Neurone formel
Un neurone formel, parfois appelé neurone de McCulloch-Pitts[1], est une représentation mathématique et informatique d'un neurone biologique. Le neurone formel possède généralement plusieurs entrées et une sortie qui correspondent respectivement aux dendrites et au cône d'émergence du neurone biologique (point de départ de l'axone). Les actions excitatrices et inhibitrices des synapses sont représentées, la plupart du temps, par des coefficients numériques (les poids synaptiques) associés aux entrées. Les valeurs numériques de ces coefficients sont ajustées dans une phase d'apprentissage. Dans sa version la plus simple, un neurone formel calcule la somme pondérée des entrées reçues, puis applique à cette valeur une fonction d'activation, généralement non linéaire. La valeur finale obtenue est la sortie du neurone.
Le neurone formel est l'unité élémentaire des réseaux de neurones artificiels dans lesquels il est associé à ses semblables pour calculer des fonctions arbitrairement complexes, utilisées pour diverses applications en intelligence artificielle.
Mathématiquement, le neurone formel est une fonction à plusieurs variables et à valeurs réelles.
Le neurone formel de McCulloch et Pitts
Historique
Le premier modèle mathématique et informatique du neurone biologique est proposé par Warren McCulloch et Walter Pitts en 1943[2]. En s'appuyant sur les propriétés des neurones biologiques connues à cette époque, issues d'observations neurophysiologiques et anatomiques, McCulloch et Pitts proposent un modèle simple de neurone formel. Il s'agit d'un neurone binaire, c'est-à-dire dont la sortie vaut 0 ou 1. Pour calculer cette sortie, le neurone effectue une somme pondérée de ses entrées (qui, en tant que sorties d'autres neurones formels, valent aussi 0 ou 1) puis applique une fonction d'activation à seuil : si la somme pondérée dépasse une certaine valeur, la sortie du neurone est 1, sinon elle vaut 0 (cf les sections suivantes).
McCulloch et Pitts étudiaient en fait l'analogie entre le cerveau humain et les machines informatiques universelles. Ils montrèrent en particulier qu'un réseau (bouclé) constitué des neurones formels de leur invention a la même puissance de calcul qu'une machine de Turing.
Malgré la simplicité de cette modélisation, ou peut-être grâce à elle, le neurone formel dit de McCulloch et Pitts reste aujourd’hui un élément de base des réseaux de neurones artificiels. De nombreuses variantes ont été proposées, plus ou moins biologiquement plausibles, mais s'appuyant généralement sur les concepts inventés par les deux auteurs. On sait néanmoins aujourd’hui que ce modèle n’est qu’une approximation des fonctions remplies par le neurone réel et, qu’en aucune façon, il ne peut servir pour une compréhension profonde du système nerveux.
Formulation mathématique
On considère le cas général d'un neurone formel à entrées, auquel on doit donc soumettre les grandeurs numériques (ou signaux, ou encore stimuli) notées à . Un modèle de neurone formel est une règle de calcul qui permet d'associer aux entrées une sortie : c'est donc une fonction à variables et à valeurs réelles.




Dans le modèle de McCulloch et Pitts, à chaque entrée est associé un poids synaptique, c'est-à-dire une valeur numérique notée de pour l'entrée jusqu'à pour l'entrée . La première opération réalisée par le neurone formel consiste en une somme des grandeurs reçues en entrées, pondérées par les coefficients synaptiques, c'est-à-dire la somme




À cette grandeur s'ajoute un seuil . Le résultat est alors transformé par une fonction d'activation non linéaire (parfois appelée fonction de sortie), . La sortie associée aux entrées à est ainsi donnée par


- ,

qu'on peut écrire plus simplement :
- ,

en ajoutant au neurone une entrée fictive fixée à la valeur .

Dans la formulation d'origine de McCulloch et Pitts, la fonction d'activation est la fonction de Heaviside (fonction en marche d'escalier), dont la valeur est 0 ou 1. Dans ce cas, on préfère parfois définir la sortie par la formule suivante
- ,

qui justifie le nom de seuil donné à la valeur . En effet, si la somme dépasse la sortie du neurone est 1, alors qu'elle vaut 0 dans le cas contraire : est donc le seuil d'activation du neurone, si on considère que la sortie 0 correspond à un neurone « éteint ».

Variantes du neurone de McCulloch et Pitts
La plupart des neurones formels utilisés actuellement sont des variantes du neurone de McCulloch et Pitts dans lesquelles la fonction de Heaviside est remplacée par une autre fonction d'activation. Les fonctions les plus utilisées sont :
- la fonction sigmoïde ;
- la fonction tangente hyperbolique ;
- la fonction identité ;
- la fonction rectifieur : ;
- La lissage de la moyenne ou , = poids du synapse actuel, = attendu
- dans une moindre mesure, certaines fonctions linéaires par morceaux.




Ces choix sont motivés par des considérations théoriques et pratiques issues de la combinaison des neurones formels en un réseau de neurones formels.
Propriétés importantes de la fonction d'activation
Les propriétés de la fonction d'activation influent en effet sur celle du neurone formel et il est donc important de bien choisir celle-ci pour obtenir un modèle utile en pratique.
Quand les neurones sont combinés en un réseau de neurones formels, il est important par exemple que la fonction d'activation de certains d'entre eux ne soit pas un polynôme sous réserve de limiter la puissance de calcul du réseau obtenu[3]. Un cas caricatural de puissance limitée correspond à l'utilisation d'une fonction d'activation linéaire, comme la fonction identité : dans une telle situation le calcul global réalisé par le réseau est lui aussi linéaire et il est donc parfaitement inutile d'utiliser plusieurs neurones, un seul donnant des résultats strictement équivalents.
Cependant, les fonctions de type sigmoïde sont généralement bornées. Dans certaines applications, il est important que les sorties du réseau de neurones ne soient pas limitées a priori : certains neurones du réseau doivent alors utiliser une fonction d'activation non bornée. On choisit généralement la fonction identité.
Il est aussi utile en pratique que la fonction d'activation présente une certaine forme de régularité. Pour calculer le gradient de l'erreur commise par un réseau de neurones, lors de son apprentissage, il faut que la fonction d'activation soit dérivable. Pour calculer la matrice hessienne de l'erreur, ce qui est utile pour certaines analyses d'erreur, il faut que la fonction d'activation soit dérivable deux fois. Comme elles comportent généralement des points singuliers, les fonctions linéaires par morceaux sont relativement peu utilisées en pratique.
La fonction sigmoïde
La fonction sigmoïde (aussi appelée fonction logistique ou fonction en S) est définie par :

Elle possède plusieurs propriétés qui la rendent intéressante comme fonction d’activation.
Elle n'est pas polynômiale
Elle est indéfiniment continûment dérivable et une propriété simple permet d'accélérer le calcul de sa dérivée. Ceci réduit le temps calcul nécessaire à l'apprentissage d'un réseau de neurones. On a en effet
.

On peut donc calculer la dérivée de cette fonction en un point de façon très efficace à partir de sa valeur en ce point.
De plus, la fonction sigmoïde renvoie des valeurs dans l'intervalle , ce qui permet d'interpréter la sortie du neurone comme une probabilité. Elle est aussi liée au modèle de régression logistique et apparaît naturellement quand on considère le problème de la séparation optimale de deux classes de distributions gaussiennes avec la même matrice de covariance.
![[0;1]](https://img.franco.wiki/i/bc3bf59a5da5d8181083b228c8933efbda133483.svg)
Cependant, les nombres avec lesquels travaillent les ordinateurs rendent cette fonction difficile à programmer.
En effet, , et avec la précision des nombres à virgule des ordinateurs, , et donc .



Lorsque vous essayez de coder un réseau de neurones en commettant cette erreur, après apprentissage, quelles que soient les valeurs que vous mettrez en entrée de votre réseau, vous obtiendrez toujours le même résultat.
Il existe heureusement de nombreuses solutions pour tout de même utiliser dans votre programme, et certaines d'entre elles sont dépendantes d'un langage. Elles reviennent toutes à utiliser une représentation des nombres flottants, plus précise que l'IEEE754. Parfois, normaliser les entrées entre 0 et 1 peut suffire à régler le problème[4].
La fonction tangente hyperbolique
La fonction tangente hyperbolique, définie par

est aussi très utilisée en pratique, car elle partage avec la fonction sigmoïde certaines caractéristiques pratiques :
- non polynomiale
- indéfiniment continûment dérivable
- calcul rapide de la dérivée par la formule

C'est, à une transformation linéaire près, la fonction sigmoïde :

Autres neurones formels
Le développement des réseaux de neurones artificiels a conduit à l'introduction de modèles différents de celui de McCulloch et Pitts. La motivation n'était pas de mieux représenter les neurones réels, mais plutôt d'utiliser les propriétés de certaines constructions mathématiques pour obtenir des réseaux plus efficaces (par exemple avec un apprentissage plus simple, ou encore utilisant moins de neurones).
Comme le neurone de McCulloch et Pitts, les neurones présentés dans cette section possèdent entrées numériques.
Neurone à base radiale
Un neurone à base radiale est construit à partir d'une fonction du même nom. Au lieu de réaliser une somme pondérée de ses entrées, un tel neurone compare chaque entrée à une valeur de référence et produit une sortie d'autant plus grande (proche de 1) que les entrées sont proches des valeurs de références.
Chaque entrée est donc associée à une valeur . La comparaison entre les deux jeux de valeurs se fait généralement au sens de la norme euclidienne. Plus précisément, le neurone commence par calculer la grandeur suivante



Il est parfaitement possible d'utiliser une autre norme que la norme euclidienne, et plus généralement une distance quelconque, pour comparer les vecteurs et .


Le neurone transforme ensuite la valeur obtenue grâce à une fonction d'activation. Sa sortie est donc finalement donnée par
- .

La fonction calculée par le neurone est dite à base radiale car elle possède une symétrie radiale autour du point de référence : si on réalise une rotation quelconque autour de ce point, la sortie du neurone reste inchangée.

En pratique, il est très courant d'utiliser une fonction d'activation gaussienne définie par
- .

Le paramètre peut être interprété comme l'inverse de la sensibilité du neurone : plus il est grand, plus il faut que les entrées soient proches des valeurs de références pour que la sortie du neurone soit proche de 1.

Neurone Sigma-Pi
Un neurone Sigma-Pi est obtenu en remplaçant la somme pondérée des entrées du modèle de McCulloch et Pitts par une somme pondérée de produits de certaines entrées.
Considérons par exemple le cas de deux entrées. La sortie d'un neurone de McCulloch et Pitts s'écrit sous la forme , alors que celle d'un neurone Sigma-Pi est donnée par

- ,

la différence résidant donc dans la présence du terme produit .

Dans le cas général à entrées, on obtient une sortie de la forme suivante
- .

Dans cette formule, est un entier quelconque qui désigne le nombre de produits d'entrées utilisés. L'ensemble est un sous-ensembles de qui précise les entrées à multiplier entre elles pour obtenir le terme numéro . Selon cette notation, l'exemple donné plus haut pour 2 entrées correspond à (3 termes dans la somme), (entrée 1 utilisée seule), (entrée 2 utilisée seule) et (produit des entrées 1 et 2).








La formulation utilisée montre qu'il existe de nombreuses possibilités pour construire un neurone Sigma-Pi pour un nombre donné d'entrées. Ceci est lié à la croissance exponentielle avec le nombre d'entrées du nombre de sous-ensembles d'entrées utilisables pour construire un neurone Sigma-Pi : il existe en effet combinaisons possibles (en considérant la combinaison vide comme celle correspondant au seuil ). En pratique, quand devient grand (par exemple à partir de 20), il devient quasi impossible d'utiliser tous les termes possibles et il faut donc choisir les produits à privilégier. Une solution classique consiste à se restreindre à des sous-ensembles de entrées pour une valeur faible de .


La formulation générale de ces neurones est aussi à l'origine du nom Sigma-Pi qui fait référence aux lettres grecques capitales Sigma (Σ) et Pi (Π) utilisées en mathématiques pour représenter respectivement la somme et le produit.
Calcul logique neuronal
Le neurone de McCulloch et Pitts (dans sa version d'origine) peut réaliser des calculs logiques élémentaires.
Fonctions logiques calculables
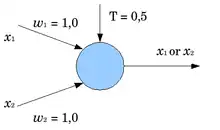
Considérons par exemple un neurone formel à deux entrées dont on fixe les poids synaptiques à 1. En fonction de la valeur du seuil, le neurone réalise une fonction logique, telle le OU logique ou le ET logique. On remarque en effet que la sortie du neurone est donnée par:
- ,

où désigne la fonction de Heaviside[5]. En fonction des valeurs des entrées, on a donc les résultats suivants :

| / | 0 | 1 |
|---|---|---|
| 0 | ||
| 1 |




On distingue quatre cas, selon la valeur de .
Si le est positif ou nul, la sortie du neurone vaut toujours 1 (la fonction de Heaviside définissant ).

Si , la table devient :

| / | 0 | 1 |
|---|---|---|
| 0 | ||
| 1 |

et le neurone calcule donc un OU logique.
Si , la table devient :

| / | 0 | 1 |
|---|---|---|
| 0 | ||
| 1 |
et le neurone calcule donc un ET logique.
Enfin, si , le neurone donne toujours un résultat nul.

Par le même type de raisonnement, on constate qu'un neurone à une entrée peut n'avoir aucun effet (neurone identité) ou réaliser un NON logique.
Par linéarité de la somme pondérée, si on multiplie en même temps les poids synaptiques et le seuil d'un neurone par un nombre positif quelconque, le comportement du neurone est inchangé, et la modification est totalement indiscernable. En revanche, si on multiplie tout par un nombre négatif, le comportement du neurone est inversé, puisque la fonction d'activation est croissante.
En combinant des neurones de McCulloch et Pitts, c'est-à-dire en utilisant les sorties de certains neurones comme entrées pour d'autres neurones, on peut donc réaliser n'importe quelle fonction logique. Quand on autorise en outre des connexions formant des boucles dans le réseau, on obtient un système avec la même puissance qu'une machine de Turing.
Limitations
Un neurone seul ne peut pas cependant représenter n'importe quelle fonction logique, mais seulement des fonctions logiques monotones. L'exemple le plus simple de fonction non calculable directement est le OU exclusif, en raison de son caractère non monotone.
On peut donner une démonstration élémentaire de cette propriété. Étudions en effet les propriétés que devraient vérifier les poids d'un neurone calculant la fonction OU exclusif. Comme le OU exclusif de 0 et 0 vaut 0, on doit avoir , soit donc

- ,

par définition de la fonction de Heaviside. Quand l'une des deux entrées du neurone vaut 0 et l'autre 1, la sortie doit être 1. Cela implique donc , soit donc

- .

De même, on doit avoir
- .

Enfin, quand les deux entrées valent 1, la sortie vaut 0, soit donc , ce qui implique

- .

En ajoutant les équations (1) et (4), on obtient
- ,

alors que l'ajout des équations (2) et (3) donne
- .

Notes
- (en) Akshay L. Chandra, « McCulloch-Pitts Neuron — Mankind’s First Mathematical Model Of A Biological Neuron », sur Medium, (consulté le )
- En particulier dans McCulloch, W. S., Pitts, W., A Logical Calculus of the Ideas Immanent in Nervous Activity, Bulletin of Mathematical Biophysics, vol. 5, pp. 115-133, 1943.
- Leshno, M., Lin, V. Y., Pinkus, A., Schocken, S., 1993. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Networks 6 (6), 861-867.
- rapport de projet EISTI de filière IMA-CHP - Pierre-Marie LANSAC.
- il s'agit plus exactement de , i.e .
