Architecture Dataflow
Le dataflow (en français : flux de données) est une architecture où les données sont des entités actives qui traversent le programme de manière asynchrone, contrairement à l'architecture classique von Neumann, où elles attendent passivement en mémoire pendant que le programme est exécuté séquentiellement suivant le contenu du pointeur de programme (PC). On parle aussi d'ordinateur cadencé par les données.
Principe de fonctionnement
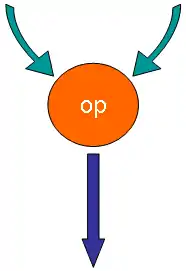
Dans une architecture flux de données, les programmes sont représentés sous forme de graphes : un nœud représente une opération à effectuer, tandis que les données circulent sur les arcs et forment les entrées aux nœuds. Les données sont transportées par des jetons (tokens). La règle de base, dite « de déclenchement », instaure que lorsqu'un nœud voit toutes ses entrées satisfaites, il est activé et produit une valeur en sortie, et les jetons présents en entrée sont supprimés.
Ces architectures sont étroitement couplées aux langages de programmation fonctionnelle. Elles ne génèrent pas d'effet de bord, donc ne nécessite pas de mémoire partagée, ni de séquenceur ou de pointeur de programme. Elles sont aussi éminemment parallèles : l'unité responsable de l'exécution des instructions issue de la mémoire contenant le programme doit posséder un nombre relativement élevé de processeurs (16 et plus) afin de maximiser la puissance totale de l'ordinateur.
Plusieurs unités de calcul traitant des données différentes les classent dans la famille des ordinateurs MIMD (Multiple Instructions, Multiple Data).
Les graphes comme langage
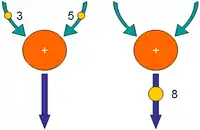
Un nœud computationnel peut être représenté comme le sommet d'un graphe. Les jetons circulent sur les arcs reliant les sommets. Quand deux jetons contenant respectivement les valeurs 3 et 5 se présentent aux entrées du nœud, celui-ci exécute l'opération pour laquelle il est conçu (ici une addition), génère un jeton en sortie représentant la somme (3 + 5), 8, et supprime les jetons d'entrée :
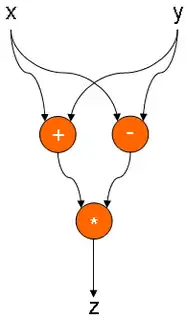
L'expression plus complexe z = (x + y) × (x - y) correspond au graphe ci-dessous. On constate que le parallélisme est implicite : les deux nœuds + et - sont activables simultanément.
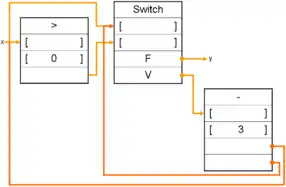
Grâce à deux types de nœuds appelés switch et merge, on peut coder la condition si. Le premier type possède deux entrées et deux sorties, tandis que le second possède trois entrées et une sortie. Le type switch répercutera son jeton d'entrée sur l'une ou l'autre de ses sorties suivant l'état de sa seconde entrée. Le type merge fera la sélection d'un de ses deux jetons d'entrée suivant la valeur d'un troisième. Schématiquement :
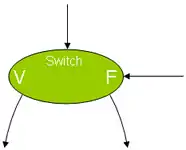 Un nœud de type switch. V et F tiennent lieu de Vrai et Faux. |
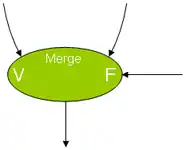 Un nœud de type merge. V et F tiennent lieu de Vrai et Faux. |
Voici deux exemples de ces instructions, dans un test conditionnel et dans une boucle. Notez l'initialisation à Faux sur le nœud merge pour correctement sélectionner la valeur de x.
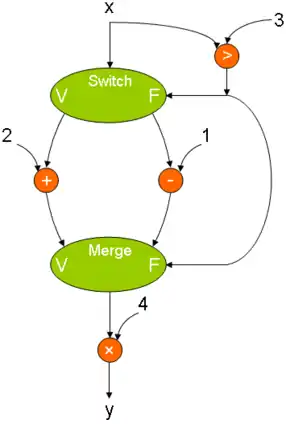 Le graphe du programme y = (IF x > 3 THEN x + 2 ELSE x -1) × 4. |
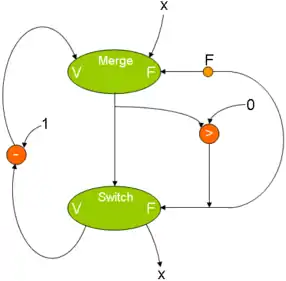 Le graphe du programme WHILE x > 0 DO x - 1. |
Implications de l'utilisation de graphes
- Localité : les interdépendances entre les données sont très localisées, contrairement aux langages impératifs habituels qui utilisent des variables globales (situées « loin » des procédures qui sont susceptibles de les modifier).
- Pas d'effets de bord, pas de notion de passage de paramètres par référence : les valeurs sont dupliquées.
- Dépliage des boucles : pour paralléliser l'exécution des boucles, le code doit être déplié pour que chaque itération puisse être exécutées en parallèle.
- Règle de la référence unique :
- le nom d'une variable ne peut apparaître qu'une seule fois dans une assignation. Pour éviter cela, on renomme la variable à partir de ce point, et on utilise ce nouveau nom par la suite. Par exemple :
| X = P - Q | X = P - Q |
| X = X × Y | X1 = X × Y |
| W = X - Y | W = X1 - Y |
- Cette règle a été proposée en 1968.
Structure des graphes
Pour mieux comprendre comment les programmes flot de données peuvent être exécutés par un ordinateur, il est plus aisé de représenter les graphes sous la forme d'une collection de structures reliées entre elles par des pointeurs.
Le premier graphe z = (x + y) × (x - y) peut être représenté par cette structure :
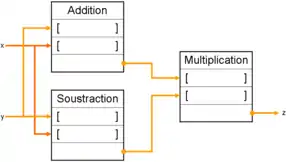
Chaque nœud est représenté par un bloc dont le premier élément est l'opération à effectuer, puis suivent les emplacements indiqués par des parenthèses « [ ] » qui sont destinées à contenir les paramètres de l'opération, ainsi que des emplacements contenant les adresses où sera placé le résultat. Certains emplacements peuvent éventuellement contenir des constantes.
Les itérations ne posent pas de problème non plus, ci-dessous la structure de la boucle WHILE précédemment évoquée :
Types de machine
Il existe plusieurs types d'ordinateur flot de données, mais on peut distinguer deux modèles :
- Le modèle statique : il n'y a qu'un seul jeton sur un arc à un instant donné ;
- Le modèle dynamique : il peut y avoir plusieurs jetons en attente sur un arc.
Des machines hybrides dataflow/von Neumann ont aussi été conçues (MIT P-RISC).
Machines statiques
Rentrent dans cette catégorie la machine conçue par Jack Dennis du Massachusetts Institute of Technology en 1974. La difficulté rencontrée sur cette architecture est la contrainte de n'avoir qu'une seule valeur (jeton) sur un arc à un moment donné (car on ne peut pas faire de différence entre les jetons). Elle est effacée par l'utilisation de jetons de contrôles qui acquiescent la transmission des données d'un nœud à un autre.
Machines dynamiques
Ces machines associent un marqueur (tag), ou une couleur, à chaque jeton. La règle de base est modifiée, et devient : « lorsqu'un nœud voit toutes ses entrées satisfaites par des jetons de même couleur, il est activé et produit une valeur en sortie, avec sa propre couleur, et les marqueurs et jetons d'entrées sont effacés ». L'architecture en est simplifiée et le dépliage des boucles se fait tout seul : il est créé autant de couleurs et jetons que nécessaire.
Exemple : la machine dataflow dynamique de Manchester
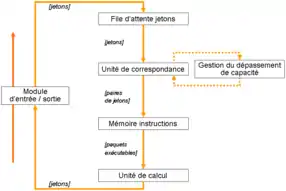
Son architecture simplifiée est représentée par la figure ci à droite. Elle est volontairement simplifiée, mais est tout à fait représentative des machines de type dynamique. On remarque immédiatement qu'elle est très facilement « pipelinable », ce qui bien sûr améliore sensiblement les performances. Il est spécifié en caractères italiques le type de paquets circulant entre deux unités.
Les jetons appartenant à une même instruction sont appairés dans l'unité de correspondance. Ils sont envoyés vers l'unité où sont stockées les instructions, d'où ils chargent les instructions dont ils dépendent. Ces paquets enfin exécutables sont dirigés vers l'unité de calcul qui, à la suite de l'exécution de l'instruction reçue en entrée, va émettre de nouveaux jetons. L'unité d'entrée/sortie sert à communiquer avec l'ordinateur externe qui contrôle la machine dataflow, par le biais du bus schématisé verticalement, qui permet l'injection de paquets ou bien leur récupération. La file d'attente « jetons » est simplement une mémoire tampon FIFO.
Les jetons sont formés de :
- 37 bits de données, associées à
- un marqueur de 36 bits suivi de
- une adresse de destination sur 22 bits, puis
- un second marqueur de 1 bit.
Étant donné que de larges itérations ou de vastes ensembles de données peuvent provoquer un dépassement de capacité (en nombre de jetons), une unité particulière est couplée à l'unité de correspondance pour pallier ce cas. L'unité de calcul va bien sûr contenir plusieurs unités arithmétiques et logiques pour permettre d'exécuter les instructions en parallèle.
Langages
- Id a été mis au point à Irvine (Université de Californie), puis au MIT
- Val au MIT.
- SISAL (Streams and Iteration in a Single Assignment Language) à l'université de Manchester.
Historique
Les premières idées et concepts qui ont donné naissance à ces architectures sont nés dans les années 1960.
Les premiers ordinateurs de ce type sont nés au début des années 1970, d'abord aux États-Unis et au Japon, mais aussi en France avec le LAU (Langage à Assignation Unique, CERT-ONERA de Toulouse). Les constructeurs qui se sont impliqués sont : Texas Instruments, NEC, OKI etc. Certaines machines ont été construites sur la base de microprocesseurs tel que le Zilog Z8001 et Motorola 88110 ou bien encore des microprocesseurs en tranches AMD.
Quelques machines
Machines à architecture statique
- MIT Static Dataflow Architecture, un prototype avec 8 processeurs.
- HDFM, Hughes Dataflow Multiprocessor, avec 512 processeurs.
- LAU, TI's Distributed Data Processor, DDM1, etc.
Machines a jetons marqués (architecture dynamique)
- MIT Tagged-Token Dataflow Machine, 4 processeurs par cluster, les clusters sont interconnectés sur un réseau en boucle.
- SIGMA-1, superordinateur Japonais, 128 processeurs, 1988.
- PATTSY, Processor Array Tagged-Token System, système expérimental australien. 18 processeurs Intel 8085 reliés à un IBM-PC.
- DDDP, Distributed Data Driven Processor, conception Japonaise, 16 processeurs.
- Q-p, SDFA, CSIRAC II, PIM-D etc.
Il est tout à fait possible que le dataflow soit utilisé sous une forme « moderne » pour équiper un superordinateur.
Références
Liens internes
Liens externes
- [PDF] Executing a Program on the MIT Tagged-Token Dataflow Architecture.
- Flow-based Programming : un livre sur la programmation orientée flot de données.
- DataFLOW activity Solution SaaS de traçabilité d'activité terrain (B2B). Croise des flux de données dans un univers de Business Intelligence.