Modèle de Markov caché
Un modèle de Markov caché (MMC, terme et définition normalisés par l’ISO/CÉI [ISO/IEC 2382-29:1999]) —en anglais : hidden Markov model (HMM)—, ou plus correctement (mais non employé) automate de Markov à états cachés, est un modèle statistique dans lequel le système modélisé est supposé être un processus markovien de paramètres inconnus. Contrairement à une chaîne de Markov classique, où les transitions prises sont inconnues de l'utilisateur mais où les états d'une exécution sont connus, dans un modèle de Markov caché, les états d'une exécution sont inconnus de l'utilisateur (seuls certains paramètres, comme la température, etc. sont connus de l'utilisateur).
Les modèles de Markov cachés sont massivement utilisés notamment en reconnaissance de formes, en intelligence artificielle ou encore en traitement automatique du langage naturel.
Modèle du sac en papier
Le jeu des sacs en papier
Imaginons un jeu simple, avec des sacs en papier (opaques) contenant des jetons numérotés.
À chaque tour du jeu nous tirons un jeton d'un sac et, en fonction du jeton, passons à un autre sac.
Après chaque tour, le jeton est remis dans le sac, nous notons enfin la séquence des numéros tirés.
Exemple
Nous disposons de deux sacs, appelés A et B, ainsi que d'un ensemble de jetons numérotés a et b.
Dans chaque sac nous plaçons un certain nombre de jetons a et un certain nombre de jetons b : dans cet exemple, nous plaçons dans le sac A 19 jetons b et un seul jeton a. Dans le sac B nous plaçons 4 jetons a et un seul jeton b.
- Nous commençons par piocher un jeton au hasard dans le sac A. Si l'on pioche un jeton a, on reste sur ce sac, si l'on pioche un jeton b, on passe au sac B. On note également quel jeton a été tiré et on le remet dans le sac.
- On recommence cette étape avec le sac en cours, jusqu'à ce que le jeu s'arrête (au bon vouloir du joueur).
Nous avons les probabilités de passer à une station suivante :
| Tirage suivant en a | Tirage suivant en b | |
|---|---|---|
| Station courante en A | 0,05 | 0,95 |
| Station courante en B | 0,8 | 0,2 |
En jouant plusieurs parties, nous sommes susceptibles d'obtenir les séquences suivantes :
- a b a b a b a a b a
- a b b a b a b a b a
- a b b a b b a b a b
- …
Ce jeu peut être modélisé par une chaîne de Markov : chaque sac représente un état, la valeur du jeton donne la transition, la proportion de jeton d'une valeur est la probabilité de la transition.
Notre exemple du jeu du sac en papier est équivalent à l'automate de Markov suivant :

Le jeu des sacs en papier cachés
Nous reprenons en partie le modèle précédent mais introduisons de nouveaux types de sacs :
- Des sacs pour savoir dans quel sac effectuer le prochain tirage ;
- Des sacs de sortie pour générer la séquence.
À partir de la séquence générée, il sera généralement impossible de déterminer quels tirages ont conduit à quelle séquence, la séquence de tirage dans les sacs donnant les transitions est inconnue, c'est pourquoi on parle de sacs en papier cachés.
Exemple
Repartons de l'exemple précédent. Nous conservons les sacs A et B, qui donnent les transitions, et ajoutons deux sacs A' et B' (contenant des jetons j et k), situés juste à côté :
- A' contient quatre jetons j et un jeton k ;
- B' contient un jeton j et quatre jetons k.
Le jeu est le suivant :
- On part du groupe de sacs (A et A'), on tire un jeton dans le sac A', on consigne sa valeur (j ou k) et on le replace dans le sac ;
- On tire un jeton dans le sac A pour savoir dans quel groupe de sacs se feront les prochains tirages, on le replace ;
- Si le jeton sortant du sac A est un 'a' alors les prochains tirages se feront dans le groupe de sac (A et A'), si c'est un 'b', il se fera dans le groupe de sac (B et B') ;
- On recommence ces opérations autant de fois que le joueur le souhaite.
À chaque étape, on tire donc un jeton dans chaque sac d'un même groupe, à savoir A et A' ou B et B', ce qui permet d'avoir une valeur (j ou k) qui n'indique pas directement la transition.
Le jeu génère deux séquences :
- La séquence de sortie, connue, le résultat du jeu (ce sont les valeurs j ou k contenues dans les sacs A' et B') ;
- La séquence des transitions, inconnue (ce sont les valeurs a et b contenues dans les sacs A et B).
Pour cet exemple, nous avons pu générer les séquences suivantes :
| Séquence de transition | A B A B | A B B A | A A B A | A B A B | A B A B |
|---|---|---|---|---|---|
| Séquences de sortie | j j k k | j k k j | k j j j | j k k j | k k j k |
On observe que des séquences de transitions identiques peuvent donner des sorties différentes, et vice-versa.
Ce jeu peut être modélisé par un Automate de Markov à états cachés : les groupes de sacs sont les états, les tirages donnant le groupe de tirages suivant sont les transitions (avec la probabilité associée en fonction de la proportion des jetons dans les sacs A ou B), les sacs de sortie donnent les valeurs de sortie de l'automate (avec la probabilité associée en fonction de la proportion des jetons dans les sacs A' ou B').
Le jeu précédent correspond donc à l'automate de Markov à états cachés suivant :
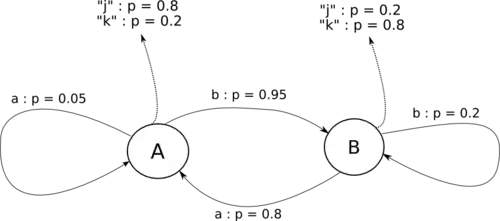
Les flèches en pointillés indiquent les sorties probables à chaque passage dans un état.
Définition formelle d'un Modèle de Markov Caché (MMC) [1]
Formellement, un MMC est défini par :
l'ensemble discret des états du modèle; on désigne un état au temps par .




l'ensemble discret des symboles observables; on désigne un symbole au temps par .



la probabilité de commencer dans l'état .


, où pour les modèles d'ordre ; est la matrice des probabilités de transitions entre états.




, où ; est la matrice des probabilités d'observation dans les états.



Habituellement, on désigne un MMC par le triplet .

Les contraintes classiques d'un MMC sont[2] :
: la somme des probabilités des états initiaux est égale à 1.

: la somme des probabilités des transitions partant d'un état est égale à 1.

: la somme des probabilités des observations d'un état est égale à 1.

Définition étendue d'un MMC : MMC à états spécifiques
Au début des années 2000, une définition étendue des MMC a été proposée[3][4]. Elle ajoute deux états spécifiques et qui modélisent respectivement les transitions permettant de (D)ébuter dans un état et de (F)inir dans un état.



Formellement, un MMC à états spécifiques est défini par :
l'ensemble discret des états du modèle plus les deux états spécifiques et ; on désigne un état au temps par .

l'ensemble discret des symboles observables; on désigne un symbole au temps par .
, où , , pour les modèles d'ordre ; est la matrice des probabilités de transitions entre états.




, où ; est la matrice des probabilités d'observation dans les états; Les états spécifiques et n'ont pas de probabilité d'observation.

On désigne un MMC à états spécifiques par le couple .

Les contraintes d'un MMC à états spécifiques sont :
.

.

Notons que la probabilité de commencer en un état () a disparu : elle est élégamment remplacée par les transitions de vers les états concernés; d'un point de vue intellectuel, ces transitions sont plus en accord avec la théorie des graphes, puisqu'il n'y a plus de cas spécifique pour le démarrage, mais des transitions comme toutes les autres; d'un point de vue technique, ces transitions sont strictement équivalentes aux probabilités de commencer dans des états, et leur réestimation conduit exactement au même résultat.

Concernant l'état , il permet de sortir proprement du modèle : cela mérite quelques explications. Pour des modèles fortement structurés[5], où les états se succèdent sans auto-boucler, les états finaux sont ceux où la dernière observation peut être vue. Pour des modèles où des états bouclent sur eux-mêmes[3], la notion de fin n'est pas déterminée : théoriquement, chaque état peut être final, sauf à avoir un ou des états finaux par structuration(s) forte(s) locale(s). L'état vient pallier ce manque : en assignant une probabilité de finir en des états, il contraint le modèle à évaluer cette probabilité, qui modélise alors l'équilibre entre la transition d'un état sur lui-même et sa qualité d'état final.
Utilisation
Il y a trois exemples typiques de problèmes que l'on peut chercher à résoudre avec un HMM :
- Connaissant l'automate, calculer la probabilité d'une séquence particulière (se résout à l'aide de l'algorithme Forward (en)) ;
- Connaissant l'automate, trouver la séquence la plus probable d'état (caché) ayant conduit à la génération d'une séquence de sortie donnée (se résout avec l'algorithme de Viterbi) ;
- Étant donné une séquence de sortie, retrouver l'ensemble d'états le plus probable et les probabilités des sorties sur chaque état. Se résout avec l'algorithme de Baum-Welch, appelé aussi algorithme forward-backward.
Applications
- Reconnaissance de la parole.
- Traitement automatique du langage naturel (traduction automatique, étiquetage de texte, reconstruction de texte bruités…).
- Reconnaissance de l'écriture manuscrite.
- Bio-informatique, notamment pour la prédiction de gènes.
Histoire
Les HMM ont été décrits pour la première fois dans une série de publications de statistiques par Leonard E. Baum et d'autres auteurs après 1965.
Ils ont été appliqués dès la fin des années 1970 à la reconnaissance vocale[2].
Dans la seconde moitié des années 1980, les HMM ont commencé à être appliqués à l'analyse de séquences biologique, en particulier l'ADN [6]. Les réseaux bayésiens dynamiques introduits au tout début des années 1990 généralisent le principe des HMM.
Apprentissage des HMM
Il existe plusieurs algorithmes pour réaliser l'apprentissage des paramètres d'un HMM. On peut citer notamment :
- L'algorithme de Baum-Welch est un cas particulier de l'algorithme espérance-maximisation et utilise l'algorithme Forward-Backward. Il permet de ré-estimer les paramètres de manière itérative.
- L'algorithme de Viterbi, souvent utilisé en décodage, peut également être utilisé pour l'apprentissage.
- Iterated Conditional Estimation ICE
Référence
- L. Rabiner et B. Juang, « An introduction to hidden Markov models », IEEE ASSP Magazine, vol. 3, no 1, , p. 4–16 (ISSN 0740-7467, DOI 10.1109/massp.1986.1165342, lire en ligne)
- Lawrence R. Rabiner, « A tutorial on Hidden Markov Models and selected applications in speech recognition », Proceedings of the IEEE, vol. 77, no 2, , p. 257–286 (DOI 10.1109/5.18626, lire en ligne [PDF]) .
- Christophe Choisy, Abdel Belaïd, « Apprentissage croisé en reconnaissance analytique de l’écriture manuscrite », Colloque International Francophone sur l’Ecrit et le Document - CIFEd'00, (lire en ligne)
- Christophe Choisy, Abdel Belaïd, « Cross-learning in Analytic Word Recognition Without Segmentation », International Journal on Document Analysis and Recognition, vol. 4, no 4, , p. 281-289 (DOI 10.1007/s100320200078).
- El Yacoubi, Mounim & Gilloux, M. & Sabourin, Robert & Suen, Ching, « An HMM-based approach for off-line unconstrained handwritten word modeling and recognition », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 21, no 8, , p. 752-760 (DOI 10.1109/34.784288, lire en ligne)
- M Bishop et Thompson E, « Maximum likelihood alignment of DNA sequences », J Mol Biol, vol. 190, no 2, , p. 159–65 (PMID 3641921, DOI 10.1016/0022-2836(86)90289-5).