Calcul distribué
Un calcul distribué, ou réparti ou encore partagé, est un calcul ou un traitement réparti sur plusieurs microprocesseurs et plus généralement sur plusieurs unités centrales informatiques, et on parle alors d'architecture distribuée ou de système distribué. Le calcul distribué est souvent réalisé sur des clusters de calcul spécialisés, mais peut aussi être réalisé sur des stations informatiques individuelles à plusieurs cœurs. La distribution d'un calcul est un domaine de recherche des sciences mathématiques et informatiques. Elle implique notamment la notion de calcul parallèle.
Historique
Le calcul réparti est un concept qui apparaît dans les années 1970, lorsque le réseau Cyclades français, poussé par la CII et sa Distributed System Architecture, basés sur le Datagramme, tentent de mettre en commun les ressources informatiques des centres universitaires et de grandes entreprises en forte croissance comme EDF ou le Commissariat à l'énergie atomique. Aux États-Unis, IBM et Digital Equipment Corporation créent les architectures SNA et DECnet, en profitant de la numérisation du réseau de téléphone d'AT&T (voir Réseau téléphonique commuté)[1] et ses connexions dédiées à moyen débit. À partir de là, la conception du grand système est concurrencée par les mini-ordinateurs en réseau, comme le Mitra 15 puis le Mini 6, qui viennent le compléter et modifier son architecture.
Système distribué
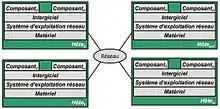
Un système informatique distribué est une collection de postes ou calculateurs autonomes qui sont connectés à l'aide d'un réseau de communication. Chaque poste exécute des composantes, par exemple des séquences de calculs, issues du découpage d'un projet de calcul global, et utilise un middleware, qui s'occupe d'activer des composantes et de coordonner leurs activités de telle sorte qu'un utilisateur perçoive le système comme un unique système intégré[2].
Une propriété importante des systèmes distribués est que la distribution est généralement cachée pour l’utilisateur et les programmeurs de l’application. Ces derniers préfèrent voir l'ensemble comme un seul et unique système, ce qui cache la complexité de la distribution le plus possible et augmente la transparence du système distribué. Cela permet de développer le plus possible les applications de la même façon que les systèmes centralisés.
Un système distribué est généralement séparable en plusieurs composantes entièrement autonomes. Il n’existe pas de composante maître qui gère les autres et chacune est donc responsable de son propre fonctionnement. Cela permet notamment d’avoir une hétérogénéité dans la technologie utilisée pour chaque composante, qui peuvent être écrits dans différents langages de programmation (Java, Cobol, C++, etc.) et s'exécuter sur différents systèmes d'exploitation (Mac OS X, Linux, Windows, etc.). L’autonomie des composantes fait que les systèmes sont exécutés simultanément (programmation concurrente). De plus, contrairement aux systèmes centralisés, les systèmes distribués possèdent plusieurs points de défaillances (problème de composantes, réseau, trafics, etc.).
Exigences des systèmes distribués
Le besoin d'utiliser un système distribué est souvent dérivé d'exigences non fonctionnelles soit :
- extensibilité (« scalability ») – les systèmes distribués permettent facilement une expansion si nécessaire ;
- ouverture – les composantes des systèmes distribués possèdent des interfaces bien définies, ce qui leur permet d'être facilement extensibles et modifiables. Les services web sont un exemple de système distribué qui possède une grande ouverture ;
- hétérogénéité – les composantes peuvent être écrits en différents langages sur différentes machines. Par exemple, les éléments d’un serveur peuvent être programmés en C++ et s'exécuter sous Unix, alors que le client peut être en Java et s'exécuter sous Windows ;
- accès aux ressources et partage – les systèmes distribués fournissent un moyen de partager les ressources, c'est-à-dire à la fois le matériel, le logiciel et les données ;
- tolérance aux pannes – les systèmes distribués peuvent être plus tolérants aux pannes que les systèmes centralisés, car ils permettent de répliquer facilement les composantes.
Projets

Le projet « pionnier », dans l'emploi du calcul distribué est le SETI@home, développé par l'université de Berkeley, en Californie (États-Unis). Ce projet, développé en collaboration avec le programme SETI (Search for Extra-Terrestrial Intelligence), vise la détection d'une possible trace d'activité extraterrestre dans l'espace.
Cependant, le besoin croissant de puissance de calcul informatique dans la recherche médicale et autres domaines est surtout ce qui a suscité l'emploi de plus en plus important de cette technologie. Le coût des superordinateurs étant trop élevé, il est ainsi envisagé d'utiliser la puissance de calcul « disponible » d'ordinateurs au repos (ou sous-utilisés). Le procédé consiste souvent en l'installation d'un logiciel qui télécharge des données brutes à partir d'un serveur, les retravaille (les « traite ») de façon transparente pour l'utilisateur (en n'utilisant que la puissance de calcul non utilisée par les autres applications), puis renvoie les résultats aux serveurs.
Certains systèmes de calcul distribué sont ouverts au public via Internet (cf. Quelques projets de calcul partagé) et attirent facilement les utilisateurs. On peut voir l'évolution du projet depuis ses débuts, le classement des utilisateurs, le temps de calcul réalisé par les possesseurs d'une architecture donnée, ou par tel ou tel système d'exploitation (Linux, Windows, Macintosh, etc.). Plusieurs de ces projets utilisent la plate-forme libre BOINC (Berkeley Open Infrastructure for Network Computing), une évolution du SETI@home original.
Le calcul distribué est aussi un thème actif de recherche, avec une abondante littérature. Les plus connues des conférences sur le calcul distribué sont « The International Conference on Dependable Systems and Networks[3] » et « ACM Symposium on Principles of Distributed Computing[4] ». Il existe également la revue Journal of Parallel and Distributed Computing[5].
Une part importante du génome humain a ainsi pu être décryptée par les internautes du programme « Décrypthon » de l'AFM[6] en collaboration avec le CNRS et IBM[7]. Des projets sont également en cours, centralisés par le World Community Grid visant à l'analyse des protéines et à l'élaboration de solutions contre le sida.
La grande majorité des projets de ce type sont faits par des universités et/ou des professeurs très sérieux diffusant leurs résultats. Le Décrypthon a par exemple contribué au décodage du génome humain qui est maintenant disponible sur Internet sans brevet déposé[8].
Notes et références
- (en) History of Network Switching., sur le site corp.att.com.
- W. Emmerich (2000). Engineering distributed objets. John Wiley & Sons. Ltd.
- « The International Conference on Dependable Systems and Networks » (consulté le ).
- « ACM Symposium on Principles of Distributed Computing » (consulté le ).
- « Journal of Parallel and Distributed Computing » (consulté le ).
- « AFM France » (consulté le ).
- « Les trois partenaires fondateurs du Décrypthon » (consulté le ).
- « National Center of Biotechnology Iinformation » (consulté le ).
Voir aussi
Articles connexes
- Réseaux P2P
- Intelligence distribuée
- BOINC ainsi que Liste des projets BOINC
- Ferme de rendu
- Grille informatique
- Grappe de serveurs
- Algorithme de Naimi-Trehel
- Architecture distribuée
- Robotique en essaim
- Essaim de drones
- Distributed System Architecture
- World Community Grid
- Système d'exploitation distribué
- Algorithmes distribués
Quelques projets de calcul partagé
- Genome@home (en) : séquençage de protéines dans le génome humain, ce projet est achevé puisque la fin du séquençage du génome humain a été annoncée le 14 avril 2003. L'université Stanford l'a remplacé par Folding@Home ;
- Folding@home : simulations de la manière dont les protéines se replient et se déplient sur elles-mêmes ;
- Ibercivis (en) : plusieurs projets de recherche scientifique, maintenus conjointement par les gouvernements espagnol et portugais ;
- Distributed.net : héberge de nombreux projets, dont l'un est la recherche des règles de Golomb optimales ;
- SETI@home : recherche des signes d'une intelligence extraterrestre ;
- GIMPS : rechercher les nombres premiers de Mersenne ;
- Seventeen or Bust : projet pour résoudre le problème de Sierpiński ;
- Africa@Home : projet de lutte contre le paludisme ;
- LHC@Home : simuler la trajectoire de particules élémentaires dans l'accélérateur de particules du CERN près de Genève.