Glossaire de l'exploration de données
L'exploration de données étant à l'intersection des domaines de la statistique, de l'intelligence artificielle et de l'informatique, il semble intéressant de faire un glossaire où on peut retrouver les définitions des termes en français et leur équivalent en anglais classées selon ces trois domaines, en indiquant lorsque c'est utile s'il s'agit d'exploration de données « classiques », de fouille de texte, du web, de flots de données ou de fichier audio.
Informatique
Dans ce paragraphe est listé le vocabulaire informatique utilisé dans le data mining.
A
Algorithme (« algorithm ») : c'est un ensemble d'étapes, d'opérations, de procédures destinées à produire un résultat.
C
Champ (« field ») : c'est l'information élémentaire d'une table (colonne de la table) dans une base de données.
F
FP-tree (« frequent pattern tree ») : Dans le domaine des règles d'association, c'est la déclinaison d'un arbre trie composé d'une racine, de sous-arbres préfixés par les items, et d'une table des items fréquents. Chaque nœuds contient le nom de l'item, le nombre de transactions contenant l'item dans la portion de l'arbre menant à ce nœud, un lien vers le prochain nœud portant le même nom d'item - ou null s'il n'y en a pas. La table des têtes d'items fréquents contient le nom de l'item, et un pointeur vers le premier nœud du FP-tree portant le nom de l'item[1].
M
Métadonnée (« metadata ») : Données sur les données. Ce sont les descriptions, définitions des données ou des informations.
S
Session (« session ») : En fouille du web, une session est l'ensemble des séquences d'actions effectuées par un utilisateur sur internet en une seule visite. Par exemple se connecter à internet, lire un article, puis accéder à un site marchand, ajouter un objet à son panier, payer, sortir d'internet.
Système de gestion de base de données (DBMS) (« database management system (DBMS) ») : Un système de gestion de base de données est l'ensemble des programmes qui contrôlent la création, l'évolution et l'utilisation d'une base de données.
Système de gestion de flux de données[2] (DSMS) (« data stream management system » (« DSMS »)) : C'est l"ensemble des programmes qui permettent la gestion et l'interrogation des données dans un flot de données. C'est l'équivalent pour les flots de données du DBMS pour les données statiques. Les DSMS sont utilisés dans la gestion des données envoyés par les capteurs, par exemple. On utilise les DSMS dans l'exploration de flots de données où on utilise leur capacité à interroger continûment les données qui arrivent[3].
Data mining
Dans ce paragraphe est listé le vocabulaire spécifique au data mining ainsi que les algorithmes utilisés dans le data mining et issus d'autres domaines[4].
A
Analyse lexicale (« tokenization ») : En fouille de texte (entre autres domaines) , l'analyse lexicale est la décomposition de textes en mots appelés tokens, et l'étude des phénomènes (statistique, morphologiques) relatifs à ces mots[5].
Arbre de décision (« decision tree ») : Une classe de méthodes statistiques et d'exploration de données (« Data Mining ») qui forment des modèles prédictifs en forme d'arbre.
Arbre de classification (« classification tree ») : c'est une technique de data mining utilisée pour prédire l'appartenance de données à des classes de telle manière que les données dans une classe se ressemblent le plus possible alors que les classes elles-mêmes soient le plus dissemblables possible. Les critères de séparation peuvent être le χ², l'indice de Gini, le Twoing, l'Entropie[6] - [7]…
Autocorrélation spatiale (« spatial autocorrelation ») : en fouille de données spatiales, c'est la mesure de la dépendance spatiale. Elle quantifie l'importance avec laquelle un évènement en un lieu, force ou rend plus probable le même évènement en un lieu voisin[8].
C
Cadrage multidimensionnel (« multidimensional scaling ») : c'est une technique de fouille de données spatiales permettant de représenter visuellement des objets ou des évènements en fonction de leur proximité ou de leur similarité[9] - [Géo 1].
Catégorisation de documents (« categorization of text material ») : En fouille de texte, c'est l'assignation de documents à une ou plusieurs catégories selon son contenu (comme on le fait sur Wikipedia)[10].
CART (« classification and regression trees ») : Un type d'algorithme d'arbre de décision qui automatise le processus d'élagage par validation croisée et autre techniques.
Cartographie de surface de tendances (« trend surface mapping ») : En fouille de données spatiales, le but de la cartographie de surface de tendances est de décomposer une série spatiale (un phénomène sur un ensemble de sites) en deux composantes : une tendance ou composante régionale et une erreur ou composante locale. Cette séparation est accomplie en spécifiant et ajustant un modèle de surface de tendance. Il capture la structure régionale sousjacente de la série et laisse une composante locale ne montrant aucune variation visible. Un modèle de surface de tendance est un modèle de régression linéaire dans lequel les variables explicatives sont les coordonnées géographiques de chaque site dans la série spatiale[11] - [12].
Classification ou segmentation (« clustering ») : C'est la technique qui consiste à regrouper les enregistrements en fonction de leur proximité et de la connectivité à l'intérieur d'un espace à n dimensions. Dans ce cas, c'est une technique d'apprentissage non-supervisée. La Classification est aussi le processus permettant de déterminer qu'un enregistrement appartient à un groupe prédéterminé. Il s'agit alors d'une technique d'apprentissage supervisée. En français on parle aussi de Segmentation (en marketing), de Typologie, de Taxinomie (en zoologie et en biologie), de Nosologie (en médecine)[13]. En Exploration de données, la Classification se déroule en trois phases : une première phase où le modèle est construit sur un échantillon de données pré-classée, une deuxième phase où le modèle doit prédire la classification de données pré-classée (données sur lesquelles le modèle n'a pas effectué son apprentissage), enfin une troisième phase où le modèle est déployé. En Fouille de flots de données, les données pré-classées et les données non pré-classées sont présentes dans le même flux, les trois phases sont donc confondues[14].
Classification double (« biclustering ») : En Exploration de données, c'est une technique non supervisée qui vise à segmenter les lignes et les colonnes d'une matrice de données. Très utilisée en bio-informatique, notamment pour l'analyse de l'expression des gènes, cette technique a tendance à s'étendre à beaucoup d'autres domaines, tels que la compression d'image, en fouille du web pour la classification des spammeurs, etc.
CHAID (« chi-square automatic interaction detector ») : Un processus qui utilise des tables d'éventualités et le test du chi2 pour créer un arbre.
Colocalisation(« co-location ») : la colocalisation est l'analyse en fouille de données spatiales, consistant à rapprocher deux évènements par leur localisation géographique. Par exemple la présence d'eaux polluées et l'apparition d'une épidémie dans le voisinage[Géo 1].
Contrainte anti-monotone (« anti-monotone constraint ») : Dans le domaine des règles d'associations, une contrainte[15] est dite anti-monotone[16] - [17] (pour l'inclusion) lorsque, étant valide pour un motif, elle est forcément valide pour un sous-ensemble englobant ce motif.
Contrainte monotone (« monotone constraint ») : Dans le domaine des règles d'associations, une contrainte est dite monotone[16] - [17] (pour l'inclusion), lorsque étant valide pour un motif, elle est forcément valide pour un sur-ensemble englobant ce motif.
Validation croisée[10] (« cross validation ») : C'est le processus d'évaluation de la prédictibilité d'un modèle en comparant le résultat du modèle appliqué sur un échantillon de test avec le résultat obtenu sur l'échantillon d'apprentissage qui a servi à bâtir le modèle. C'est la première étape de validation qui permet entre autres de vérifier qu'il n'y a pas sur-apprentissage.
D
Data binning (« Binning ») : Processus par lequel une grandeur continue est discrétisée, découpée en morceaux.
Diagramme de Voronoi (« Voronoi diagram ») : Partition de l'espace définie à partir des triangles de Delaunay, en construisant les points à l'aide des médiatrices des côtés de chaque triangle.
Distance (« distance ») : Ce sont des fonctions utilisées en classification non supervisée (« Clustering ») pour déterminer les classes et placer les individus dans ces classes.
- pour les données continues on peut utiliser les distances issues de la distance de Minkowski définie comme ceci[18] :
- si sont deux vecteurs d'un espace de dimension on a :



- si , on obtient la distance de Manhattan ; si , on a la distance euclidienne.
- on utilise aussi la distance de Chebychev :



.
- si sont deux variables aléatoires de même distribution à valeurs dans , et si est la matrice de covariance de ces deux variables aléatoires, on définit la distance de Mahalanobis par :



.
- pour les variables binaires symétriques - celles qui ne prennent que deux valeurs 0 et 1 et toutes deux d'égale importance - on utilise la matrice de confusion
| point | ||||
|---|---|---|---|---|
| 1 | 0 | total | ||
| point |
1 | a | b | a+b |
| 0 | c | d | c+d | |
| total | a+c | b+d | a+b+c+d | |


- pour avoir

.
- Pour les variables binaires asymétriques - celles pour lesquelles une des deux valeurs est plus importante (par convention la valeur 1)
- on utilise la distance de Jaccard, soit :

- Dans le cadre de la recherche de similarité entre pages web ou entre documents, on utilise la mesure cosinus, qui permet en fouille du web de déterminer si deux pages - ou deux documents - sont «proches» ou non. Mais ce n'est pas une distance mathématique à proprement parler.
Dendrogramme (« dendrogram ») : c'est une représentation graphique d'une classification hiérarchique ascendante[19]
Dépendance spatiale (« spatiale dependence ») : c'est une notion fondamentale en Analyse spatiale. Elle caractérise le fait qu'une grandeur en un point géographique ou en une région dépend de la même grandeur dans le voisinage de ce point ou de cette région. Par exemple le prix d'un appartement dans une ville dépend du prix des appartements aux alentours. L'amplitude de la dépendance spatiale est mesurée par l'autocorrélation spatiale[20].
E
Echantillonnage spatial (« spatial sampling ») : La dépendance spatiale et l'hétérogénéité, en fouille de données spatiales, autorisent l'utilisation de mesures, en nombre restreint, judicieusement placées dans l'espace étudié en vue d'obtenir des échantillons des grandeurs auxquelles l'analyste s’intéresse[Géo 2] - [21].
Élagage (« pruning ») : C'est la technique qui permet de modifier la structure d'un arbre de décision en remplaçant certaines branches par des feuilles de telles sorte que la justesse de la classification ou de la prédiction en soit améliorée. En général, on emploie cette technique après avoir construit l'arbre en entier.
Ensemble (méthodes) (« ensemble methods ») : C'est la technique qui permet
- de combiner différentes méthodes sur un même échantillon, réconcilier les résultats puis appliquer le modèle réconcilé sur des données hors-échantillon,
- ou bien de paramétrer différentes méthodes sur un échantillon, appliquer les méthodes paramétrées sur des données hors-échantillon et adopter le résultat par vote[22]- ie le résultat adopté par le plus de méthodes est retenu.
La première technique combine les résultats par l'apprentissage et est plutôt liée aux méthodes supervisées, la seconde par consensus et est plutôt liée aux méthodes non-supervisées.
Entropie (« entropy ») : Souvent utilisée en « Data Mining », elle permet de mesurer le désordre dans un ensemble de données. Pour un ensemble discret de k valeurs on a


L'entropie est utilisée dans les arbres de décision pour choisir la variable maximisant le gain d'information[23] :
Si est un ensemble de données contenant les attributs , si est l'ensemble des classes , alors :








Si on utilise pour partitionner , celui-ci sera divisé en sous-ensembles disjoints deux à deux où est le nombre de valeurs de l'attribut .



L'entropie de après la partition selon est donnée par :

Le gain d'information de l'attribut est égal à :

et le ratio de gain d'information est égal à

Dans un arbre de décision, chaque nœud est valorisé par l'attribut qui maximise le ratiogain.
Exactitude (« Accuracy ») : L'exactitude d'un système de mesures d'une grandeur est sa capacité à être proche de la vraie valeur de cette grandeur[DM 1].
Extraction de connaissance à partir des données (« knowledge discovery in databases ») : une autre expression signifiant Data Mining.
Extraction de connaissance omniprésente (« ubiquitous knowledge discovery ») : Domaine dont les objets d'étude[24] :
- existent dans le temps et l'espace dans un environnement changeant
- peuvent se mouvoir, et apparaître et disparaître
- ont des capacités de traitement de l'information
- ne connaissent que leur environnement spatio-temporel local
- agissent sur contraintes en temps réel
- sont capables d'échanger de l'information avec d'autres objets.
F
Fenêtre glissante[25] (« sliding window ») : Fenêtre temporelle utilisée dans l'exploration des flots de données (« Data stream mining ») pour en extraire des motifs. Les fenêtres peuvent avoir une taille W fixe et la fouille de données s'effectue sur les W dernières transactions, ou sur les W dernières unités de temps, elles peuvent aussi avoir une taille variable, dans la détection de la dérive conceptuelle, par exemple.
Fenêtre à jalon[25] (« landmark window ») : autre type de fenêtre temporelle utilisée dans l'exploration des flots de données. Ce sont des fenêtres acceptant des transactions depuis un jalon temporel donné.
Fenêtre pondérée[25] (« damped window ») : encore un autre type de fenêtre temporelle utilisée dans l'exploration des flots de données. Ce sont des fenêtres où les transactions sont pondérées en fonction de leur ancienneté. Ceci peut être réalisé en utilisant un taux de dégénérescence (« Decay rate »).
Fenêtre dilatée (« tilted time window ») : C'est une fenêtre temporelle, utilisée dans certains algorithmes de fouille de flot de données, où les arrivants les plus récents sont stockés à un niveau de granularité le plus fin, alors que les item(set)s les plus anciens sont stockés à un niveau de granularité plus grossier. On peut utiliser des fenêtres dilatées naturelle, des fenêtres dilatées à échelle logarithmique ou des fenêtres dilatées progressives logarithmique[26].
Flux de clics (« clickstream ») : Dans le domaine de l'usage du web c'est l'enregistrement de ce sur quoi un utilisateur clique lorsqu'il navigue sur l'internet. Quand l'utilisateur clique sur une page web, l'action est logger sur le poste client ou sur un server web, avec d'autre données telles que le navigateur Web, les routeurs, les serveurs de proxy, etc. L'analyse des flux de clics est utile pour l'analyse de l'activité internet[27] - [28] d'un site ou l'analyse des comportements des utilisateurs face au web.
Frontière (« frontier ») : En fouille de la structure du web, une Frontière est l'ensemble des URL non encore visitées par un robot d'indexation (« Web Crawler »).
G
Gain d'information (« information gain ») : voir Entropie
Gini (« Gini Metric ») : Un indicateur permettant de mesurer la réduction du désordre dans un ensemble de données induite par la séparation des données dans un arbre de décision. L'indice de diversité de Gini et l'entropie sont les deux manières les plus populaires pour choisir les prédicteurs dans l'arbre de décision CART. Pour un ensemble discret de k valeurs on a

H
Hétérogénéité spatiale (« spatial heterogeneity ») : c'est ainsi qu'est nommée la non stationnarité de la plupart des processus géographiques[20].Une autre manière de le dire : le contexte spatial est différent en chaque point et cette fluctuation spatiale influe sur les relations entre les variables[29] - [Géo 3].
I
ID3 (« ID3 ») : ID3 est l'un des plus anciens algorithmes d'arbre de décision
Item (« Item ») : c'est un motif, en exploration de flots de données (« Data stream mining »), c'est un objet dans le domaine des règles d'association…
Itemset (« itemset ») : c'est un motif, en exploration de flots de données (« Data stream mining »), c'est un ensemble d'objets dans le domaine des règles d'association…
Interpolation spatiale (« spatial interpolation ») :
« Tout d'abord, qu'est-ce que l'interpolation spatiale ? C'est le processus d'estimation d'une valeur à une localisation (x,y) à partir de valeurs placées à d'autres localisations (x1,y1)...(xn,yn) »
— SOM, SIG-o-Matic[30]
L'interpolation spatiale est rendue possible et utile par l'hétérogénéité et la dépendance spatiales. Si tout était homogène l'interpolation serait inutile, si tous les phénomènes spatiaux étaient indépendants l'interpolation serait impossible[31].
Interpolation polynomiale globale (« global polynomial interpolation ») : c'est une méthode d'interpolation spatiale déterministe utilisant les polynômes sur toute la surface à interpoler[32]. C'est une méthode qui n'utilise pas les voisins.
Interpolation polynomiale locale (« local polynomial interpolation ») : c'est une méthode d'interpolation spatiale déterministe utilisant des polynômes sur des voisinages de points[33].
K
Krigeage (« krigging ») : méthode d'interpolation spatiale utilisant une pondération minimisant la variance de l'estimation[34] - [35] - [36]. Le krigeage simple ou le krigeage universel[37] est utilisé selon que des hypothèses de stationnarité sont satisfaites ou non.
L
Large vocabulary continuous speech recognition : En fouille audio, technique permettant de reconnaître des mots dans un flux audio.
M
Distance de Mahalanobis (« Mahalanobis distance ») : voir Distance. Cette distance peut être utilisée pour savoir si une observation est un outlier ou non[38].
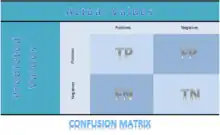
Matrice de Confusion[39] - [40] (« confusion matrix ») : c'est un tableau dans lequel on place les compteurs des valeurs que le test (ou modèle) a prédit correctement dans la case des "Vrai Corrects" ou des "Faux Corrects", celles des valeurs que le test (ou modèle) n'a pas prédit correctement dans la case des "Vrais Incorrects" ou "Faux Incorrects" (dans l'exemple ci-contre on voit les True Positive, True Negative, False Positive et False Negative). On calcule ensuite l'Exactitude, la Sensibilité ou Rappel, La Précision, la Spécificité pour mesurer la pertinence dut test ou du modèle.
Définitions :
Exactitude = ,
Rappel = ,
Précision = ,
Spécificité = .




Matrice d'interactions spatiales ou matrice de poids spatiale (« spatial weight matrix ») : Matrice carrée permettant de modéliser l'interaction entre deux points géographiques en fonction de l'importance de leur interaction. En fouille de données spatiales les matrices peuvent être de contiguïté - modélisant l'importance de l'interaction en fonction de la proximité [41] - ou de gravité, modélisant l'interaction en fonction de la «masse» du phénomène observé, comme les flux migratoires modélisés par E.Ravenstein en 1885[42].
Motif séquentiel[43] (« sequential pattern ») : c'est un motif, en fouille de données et en exploration de flots de données. Ce sont des motifs tels qu'on les trouve dans des règles d'associations mais assortis de contraintes temporelles. Par exemple[44], les clients qui achètent un ordinateur sont susceptibles d'acheter tel ou tel accessoire dans un laps de temps déterminé après l'achat du premier appareil. Les motifs séquentiels peuvent être recherchés dans plusieurs transactions effectuées dans des périodes de temps différentes, alors que les règles d'associations sont recherchées dans la même transaction.
Mesure cosinus (« cosine mesure ») : en fouille du web, c'est une mesure de la similarité de deux pages. Si et où sont les fréquences des mots en commun aux pages et , alors la similarité des pages et est mesurée par : , soit . (voir exemple graphique [45])






![\cos (\alpha) = \frac{\sum_{k=1}^n p_{1k}.p_{2k}}{\sqrt[2]{\sum_{k=1}^n p_{1k}^2}.\sqrt[2]{\sum_{k=1}^n p_{2k}^2}}](https://img.franco.wiki/i/d3fa2876dd22bf9ff06d7fc7c6c4d3ce18baa2ad.svg)
N
N-Gramme (« n-gram ») : technique, employée en fouille de texte, de découpage des textes en sous-séquences de longueur N[46].
P
Pondération inverse à la distance (« inverse distance weighting ») : c'est une des méthodes déterministes d'interpolation spatiale, qui consiste à estimer la valeur d'une grandeur en un point en fonction des valeurs connues de cette même grandeur en différents points voisins, en pondérant chaque valeur par l'inverse de la distance entre le point dont la valeur est à estimer et les différents points voisins[47].
Précision (« precision ») : La précision d'un système de mesures d'une grandeur est sa capacité à donner des résultats proches lorsqu'ils sont répétés sous conditions inchangées.
Première loi de Tobler (« Tobler's first law ») : Assez éloignée de la fouille de données, cette entrée explique la nature particulière de la fouille de données spatiales et le concept d'autocorrélation spatiale.
« « Everything is related to everything else, but near things are more related than distant things. » »
.
Q
QUEST (« QUEST ») : un arbre de décision/classification développé par Wei-Yin Loh et Yu-Shan Shih en 1997[49]. QUEST est utilisé dans le package lohTools[50] du logiciel R.
R
Page Racine (« seed page ») : En fouille de la structure du web, c'est une page initiale, permettant l'exploration de la structure de l'internet ou d'une partie de celle-ci par un robot d'indexation (nommé aussi « Spider » ou « Web Crawler »).
Recouvrement (« overlay ») : En fouille de données spatiales, il s'agit du processus consistant à joindre et visualiser simultanément des données, provenant de sources diverses, localisées dans le même espace géographique[51] - [Géo 4].
Règle d'association (« association rule ») : C'est une technique de data mining utilisée pour décrire des relations entre des objets (item), des ensembles d'objets (itemset) ou des évènements[10]. L'algorithme A-priori est un algorithme efficace et populaire pour trouver ce type de règles d'association. Exemple les associations entre les objets achetés dans un supermarché. Une règle d'association est de la forme Si ceci alors cela. Plus formellement, soit un ensemble d'items. Soit un ensemble de transactions, telles que soit un sous-ensemble de (ie ). Une règle d'association s'exprime sous la forme :










est un ensemble appelé itemset.

Règle d'association spatiale (« spatial association rule ») : c'est une règle d'association où X ou Y contient des prédicats spatiaux - de types distance, direction, topologique - tels que proche, éloigné, contient, contigu… Alors que dans une règle d'association chaque occurrence (lignes dans une Bdd géographique) de l'association est une transaction, en analyse spatiale une occurrence représente un objet spatial (Paris, Londres, ..) d'un type d'objet spatial (ville, pays, bâtiment, ..) analysé selon les prédicats (colonnes dans une Bdd géographique)[52].
S
Segmentation (« clustering ») : Technique de classification non supervisée permettant de ranger des données dans des classes non prédéfinies[53].
Segmentation en analyse de texte (« clustering in text analysis ») : En fouille de texte, il s'agit d'une segmentation non supervisée pour l'organisation de documents, ou de textes dans des documents, parfois appelée aussi filtrage, impliquant des algorithmes comme les arbres de classification ou l'algorithme SVM[10].
Stationnarité(« stationarity ») : En fouille de données spatiales, les hypothèses de stationnarité concernent l'espérance mathématique d'un processus (stationnarité d'ordre un), et la covariance (stationnarité d'ordre deux). Si est un champ aléatoire, on dit que est stationnaire au premier ordre si pour tout x. Ce champ est stationnaire de second ordre s'il est stationnaire de premier ordre et si [54].

![\Epsilon[(\Zeta(x)]=Cste](https://img.franco.wiki/i/57f221c59ecf4aca540d3c68d072c6b39e2b0785.svg)

T

Triangulation de Delaunay (« Delaunay triangulation ») : Partition de l'espace de points créée en joignant les plus proches voisins de chaque point de telle manière qu'aucun point ne soit contenu dans le cercle circonscrit de chaque triangle[55].
V
Variable catégorielle (« categorical variable ») : variable pouvant prendre un nombre restreint de valeurs, comme les couleurs par exemple. On parle aussi de variable qualitative ou discrète.
Variable continue (« continuous variable ») : variable pouvant prendre un nombre infini de valeurs, comme un prix par exemple.
Variable dépendante (« dependent variable ») : variable cible ou variable à expliquer dont on veut estimer les valeurs en fonctions d'autres variables dites explicatives. On parle aussi de variable cible ou variable réponse[56].
Variable indépendante (« independent variable ») : variable explicative permettant d'estimer une variable cible. On parle aussi de variable explicative, de contrôle, réponse[56].
Voisinage (« neighborhood ») : c'est l'ensemble des zones (ou des points) proches de la zone (ou du point) de référence. En termes de contiguïté, dans le cadre de grilles (raster ou autres), le voisinage de 8 cellules est appelé voisinage de la Reine, celui des 4 cellules Nord-Sud et Ouest-Est est dénommé voisinage de la Tour et celui des angles est appelé voisinage du Fou. Le voisinage du Fou complété par le voisinage de la Tour revient au voisinage de la Reine[57].
Variogramme (« variogram ») : notée , cette fonction est une mesure de la dissimilarité[58] ou de la continuité[59] en analyse spatiale. Si est une variable aléatoire au point x, alors le variogramme est défini par :

![\gamma (h) = \frac{1}{2} \Epsilon[(\Zeta(x+h) - \Zeta(x))^2]](https://img.franco.wiki/i/4cc39b5fc19a7b4e80d616c7ecaea21703954208.svg)
Intelligence artificielle
Dans ce paragraphe est listé le vocabulaire spécifique à l'intelligence artificielle et les concepts issus de l'IA et utilisés dans le data mining.
A
Algorithme génétique[60] (« genetic algorithm ») : C'est un algorithme de recherche heuristique inspiré de l'évolution naturelle. Il est employé dans le domaine de la recherche de solutions approchées dans les problèmes d'optimisation. Il utilise des techniques comme l'héritage, la mutation, la sélection et l'enjambement.
Apprentissage incrémental (« incremental learning ») : Un classifieur utilise l'apprentissage incrémental quand, lors de l'arrivée de nouveaux items, il est capable d'évoluer sans pour cela que l'apprentissage soit à refaire entièrement[61].
Apprentissage supervisé (« supervised learning ») : c'est une stratégie d'apprentissage qui consiste à apprendre par l'exemple. Un enseignant (quelqu'un qui apprend quelque chose au système) aide le système à construire le modèle recherché en lui fournissant les classes et les exemples qui caractérisent chaque classe. Le système en déduit les descriptions de chaque classe pour que les descriptions et les classes forment les règles de classification qui serviront à classer les nouveaux arrivants[62].
Apprentissage non supervisé (« unsupervised learning ») : c'est une stratégie d'apprentissage qui consiste à apprendre par l'observation et la découverte. Le système se débrouille seul avec les arrivants, aucune classe n'est prédéfinie : il doit donc analyser les exemples et découvrir les schémas et les caractéristiques de chaque arrivant et les classer selon ces caractéristiques[62].
B
Bagging (« bagging ») : ou « Bootstrap aggregating » est la technique qui consiste à la création de plusieurs modèles sur des échantillons « bootstrap », puis à combiner les résultats. Cette technique est destinée à l'amélioration de l'exactitude[DM 2] de la classification et/ou de la prédiction d'un modèle en apprentissage automatique.
D
Dérive conceptuelle (« concept drift ») : En Fouille de flots de données, et en Apprentissage automatique la dérive conceptuelle fait référence aux changements - dans les propriétés statistiques des variables cibles, en général - qui interviennent au cours du temps de manière imprévue[63].
F
Feuille (« leaf ») : Dans un arbre de classification, tout nœud qui n'est pas segmenté.
Forêt d'arbres décisionnels (« Random forest ») :
« Les Forêts d'arbres décisionnelles sont formées d'une combinaison d'arbres estimateurs tels que chaque arbre dépend des valeurs d'un vecteur aléatoire échantillonné indépendamment et ayant la même distribution pour tous les arbres de la forêt. »
— Leo Breiman, Random Forests[64]
I
Intelligence artificielle (« artificial intelligence ») : Le domaine scientifique qui a pour but la création de comportements intelligents dans une machine.
N
Nœud racine (« Root node ») : le début d'un arbre de décision; le nœud racine détient l'ensemble des données avant qu'elles ne soient découpées dans l'arbre.
R
Règle de Hebb (« Hebbian Learning ») : Cette règle d'apprentissage des réseaux de neurones précise que les poids entre deux neurones augmentent quand ils sont excités simultanément et décroissent dans le cas contraire.
Réseaux de Kohonen (« Kohonen networks ») : Un type de réseau de neurones où la localisation d'un nœud est calculée par rapport à ses voisins ; la localité d'un nœud est très importante dans l'apprentissage ; les réseaux de Kohonen sont souvent utilisés en clustering.
Réseaux Neuronaux (« neural network ») : Un modèle basé sur l'architecture du cerveau. Un réseau Neuronal consiste en multiples unités de calcul simples connectés par des poids adaptatifs.
Réseaux neuronaux à base radiale « radial basis function neural Network ») : c'est un réseau neuronal (voir ci-dessus) utilisant une couche cachée constituée de fonctions à base radiale[65] - [66], et une sortie combinaison linéaire des sorties des fonctions à base radiale. Ils sont caractérisés par un apprentissage rapide et un réseau compact[67] - [68].
Résumés (« summaries ») : En Fouille de flots de données c'est un ensemble de techniques permettant d'explorer le flot de données sur un nombre restreints d'éléments sans pour cela ralentir le flot, et dans un système limité en mémoire et en puissance. Les techniques se nomment échantillonnage aléatoire, résumé (sketching), synopsis (histogramme, analyses par ondelettes, quantiles et fréquences)[69] - [70].
Rétro-Propagation (« back propagation ») : Un des algorithmes d'apprentissage les plus usités pour la préparation des réseaux de neurones
Statistique
Dans ce paragraphe est listé le vocabulaire spécifique aux statistiques et les concepts issus des statistiques et utilisés dans le data mining.
A
Analyse des données (« exploratory data analysis ») : L'analyse des données est le processus qui consiste à examiner, nettoyer, transformer, et modéliser les données dans le but d'en extraire de l'information utile, de suggérer des conclusions, de prendre des décisions. Le Data mining est une technique spécifique d'analyse des données qui se concentre sur la modélisation et l'extraction de connaissances dans un but prédictif plutôt que descriptif, bien qu'une partie du processus de data mining nécessite la description des données.
Analyse factorielle (« factor analysis ») : voir Analyse factorielle.
B
Boostrapping[71] (« Bootstrap method ») : C'est une méthode de ré-échantillonnage permettant d'obtenir une distribution d'échantillons pour un paramètre, au lieu d'une seule valeur de l'estimation de ce paramètre.
C
Colinéarité (« collinearity ») : Deux variables sont colinéaires si elles sont corrélées sans qu'une relation de cause ne soit établie entre elles.
Méthode du coude : Quand une grandeur est exprimée en fonction d'une autre, sans qu'il y ait de maximum absolu ou local, et qu'il faut choisir une valeur pertinente optimale du couple des deux grandeurs, la méthode du coude, empirique, consiste à choisir les valeurs où la courbe s'infléchit. On utilise cette méthode dans le cas de l'analyse factorielle pour prendre en compte le nombre d'axes idéal en fonction des valeurs propres, ou bien dans le choix d'un nombre de classes en fonction de l'indice en classification automatique.

Courbe de lift (« lift chart ») : c'est un résumé visuel de l'utilité des modèles statistiques et de data mining pour la prédiction d'une variable catégorielle. Elle sert à mesurer la performance d'un modèle. (voir courbe ROC et indice de Gini)
Courbe ROC[39] (« ROC curve ») : La courbe ROC (« Receiver Operating Characteristics ») nous vient des ingénieurs US du traitement du signal qui l'ont inventée pendant la seconde guerre mondiale et depuis elle a été utilisée en médecine, radialogie, psychologie et maintenant en data mining. Sur l'axe des Y on représente les vrais évènements détectés et sur l'axe des X les faux évènements détectés (les erreurs de détection). Elle sert à mesurer la performance d'un estimateur ou d'un modèle[72].
E
Ensemble flou (« fuzzy set ») : Ils servent à modéliser la représentation humaines des connaissances[73].
F
Fonction base (« basis function ») : Fonction impliquée dans l'estimation de la Régression multivariée par spline adaptative (MARS). Ces fonctions forment une approximation des relations entre les estimateurs et les variables estimées[74].
G
Indice de Geary (« Geary index » ou « Geary's C ») : indice de mesure de l'autocorrélation spatiale en fouille de données spatiales[Géo 5]. Il s'exprime comme le rapport de la variance locale (celle des mesures entre voisins de l'échantillon) à la variance totale des mesures de l'échantillon[75]. Si est un échantillon de mesures spatiales, l'indice c de Geary s'exprime ainsi :


où


.
H
Inégalité de Hoeffding (« Hoeffding’s inequality ») : L'inégalité de Hoeffding sert à la mesure de l'erreur d'un estimateur.
Définition : Soient variables aléatoires indépendantes, de distribution identique, telles que tendant vers une variable aléatoire , Alors



![\Pr [ | \frac 1n \sum_{i=1}^n X_i - \Epsilon [ X ] | > \epsilon ] \le \delta = 2\exp(-2n \epsilon ^2)](https://img.franco.wiki/i/0e1dbfcd0e1a0137c33fbe628376922414c38c36.svg)
Théorème : Supposons que Alors, avec une probabilité supérieure ou égale à , la différence entre la moyenne empirique et la moyenne est au plus égale à .



![\Epsilon [ X ]](https://img.franco.wiki/i/e855c523912e0552431adc64db30321c734b1ca2.svg)

- la précision nous dit de combien nous sommes éloigné de la moyenne réelle de la variable aléatoire
- la confiance nous dit avec quelle probabilité nous nous trompons[76].

I
Indépendance statistique (« independence (statistical) ») : Deux évènements sont indépendants s'ils n'ont aucune influence l'un sur l'autre.

J
Jackknife[71] (« Jackknife method ») : C'est une méthode de ré-échantillonnage, analogue à celle du bootstrapping, qui diffère de celle-ci seulement par la méthode de sélection des différents échantillons.
L
Logique floue (« fuzzy logic ») : La logique floue est une technique, formalisée par Lotfi Zadeh, utilisée en intelligence artificielle. Elle s'appuie sur les ensembles flous.
M
Modèle (« Model ») : Une description qui explique et prédit convenablement des données pertinentes mais qui est généralement moins volumineuse que les données elles-mêmes.
Modèle de Markov caché (« HMM » ou « hidden Markov model ») : C'est un processus qui permet de déterminer les paramètres cachés d'un système à modéliser supposé être un processus de Markov. Les Modèles de Markov cachés ont été utilisés pour la première fois dans la reconnaissance de la parole dans les années '70, il est aussi utilisé en fouille de texte[77].
Indice de Moran (« Moran index » ou « Moran's I ») : indice de mesure de l'autocorrélation spatiale en fouille de données spatiales[Géo 6]. Il s'exprime comme le rapport de la covariance locale (celle des mesures entre voisins de l'échantillon) à la variance totale des mesures de l'échantillon[75]. Si est un échantillon de mesures spatiales, l'indice I de Moran s'exprime ainsi :

où
.
R
Robustesse (« robustness ») : Un modèle statistique, un algorithme, un processus est dit robuste s'il produit des résultats justes en moyenne et s'il n'est pas sensible aux données ayant des problèmes. Dans le cas contraire on parle de modèle instable.
Indice de Ripley (« Rispley'K ») : créé par Brian Ripley, il permet d'analyser les motifs de points, effectuer des tests d'hypothèses, estimer des paramètres et ajuster des modèles[78] - [Géo 7].

où est le nombre de points / évènements dans un cercle de rayon centré sur le point [79].


S
Statistique bayésienne (« Bayesian statistics ») : Une approche des statistiques fondée sur la loi de Bayes. Le théorème de Bayes exprime la probabilité de l'évènement A connaissant l'évènement B de la manière suivant :

T
Taux d'erreur (« error rate ») : Un nombre indiquant l'erreur faite par un modèle prédictif.
Test d'hypothèse (« Hypothesis Testing ») : voir Test d'hypothèse
Notes et références
Fouilles de données Géographiques
- voir Voisinage
- voir aussi Interpolation spatiale dans ce glossaire
- Voir la dépendance spatiale aussi pour une autre caractéristique de l'espace géographique.
- Voir aussi Colocalisation
- voir Indice de Moran et Indice de Ripley
- voir Indice de Geary et Indice de Ripley
- voir Indice de Geary et Indice de Moran
Autres
Références
- [PDF](en) Zengyou He, Xiaofei Xiu, Schengchung Deng, « A FP-Tree based approach for mining all correlated pairs without candidate generator » (consulté le )
- [PDF](en) Brian Babcock, Shivnath Babu, Mayur Datar, Rajeev Motwani, Jennifer Widom, « « Models and Issues in Data Stream Systems » » (consulté le )
- [PDF](en) Chih-Hsiang Lin, Ding-Ying Chiu, Yi-Hung Wu, Arbee L. P. Chen, « « Mining Frequent Itemsets from Data Streams with a Time-Sensitive Sliding Window » » (consulté le )
- Glossaire anglais-Français
- (en) Searsr, « Text mining » (consulté le )
- (en) Salford Systems, « Do Splitting Rules Really Matter? » (consulté le )
- (en) Leo Breiman, « « Technical Note: Some Properties of Splitting Criteria » » (consulté le )
- [PDF](en) Arthur J. Lembo, Jr, « « Spatial Autocorrelation, Moran's I Geary's C » » (consulté le )
- Stephen P. Borgatti, « Multidimensional Scaling », (consulté le )
- Robert Nisbet, John Elder, Gary Miner, Handbook of Statistical Analysis & Data Mining Applications édition 2009, Academic Press, Page 789 et suivantes
- [PDF](en) N. Wrigley, « « Probability Surface mapping. An Introduction with Examples and Fortran Programme » », (consulté le )
- SOM, « Surface de Tendances Polynomiales » (consulté le )
- Stéphane Tufféry, Data mining et Statistique décisionnelle
- Hanady Abdulsalam, Streaming Random Forests
- Arnaud Soulet, Découverte de motifs sous contraintes
- Mohammad El-Ha jj, Osmar R. Za¨ıane, Bi-Directional Constraint Pushing in Frequent Pattern Mining
- Jérémy Besson, Céline Robardet, Jean-François Boulicaut, Un algorithme générique d'extraction de bi-ensembles sous contraintes dans des données booléennes
- Bing Liu, Web Data Mining, Springer, Édition 2010, pages 135-138
- Maxime Chambreuil, (exemples de Dendrogrammes) Classification Hiérarchique Ascendante
- Miller et Han 2009, p. 11
- [PDF] (en) Justin Ngan, Byron Moldofsky, « Sampling Choices and Implications » (consulté le ).
- [ Jing Gao1, Wei Fan2, Jiawei Han1, On the Power of Ensemble: Supervised and Unsupervised Methods Reconciled
- Bing Liu, Web Data Mining, Springer, Édition 2010, pages 62-67
- Michael May, Research Challenges in Ubiquitous Knowledge Discovery
- Ruoming Jin, Cagan Agrawal, Frequent Pattern Mining in Data Stream
- Jiawei Han, Micheline Kamber, Data Mining: Concepts and Techniques
- WW Moe, PS Fader (2004), “Capturing Evolving Visit Behavior in Clickstream Data” Journal of Interactive Marketing (2004)
- Clickstream Study Reveals Dynamic Web
- Jennifer A. Miller, « Spatial non-stationarity and the scale of species-environment relationships in the Mojave Desert, California, USA », (consulté le )
- SOM, « Les types d'interpolation spatiales », (consulté le )
- Penn State - College of Earth and mineral Sciences, « Interpolation », (consulté le )
- (en) sppsr.ucla.edu, « « A few Interpolation methods » », (consulté le )
- (en) Arcgis Resource center, « « How local polynomial interpolation works » », (consulté le )
- [PDF]Sophie Baillargeon, « Le krigeage : revue de la théorie et application à l'interpolation spatiale de données de précipitations », (consulté le )
- [PDF](en) Geoff Bohling, « « Kriging » », (consulté le )
- Ferenc Sárközy, « « The kriging » », (consulté le )
- Xavier Guyon, « Statistique spatiale », (consulté le )
- statsoft , Mahalanobis distance
- César de Souza, Discriminatory Power Analysis by Receiver-Operating Characteristic Curves
- R. Eisner, Basic Evaluation Measures for Classifier Performance
- [PDF]Hubert Jayet, « Économétrie et données spatiales », (consulté le ), p. 109
- Claude Grasland, « Les Modèles d'interaction Spatiale », (consulté le )
- Rakesh Agrawal, Ramakrishnan Srikant, Mining Sequential Patterns
- F. Masseglia, M. Teisseire, P. Poncelet, Extraction de motifs séquentiels
- Sophie Rosset, Mesure Cosinus
- C. Justicia de la Torre, M.J. Martin-Bautista, D. Sanchez, M.A. Vila, Text Mining: Intermediate Forms for Knowledge Representation
- (en) Ferenc Sárközy, « « GIS functions - Interpolation » », (consulté le )
- (en) Karl Yorgason, « First Law of Geography », (consulté le )
- Wei-Yin Loh, Yu-Shan Shih Split Selection Methods for Classification Trees
- Vincent Zoonekynd Vincent Zoonekynd's Blog, Fri, 16 Oct 2009: Use R 2009 Conference, page 5
- (en) volusia_county_government">volusia county government, « Spatial Overlay » (consulté le )
- [PDF](en) Vania_Bogorny">Vania Bogorny, « Enhancing Spatial Association Rule Mining in a Geographic Databases » (consulté le )
- Philippe Leray, Le Clustering en 3 leçons
- [PDF]Xavier Guyon, « statistique spatiale », (consulté le )
- (en) Nicolas Dumoulin, Michaël Ortega, « Triangulation de Delaunay » (consulté le )
- Stéphane Tufféry, Data Mining et statistique décisionnelle Troisième édition page 297, aux éditions Technip
- (en) M.Sawada, « Global Spatial Autocorrelation Indices - Moran's I, Geary's C and the General Cross-Product Statistic » (consulté le )
- [PDF](en) Geoff Bohling, « « Introduction to Geostatistics and Variogram Analysis » », (consulté le )
- [PDF]Denis Marcotte, « Le Variogramme », (consulté le )
- Genetic algorithm on Wiki
- Gregory Hulley, Tshilidzi Marwala, Evolving Classifiers: Methods for Incremental Learning
- Kapil Wankhade, Snehlata Dongre, « Data Streams Mining, Classification and Application », édition 2010 Lambert, page 9
- Alexey Tsymbal, The problem of concept drift: definitions and related work
- Leo Breiman, Random Forests
- Bradley John Charles Baxter, The interpolation theory of radial basis functions
- Cartier-Michaud Thomas, Teffah Zakaria Introduction aux fonctions de base radiale
- S. Haykin, Neural Networks: A comprehensive Foundation, New York : Macmillan Publishing, 1994
- M.Boukadoum, Réseaux de neurones à base radiale
- Mohamed Medhat Gaber, Arkady Zaslavsky, Shonali Krishnaswamy, Mining Data Streams: A Review
- Dariusz Brzeziński, Mining data streams with concept drift
- Peter Young, Jackknife and Bootstrap Resampling Methods in Statistical Analysis to Correct for Bias
- César de Souza, Discriminatory Power Analysis by Receiver-Operating Characteristic Curves (Part 2 of 2: C# Source Code)
- Ensembles flous
- Christine Thomas-Agnan, Estimateurs splines
- [PDF]Arnaud Banos, « De l’exploration à la prospective : essai de généralisation spatiale de la demande de transport », (consulté le )
- Justin Domke, Learning Theory
- Krishnalal G, S Babu Rengarajan, K G Srinivasagan, A New Text Mining Approach Based on HMM-SVM for Web News Classification
- Philip M. Dixon, « « Ripley’s K function » », (consulté le )
- [PDF](en) Maria A. Kiskowski, John F. Hancock,Anne K. Kenworthy, « « On the Use of Ripley’s K-Function and Its Derivatives to Analyze Domain Size » », (consulté le )
Voir aussi
Bibliographie
- (en) Harvey Miller et Jiawei Han, Geographic Data Mining and Knowledge Discovery, Boca Raton, CRC Press, , 458 p. (ISBN 978-1-4200-7397-3).
