse linéaire discriminante, d'analyse discriminante de Fisher et d'analyse canonique discriminante[b 43]. Cette technique projette des classes prédéfinies sur des plans factoriels discriminant le plus possible. Le tableau de données décrit n individus sur lesquels p variables quantitatives et une variable qualitative à q modalités ont été mesurées. La variable qualitative permet de définir les q classes et le regroupement des individus dans ces classes. L'AFD se propose de trouver q-1 variables, appelées variables discriminantes, dont les axes séparent le plus les projections des q classes qui découpent le nuage de points[b 44].
Comme dans toutes les analyses factorielles descriptives, aucune hypothèse statistique n'est faite au préalable ; ce n'est que dans la partie prédictive de l'analyse discriminante que des hypothèses a priori sont émises.
La mesure de la qualité de la discrimination est effectuée à l'aide du de Wilks qui est égal au rapport du déterminant de la matrice de variances-covariances intra-classe sur le déterminant de la matrice de variances-covariances totale. Un de Wilks faible indique une discrimination forte par les plans factoriels[b 45]. Par exemple sur les données Iris, il est de 0.0234 sur les deux premiers facteurs. En outre si la première valeur propre est proche de 1, l'AFD est de qualité[i 50].

La corrélation entre les variables et les facteurs permet d'interpréter ceux-ci.
Une AFD est une ACP effectuée sur les barycentres des classes d'individus constituées à l'aide des modalités de la variable qualitative. C'est aussi une analyse canonique entre le groupe des variables quantitatives et celui constitué du tableau disjonctif de la variable qualitative[b 46].
Analyse des données et régressions
En s'inspirant de ce qu'écrivent Henry Rouanet et ses coauteurs, l'analyse des données descriptive et l'analyse prédictive peuvent être complémentaires, et parfois produire des résultats similaires[i 51].
Approche PLS
L'approche PLS[note 12] est plus prédictive que descriptive, mais les liens avec certaines analyses que l'on vient de voir ont été clairement établis.
L'algorithme d'Herman Wold, nommé tout d'abord NILES (« Nonlinear Estimation by Iterative Least SquareS »), puis NIPALS (« Nonlinear Estimation by Iterative Partial Least SquareS ») a été conçu en premier lieu pour l'analyse en composantes principales[b 48] - [i 52].
En outre, PLS permet de retrouver l'analyse canonique à deux blocs de variables, l'analyse inter batteries de Tucker, l'analyse des redondances et l'analyse canonique généralisée au sens de Carroll[i 53]. La pratique montre que l'algorithme PLS converge vers les premières valeurs propres dans le cas de l'analyse inter batteries de Tucker[b 49], l'analyse canonique à deux blocs de variables et l'analyse des redondances[i 53].
Régressions
La régression sur composantes principales (PCR) utilise l'ACP pour réduire le nombre de variables explicatives en les remplaçant par les composantes principales qui ont l'avantage de ne pas être corrélées. PLS et PCR sont souvent comparées l'une à l'autre dans la littérature.
Déjà mentionné plus haut dans cet article, l'analyse canonique est équivalente à la régression linéaire lorsqu'un des deux groupes se réduit à une seule variable[i 54].
Logiciels
L'analyse des données moderne ne peut être dissociée de l'utilisation des ordinateurs ; de nombreux logiciels permettant d'utiliser les méthodes d'analyse des données vues dans cet article peuvent être cités. SPSS, Statistica, HyperCube[4], SAS et CORICO fournissent des modules complets d'analyse des données ; le logiciel R aussi avec des bibliothèques comme FactoMineR, Ade4 ou MASS ; Braincube[5] est une solution de Big Data et d'Edge Analytics pour les modes de fabrication en continu et discontinu.
Notes et références
Notes
- Les « loadings » peuvent être vus comme des coefficients de régression exprimant les variables en fonction des facteurs[1].
- Les « facteurs » dans le modèle du « Factor Analysis » considérés comme « variables latentes », préexistent aux mesures ; tandis que dans l'analyse en composantes principales, les « composantes » sont les variables, conséquences des mesures, permettant de réduire les dimensions.
- L'AFC peut aussi être vue comme une Analyse canonique particulière[b 27].
- Ceux-ci sont nommés tableaux des profils-lignes et des profils-colonnes. Si le tableau initial possède p lignes et q colonnes, et si est son élément générique, le tableau des profils-lignes a pour élément générique , celui des profils-colonnes . Les profils-lignes forment un nuage de p points dans qu'on munit de la métrique . Une métrique équivalente est appliquée sur sur les profils-colonnes
- Pour plus d'informations sur l'exemple ci-contre voir l'analyse de FG Carpentier de l'université de Brest FG Carpentier, « Analyse Factorielle des correspondances » [PDF], sur geai.univ-brest.fr, (consulté le ).
- Pour appréhender l'apport spécifique de l'ACM, voir Saporta 2006, p. 227.
- L'inertie totale du nuage de points est égale à , l'inertie de la variable possédant modalités est donnée par et l'inertie de la modalité j a pour formule .
- Deux livres comportent une description détaillée de l’AFM : Escofier & Pagès 2008 et Pagès 2013.
- Voir ce document aussi pour une comparaison entre ACP et ACI.
- Voir les données sur le site Université de Koln, « « Data Sets for Clustering Techniques » », sur uni-koeln.de (consulté le ).
- Voir « Glossaire du data mining ».
- PLS signifie « Partial Least Squares » soit Moindres carrés partiels ou bien « Projection to Latent Structure » soit Projection sur la Structure Latent selon les cas.









Références
- Elizabeth Garrett-Mayer, « Statistics in Psychosocial Research : Lecture 8 : Factor Analysis I », sur ocw.jhsph.edu, (consulté le ).
- Etienne Brunet, Le Vocabulaire français de 1789 à nos jours, 3 tomes, 1824 p., Genève-Paris, Slatkine-Champion, 1981 (préface de P. Imbs, membre de l’Institut) (ISBN 2-05-100361-0). Le Vocabulaire de Proust, avec l’Index complet et synoptique de À la recherche du temps perdu, 3 vol., 1918 p., Genève-Paris, Slatkine-Champion, 1983 (préface de J.Y. Tadié). (ISBN 2051004749) (ISBN 9782051004749). Le Vocabulaire de Zola, suivi de l’Index complet et synoptique des Rougon-Macquart, 3 tomes, 472 p., 646 p., 357 p. et 5500 pages sur microfiches normalisées, Genève-Paris, Slatkine-Champion, 1985 (préface de H. Mitterand) (ISBN 2-05-100670-9). Le vocabulaire de Victor Hugo, vol.1, 484 p., vol.2, 637 p., vol.3, 556 p., + 27 microfiches normalisées contenant l’Index synoptique des œuvres de Hugo (6878 p.), Genève-Paris, Slatkine-Champion, 1988. (ISBN 2051010048) (ISBN 9782051010047)
- Kathleen Desveaud et Jean Mallol, « Les 5 analyses de données incontournables pour la prise de décision en Marketing », Management & Datascience, vol. 3, no 3, (ISSN 2555-7017, lire en ligne, consulté le )
- « Publications », sur bearingpoint.com (consulté le ).
- « Braincube Cloud Solution », sur www.ipleanware.com
Ouvrages spécialisés
- Husson 2009, p. iii
- Saporta 2006, p. 190
- Lebart 2008, p. 38
- Lebart 2008, p. 418-419
- Tenenhaus 1998, p. 23
- Tenenhaus 1998, p. 35
- Lebart 2008, p. 131
- Benzécri 1976, p. 91 et suiv. (Tome I)
- Benzécri 1976, p. 63 et suiv. (Tome I)
- Husson 2009, p. 155
- Benzécri 1976, p. 339 (Tome II)
- Benzécri 1976, p. 372(Tome II)
- Frédéric Lebaron, La Croyance économique, Le Seuil, coll. « Liber », , 1re éd., 260 p. (ISBN 978-2-02-041171-4)
- Benzécri 1976, p. 329 (Tome II)
- Benzécri 1976, p. 467 (Tome II)
- Benzécri 1976, p. 485 (Tome I)
- Husson 2009, p. 58
- Husson 2009, p. 110
- Benzécri 1976, p. 29 (Tome I)
- Benzécri 1976, p. 31 (Tome I)
- Benzécri 1976, p. 37 (Tome I)
- Benzécri 1976, p. 55 (Tome I)
- Lebart 2008, p. 6
- Saporta 2006, p. 162
- Saporta 2006, p. 178
- Lebart 2008, p. 93
- Saporta 2006, p. 212.
- Saporta 2006, p. 201-204
- Husson 2009, p. 70
- Benzécri 1976, p. 47 (Tome II)
- Husson 2009, p. 81-83
- Lebart 2008, p. 187
- Saporta 2006, p. 220
- Husson 2009, p. 140-141
- Lebart 2008, p. 37
- Saporta 2006, p. 189-190
- Husson 2009, p. 172
- Saporta 2006, p. 250-251
- Saporta 2006, p. 243
- Tufféry 2010, p. 240
- Saporta 2006, p. 258
- Saporta 2006, p. 256
- Lebart 2008, p. 329
- Tufféry 2010, p. 329
- Tufféry 2010, p. 342
- Saporta 2006, p. 444
- Tenenhaus 1998, p. 243
- Tenenhaus 1998, p. 61
- Tenenhaus 1998, p. 237 et suiv.
Articles publiés sur internet
- Jean-Paul Benzécri, « Histoire et Préhistoire de l'Analyse des données : Partie 5 », Les Cahiers de l'analyse des données, vol. 2, no 1, , p. 9-40 (lire en ligne [PDF], consulté le )
- (en) N. Zainol, J. Salihon et R. Abdul-Rahman, « Biogas Production from Waste using Biofilm Reactor: Factor Analysis in Two Stages System », World Academy of Science, Engineering and Technology, vol. 54, no 2, , p. 30-34 (lire en ligne [PDF], consulté le )
- (en) Reza Nadimi et Fariborz Jolai, « Joint Use of Factor Analysis (FA) and Data Envelopment Analysis (DEA) for Ranking of Data Envelopment Analysis », International Journal of Mathematical, Physical and Engineering Sciences, vol. 2, no 4, , p. 218-222 (lire en ligne [PDF], consulté le )
- (en) Noboru Ohsumi et Charles-Albert Lehalle, « Benzecri, Tukey and Hayashi (maths) », sur lehalle.blogspot.com, (consulté le )
- (en) Antoine de Falguerolles, « L'analyse des données : before and around », Journal Electronique d'Histoire des Probabilités et de la Statistique, vol. 4, no 2, (lire en ligne [PDF], consulté le )
- Jean-Paul Benzécri, « Histoire et Préhistoire de l'Analyse des données : Partie 2 », Les Cahiers de l'analyse des données, vol. 1, no 2, , p. 101-120 (lire en ligne, consulté le )
- Ludovic Lebart, « L'analyse des données des origines à 1980 : quelques éléments », Journal Electronique d'Histoire des Probabilités et de la Statistique, vol. 4, no 2, (lire en ligne [PDF], consulté le )
- Gilbert Saporta, « Données supplémentaires sur l'analyse des données » [PDF], sur cedric.cnam.fr, (consulté le )
- Jean-Paul Benzécri, « Histoire et Préhistoire de l'Analyse des données : Partie 4 », Les Cahiers de l'analyse des données, vol. 1, no 4, , p. 343-366 (lire en ligne [PDF], consulté le )
- (en) Louis Léon Thurstone, Multiple factor analysis. Psychological Review, 38, , p. 406–427
- (en) Shizuhiko Nishisato, « Elements of Dual Scaling : An Introduction to Practical Data Analysis », Applied Psychological Measurement, vol. 18, no 4, , p. 379-382 (présentation en ligne, lire en ligne [PDF])
- (en) George Michailidis et Jan de Leeuw, « The Gifi System of Descriptive Multivariate Analysis », Statistical Science, vol. 4, no 13, , p. 307-336 (lire en ligne [PDF], consulté le )
- Christian Baudelot et Michel Gollac, « Faut-il travailler pour être heureux ? », Insee Première, no 560, (lire en ligne, consulté le )
- (en) Johs Hjellbrekke, Brigitte Le Roux, Olav Korsnes, Frédéric Lebaron, Henry Rouanet et Lennart Rosenlund, « The Norwegian Field of Power Anno 2000 », European Societies, vol. 9, no 2, , p. 245-273 (lire en ligne, consulté le )
- François Denord, Paul Lagneau-Ymonet et Sylvain Thine, « Le champ du pouvoir en France », Actes de la recherche en sciences sociales, no 190, , p. 24-57 (lire en ligne, consulté le )
- Julien Duval, « L'art du réalisme », Actes de la recherche en sciences sociales, nos 161-162, , p. 96-195 (lire en ligne, consulté le )
- E. Boukherissa, « Contribution à l'étude de la structure des pièces de théâtre : Analyse de la matrice de présence des personnages sur la scène », Les Cahiers de l'Analyse des données, vol. 20, no 2, , p. 153-168 (lire en ligne [PDF], consulté le )
- C. Desroussilles, « Taille et structure des entreprises étudiées d'après leurs bilans », Les Cahiers de l'Analyse des données, vol. 5, no 1, , p. 45-63 (lire en ligne [PDF], consulté le )
- (en) Zhang Yan et Yu Bin, « Non-negative Principal Component Analysis for Face Recognition », World Academy of Science, Engineering and Technology, vol. 48, , p. 577-581 (lire en ligne [PDF], consulté le )
- L. Bellanger, D. Baize et R. Tomassone, « L'Analyse des corrélations canoniques appliquées à des données environnementales », Revue de Statistique Appliquée, vol. LIV, no 4, , p. 7-40 (lire en ligne [PDF], consulté le )
- F. Bertrand, M. Maumy, L. Fussler, N. Kobes, S. Savary et J. Grossman, « Etude statistique des données collectées par l'Observatoire des maladies du Bois de la Vigne », Journal de la Société Française de Statistique, vol. 149, no 4, , p. 73-106 (lire en ligne [PDF], consulté le )
- H. Seiffolahi, « Caractéristiques des sujets pratiquant divers sports dans la région parisienne », Les Cahiers de l'Analyse des Données, vol. 6, no 4, , p. 493-497 (lire en ligne [PDF], consulté le )
- Renaud Laporte, « Pratiques Sportives et Sociabilité », Mathematics and Social Sciences, vol. 43, no 170, , p. 79-94 (lire en ligne [PDF], consulté le )
- Anne-Béatrice Dufour, Jacques Pontier et Annie Rouard, « Morphologie et Performance chez les Sportifs de Haut Niveau: Cas du Handball et de la Natation » [PDF], sur pbil.univ-lyon1.fr, (consulté le )
- Carla Henry, Manohar Sharma, Cecile Lapenu et Manfred Zeller, « Outil d’évaluation de la pauvreté en microfinance » [PDF], sur lamicrofinance.org, (consulté le )
- Arthur Charpentier et Michel Denuit, Mathématiques de l'Assurance Non Vie, t. II, Economica, , 596 p. (ISBN 978-2-7178-4860-1)
- Dominique Desbois, « La place de l’a priori dans l’analyse des données économiques ou le programme fort des méthodes inductives au service de l’hétérodoxie », Modulad, no 32, , p. 176-181 (lire en ligne [PDF], consulté le )
- FG Carpentier, « Analyse en composantes principales avec R », sur geai.univ-brest.fr, (consulté le )
- C. Duby et S. Robin, « Analyse en Composantes Principales » [PDF], sur agroparistech.fr, (consulté le )
- Christine Decaestecker et Marco Saerens, « Analyse en composantes principales » [PDF], sur isys.ucl.ac.be (consulté le )
- (en) Hossein Arsham, « « Topics in Statistical Data Analysis: Revealing Facts From Data » », sur home.ubalt.edu (consulté le )
- FG Carpentier, « Analyse factorielle des correspondances avec R », sur geai.univ-brest.fr (consulté le )
- R. Ramousse, M. Le Berre et L. Le Guelte, « Introduction aux Statistiques », sur cons-dev.org, (consulté le )
- Université Pierre et Marie Curie, Paris, « Analyse factorielle des correspondances multiples : 4.3 Formulaire », sur obs-vlfr.fr (consulté le )
- (en) Ignacio Gonzalez, Sébastien Déjean, Pascal G. P. Martin et Alain Baccini, « « CCA: An R Package to Extend Canonical Correlation Analysis » » [PDF], sur jstatsoft.org, (consulté le )
- Ph. Casin et J.C. Turlot, « Une présentation de l'analyse canonique généralisée dans l'espace des individus », Revue de Statistique Appliquée, vol. 34, no 3, , p. 65-75 (lire en ligne [PDF], consulté le )
- (en) A. Mead, « Review of the Development of Multidimensional Scaling Methods », Statistician, vol. 41, no 1, , p. 27-39 (lire en ligne [PDF], consulté le )
- Dominique Desbois, « Une introduction au positionnement multidimensionnel. », Modulad, vol. 32, , p. 1-28 (lire en ligne [PDF], consulté le )
- Sébastien le Dien et Jérôme Pagès, « Analyse Factorielle Multiple Hiérarchique », Revue de Statistique Appliquée, vol. 51, no 2, , p. 47-73 (lire en ligne [PDF], consulté le )
- Jérôme Pagès, « Analyse Factorielle Multiple et Analyse Procustéenne », Revue de Statistique Appliquée, vol. LIII, no 4, , p. 61-86url=http://smf4.emath.fr/Publications/JSFdS/RSA/53_4/pdf/sfds_rsa_53_4_61-86.pdf
- Jérôme Pagès, « Analyse Factorielle de Données Mixtes », Revue de Statistique Appliquée, vol. 52, no 4, , p. 93-111 (lire en ligne, consulté le )
- Michel Lesty, « Corrélations partielles et corrélations duales », Modulad, vol. 39, , p. 1-22 (lire en ligne, consulté le )
- Jean-François Cardoso, « Analyse en composantes indépendantes » [PDF], sur perso.telecom-paristech.fr (consulté le )
- Laurence Reboul, « CH 3 : Classification » [PDF], sur iml.univ-mrs.fr (consulté le )
- J.M Loubes, « Exploration Statistique Multidimensionnelle Chapitre 8 : Classification non supervisée » [PDF], sur math.univ-toulouse.fr (consulté le )
- (en) Unesco, « « Partitioning Around Medoids » », sur unesco.org (consulté le )
- Christel Vrain, « Classification non supervisée » [PDF], sur univ-orleans.fr (consulté le )
- Catherine Aaron, « Algorithme EM et Classification non Supervisée » [PDF], sur samos.univ-paris1.fr (consulté le )
- Mireille Summa-Gettler et Catherine Pardoux, « La Classification Automatique » [PDF], sur ceremade.dauphine.fr (consulté le )
- Jean-Yves Baudot, « L'AFD modèle Linéaire », sur jybaudot.fr, (consulté le )
- Henry Rouanet, Frédéric Lebaron, Viviane Le Hay, Werner Ackermann et Brigitte Le Roux, « Régression et Analyse Géométrique des Données : Réflexions et Suggestions », Mathématiques et Sciences humaines, no 160, , p. 13-45 (lire en ligne, consulté le )
- Séverine Vancolen, « Régression PLS » [PDF], sur doc.rero.ch, (consulté le )
- Michel Tenenhaus, « L'approche PLS », Revue de Statistique Appliquée, vol. 47, no 2, , p. 5-40 (lire en ligne [PDF], consulté le )
- J. Obadia, « L'analyse en composantes explicatives », Revue de Statistique Appliquée, vol. 26, no 4, , p. 5-28 (lire en ligne [PDF], consulté le )
Voir aussi
Bibliographie
- Jean-Paul Benzécri et al., L'Analyse des Données : 1 La Taxinomie, Paris, Dunod, , 631 p. (ISBN 2-04-003316-5).

- Jean-Paul Benzécri et al., L'Analyse des Données : 2 L'Analyse des correspondances, Paris, Dunod, , 616 p. (ISBN 2-04-004255-5).
- Jean-Marie Bouroche et Gilbert Saporta, L'Analyse des données, Paris, Presses Universitaires de France, , 9e éd., 125 p. (ISBN 978-2-13-055444-8).
- Alain Desrosières, « Analyse des données et sciences humaines : comment cartographier le monde social ? », Journal électronique d’histoire d’histoire des probabilités et des statistiques, (lire en ligne)
- Brigitte Escofier et Jérôme Pagès, Analyses factorielles simples et multiples : objectifs, méthodes et interprétation, Paris, Dunod, Paris, , 318 p. (ISBN 978-2-10-051932-3)
- François Husson, Sébastien Lê et Jérome Pagès, Analyse de données avec R, Rennes, Presses Universitaires de Rennes, , 224 p. (ISBN 978-2-7535-0938-2).
- (en) Lyle V. Jones, The Collected Works of John W. Tukey T.IV, Monterey, California, Chapman and Hall/CRC, , 675 p. (ISBN 978-0-534-05101-3, lire en ligne).
- (en) Lyle V. Jones, The Collected Works of John W. Tukey T.I, Monterey, California, Wadsworth Pub Co, , 680 p. (ISBN 978-0-534-03303-3, lire en ligne).
- Ludovic Lebart, Marie Piron et Alain Morineau, Statistique Exploratoire Multidimensionnelle, Paris, Dunod, , 464 p. (ISBN 978-2-10-049616-7)
- Frédéric Lebaron, L'enquête quantitative en sciences sociales : Recueil et analyse des données, Dunod, coll. « Psycho sup », , 1re éd., 182 p. (ISBN 978-2-10-048933-6)
- Jérôme Pagès, Analyse factorielle multiple avec R, Les Ulis, EDP sciences, Paris, , 253 p. (ISBN 978-2-7598-0963-9)
- Gilbert Saporta, Probabilités, Analyse des données et Statistiques, Paris, Éditions Technip, , 622 p. [détail des éditions] (ISBN 978-2-7108-0814-5, présentation en ligne)
- Michel Tenenhaus, La régression PLS : Théorie et Pratique, Paris, éditions Technip, , 254 p. (ISBN 978-2-7108-0735-3, lire en ligne)
- Stéphane Tufféry, Data Mining et statistique décisionnelle : l'intelligence des données, Paris, éditions Technip, , 705 p. (ISBN 978-2-7108-0946-3, lire en ligne)
- (en) J W Tukey et K.E. Basford, Graphical Analysis of Multiresponse Data, Londres, Chapman & Hall (CRC Press), , 587 p. (ISBN 0-8493-0384-2).
- Michel Volle, Analyse des données, Economica, , 4e éd., 323 p. (ISBN 978-2-7178-3212-9).
- Michel Volle, « L'analyse des données », Économie et Statistique, vol. 96, no 1, , p. 3–23 (DOI 10.3406/estat.1978.3094, présentation en ligne).