Parallélisme (informatique)
En informatique, le parallélisme consiste à mettre en œuvre des architectures d'électronique numérique permettant de traiter des informations de manière simultanée, ainsi que les algorithmes spécialisés pour celles-ci. Ces techniques ont pour but de réaliser le plus grand nombre d'opérations en un temps le plus petit possible.

Les architectures parallèles sont devenues le paradigme dominant pour tous les ordinateurs depuis les années 2000. En effet, la vitesse de traitement qui est liée à l'augmentation de la fréquence des processeurs connait des limites. La création de processeurs multi-cœurs, traitant plusieurs instructions en même temps au sein du même composant, résout ce dilemme pour les machines de bureau depuis le milieu des années 2000.
Pour être efficaces, les méthodes utilisées pour la programmation des différentes tâches qui constituent un programme sont spécifiques à ce mode de calcul, c'est-à-dire que les programmes doivent être réalisés avec cette optique. Ces méthodes ont initialement été développées de manière théorique et sur des superordinateurs, qui étaient à une période les seuls à compter de nombreux processeurs, mais sont de plus en plus volontiers utilisées par les développeurs de logiciel du fait de l'omniprésence de telles architectures.
Certains types de calculs se prêtent particulièrement bien à la parallélisation : la dynamique des fluides, les prédictions météorologiques, la modélisation et simulation de problèmes de dimensions plus grandes, le traitement de l'information et l'exploration de données, le décryptage de messages, la recherche de mots de passe, le traitement d'images ou la fabrication d'images de synthèse, tels que le lancer de rayon, l'intelligence artificielle et la fabrication automatisée. Initialement, c'est dans le domaine des supercalculateurs que le parallélisme a été utilisé, à des fins scientifiques.
Principes
Les premiers ordinateurs étaient séquentiels, exécutant les instructions l'une après l'autre. Le parallélisme se manifeste actuellement de plusieurs manières : en juxtaposant plusieurs processeurs séquentiels ou en exécutant simultanément des instructions indépendantes.
Différents types de parallélisme : la taxonomie de Flynn
| Une seule instruction |
Plusieurs instructions | |
|---|---|---|
| Donnée unique |
SISD | MISD |
| Plusieurs données |
SIMD | MIMD |
La taxonomie de Flynn, proposée par l'Américain Michael J. Flynn est l'un des premiers systèmes de classification des ordinateurs créés. Les programmes et les architectures sont classés selon le type d'organisation du flux de données et du flux d'instructions.
- Les machines les plus simples traitent une donnée à la fois : ces systèmes sont dits « séquentiels ». Ce type de fonctionnement était prédominant pour les ordinateurs personnels jusqu'à la fin des années 1990. On parle d'architectures SISD (Single Instruction, Single Data).
- Les systèmes traitant de grandes quantités de données d'une manière uniforme ont intérêt à être des SIMD (Single Instruction, Multiple Data) ; c'est typiquement le cas des processeurs vectoriels ou des unités de calcul gérant le traitement du signal comme la vidéo ou le son.
- Les systèmes utilisant plusieurs processeurs ou un processeur multi-cœur sont plus polyvalents et pleinement parallèles, ce sont des MIMD (Multiple Instructions, Multiple Data).
- Le type MISD a été beaucoup plus rarement utilisé, il semble néanmoins adapté à certains problèmes comme les réseaux neuronaux et aux problèmes temps-réel liés. L'architecture appelée réseau systolique est un type d'architecture MISD.
Selon David A. Patterson et John L. Hennessy, « Certaines machines sont des hybrides de ces catégories, bien sûr, mais cette classification traditionnelle a survécu parce qu'elle est simple, facile à comprendre, et donne une bonne première approximation. C'est aussi, peut-être en raison de son intelligibilité, le schéma le plus utilisé. »[1]
Cette approche montre clairement deux types de parallélismes différents : le parallélisme par flot d'instructions également nommé parallélisme de traitement ou de contrôle, où plusieurs instructions différentes sont exécutées simultanément, qui correspond au MIMD et le parallélisme de données, où les mêmes opérations sont répétées sur des données différentes, le SIMD.
Efficacité du parallélisme

L'accélération du programme par la parallélisation est limitée par le nombre d'exécutions parallèles possible au sein de l'algorithme. Par exemple, si un programme peut être parallélisé à 90 %, l'accélération maximale théorique sera de x 10, quel que soit le nombre de processeurs utilisés.
De façon idéale, l'accélération due à la parallélisation devrait être linéaire : en doublant le nombre d'unités de calcul, on devrait réduire de moitié le temps d'exécution, et ainsi de suite. Malheureusement, très peu de programmes peuvent prétendre à de telles performances. Dans les années 1960, Gene Amdahl formula une loi empirique restée célèbre, à laquelle il donna son nom[2]. La loi d'Amdahl affirme que la petite partie du programme qui ne peut être parallélisée limite la vitesse globale du programme. Or tout programme contient nécessairement des parties parallélisables et des parties séquentielles non parallélisables. Cette loi prévoit qu'une fois optimisé, il existe au sein du programme une relation entre le ratio de code parallélisable et la vitesse globale d'exécution du programme. Dans la pratique, cette approximation est utilisée pour fixer une limite à la parallélisation des architectures matérielles ou à l'optimisation de la programmation pour résoudre un problème.
La loi de Gustafson est assez analogue. Plus optimiste, elle prend quant à elle en compte le cas où il est possible d'augmenter la quantité de données sur lesquelles des calculs sont effectués en parallèle : une augmentation du nombre d'unités de calcul permet alors de traiter plus de données en un temps équivalent, alors que la loi d'Amdahl fixe une limite d'efficacité à quantité de données égale.
La métrique de Karp-Flatt proposée en 1990 est plus complexe et efficace que les deux autres lois. Elle intègre le coût lié au temps d'exécution des instructions qui mettent en œuvre le parallélisme.
Plus simplement, Jean Ichbiah montrait qu'en supposant un overhead même léger pour le lancement de chaque processus, il existe un degré optimal de parallélisme, au-delà duquel il est inefficace. Le temps d'exécution est alors du style T(n) = a + b*n + (T(1)-a)/n. Avec T(1)=1, a =0,1 et b=0,005 il vient T(n)= 0,1+0,005n+0,9/n, minimal pour n=13 ou 14.
Autres considérations empiriques
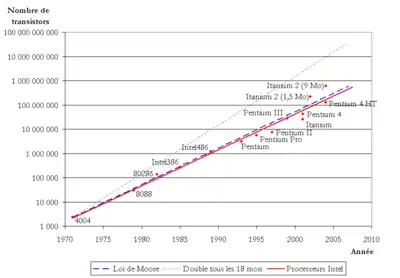
Une autre thèse veut que tout problème pouvant être résolu sur un ordinateur séquentiel raisonnable en utilisant un espace de taille polynomiale puisse être résolu en temps polynomial par un ordinateur parallèle raisonnable et vice versa.
La thèse de l'invariance est une thèse complémentaire qui supporte, du moins de façon approximative, la définition d'une notion d'ordinateur raisonnable. Elle s'énonce comme suit: Des machines raisonnables peuvent se simuler entre elles avec au plus un accroissement polynomial en temps et une multiplication constante de l'espace. Une manière de construire des modèles « raisonnables » est de considérer la classe des machines raisonnables incluant la machine de Turing.
Depuis les années 1960, la densité des transistors dans un microprocesseur double tous les 18 à 24 mois, cette observation est appelée la loi de Moore[3]. En dépit de problèmes de consommation énergétique, la loi de Moore est toujours valable en 2010 (c'est moins vrai en 2020). Les transistors supplémentaires, toujours plus petits, permettent de créer plusieurs unités de calcul, appelé cœurs, au sein du même processeur.
Historique

L'un des premiers modèles de cohérence pour la programmation concourante est celui de Leslie Lamport, c'est celui de la cohérence séquentielle. Il implique que les données produites par un programme concurrent soient les mêmes que celui produit par un programme séquentiel ou plus précisément un programme est séquentiellement cohérent si « les résultats de toute exécution sont le même que si les opérations de tous les processeurs sont exécutées dans un ordre séquentiel, et les opérations de chaque processeur individuelles apparaissent dans cette séquence dans l'ordre indiqué par son programme »[5].
- 1962 : première tentative de rationalisation d'accès cohérent à la mémoire, par Carl Adam Petri dans sa thèse sur les réseaux de Petri.
- 1962 : le D825 de Burroughs Corporation est le premier ordinateur multi-processeur, mais un système non parallèle[6].
- 1964 : le CDC 6600, premier double cœur et premier ordinateur à structure parallèle.
- Début des années 1970 : la théorie du flot de données permet de mettre en œuvre les architectures à flots de données.
- 1969 : la société Honeywell lance son premier système Multics, un système à multiprocesseur symétrique capable de gérer jusqu'à huit processeurs en parallèle.
- Fin des années 1970 : les algèbres de processus telles que Calculus of Communicating Systems et Communicating sequential processes en 1978 sont développées pour permettre de modéliser l'interaction des processus dans un système.
- 1982 : conception du Cray X-MP, deux Cray-1 mis en parallèle.
- 1986 : premier ordinateur massivement parallèle avec 16 000 processeurs.
- Début des années 1990 : le Pi-calcul permet de raisonner sur des typologies dynamiques. La logique modale de Lamport, appelée TLA+ et d'autres modélisations, comme les théories des traces et du modèle d'acteur, ont également été développés pour décrire le comportement des systèmes concurrents.
- 2005 : apparition des microprocesseurs multicœurs pour les ordinateurs personnels.
- 2010 : Intel produit un microprocesseur avec 128 cœurs.
Les programmes
Un programme parallèle est divisé en plusieurs tâches séquentielles s'exécutant simultanément, habituellement appelées processus et peuvent être de plusieurs types selon le système d'exploitation ou la machine virtuelle.
Un tel parallélisme de tâche correspond à une architecture MIMD. En Anglais, on parle de TLP (Thread Level Parallelism).
Certains processus sont dits légers, les anglophones utilisant plutôt le mot Thread, qui peut se traduire par fil d'exécution. Les threads plus légers encore utilisés par certaines architectures sont appelés fibers en anglais, c'est-à-dire fibres en français.
Les synchronisations
Des processus différents peuvent s'exécuter sur des processeurs différents. Plusieurs défis ont donc dû être relevés par la programmation de système parallèle, par exemple celui de traiter des informations sur des processeurs indépendants.
Des langages de programmation concurrente, des interfaces de programmation spécialisées et des algorithmes modèles ont été créés pour faciliter l'écriture de logiciels parallèles et résoudre ces problèmes. La plupart des problèmes de concurrence sont des variantes des problèmes rencontrés dans les modèles appelés producteur-consommateur, lecteur-rédacteur ou Dîner des philosophes. Ils découlent des interactions entre les processus (échange de données, attente...), qui peuvent causer des erreurs ou des blocages si le programmeur les gère mal.
- Dans le problème « producteur-consommateur », des processus dits « producteurs » produisent des données qui sont posées dans une file d'attente, une ressource bornée, ces données sont consommées par les processus dits « consommateurs ». Le fait que la ressource soit bornée implique que les producteurs doivent attendre que la file se vide pour pouvoir en produire une nouvelle, et elle implique que le consommateur patiente quand cette liste est vide. Un mécanisme d'avertissement entre les producteurs et les consommateurs peut être mis en place pour assurer un meilleur fonctionnement au système.
- Dans le modèle « lecteur-rédacteur », spécialisé dans le traitement des flux, c'est-à-dire du filtrage, les débits respectifs de l'un et l'autre peuvent causer, une famine du fait de la lenteur du lecteur, l'obsolescence du fait de la lenteur du rédacteur ou d'une manière plus particulière encore du fait de la mise à jour des données. La principale difficulté du programmeur est d'écrire des algorithmes qui produisent des débits comparables pour les uns et les autres.
- Enfin, le modèle du « Dîner des philosophes » est le modèle le plus fréquent, car les cas où l'échange d'information entre processus peut se faire par simple accès à des données via une zone mémoire partagée sont rares et les données, lorsque cette manière de faire est utilisée, doivent n'avoir soit aucun rapport entre elles soit n'avoir pas besoin d'être mis à jour sans quoi des problèmes de compétition surgissent. Ainsi, plusieurs mécanismes adaptés à des échanges plus polyvalents ont donc été inventés, répondant chacun au mieux à un problème spécifique, comme les tubes anonymes adaptés aux filtrages ou les files d'attente de messages permettant de diminuer l'attente active dans le modèle producteur-consommateur.
Le choix du mécanisme d'échange de données dépend aussi du type d'architecture à laquelle le langage, l'interface ou l'algorithme est destiné. Autrement dit, un programme destiné à s'exécuter sur une architecture à mémoire partagée ne serait pas identique à celui destiné à une architecture à mémoire distribuée ou à une architecture mixte. Les programmes s'exécutant sur les architectures partagées vont pouvoir simplement partager des zones mémoires, alors que les systèmes à mémoire distribué vont devoir échanger des messages via un bus ou un réseau. POSIX Threads et OpenMP sont, en 2010, les deux bibliothèques spécialisées les plus utilisées pour une exécution en mémoire partagée, tandis que le protocole Message Passing Interface l'est pour du passage de message[7].
Les problèmes dits de « synchronisation » et même plus généralement ceux de communication inter-processus dont ces derniers dépendent, rendent pratiquement toujours la programmation plus difficile malgré la volonté des programmeurs de produire un code source « Threadsafe ».
Partage des données
Au sein des ordinateurs parallèles, la mémoire vive peut être soit partagée, soit distribuée. Dans les premières, l'échange de donnée est plus simple, mais nécessite dans la plupart des cas l'usage de mécanismes logiciels particuliers difficiles à programmer efficacement et un bus mémoire à large bande passante. Pour le second cas la bande passante est moins cruciale autrement dit les répercussions d'un flux important sur la vitesse de traitement globale sont plus faibles, mais nécessite l'appel à un système de transmission des données explicite plus lourd.
Dépendance des données
La connaissance des dépendances entre les données est fondamentale dans la mise en œuvre d'algorithmes parallèles. Puisqu'un calcul qui dépend du résultat d'un calcul préalable doit être exécuté séquentiellement, aucun programme ne peut s'exécuter plus vite que l'exécution du plus long des enchainements de calculs, c'est-à-dire le chemin critique. Un des gains de performance dus au parallélisme se trouve donc dans l'exécution de calculs indépendants et des chemins non critiques en simultané. Les conditions de Bernstein[8] permettent de déterminer lorsque deux parties de programme peuvent être exécutées en parallèle. Ceci se formalise ainsi :
Soit Pi et Pj deux fragments de programme. Pour Pi, avec Ii les variables d'entrées et Oi les variables de sorties, et de même façon pour Pj. P i et Pj sont indépendants s'ils satisfont les conditions suivantes :



La violation de la première de ces conditions implique une dépendance des flux, c'est-à-dire que le premier fragment produit un résultat utilisé par le second. La seconde condition est une condition d'« antidépendance », le premier fragment écrase (c.-à-d. remplace) une variable utilisée par le second. La dernière condition est une condition sur les sorties, lorsque les deux fragments écrivent une même donnée, la valeur finale est celle produite par le fragment exécuté en dernier[9].
Considérons les fonctions suivantes, qui démontrent plusieurs sortes de dépendances :
|
L'opération 3 dans Dep (a, b) ne peut pas être exécutée avant (ni même en parallèle avec) l'opération 2, car l'opération 3 utilise un résultat d'exploitation 2. Il viole la condition 1, et introduit ainsi une dépendance de flux. |
|
Dans cet exemple, il n'y a pas de dépendances entre les instructions, de sorte qu'elles peuvent être exécutées en parallèle. |
Les conditions de Bernstein ne permettent pas de gérer l'accès à la mémoire entre différents processus. Pour ce faire il faut utiliser des outils logiciels comme les moniteurs, les barrières de synchronisation ou toute autre méthode de synchronisation.
Accès aux données

Pour accélérer les traitements effectués par les différentes unités de calcul, il est efficace de multiplier les données, c'est typiquement le cas lors de l'utilisation des caches. Ainsi l'unité de calcul travaille à partir d'une mémoire, spécialisée si possible, qui n'est pas la mémoire partagée par l'ensemble des unités de calculs. Lorsque le programme modifie une donnée dans ce cache, le système doit en fait la modifier dans l'espace commun et répercuter cette modification au sein de tous les caches où cette donnée est présente. Des mécanismes sont mis en place pour que les données restent cohérentes. Ces mécanismes peuvent être décrits par de complexes modèles d'algèbres de processus et ces derniers peuvent être décrits de plusieurs manières au sein de divers langages formels. Le mécanisme à mémoire transactionnelle logicielle est le plus courant des modèles de cohérence, il emprunte à la théorie des systèmes de gestion de base de données la notion de transactions atomiques et les applique aux accès mémoire.
En outre, certaines ressources ne peuvent être disponibles en même temps que pour un nombre restreint de tâches. C'est typiquement le cas pour l'accès en écriture sur un fichier sur disque par exemple. Alors que celui-ci est disponible pour théoriquement un nombre infini en lecture seule, le fichier n'est disponible que pour une seule tâche en lecture-écriture, toute lecture par un autre processus est alors proscrite. La réentrance est le nom de la propriété du code lorsque celui-ci peut être utilisable simultanément par plusieurs tâches.
Situation de compétition
Les processus ont souvent besoin d'actualiser certaines variables communes sur lesquelles ils travaillent. Les accès à ces variables se font d'une manière indépendante, et ces accès peuvent occasionner des erreurs.
| Thread A | Thread B | Dans l'illustration ci-contre, le résultat d'exécution n'est pas prévisible, du fait que vous ne pouvez savoir quand les Thread A et B s'exécutent, cela dépend en effet de la manière dont les exécutions se chevauchent. Dans l'hypothèse la plus simple ou les thread A et B s'exécutent une fois, l'ordre d'exécution des instructions peut être par exemple : Lire, Lire, Add, Add, Écrire, Écrire ou bien Lire, Add, Écrire, Lire, Add, Écrire. Le résultat dans ces deux hypothèses n'est pas le même puisqu'au final dans le second cas la variable est augmentée de deux alors qu'elle n'est augmentée que de un dans le premier. |
|---|---|---|
| 1A: Lire variable V | 1B: Lire variable V | |
| 2A: Add 1 à la variable V | 2B: Add 1 à la variable V | |
| 3A: Écrire la variable V | 3B: Écrire la variable V |
Ce phénomène est connu sous le nom de situation de compétition. Pour résoudre ce genre de problème, le système doit permettre au programmeur d'éviter certaines situations de concurrence, grâce à des opérations dites « atomiques », du grec ancien ατομος (atomos), qui signifie « que l'on ne peut diviser[10] ».
Il peut par exemple utiliser un verrou d'exclusion mutuelle.
| Il existe concrètement plusieurs techniques pour obtenir des verrous et des sections critiques où l'accès aux données est « sécurisé » comme ci-contre, mais ce genre de mécanismes est source potentielle de bug informatique. | Thread A | Thread B |
|---|---|---|
| 1A: Verrouiller la variable V | 1B: Verrouiller la variable V | |
| 2A: Lire la variable V | 2B: Lire la variable V | |
| 3A: Add 1 à la variable V | 3B: Add 1 à la variable V | |
| 4A: Écrire la variable V | 4B: Écrire la variable V | |
| 5A: déverrouiller la variable V | 5B: déverrouiller la variable V |
Un fort couplage augmente le risque de bugs, aussi il est recommandé au programmeur de les minimiser. En effet si deux tâches doivent chacune lire et écrire deux variables et qu'elles y accèdent en même temps, cela doit être fait avec précaution. Si la première tâche verrouille la première variable pendant que la seconde tâche verrouille la seconde, alors les deux tâches seront mises en sommeil. Il s'agit là d'un cas d'interblocage, autrement appelé d'« étreinte mortelle » ou « étreinte fatale ».
Certaines méthodes de programmation, dites non bloquantes, cherchent à éviter d'utiliser ces verrous. Elles utilisent elles-mêmes des instructions atomiques. La mémoire transactionnelle logicielle en est une.
Efficacité et limites
D'une manière générale, plus le nombre de tâches est élevé dans un programme, plus ce programme passe son temps à effectuer des verrouillages et plus il passe son temps à échanger des messages entre tâches. Autrement lorsque le nombre de tâches augmente trop, la programmation concourante ne permet plus d'augmenter la vitesse d'exécution du programme ou plus précisément de diminuer la durée de son chemin critique, car le programme passe son temps à mettre en sommeil les tâches qui le composent et à écrire des informations qui permettent l'échange d'information entre tâches. Ce phénomène est appelé le ralentissement parallèle.
D'ailleurs les applications sont souvent classées en fonction de la fréquence à laquelle leurs tâches dialoguent ou se synchronisent. Les applications ayant beaucoup d'échanges ou de synchronisations entre leurs sous-tâches sont dites fine-grained (à grain fin), celles qui ont au contraire peu d'échanges et de synchronisations sont dites coarse-grained c'est-à-dire à gros grain. L'algorithme est dit embarrassingly parallel, c'est-à-dire de « parallélisme embarrassant » s'il n'y a aucun contact entre les sous-tâches. Ce dernier est le plus simple à programmer.
Algorithmique
Si certains problèmes sont simplement divisibles en multiples sous-problèmes exécutables par différents processus, ce n'est pas le cas de tous. Par exemple, s'il est simple de paralléliser la recherche de la liste des nombres premiers en attribuant à chaque processeur une liste de nombres et en regroupant les résultats à la fin, il est plus difficile de le faire, par exemple, pour le calcul de π puisque les algorithmes habituels, bâtis sur le calcul de séries, évaluent cette valeur par approximations successives de plus en plus précises. Le calcul des séries, les méthodes itératives, comme la méthode de Newton et le problème des trois corps, les algorithmes récursifs comme celui du parcours en profondeur des graphes sont par conséquent très difficiles à paralléliser.
Problématique sériel ou temporel
Lors de calcul de fonctions récursives, une dépendance est créée au sein d'une boucle, l'exécution de celle-ci ne peut s'effectuer que lorsque la précédente s'est effectuée. Ceci rend le parallélisme impossible. Le calcul de la suite de Fibonacci en est un cas d'école, comme l'illustre le pseudo-code suivant :
PREV1 := 0
PREV2 := 1
do:
CUR := PREV1 + PREV2
PREV1 := PREV2
PREV2 := CUR
while (CUR < 10)
Ce n'est cependant pas le cas de tous les algorithmes récursifs, lorsque chaque fonction a un traitement suffisant à effectuer, ils peuvent même être plus efficaces que des algorithmes composés de boucle en raison de leur nature : « diviser pour régner ». C'est par exemple le cas pour deux algorithmes de tri récursifs, le Tri rapide et plus particulièrement le Tri fusion. En outre ces deux algorithmes ne créent pas de situation de compétition et il n'est donc pas nécessaire de synchroniser les données.
Si l'algorithme permet de créer une liste de taches par processeurs en un temps moyen , et si les processeurs effectuent les tris dans un temps moyen , alors l'accélération est optimum. Dans ce cas, une augmentation du nombre de processeurs n'accélérerait pas le traitement.




Les patrons de conception de synchronisation
Des fonctions particulières peuvent être fournies par des bibliothèques pour permettre la synchronisation et la communication entre différents fils d'exécution.
Les mutex
Une mutex (de mutual exclusion, exclusion mutuelle), se comporte comme un verrou : un processus peut la verrouiller pour obtenir un accès exclusif à certaines ressources, et tout processus qui tentera ensuite de l'obtenir sera bloqué jusqu'à ce que le premier processus la libère.
Les spinlocks
Les spinlocks, ou verrous tournants, sont analogues aux mutexs, mais les processus bouclent en attendant que le verrou se libère plutôt que d'être bloqués. La reprise est plus rapide, car il n'y a pas de changements de contexte, mais le processus utilise des ressources inutilement.
Les barrières de synchronisation
Une barrière de synchronisation permet de synchroniser un certain nombre de processus à un point précis de leur exécution, en les forçant à attendre jusqu'à ce que suffisamment d'entre eux l'aient atteint.
Conséquences du parallélisme pour le code produit
Pour générer du code adapté à une utilisation multi-threads, les programmes doivent être compilés avec des méthodes spécifiques : un code qui peut être exécuté simultanément par plusieurs threads est qualifié de réentrant. En particulier, pour les bibliothèques chargées dynamiquement, qui sont utilisées simultanément par plusieurs programmes, l'adressage interne doit être relatif, c'est-à-dire qu'un ensemble d'instructions peut s'exécuter convenablement quel que soit l'emplacement mémoire où il est stocké. Le code peut donc être dupliqué, et l'exécution simultanée d'un même code en plusieurs exemplaires ne pose aucun problème.
Parallélisation automatique
Certains compilateurs cherchent à rendre parallèle un code séquentiel, ce qui peut améliorer ses performances, particulièrement pour du calcul intensif. Il va s'agir de paralléliser les tâches entre différents threads. Plus simplement, ils peuvent aussi tirer parti des instructions SIMD de certains processeurs pour paralléliser les calculs.
Pipeline et parallélisme au niveau des instructions
Certains jeux d'instructions, comme ceux de type VLIW et EPIC, nécessitent que le compilateur repère les instructions à exécuter en parallèle et optimise le code en conséquence. Pour les autres architectures, même si ce n'est pas nécessaire pour produire un code correct, le compilateur peut optimiser le code afin d'utiliser au mieux le parallélisme d'instructions fourni par le processeur.
Le système d'exploitation
Le système d'exploitation, via son ordonnanceur, ou l'intergiciel doit répartir les calculs de manière à optimiser l'utilisation des unités de calcul, problème connu sous le nom de répartition de charge. Pour que ce soit efficace, il faut que les applications soient écrites de telle façon que les algorithmes soient constitués de tâches, c'est-à-dire écrits par « tranches » dont les exécutions pourront se faire de manière relativement indépendante les unes des autres sur les différentes unités de calcul.
Il fournit aussi des primitives simples de synchronisation et de passage de messages.
Le matériel
Pipeline
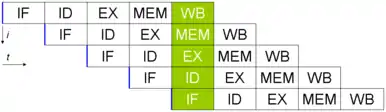
Il faut 9 cycles pour exécuter 5 instructions. À t = 5, tous les étages du pipeline sont sollicités, et les 5 opérations ont lieu en même temps.
Un programme informatique est, par essence, un flux d'instructions exécuté par un processeur. Chaque instruction nécessite plusieurs cycles d'horloge, l'instruction est exécutée en autant d'étapes que de cycles nécessaires. Les microprocesseurs séquentiels exécutent l'instruction suivante lorsqu'ils ont terminé la première. Dans le cas du parallélisme d'instruction, le microprocesseur peut traiter plusieurs de ces étapes en même temps pour plusieurs instructions différentes, car elles ne mobilisent pas les mêmes ressources internes. Autrement dit, le processeur exécute en parallèle des instructions qui se suivent à différents stades d'achèvement. Cette file d'exécution s'appelle un pipeline. Ce mécanisme a été mis en œuvre pour la première fois dans les années 1960 par IBM.
L'exemple canonique de ce type de pipeline est celui d'un processeur RISC, en cinq étapes. L'Intel Pentium 4 dispose de 35 étages de pipeline[11].
Des processeurs plus évolués exécutent en même temps autant d'instructions qu'ils ont de pipelines, à la condition que les instructions de tous les étages soient indépendantes c'est-à-dire que l'exécution de chacune ne dépende pas du résultat du calcul d'une autre (on ne peut pas calculer δ=α+β sans connaitre α). Les processeurs de ce type sont appelés superscalaires. Le premier ordinateur à être équipé de ce type de processeur était le Seymour Cray CDC 6600 en 1965. L'Intel Pentium est le premier des processeurs superscalaires pour compatible PC. Ce type de processeur s'est imposé pour les machines grand public à partir des années 1980 et jusqu'aux années 1990[12].
Exécution dans le désordre et renommage de registres
Des instructions indépendantes peuvent être exécutées en parallèle par différentes unités de calcul. Pour pouvoir utiliser ce parallélisme, certains processeurs réordonnent les instructions de manière à augmenter le parallélisme : on parle d'exécution dans le désordre, ou out-of-order.
Pour augmenter encore les possibilités de parallélisation, certains processeurs utilisent le renommage de registres. Les registres qui sont utilisés plusieurs fois (par exemple lors de boucles) introduisent en effet des dépendances entre instructions. Pour éviter celles-ci, le processeur dispose de plus de registres physiques que de registres architecturaux, et chaque nouvelle écriture est faite dans un nouveau registre physique. Ainsi, certaines dépendances peuvent être éliminées (Write-after-read et Write-after-write), permettant au processeur d'exécuter plus d'instructions en parallèle.
VLIW et EPIC
Les instructions peuvent aussi exprimer elles-mêmes le parallélisme disponible : c'est le principe qui gouverne les processeurs VLIW (Very Long Instruction Word). Dans ceux-ci, les instructions sont regroupées en longs "mots" de taille fixe, celles composant un même mot étant exécutées en parallèle. Le compilateur doit alors optimiser lui-même le code.
L'architecture EPIC utilise le même principe.
Systèmes à plusieurs processeurs
 |
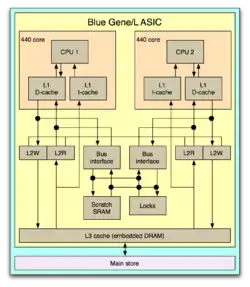 | |
Le Blue Gene L dispose de seize cartes-nœuds (à gauche) pour un total de 440 cœurs organisés suivant le schéma de droite. | ||
Histoire
L'idée de faire cohabiter deux processeurs dans la même machine date des années 1960, le D825 de Burroughs Corporation commercialisé en 1962 est le premier ordinateur multi-processeur, mais ce système n'était pas parallèle[6]. Il a fallu attendre 1969 pour que Honeywell produise le premier ordinateur qui dispose de processeurs fonctionnant réellement en parallèle. Les huit processeurs[13] de cette machine de la série Honeywell 800 fonctionnaient de manière symétrique[14] (ou SMP), c'est-à-dire que tous les processeurs ont la même fonction et les mêmes capacités. Ce ne fut pas le cas de toutes les machines, DEC et le MIT ont développé dans les années 1970 une technologie asymétrique, mais elle a été abandonnée dans les années 1980. Peu de machines ont utilisé ce principe, même si certaines ont eu du succès comme les VAX.
Organisation de la mémoire
Dans des systèmes multiprocesseurs, l'organisation de la mémoire peut varier : on peut distinguer les cas où la mémoire est accédée de la même manière par tous les processeurs (accès symétrique, ou Symetric Multiprocessing), et ceux où la mémoire est répartie de telle manière que les processeurs n'accèdent pas aussi rapidement à toutes les adresses (accès non uniforme).
Dans un système symétrique les processeurs se synchronisent et échangent des données via un bus[15]. Historiquement, ces systèmes étaient limités à 32 processeurs[16], en effet au-delà, les contentions de bus deviennent ingérables. Cependant « Grâce à la petite taille des processeurs et à la réduction significative des exigences en bande passante du bus obtenue par la taille importante des caches, les systèmes à multiprocesseurs symétriques sont d'un excellent rapport coût-efficacité, à condition toutefois qu'il existe une bande passante mémoire suffisante »[15].
Les architectures NUMA sont un exemple de solution : il s'agit de systèmes où les zones mémoires sont accessibles par l'intermédiaire de différents bus, c'est-à-dire que chaque zone mémoire est réservée à un ou quelques processeurs seulement et que les données qui y sont stockées ne sont disponibles que via un passage de message analogue à celui mis en place pour les mémoires distribuées. Dans tous les cas, les temps d'accès diffèrent en fonction des processeurs et des zones mémoires visées. Ce système peut être vu comme une étape entre le SMP et le clustering.
Cohérence de la mémoire et opérations atomiques
Lorsqu'une même mémoire est accédée par plusieurs processeurs ou cœurs, des accès à une même adresse peuvent être effectués par plusieurs d'entre eux. En particulier, les modifications effectuées doivent être visibles par tous les processeurs au bout d'un certain temps. Cela affecte entre autres le fonctionnement des mémoires caches, car une modification par un processeur oblige à invalider la donnée dans tous les caches. C'est le problème de la cohérence de la mémoire.
Selon les architectures, la cohérence de la mémoire peut être plus ou moins forte. De plus, certaines opérations atomiques, à la base des primitives de synchronisation, sont souvent fournies par le matériel. Enfin, l'opération d'écriture peut aussi être atomique, de manière que deux mots écrits par des processeurs différents ne soient pas mélangés en mémoire. Ces différents mécanismes permettent une coopération efficace entre les processeurs.
Multicœur
Grâce à la miniaturisation, il est devenu possible de réunir plusieurs processeurs sur une même puce. On parle alors de processeurs multicœurs. Leur fonctionnement est similaire à celui des multiprocesseurs, et ils utilisent généralement un accès symétrique à la mémoire, avec plusieurs niveaux de cache partagés ou non par plusieurs cœurs.
Partage des unités d'exécution
Il est aussi possible de simuler le comportement d'un ordinateur multicœur sans juxtaposer réellement plusieurs cœurs sur une même puce. Un même cœur peut alors exécuter plusieurs processus simultanément en partageant certaines unités d'exécution entre eux (on parle de simultaneous multithreading), ou les exécuter en alternance.
Cela permet d'obtenir certains avantages des multiprocesseurs avec une augmentation modérée de la taille du circuit, de tirer parti de threads qui n'utilisent pas les mêmes ressources ou d'utiliser le processeur même lorsque l'un des threads est en attente (par exemple lors d'un accès à la mémoire).
Systèmes à plusieurs machines
Pour faire fonctionner en parallèle un plus grand nombre de processeurs, on peut utiliser plusieurs machines qui communiquent ensemble via un réseau. Selon les cas, il peut s'agir d'un réseau d'interconnexion spécialement conçu ou d'internet, comme pour BOINC. On distingue les grappes de serveurs, où toutes les machines sont du même type, des grilles, où des machines de caractéristiques différentes sont utilisées.
Coprocesseurs
Les coprocesseurs sont des unités destinées à fournir des fonctionnalités supplémentaires au processeur, ou des circuits spécialisés pour des applications particulières. Certaines de ces applications sont facilement parallélisables, comme les calculs graphiques. Beaucoup de coprocesseurs graphiques actuels permettent aussi de réaliser des calculs parallèles sans qu'il s'agisse nécessairement de création d'image.
Motivations technologiques
Trois facteurs principaux ont contribué à la forte tendance actuelle en faveur du traitement parallèle.
Coût du matériel
Il a décru de manière constante, de sorte qu'il est aujourd'hui possible de construire des systèmes à multiprocesseurs à moindre coût.
Intégration à très grande échelle
La technologie des circuits a progressé à un tel point qu'il est devenu possible de fabriquer des systèmes complexes nécessitant des millions de transistors sur une seule puce.
On peut alors augmenter le nombre d'unités de calcul et ajouter des unités de calculs vectoriels ou créer des processeurs multicœurs en juxtaposant plusieurs processeurs.
Vitesse de traitement des ordinateurs
La vitesse des traitements séquentiels traditionnels, basés sur le modèle de von Neumann, semble s'approcher de la limite physique au-delà de laquelle il n'est plus possible d'accélérer. On peut en revanche disposer :
- d'unités de calcul vectoriel ;
- de plusieurs processeurs dans la même puce ;
- de plusieurs puces sur la même carte mère ;
- de plusieurs cartes mères dans le même châssis.
C'est sur la combinaison de ces principes que sont construits les ordinateurs les plus puissants du moment (Roadrunner 2008).
Notes et références
- (Computer Organization and Design, p. 748)
- Amdahl, G., The validity of the single processor approach to achieving large-scale computing capabilities, AFIPS Press, coll. « In Proceedings of AFIPS Spring Joint Computer Conference, Atlantic City, N.J. », , pp. 483–85
- (en) Gordon E. Moore, « Cramming more components onto integrated circuits » [PDF], Electronics Magazine, (consulté le ), p. 4
- (en) John L. Hennessy, David A. Patterson et James R. Larus, Computer organization and design : the hardware/software interface, San Francisco, Kaufmann, , 2. ed., 3rd print. éd., 759 p. (ISBN 1-55860-428-6)
« (pp. 749–50) Although successful in pushing several technologies useful in later projects, the ILLIAC IV failed as a computer. Costs escalated from the $8 million estimated in 1966 to $31 million by 1972, despite the construction of only a quarter of the planned machine. It was perhaps the most infamous of supercomputers. The project started in 1965 and ran its first real application in 1976. »
- (en) Leslie Lamport, « How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs », IEEE Transactions on Computers, vol. C-28, no 9, , p. 690–91.
- (en) Philip H. Jr. Enslow, « Multiprocessor Organization - A Survey », Computing Surveys, vol. 9, , p. 103-129.
- (en) Le Sidney Fernbach Award given to MPI inventor Bill Gropp faisant référence à MPI comme the dominant HPC communications interface c'est-à-dire l'interface de communication dominant pour le calcul intensif
- A. J. Bernstein, « Program Analysis for Parallel Processing », IEEE Trans. on Electronic Computers, no EC-15, , p. 757–62.
- (en) Seyed H. Roosta, Parallel processing and parallel algorithms : theory and computation, New York/Berlin/Heidelberg, Springer, , 566 p. (ISBN 0-387-98716-9, lire en ligne), p. 114.
- Informations lexicographiques et étymologiques de « atome » dans le Trésor de la langue française informatisé, sur le site du Centre national de ressources textuelles et lexicales
- (en) Patt, Yale, « The Microprocessor Ten Years From Now: What Are The Challenges, How Do We Meet Them? (wmv). Distinguished Lecturer talk at Carnegie Mellon University » [archive du ], (consulté le ). Consulté le 7 novembre 2007.
- (Culler et al, p. 15)
- (en) « Guide of parallele computing », sur ctbp.ucsd.edu (consulté le )
- « Honeywell - Series 200 », sur feb-patrimoine.com (consulté le )
- (Patterson et all, 1998, p. 549)
- (Patterson et all, 1998, p. 719)
Voir aussi
Bibliographie
- (en) Patterson, David A. et John L. Hennessy, Computer Organization and Design, Morgan Kaufmann Publishers, (réimpr. Second Edition) (ISBN 1-55860-428-6).
- Culler, David E., Jaswinder Pal Singh et Anoop Gupta, Parallel Computer Architecture : A Hardware/Software Approach, Morgan Kaufmann Publishers, (ISBN 1-55860-343-3).
Articles connexes
Le parallélisme, au départ, concerne uniquement le fait d'exécuter des calculs en parallèle. D'autres domaines de l'informatique s'en rapprochent : les systèmes de fichiers distribués et le RAID (on préfère dans ce cas le terme d'agrégation), ainsi que des techniques permettant la gestion des échecs matériels et logiciels, utilisent le même principe d'utilisation de plusieurs ressources. Les systèmes de fichiers distribués et la tolérance aux erreurs sont des techniques très liées au calcul parallèle, qui se développent avec l'avènement des architectures distribuées et du calcul en réseau.
Logiciels
Sujets généraux
Langages de programmation
- Ada
- Erlang
- Alpha
- C
- UPC
- Fortran supporte nativement le calcul parallèle depuis Fortran 2008
- Linda (en)
- Occam
- Parsec
- Sisyc
- C# (C Sharp), VB.Net (Visual Basic .NET), J# (J Sharp), F# (F Sharp) avec la nouvelle Bibliothèque Parallèle de Tâches (Task Parallel Library) et l'évolution vers le parallélisme de LINQ en PLINQ de la plateforme .Net version 4.0
Bibliothèque de programmation
Liens externes
- Cours de l’École Polytechnique sur la programmation concurrente en Java, avec quelques considérations matérielles.
- Bibliothèque parallèle de tâches (Task Parallel Library).
- PLINQ.
- (en) Internet Parallel Computing Archive
- (en) IEEE Distributed systems online
- (en) « HPCC Grand Challenges »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?) (consulté le )
- (en) Nan's Parallel Computing Page
- (en) OpenHMPP, New Standard for Manycore