Cloud de FPGA
Ces dernières années, les cloud FPGA (Field Programmable Gate Arrays) commencent à émerger dans le domaine du cloud computing. Les FPGA ont été déployés dans des centres de données des principaux fournisseurs de services cloud, tels que Microsoft, Amazon, Alibaba et Huawei et sont accessibles par les entreprises ou le grand public.

Au fil des années, les clouds FPGA se sont virtualisés pour être multi-utilisateurs et multi-applications exposant cette architecture à différentes menaces dont il est important d'apporter une réponse sur le plan de la sécurité.
L'accélération des calculs, la sécurisation et la performance énergétique sont les principales motivations de ce déploiement dans les centres de données et l'on retrouve leur utilisation dans différents domaines tels que la médecine, le BigData, l'éducation et la télécommunication.
Motivations
Accélération des calculs
L'une des motivations de l'utilisation des FPGA dans le cloud est l'accélération des calculs. Certains FPGA sont utilisés comme accélérateurs statiques, conçus une seule fois et utilisés pour une seule fonction[1]. Les systèmes combinant processeur et FPGA offrent une bande passante de donnée extrêmement élevée permettant à des applications de haute performance avec une exécution matérielle et logicielle entrelacée, comme par exemple la puce Xilinx Zynq[2]. Les FPGA sont très utilisés pour les applications intensives en calcul grâce à leur puissance et leurs délais d'exécution rapides[3]. La performance clé et les avantages de puissance sont réalisés en concevant des calculs personnalisés des chemins de données adaptés à une application particulière[1]. Les FPGA sont connus pour surpasser les GPU dans de nombreuses applications spécifiques (Chiffrement, Mathématique et Médicale)[4].
Sécurisation du Cloud
La sécurité figure parmi les motivations principales de l'utilisation des FPGA dans le cloud. L'une des techniques de sécurisation est le chiffrement homomorphe. Il est une réponse prometteuse aux problèmes de sécurité soulevés par le cloud computing car il permet de stocker et de manipuler des données à distance sous une forme chiffrée, empêchant efficacement le serveur d'accéder aux informations traitées[5].
Faible consommation d'énergie des FPGA
La faible consommation d'énergie est l'une des raisons de l'utilisation des FPGA dans le cloud. Un des moyens possibles qui permettent d'améliorer l'efficacité énergétique d'un nœud dans le cloud computing consiste à appliquer des accélérateurs matériel basés sur le FPGA[6]. L'une des approches est de s'intéresser à la réduction énergétique des composants de l’infrastructure cloud[6].
Architecture
CoProcesseur
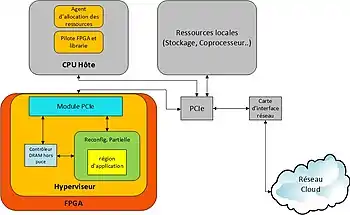
L'hyperviseur FPGA est une plateforme spécifique[7] pour piloter les accélérateurs FPGA qui sont utilisés comme périphériques connecté en PCIExpress[8]. OpenCL fournit non seulement l'API pour communiquer et gérer les périphériques informatiques à l'intérieur du FPGA; il est aussi utilisé comme langage et API de programmation pour des appareils hétérogène[9] pour une application hôte exécuté sur une machine CPU[10].
Un système d'exploitation est proposé pour gérer les FPGA[11]. L'OS a une gestion complète du bus PCIExpress du serveur de connectivité, pour permettre au FPGA d'accéder aux périphériques connectés au serveur. Le système d'exploitation assure également, la prise en charge de l'allocation de ressources FPGA aux utilisateurs et aux applications cloud[12].
Un autre cas d'usage présente une approche PaaS afin de simplifier la formation et le développement des systèmes FPGA-attachés[13]. Ce système se compose d'un environnement de développement Web personnalisable et d'un système de gestion de cluster CPU-FPGA. Cela permet de compléter le développement FPGA grâce à un navigateur et le système PaaS peut par la suite réaliser automatiquement la compilation et le déploiement FPGA[14].
Autonome
La dissociation du FPGA d'un serveur hôte est préconisée au moyen d'une interface de contrôleur de réseau (Network interface controller : NIC) 10GbE, connectant le FPGA au réseau du centre de données en tant que ressource autonome[15]. Il en découle un changement majeur sur la carte FPGA qui devient un appareil indépendant. Celui-ci exécute des tâches qui étaient auparavant sous le contrôle d'un processeur hôte, comme les actions de mise sous tension et hors tension, se connecter au réseau après la mise sous tension, réaliser des tâches locales de surveillance de l'état et de gestion du système[16]. On peut ajouter à ce qui a été décrit, cette étude se repose également sur des services cloud courants[17] et le Transfert d'état de représentation (REST)[17].
Virtualisation
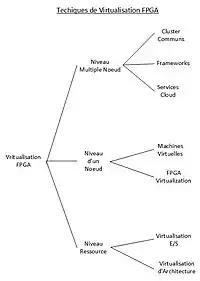
Une manière de classer les travaux existants sur la virtualisation des FPGAs, peut être de les organiser par niveau d'abstraction des systèmes de calcul qui utilisent la virtualisation. On peut donc les classer au niveau ressource, d'un noeud, ou de multiples noeuds[18].
Au Niveau ressource
La ressource peut être de deux types : reconfigurable, on parle de virtualisation d'architecture; et non reconfigurable, dans le cas de la virtualisation des E/S[18].
Les overlays (superpositions) sont des architectures implémentées sur les FPGAs reconfigurables[19]. Ainsi, un overlay peut être vu de deux manières : l'architecture fonctionnelle est la vue de dessus, c'est l'ensemble des éléments reconfigurables disponibles pour les applications ciblant l'overlay. La mise en œuvre est la vue de dessous, c'est la manière dont l'architecture fonctionnelle est mise en œuvre et synthétisée sur le FPGA hôte[19]. Ces architectures offrent trois avantages : ils peuvent être utilisés pour homogénéiser différents FPGA vendus sur l'étagère COTS (Commercial Of The Shelf) hétérogènes, en implémentant la même architecture fonctionnelle sur différents hôtes. L'architecture fonctionnelle de superposition peut être plus grossière, plus simple et plus abstraite que celle de son hôte. Les concepteurs d'overlay peuvent ajouter des fonctionnalités, à l'implémentation de l'overlay, qui peuvent ne pas être présentes sur le FPGA hôte (sauvegarde de contexte dynamique, restauration du préchargement de la reconfiguration)[19]. Il est ajouté de nouvelles fonctionnalités pour permettre la planification préventive des tâches matérielles et la migration en direct[19].
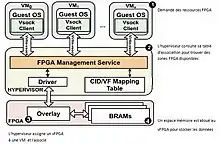
Un autre cadre de virtualisation permet d'implémenter un système de communication efficace entre les machines virtuelles et les FPGAs physiques non reconfigurable[20]. Il utilise une technique spécifique[21] pour les communications entre VM et FPGA[20]. Il utilise la table de mappage CID (Context Identifier)[22]/VF (Virtual Functions)[22] qui enregistre des régions FPGA attribuées aux machines virtuelles. Le FPGA possède principalement une architecture de superposition en pourvoyant des fonctions virtuelles VF (Virtual Functions) aux machines virtuelles VM (Virtual Machine), et un ensemble de BRAM (Blocs de RAM) pour stocker les données des VFs conçus avec une taille spécifique[23]. L'architecture overlay fournit plusieurs VFs sur le même FPGA ou sur plusieurs FPGA distants à un utilisateur; cela permet de répondre aux exigences de disponibilité des services cloud sur les tâches matérielles d'un utilisateur sur plusieurs FPGA[23]. Lorsqu'un VF est attribué à un utilisateur, le service de gestion du FPGA fait une mise à jour de sa table mappage CID/VF pour pouvoir enregistrer l'utilisateur en question. Par la suite, il configure le HWSB (HardWare SandBoxes)[24] en bloquant toutes tentatives d'accès à un VF ou BRAM qui n'appartient pas à l'utilisateur enregistré; cela permet de répondre aux exigences d'isolements du Cloud[23].
Au Niveau d'un nœud
Au niveau d'un nœud : le terme "nœud" signifie un FPGA unique. L'infrastructure et les techniques de management du FPGA sont le sujet de cette rubrique[18].
Ce système adopte le moniteur de machine virtuelle VMM (Virtual Machine Monitor) Xen pour créer un environnement paravirtualisé comme accélérateur FPGA. Il se différencie des autres techniques, car la virtualisation se réalise directement au niveau du pilote du périphérique[4]. Pour permettre l'utilisation de l'accélérateur FPGA dans le cas du pvFPGA (paravirtualized FPGA)[25], il faut un mécanisme de transfert partant de quelques dizaines de kilo-octets jusqu'à des gigaoctets de données entre le serveur et l'accélérateur FPGA. La mise en place d'un composant appelé coproviseur[26] pour pvFPGA permet le multiplexage des requêtes provenant de différents domaines et accédant au coprocesseur FPGA. Cette proposition repose sur la virtualisation GPU, qui réalise le travail de multiplexage dans l'espace utilisateur; plus précisément, le multiplexeur et l'ordonnanceur sont situés au-dessus du CUDA (Compute Unified Device Architecture), qui fournit deux interfaces de programmation : l'API du pilote et l'API d'exécution[27] - [28] - [29].
Le prototype RC2F (Reconfigurable Common Computing Frame) qui s'appuie sur des études antérieures[30], se base sur plusieurs vFPGAs (virtual FPGAs) utilisateurs fonctionnant sur un seul FPGA[31]. La partie principale est composée d'un hyperviseur[32] qui gère la configuration, les cœurs FPGA et la surveillance des informations d'état[31]. L'espace mémoire du contrôleur est disponible depuis l'hôte via une API. Les FIFO d'entrée sortie, procurent un débit élevé pour des applications comme le streaming. Les vFPGAs apparaissent comme un périphérique individuel au sein de la machine virtuelle du point de vue de l'utilisateur[31] - [33]. Les FPGA sont situés sur le système d'hôte accessible depuis l'interface PCIExpress. Sur les deux composants hôtes et FPGA, il existe un hyperviseur qui gère les accès des vFPGA, la configuration des vFPGA, l'affectation des vFPGA, et les communications de la puce entre les interfaces frontend et backend via le PCIExpress (le prototype utilise un PCIe-Core de Xillybus pour l'accès direct à la mémoire DMA(Direct Memory Access)[34]. L'hyperviseur FPGA s'occupe de la gestion des vFPGA, leur encapsulation, la gestion de l'état et la reconfiguration[35] grâce à l'ICAP (Internal Configuration Access Port)[33]. L'interaction entre l'hôte et l'hyperviseur FPGA repose sur la mémoire de configuration composée de : la configuration de l'hyperviseur FPGA (état du système, donnée de configuration et état général) et l'administration des vFPGA[33].
Au Niveau multiple noeud

Le "multiple nœuds" est défini comme un cluster de deux ou plus puces FPGA. Dans cette section, on traite des techniques et architectures utilisées pour connecter plusieurs FPGA combinés afin d'accélérer une tâche[18].
Les FPGA sont déployés sur l'ensemble d'un lot de serveurs, chaque serveur possède une petite carte avec un FPGA et une DRAM[36](une photo de cette carte ci-contre). Les FPGA sont directement câblés ensemble, permettant aux services d'allouer des groupes de FPGA pour fournir la zone reconfigurable nécessaire afin d'implémenter la fonctionnalité souhaitée[36]. Les FPGAs communiquent à travers un réseau spécialisé pour faciliter la communication FPGA-FPGA sans dégrader le réseau Ethernet du centre de données[36]. Cela permet de mapper logiquement les services sur plusieurs FPGA[37]. Catapult, qui s'appuie sur cette structure, est une partie importante du moteur de classement Bing[38]. L'interface logicielle participe à la gestion de la compression des requêtes vers Bing en document[38]. Pour y arriver, différents mécanismes sont mis en place comme : Le pipeline de traitement divisé en plusieurs étapes de macropipelines, ce qui limite la durée de traitement[39]. Une file d'attente de requêtes et documents se situe dans la DRAM du FPGA, pour être traité par le pipeline[39]. Il existe d'autres fonctionnalités de Catapult comme l'expression de forme libre[40] et la notation des documents[41].
La solution proposée est une réponse aux deux limitations majeures du FPGA, le difficile couplage entre la compilation et l'allocation des ressources, et la complexité de la programmation de l'accélération des FPGA[42]. ViTAL fournit une abstraction pour séparer la compilation et l'allocation des ressources. La compilation des applications est réalisée hors ligne sur l'abstraction, tandis que l'allocation des ressources est faite dynamiquement au moment de l'exécution[42]. ViTAL crée l'illusion d'un seul et grand FPGA pour les utilisateurs, ce qui allège la complexité de la programmation, et prend en charge l'accélération de la montée en charge[42]. De plus, il fournit une prise en charge de la virtualisation pour les composants périphériques (par exemple, DRAM et Ethernet intégrés), ainsi qu'une prise en charge de la protection et de l'isolation pour garantir une exécution sécurisée dans l'environnement cloud[42]. Cette nouvelle abstraction système, qui permet de faire l'intermédiaire entre les FPGA et la couche compilation[43]. Pour la prise en compte de cette abstraction, un FPGA physique est partitionné en trois régions, la région de service (modules dédiés pour réaliser le support de virtualisation des périphériques), la région de communication (comprend des tampons et une logique de contrôle pour implémenter l'interface), et la région utilisateur divisée en un groupe de blocs physiques identiques[44]. La couche compilation met à disposition un flux de compilation générique pour appliquer des applications écrites dans divers langages de programmation de haut niveau sur différents FPGA[45]. La partition fractionne une "netlist" donnée générée à partir de l'étape précédente en un groupe de blocs virtuels[45] - [46].
Fiabilité
Les FPGA basés sur SRAM (Static Random Access Memory)[47] - [48] utilisent celle-ci pour développer les fonctions de routage et de calcul de base, grâce à l'utilisation de LUT et de MUX[49]. Il utilise un commutateur SRAM comme élément programmable qui est un transistor passe-oxyde mince[49]. En fonction de la valeur de la tension, le commutateur peut soit permettre aux données de traverser l'entrée du commutateur, soit interrompre la connexion entre elles[50]. Le bouleversement d'événement unique SEU (Single-Event Upsets)[50] est défini comme des erreurs induites par le rayonnement dans les circuits microélectroniques provoqués lorsque des particules chargées (provenant de ceintures de rayonnement ou de rayons cosmiques)[50] - [51]. Dans les FPGA, les SEU peuvent directement corrompre les résultats des calculs ou induire des modifications de la mémoire de configuration[50]. Les bouleversements doivent être détectés[52] et corrigés pour garantir que les erreurs ne s'accumulent pas[53]. Les particules chargées peuvent également modifier la fonction logique du circuit mappé lorsqu'elles atteignent la configuration sur la puce[52] - [51] - [50].
Sur le même thème, il est bon de citer l'effet d'événement unique SEE (Single Event Effect)[54], dans les environnements terrestres, causés par divers neutrons et des particules alpha[55]. ainsi que les méthodes pour mesurer le taux d'erreurs modéré, grâce entre autres, en matière de défaillances dans le temps FIT (Failures In Time), et de temps moyen avant défaillance MTTF (Mean Time To Failure)[55]. Les auteurs éprouvent le FPGA par des injections volontaires d'erreurs et commentent les résultats[56] - [57].
L'impact de la sécurité sur l'architecture
La sécurité n'est pas sans impact sur l'architecture des cloud FPGA.
Habituellement, l'utilisateur doit faire confiance au service de cloud pour que ces données garde leur confidentialité. Une telle confiance n'est cependant pas nécessaire, si la nature des données de l'utilisateur reste inaccessible grâce à un chiffrement. On peut donc garder les données utilisateurs chiffrées tout du long du traitement. Lorsque les données sont traitées doivent être rendus à un autre utilisateur, il est habituellement nécessaire de déchiffrer ces données pour les chiffrer à nouveau avec la clé de cette autre utilisateur. Un déchiffrement n'est cependant pas nécessaire si l'on utilise un proxy de re-chiffrement.
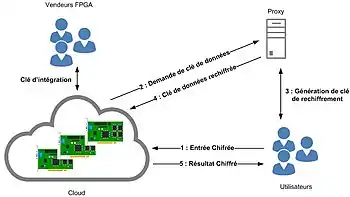
Parmi les solutions existantes, il y a la mise en place d'un proxy de re-chiffrement qui permet de rechiffrer les données déjà chiffrées[58].
Le concept du proxy de re-chiffrement permet aux utilisateurs d'utiliser leurs propres clés pour le chiffrement. De plus, la donnée chiffrée par la clé d’un utilisateur peut être re-chiffré par une clé FPGA sans déchiffrer la donnée chiffrée. Cela permet à l'utilisateur et au FPGA d'échanger des données chiffrées sans échanger de clé[59].
Il y a généralement trois parties pour une architecture d'un proxy de re-chiffrement : l'utilisateur 𝐴, l'utilisateur 𝐵 et le proxy. Les utilisateurs A et B possèdent une paire de clés (𝑝𝑘𝐴, 𝑠𝑘𝐴) et (𝑝𝑘𝐵, 𝑠𝑘𝐵) respectivement. Avec les informations des clés, une clé de re-chiffrement 𝑟𝑘𝐴𝐵 peut être calculé. La clé de re-chiffrement est généralement envoyée au Proxy[58]. Le fournisseur de FPGA est également responsable de l'intégration des clés dans les FPGA. Les clés peuvent être intégrées dans le bitstream FPGA qui est chiffré[60].
Parmi d’autres solutions afin de mettre en œuvre la sécurité, il y a les fonctions physiques non clonables PUF(Physical Unclonable Functions) qui sont des puces électronique. Les fonctions non clonables physiques (PUF) sont utilisées principalement pour l'authentification et le stockage de clé[61] - [62] - [63]. Les deux principales applications des PUF sont : l'authentification à faible coût et la génération de clé sécurisée[64].
La confidentialité des données
Les données utilisateurs sont protégées par des protocoles cryptographiques comme l'Oblivious Transfer et le Yao’s Garbled Circuit (en)[65]. L'un des protocoles très efficace utilisé est le chiffrement homomorphe pour préserver la confidentialité[66].
L'adoption d'un flux de bits de bootstrapper sécurisé par les fabricants de FPGA est une technique de sécurisation. Le programme d'amorçage sécurisé partage une clé secrète avec ses clients et déchiffre les données et le flux de bits[59]. Les accélérateurs FPGA sont mis en œuvre pour des techniques de préservation de la confidentialité des données, comme par exemple les circuits brouillés ou l'évaluation de fonction sécurisée[67]. Un accélérateur matériel a été conçu pour l'apprentissage automatique (Machine Learning) préservant la confidentialité sur les serveurs cloud qui repose sur une architecture FPGA et le protocole cryptographique Circuit brouillé de Yao[68].
Les différentes menaces de sécurité
L'enjeu de la sécurité des cloud FPGA est soumis à différentes menaces. Dans le cas des cloud multi-utilisateurs, certains utilisateurs ou administrateurs malveillants peuvent accéder aux données d’autrui[69].
Parmi les types de menaces, il y a les outils FPGA malveillants qui remplacent certaines fonctions des outils FPGA. La modification malveillante dans la conception compilée n'apparaît qu’à la génération du bitstream. Dans le processus de génération de flux bitstream, l'outil de conception recherche ces modifications malveillantes. Si l'outil trouve ces modifications malveillantes, il les reconfigure pour activer le cheval de Troie (informatique)[70]. Comme menace malveillante, on trouve les trojan (cheval de troie) conçu spécifiquement pour les FPGA. Par exemple le cheval de troie LUT (LookUp Table) qui s'injecte et se déclenche par le bitstream (flux de conception)[71].
L’une des attaques possible sur les FPGA est de les reprogrammer pour générer des fluctuations de tension excessives en utilisant des bitstream valides. Cela peut provoquer un crash de l'appareil dans un court laps de temps. Dans le pire des cas, l'appareil ne se réinitialisera pas, ça sera une attaque Deny Of Services (DoS). Il faudra alors débrancher physiquement l’appareil[72].
Il y a aussi les attaques par injection de faute (Fault-injection attacks), un attaquant injecte des fautes dans l'exécution processus d'une tâche de calcul. Ainsi, l'appareil produit des sorties erronées au niveau des ports de sortie. Ce problème peut avoir de graves conséquences dans un système cryptographique. Dans un tel système, des sorties défectueuses due à l’attaque peut conduire à une récupération réussie de la clé secrète dans le système[73].
Les solutions du marché
Avec la croissance des demandes de ressources FPGA, les offres commencent à émerger sur le marché du cloud computing.
Amazon propose des FPGA aux développeurs d'applications à travers son offre EC2 F1[74] pour permettre la création d’une accélération matérielle personnalisée[74]. Ils proposent également des infrastructures FPGA et des applications pour des domaines ciblés comme la cryptologie avec AWS Cloud Crypto[75] ou encore le machine learning avec FPGA-Accelerated Deep-Learning[76].
OVH lance en 2017[77] une offre "Acceleration as a Service" en partenariat avec Accelize qui propose un magasin d'applications pour la finance et les études de marché basée sur la technologie FPGA de Xilinx[78].
Huawei propose également des offres "Cloud accéléré" qui reposent sur des FPGA VU9P de Xilinx[79].
Microsoft utilise les FPGA sur son cloud Azure en tant qu'accélérateur dans le domaine du machine learning. Il est alors possible de déployer un modèle en tant que service Web sur des FPGA pour réduire la latence et améliorer les performances[80].
| Entreprise | Offre | Nombre de FPGA | Constructeur FPGA | Implémentation | Domaine |
|---|---|---|---|---|---|
| Amazon | EC2 F1 | 1/2/8 FPGA | Xilinx UltraScale Plus FPGA | Coprocesseur (PCIE) | Développement |
| Amazon AWS | FPGA Cloud Crypto | 1 FPGA | Xilinx UltraScale Plus FPGA | Coprocesseur (PCIE) | Cryptologie |
| Amazon AWS | FPGA-Accelerated Deep-Learning | 1 FPGA | Xilinx UltraScale Plus FPGA | Coprocesseur (PCIE) | Machine learning |
| Accelize | Pro | - | Xilinx | - | Finance/Marché |
| Accelize | Entreprise | - | Xilinx | - | Finance/Marché |
| Huawei | FP1 basic/enhanced | 1/4/8 | Xilinx VU9P | Coprocesseur (PCIE) | Développement |
| Alibaba | ecs.f3 | 1/2/4 | Xilinx VU9P | Coprocesseur (PCIE) | Développement |
| Alibaba | ecs.f1 | 1/2/4 | Intel Arria 10 GX 1150 | Coprocesseur (PCIE) | Développement |
| Microsoft | Azure ML | - | Intel Arria 10 | Coprocesseur (PCIE) | Machine learning |
Exemples d'utilisation
Apprentissage Automatique
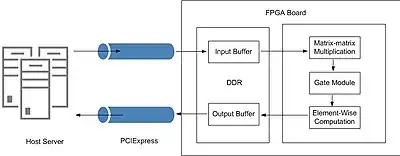
La complexité de calcul élevée des réseaux de neurones représente un défi critique pour leur adoption plus large dans des scénarios en temps réel et éco-énergétiques[81]. Dans l'implémentation de certains algorithmes utilisés pour l' Apprentissage automatique tel que Long Short-Term Memory (LSTM), les CPU et GPU ne peuvent pas atteindre de parallélisme élevé et consomment beaucoup. L'utilisation des FPGA dans ce contexte, de par leur flexibilité permet d’améliorer l'efficacité énergétique et d'optimiser chaque étape de l’algorithme de calcul[82].
Le fonctionnement est le suivant. Le serveur hôte reçoit les demandes de calculs des clients et leur répond. Il transfère également les données et taches gourmandes en calculs au FPGA via l'interface PCIExpress. Ces tâches sont "bufferisées" sur la mémoire persistante de la carte FPGA avant d'être relayées sur la puce FPGA par le bus AXI4 (ou AXI4Lite)[83]. Sur la puce FPGA est intégré les fonctions algorithmiques de Long Short-Term Memory (LSTM) qui est un réseau de neurone récurrent(RNN)[83] ou plus généralement les fonctions de réseau de neurone profond (DNN)[84].
Data Caching
Les magasins de valeurs-clés KVS (Key–value Store) deviennent de plus en plus courant dans les infrastructures Web mais ces technologies sont souvent implémentées sur des serveurs dont les performances sont limitées[85].
Memcached, déjà utilisé par des grands acteurs informatique tels que Facebook, Wikipédia, Flickr et Wordpress[86] est alors limité par le processeur dans des infrastructures classiques[87].
Les projets visant à utiliser des FPGA comme accélérateur memcached permettent d'obtenir de meilleurs résultats sur trois domaines : la latence, le débit en opérations par seconde et le coût.
| Projet | Avec FPGA | Sans FPGA | Solution Comparée |
|---|---|---|---|
| LegUp Computing Inc sur Amazon F1[88] | 7M Opérations/Seconde/$ | 691K Opérations/Seconde/$ | Amazon ElastiCache (1400 connexions simultanées) |
| Accelerateur pour Memcached (CPU+FPGA Xilinx Virtex-5 TX240T FPGA)[89] | 51.61K Requêtes/Seconde/Watt | < 22.5K Requêtes/Seconde/Watt | CPU Intel Xeon |
| HP (appareil FPGA Memcached)[90] | 88.62K Opérations/Seconde/$ | 24.69K Opérations/Seconde/$ | CPU Intel Xeon |
Equilibreur de Charge
Les équilibreurs de charge sont des éléments essentiels dans les centres de données permettant de répartir les demandes entre serveurs actifs. L'implémentation d'un équilibreur de charge sur des ressources FPGA virtualisées permet de surpasser une version logicielle installé sur un serveur standard en termes de débit et de latence[91].
L'utilisation d'une telle solution montre que l'équilibreur de charge FPGA garde une latence constante malgré l'augmentation du débit et ne perd aucun paquet contrairement à un équilibreur de charge sur machine virtuelle ou quand la charge augmente, le nombre de paquets abandonnés et la latence sont en hausses[91].
L'autre avantage réside dans la gestion du Cloud. En effet, un équilibreurs de charge FPGA peut remplacer plusieurs machines virtuelles simplifiant et rationalisant le systèmes de l'utilisateur, potentiellement réduire les coûts d'exploitation et réduire la consommation d'énergie globale et les coûts du centre de données[92].
Télécommunication
Les fournisseurs de services de télécommunications sont confrontés à des demandes d'utilisation croissantes, une augmentation exponentielle des abonnés mobiles et des appareils de l'Internet des objets[93]. Avec l'arrivée de la 5G, la virtualisation des fonctions réseau NFV (Network function virtualization) est cruciale[94].
La virtualisation des fonctions réseau est aujourd'hui une tendance importante dans l'industrie des réseaux, qui vise à remplacer les fonctions réseau de télécommunications actuelles basées sur des composants matériels spécialisés, par des fonctions de réseau virtuel fonctionnant sur des serveurs à usage général[95]. Le déplacement des NFV d'un matériel spécialement conçu vers des serveurs virtualisés à usage général présente en fait de gros avantages du point de vue de la maintenabilité et de la flexibilité, mais présente des défis sans précédent pour les processeurs qui ne sont pas en mesure de faire face aux besoins des opérateurs de réseau mobile[95].
Dans cet exercice, les FPGA sont une solution prometteuse pour les environnements cloud NFV et 5G en raison de leur temps d'exécution rapide et de leur grand potentiel d'accélération grâce à la cartographie du parallélisme des applications sur la structure reconfigurable[94] - [95].
Dans ce contexte, Intel travaille avec des leaders de l'industrie qui développent des solutions afin de transformer le réseau de demain pour les NFV (Open vSwitch,Segment routing V6), le réseau d'accès (Virtual RAN,LDPC 5G), le réseau cœur et périphérique(Réseau Cœur 5G, virtual Evolved Packet Core, et la sécurité (Virtual Firewall,IPsec & TLS)[93].
Chiffrement
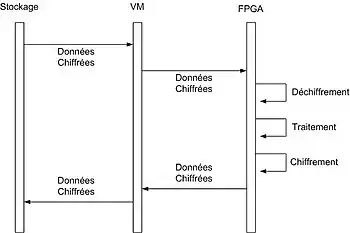
Le Chiffrement homomorphe est une technique permettant au calcul de se dérouler sur des données chiffrées[5].
Les implémentations précédentes de ce chiffrement homomorphe sur des processeurs à usage général avaient une latence très longue[96] et des coûts de calcul extrêmement élevés[5] ce qui le rend impraticable pour le cloud computing.
Les algorithmes de chiffrement ont des caractéristiques particulières, comme le calcul intégral ou la manipulation au niveau des bits ce qui rend les plates-formes standard comme les CPU et les GPU moins compétitives que les FPGA[5]. Par rapport à l'accélération GPU, la conception basée sur FPGA a une consommation d'énergie beaucoup plus faible et de meilleures performances[97].
Les résultats obtenus sur différentes études soulignent le grand potentiel des technologies FPGA dans l'accélération d'algorithmes cryptographiques à forte intensité de calcul[98].
Une autre approche que le chiffrement homomorphe travaillant sur des données chiffrées permet de développer et d'implémenter des fonctions sécurisées dans un langage de haut niveau. Ainsi, les données sont transmises chiffrées et le FPGA les déchiffre, exécute une fonction préalablement développée et chiffre de nouveau le résultat avant de le retourner[99].
Big Data
Les FPGA reçoivent beaucoup d'attention ces dernières années pour les applications d'analyse des données en raison de leur capacité à prendre en charge le traitement parallèle personnalisé[100]. Les nouvelles applications d'analyse de Big Data nécessitent une quantité importante de puissance de calcul du serveur[101], chose pour laquelle sont reconnus les FPGA[66]. Ils sont de ce fait déployés dans l'environnement cloud en tant qu'accélérateurs pour le traitement de données à grande échelle comme MapReduce[66].
L’intérêt des FPGA dans ce domaine est d'accélérer le traitement des données[102], d'augmenter l’efficacité énergétique[101] en déchargeant les fonctions intensives en calcul vers l'accélérateur matériel mais également de permettre, de par la flexibilité de programmation des puces, la mise en place d'une solution qui préserve la confidentialité de l’analyse de données en exploitant les propriétés de sécurité uniques des FPGA[66]. En combinant la méthode de protection par hashcode avec le cloud FPGA, les données de l'utilisateur sont correctement protégées : les textes en clair des données de l'utilisateur n'apparaissent qu'à l'intérieur des FPGA pour le traitement des données, et le fournisseur de services cloud n'a pas accès à ces dernières[103].
La programmation des FPGA est nécessaire avant son utilisation. Il faut préalablement convertir les fonctions C (Cartographie et réduction) de MapReduce en modules matériels HLS (High-level synthesis) avant de les transférer sur les puces FPGA[103]. Généralement, les fonctions sont implémentées en pipeline pour de meilleurs résultats[103] - [104].
Médecine
La médecine est également concerné par le cloud FPGA. En effet, la quantité de données générées en génomique devrait se situer entre 2 et 40 exaoctets par an pour la prochaine décennie, complexifiant ainsi leur analyse[105]. Les accélérateur FPGA dans le cloud permettent aux bio-informaticiens d’améliorer le temps d’exécution et le débit des analyses de données génomique[106] - [105]. Les performances et la rentabilité se révèlent nettement supérieur que GATK (boîte à outils d'analyse du génome) sur un serveur à CPU Xeon standard[106].
Education
Nous retrouvons également les plateformes cloud FPGA pour l'éducation. Une université chinoise a jugé intéressant d'intégrer un pool de ressources FPGA à disposition des étudiants informatique pour qu'ils développent leur capacité à visualiser le matériel et les logiciels dans un système informatique. Les étudiants acquièrent ainsi une méthodologie et des pratiques de co-conception matériel-logiciel[107].
Efficacité énergétique
Un centre de données représente la majeure partie de la consommation d'énergie dans l'infrastructure Cloud. De nos jours, les centres de données contiennent des milliers de nœuds de calcul qui consomment une énorme quantité d'électricité[108]. Malgré l'innovation mondiale appliquée au Green cloud computing, la plupart des entreprises informatiques choisissent d'acheter simplement de l'énergie au prix le plus bas au lieu d'augmenter l'efficacité des nœuds de calcul[109].
Augmenter les performances sur le Cloud, c'est augmenter le nombre de nœuds de calcul, ce qui conduit à augmenter la consommation d'énergie. D'autre part, les nœuds de calcul basés sur le CPU peuvent être remplacés par des solutions matérielles optimisées, dont l'efficacité est évidemment plus élevée[110]. Les processeurs universels tels que Atom et Xeon ne sont pas conçus pour offrir une efficacité maximale pour chaque application [111]. L'un des moyens possibles d'améliorer l'efficacité énergétique du nœud de Cloud computing consiste à utiliser des accélérateurs matériels basés sur FPGA[108] et décharger des applications vers un matériel dédié[111].
Les avantages des ressources FPGA sont la manière optimisée d'utiliser la solution matérielle[110] et leur excellent rapport performances/consommation[112]. Il est possible d'appliquer une solution FPGA optimisée basée sur le matériel pour une tâche de calcul précise améliorant significativement l'efficacité du calcul et la réduction de la consommation d'énergie du centre de données[110]. Les FPGA dans le cloud ont principalement été proposés pour une informatique plus verte réduisant ainsi l'énergie donc les coûts d'exploitation et les investissements dans les infrastructures pour les sources d'énergie vertes[113].
L'utilisation de FPGA sur des modèles informatiques existants tels que le Big Data permet une réduction de la puissance et une augmentation significative de l'efficacité énergétique[114].
Références
- Fahmy 2015, p. 430
- Fahmy 2015, p. 431
- Skhiri 2019, p. 01
- Wang 2013, p. 01
- Cilardo 2016, p. 1622
- Yanovskaya1 2014, p. 01
- SDAccel
- Tarafdar 2018
- OpenCL
- Tarafdar 2018, p. 25
- Zhang 2017
- Zhang 2017, p. 03
- Ryota 2019
- Ryota 2019, p. 02
- Abel 2017
- Abel 2017, p. 29
- Fielding 2000
- Bollengier 2016, p. 01
- Mbongue 2018
- virtio-vsock
- Mbongue 2018, p. 863
- Mbongue 2018, p. 864
- Bobda 2017, p. 50
- Wang 2013, p. 03
- Wang 2013, p. 04
- Shi 2012, p. 805
- Shi 2012, p. 806
- Gupta 2009, p. 18
- Knodel 2015, p. 341
- Knodel 2017, p. 34
- J.E. 2005, p. 36
- Knodel 2017, p. 35
- Xillybus
- Vivado-Design
- Putnam 2015, p. 11
- Putnam 2015, p. 12
- Putnam 2015, p. 13
- Putnam 2015, p. 14
- Putnam 2015, p. 16
- Putnam 2015, p. 17
- Zha 2020, p. 845
- Zha 2020, p. 848
- Zha 2020, p. 849
- Zha 2020, p. 850
- Zha 2020, p. 851
- Safarulla 2014
- Sari 2014
- Safarulla 2014, p. 1036
- Safarulla 2014, p. 1037
- Sari 2014, p. 237
- Manuzzato 2009
- Safarulla 2014, p. 1038
- alpha particle
- Keller 2019, p. 273
- Keller 2019, p. 277
- Keller 2019, p. 278
- Xu 2015, p. 20
- Jin 2020, p. 22
- Xu 2015, p. 04
- Herder 2014
- Jin 2020, p. 24
- Tian 2020
- Herder 2014, p. 1127
- Hussain 2018, p. 02
- Xu 2015, p. 17
- Jin 2020, p. 23
- Hussain 2018, p. 01
- Xu 2015, p. 21
- Jin 2020, p. 14
- Krieg 2016, p. 01
- Gnad 2017
- Jin 2020, p. 10
- Amazon F1
- AWS Cloud Crypto
- Deep-Learning
- OVH Accelize
- Accelize
- Huawei FPGA
- Microsoft ML
- Chen 2019, p. 73
- Wang 2019, p. 01
- Wang 2019, p. 03
- Chen 2019, p. 79
- Blott 2015, p. 01
- Choi 2018, p. 01
- Chalamalasetti 2013, p. 245
- Choi 2018, p. 08
- Lavasani 2014, p. 60
- Chalamalasetti 2013, p. 253
- Byma 2014, p. 114-115
- Byma 2014, p. 116
- NFV Intel
- Pinneterre 2018, p. 01
- Paolino 2017, p. 01
- Wang2 2013, p. 2589
- Wang2 2013, p. 2592
- Cilardo 2016, p. 1627
- Will 2017, p. 451
- Xu 2015, p. 16
- Neshatpour 2015, p. 115
- Kachris 2017, p. 357
- Xu 2015, p. 23
- Neshatpour 2015, p. 118
- Wu 2019, p. 277
- Wu 2020, p. 265
- Zhang 2019, p. 927
- Yanovskaya 2014, p. 01
- Yanovskaya 2014, p. 03
- Yanovskaya 2014, p. 02
- Neshatpour 2015, p. 121
- Proaño Orellana 2016, p. 01
- Will 2017, p. 453
- Neshatpour 2015, p. 122
Bibliographie
![]() : document utilisé comme source pour la rédaction de cet article.
: document utilisé comme source pour la rédaction de cet article.
- (en) Fei Chen, Yi Shan, Yu Zhang, Yu Wang, Hubertus Franke, Xiaotao Chang et Kun Wang, « Enabling FPGAs in the cloud », Proceedings of the 11th ACM Conference on Computing Frontiers, , p. 1-10 (ISBN 9781450372558, DOI 10.1145/2597917.2597929)
- (en) Yue Zha et Jing Li, « Virtualizing FPGAs in the Cloud », ASPLOS '20: Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, , p. 845-858 (ISBN 9781450371025, DOI 10.1145/3373376.3378491)

- (en) Watanabe Ryota, Saika Ura, Qian Zhao et Takaichi Yoshida, « Implementation of FPGA Building Platform as a Cloud Service », HEART 2019: Proceedings of the 10th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, , p. 1-6 (ISBN 9781450372558, DOI 10.1145/3337801.3337814)
- (en) Anca Iordache, Pierre Guillaume, Peter Sanders, Jose Gabriel de F. Coutinho et Mark Stillwell, « High performance in the cloud with FPGA groups », Proceedings of the 9th International Conference on Utility and Cloud Computing, , p. 1-10 (ISBN 9781450346160, DOI 10.1145/2996890.2996895)
- (en) Christophe Bobda et Ken Eguro, « Introduction to the Special Section on Security in FPGA-accelerated Cloud and Datacenters », ACM Transactions on Reconfigurable Technology and Systems, , p. 1-10 (ISSN 1936-7406, DOI 10.1145/3352060)
- (en) Naif Tarafdar, Thomas Lin, Eric Fukuda, Hadi Bannazadeh, Alberto Leon-Garcia et Paul Chow, « Enabling Flexible Network FPGA Clusters in a Heterogeneous Cloud Data Center », Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, , p. 237–246 (ISBN 9781450343541, DOI 10.1145/3020078.3021742)
- (en) Ke Zhang, Yisong Chang, Mingyu Chen, Yungang Bao et Zhiwei Xu, « Computer Organization and Design Course with FPGA Cloud », Proceedings of the 50th ACM Technical Symposium on Computer Science Education, , p. 927–933 (ISBN 9781450358903, DOI 10.1145/3287324.3287475)
- (en) Jiansong Zhang, Yongqiang Xiong, Ningyi Xu, Ran Shu, Bojie Li, Peng Cheng et Guo Chen, « The Feniks FPGA Operating System for Cloud Computing », Proceedings of the 8th Asia-Pacific Workshop on Systems, , p. 1–7 (ISBN 9781450351973, DOI 10.1145/3124680.3124743)
- (en) Andrew M. Keller, « Impact of Soft Errors on Large-Scale FPGA Cloud Computing », Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, , p. 272–281 (ISBN 9781450361378, DOI 10.1145/3289602.3293911)
- (en) Yao Chen, Jiong He, Xiaofan Zhang, Cong Hao et Deming CHen, « Cloud-DNN: An Open Framework for Mapping DNN Models to Cloud FPGAs », Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, , p. 73–82 (ISBN 9781450361378, DOI 10.1145/3289602.3293915)
- (en) Hussain Siam U, Bita Darvish Rouhani, Mohammad Ghasemzadeh et Farinaz Koushanfar, « MAXelerator: FPGA accelerator for privacy preserving multiply-accumulate (MAC) on cloud servers », DAC '18: Proceedings of the 55th Annual Design Automation Conference, , p. 1-6 (DOI 10.1145/3195970.3196074)
- (en) Rym Skhiri, Virginie Fresse, Jean Paul Jamont, Benoit Suffran Suffran et Jihene Malek, « From FPGA to Support Cloud to Cloud of FPGA: State of the Art », International Journal of Reconfigurable ComputingVolume 2019, Article ID 8085461, 17 pages, , p. 1-17 (DOI 10.1155/2019/8085461)
- (en) Jiasheng Wang, Yu Zhou, Yuyang Sun, Keyang Li et dand JunLiu, « Cloud Server Oriented FPGA Accelerator for LongShort-Term Memory Recurrent Neural Networks », IOP Conf. Series: Journal of Physics: Conf. Series1284 (2019) 012044, , p. 1-11 (DOI 10.1088/1742-6596/1284/1/012044)
- (en) Julio Proaño Orellana, Blanca Caminero, Carmen Carrión, Luis Tomas, Selome Kostentinos Tesfatsion et Johan Tordsson, « FPGA-Aware Scheduling Strategies at Hypervisor Level inCloud Environments », Scientific Programming Volume 2016, Article ID 4670271, 12 pages, , p. 1-13 (DOI 10.1155/2016/4670271)
- (en) Shanquan Tian, Wenjie Xiong, Ilias Giechaskiel, Kasper Rasmussen et Jakub Szefer, « Fingerprinting Cloud FPGA Infrastructures », FPGA 2020 - 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, , p. 1-8 (DOI 10.1145/3373087.3375322)
- (en) Burkhard Ringlein, Francois Abel, Alexander Ditter, Beat Weiss, Christoph Hagleitner et Dietmar Fey, « System architecture for network-attached FPGAs inthe Cloud using partial reconfiguration », Accepted for FPL 2019, , p. 1-8 (DOI 10.1109/FPL.2019.00054)
- (en) J. Mbongue, F. Hategekimana, D. Tchuinkou Kwadjo, D. Andrews et C. Bobda, « FPGAVirt: A Novel Virtualization Framework for FPGAs in the Cloud », 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), , p. 862-865 (ISSN 2159-6190, DOI 10.1109/CLOUD.2018.00122)
- (en) S. A. Fahmy, K. Vipin et S. Shreejith, « Virtualized FPGA Accelerators for Efficient Cloud Computing », 2015 IEEE 7th International Conference on Cloud Computing Technology and Science (CloudCom), , p. 430-435 (DOI 10.1109/CloudCom.2015.60)
- (en) V. Kulanov, A. Perepelitsyn et I. Zarizenko, « Method of development and deployment of reconfigurable FPGA-based projects in cloud infrastructure », 2018 IEEE 9th International Conference on Dependable Systems, Services and Technologies (DESSERT), , p. 103-106 (DOI 10.1109/DESSERT.2018.8409108)
- (en) A. Cilardo et D. Argenziano, « Securing the cloud with reconfigurable computing: An FPGA accelerator for homomorphic encryption », 2016 Design, Automation Test in Europe Conference Exhibition (DATE), , p. 1622-1627 (ISBN 978-3-9815-3707-9, ISSN 1558-1101)
- (en) M. A. Will et R. K. L. Ko, « Secure FPGA as a Service — Towards Secure Data Processing by Physicalizing the Cloud », 2017 IEEE Trustcom/BigDataSE/ICESS, , p. 449-455 (ISSN 2324-9013, DOI 10.1109/Trustcom/BigDataSE/ICESS.2017.270)
- (en) S. Byma, J. G. Steffan, H. Bannazadeh, A. L. Garcia et P. Chow, « FPGAs in the Cloud: Booting Virtualized Hardware Accelerators with OpenStack », 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, , p. 109-116 (DOI 10.1109/FCCM.2014.42)
- (en) A. A. Al-Aghbari et M. E. S. Elrabaa, « Cloud-Based FPGA Custom Computing Machines for Streaming Applications », IEEE Access, vol. 7, , p. 38009-38019 (ISSN 2169-3536, DOI 10.1109/ACCESS.2019.2906910)
- (en) T. La, K. Matas, K. Pham et D. Koch, « Securing FPGA Accelerators at the Electrical Level for Multi-tenant Platforms », 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), , p. 361-362 (ISSN 1946-1488, DOI 10.1109/FPL50879.2020.00069)
- (en) D. R. E. Gnad, F. Oboril et M. B. Tahoori, « Voltage drop-based fault attacks on FPGAs using valid bitstreams », 2017 27th International Conference on Field Programmable Logic and Applications (FPL), , p. 1-7 (ISSN 1946-1488, DOI 10.23919/FPL.2017.8056840)
- (en) J. Fowers, G. Brown, P. Cooke et G. Stitt, « A Performance and Energy Comparison of FPGAs, GPUs, and Multicores for Sliding-Window Applications », Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, , p. 47-56 (ISBN 9781450311557, DOI 10.1145/2145694.2145704)
- (en) Sai Rahul Chalamalasetti, Kevin Lim, Mitch Wright, Alvin AuYoung, Parthasarathy Ranganathan et Martin Margala, « An FPGA memcached appliance », Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, , p. 245-254 (ISBN 9781450318877, DOI 10.1145/2435264.2435306)
- (en) Michaela Blott, Liu Ling, Kimon Karras et Kees Vissers, « Scaling out to a Single-Node 80Gbps Memcached Server with 40terabytes of Memory », Proceedings of the 7th USENIX Conference on Hot Topics in Storage and File Systems, , p. 1-8 (DOI 10.5555/2827701.2827709)
- (en) Kevin Lim, David Meisner, Ali G. Saidi, Parthasarathy Ranganathan et Thomas F. Wenisch, « Thin Servers with Smart Pipes: Designing SoC Accelerators for Memcached », Proceedings of the 40th Annual International Symposium on Computer Architecture, , p. 36-47 (ISSN 0163-5964, DOI 10.1145/2485922.2485926)
- (en) M. Lavasani, H. Angepat et D. Chiou, « An FPGA memcached appliance », EEE Computer Architecture Letters, , p. 57-60 (ISSN 1556-6064, DOI 10.1109/L-CA.2013.17)
- (en) Jongsok Choi, Ruolong Lian, Zhi Li, Andrew Canis et Jason Anderson, « Accelerating Memcached on AWS Cloud FPGAs », Proceedings of the 9th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, , p. 1-8 (ISBN 9781450365420, DOI 10.1145/3241793.3241795)
- (en) Tarek El-Ghazawi, Kris Gaj, Volodymyr Kindratenko et Duncan Buell, « The Promise of High-Performance Reconfigurable Computing », IEEE Computer, vol. 41, no. 2, pp. 69–76, 2008, , p. 1-8 (DOI 10.1109/MC.2008.65)
- (en) Wei Wang, Miodrag Bolic et Jonathan Parri, « pvFPGA: Accessing an FPGA-based hardware accelerator in a paravirtualized environment », 2013 International Conference on Hardware/Software Codesign and System Synthesis, , p. 1-9 (ISBN 978-1-4799-1417-3, DOI 10.1109/CODES-ISSS.2013.6658997)
- (en) J.E. Smith et Ravi Nair, « The architecture of virtual machines », Computer (Volume: 38, Issue: 5, May 2005), , p. 32-38 (DOI 10.1109/MC.2005.173)
- (en) Oliver Knodel, Paul R. Genssier et Rainer G. Spallek, « Migration of long-running Tasks between Reconfigurable Resources using Virtualization », ACM SIGARCH Computer Architecture News, vol. 44, no Issue 4, , p. 56-61 (ISSN 0163-5964, DOI 10.1145/3039902)
- (en) Oliver Knodel et Rainer G. Spallek, « Computing framework fordynamic integration of reconfigurable resources in a cloud », 2015 Euromicro Conference on Digital System Design, , p. 337 - 344 (DOI 10.1109/DSD.2015.37)
- (en) Xiaolan Zhang, Suzanne McIntosh, Pankaj Rohatgi et John Linwood Griffin, « XenSocket: A High-Throughput Interdomain Transport for Virtual Machines », ACM/IFIP/USENIX International Conference on Distributed Systems Platforms and Open Distributed Processing Middleware 2007, , p. 184 - 203 (ISBN 978-3-540-76777-0, DOI 10.1007/978-3-540-76778-7_10)
- (en) Anuj Vaishnav, Khoa Dang Pham et Dirk Koch, « A Survey on FPGA Virtualization », 28th International Conference on Field Programmable Logic and Applications (FPL) Processing, , p. 131 - 138 (DOI 10.1109/FPL.2018.00031)
- (en) Andrew Putnam, Adrian M. Caulfield et Eric Chung et al., « A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services », IEEE Micro, vol. 35, no Issue 3, , p. 10 - 22 (ISSN 1937-4143, DOI 10.1109/MM.2015.42)
- (en) Philippos Papaphilippou, Jiuxi Meng et Wayne Luk, « High-Performance FPGA Network Switch Architecture », Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, , p. 76–85 (ISBN 9781450370998, DOI 10.1145/3373087.3375299)
- (en) W. Wang et X. Huang, « FPGA implementation of a large-number multiplier for fully homomorphic encryption », 2013 IEEE International Symposium on Circuits and Systems (ISCAS), , p. 2589-2592 (DOI 10.1109/ISCAS.2013.6572408)
- (en) Oliver Knodel et Paul R. Genssler, « Virtualizing Reconfigurable Hardware to Provide Scalability in Cloud Architectures », CENICS 2017 : The Tenth International Conference on Advances in Circuits, Electronics and Micro-electronics, , p. 33 - 38 (ISBN 978-1-61208-585-2)
- (en) Cristophe Bobda, Joshua Mead, Taylor J. L. Whitak, Charles Kwiat et Kevin Kamhoua, « Hardware Sandboxing: A Novel Defense Paradigm Against Hardware Trojans in Systems on Chip », International Symposium on Applied Reconfigurable Computing 2017, , p. 47-59 (DOI 10.1007/978-3-319-56258-2_5)
- (en) O Yanovskaya1, M. Yanovsky1 et V. Kharchenko1, « The Concept of Green Cloud Infrastructure Based on Distributed Computing and Hardware Accelerator within FPGA as a Service », Proceedings of IEEE East-West Design & Test Symposium (EWDTS 2014), , p. 1-4 (ISBN 978-1-4799-7630-0, DOI 10.1109/EWDTS.2014.7027089)
- (en) Rusty Russel, « virtio: towards a de-facto standard for virtual I/O devices », ACM SIGOPS Operating Systems Review, vol. 42, no Issue 5, , p. 95-103 (ISSN 0163-5980, DOI 10.1145/1400097.1400108)
- (en) Chenglu Jin, Vasudev Gohil, Ramesh Karri et Jeyavijayan Rajendran, « Security of Cloud FPGAs: A Survey », ACM Comput. Surv., Vol. 0, No. 0, Article 0, vol. 0, no 0, , p. 1-32
- (en) Christoforos Kachris, Dionysios Diamantopoulos, Georgios Ch. Sirakoulis et Dimitrios Soudris, « An FPGA-based Integrated MapReduce Accelerator Platform », Journal of Signal Processing Systems, , p. 357–369 (ISSN 1939-8115, DOI 10.1007/s11265-016-1108-7)
- (en) Lei Xu, Dionysios Pham, Hanyee Kim, Weidong Shi et Taeweon Suh, « END-TO-END BIG DATA PROCESSING PROTECTION IN CLOUD ENVIRONMENT USING BLACK BOXES - AN FPGA APPROACH », Services Transactions on Cloud Computing, , p. 16-29 (DOI 10.29268/stcc.2015.0002)
- (en) L. Wu, D. Bruns-Smith, F. A. Nothaft, Q. Huang, S. Karandikar, J. Le, A. Lin, H. Mao, B. Sweeney, K. Asanović, D. A. Patterson et A. D. Joseph, « FPGA Accelerated INDEL Realignment in the Cloud », 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), , p. 277-290 (DOI 10.1109/HPCA.2019.00044)
- (en) Vishakha Gupta, Ada Gavrilovska, Karsten Schwan, Harshvardhan Kharche, Niraj Tolia, Vanish Talwar et Parthasarathy Ranganathan, « GViM: GPU-accelerated virtual machines », HPCVirt '09: Proceedings of the 3rd ACM Workshop on System-level Virtualization for High Performance Computing, , p. 17-24 (ISBN 9781605584652, DOI 10.1145/1519138)
- (en) Lin Shi, Hao Chen, Jianhua Sun et Kenli Li, « vCUDA: GPU-Accelerated High-Performance Computing in Virtual Machines », IEEE Transactions on Computers, vol. 61, no Issue 6, , p. 804-816 (ISSN 1557-9956, DOI 10.1109/TC.2011.112)
- (en) Joon-Myung Kang, Hadi Bannazadeh, Hesam Rahimi, Thomas Lin, Mohammad Faraji et Alberto Leon-Garcia, « Software-Defined Infrastructure and the Future Central Office », IEEE International Conference on Communications Workshops (ICC), , p. 225-229 (ISBN 978-1-4673-5753-1, DOI 10.1109/ICCW.2013.6649233)
- (en) Kizheppatt Vipin et Suhaib A. Fahmy, « DyRACT: A partial reconfiguration enabled accelerator and test platform », Proceedings of the International Conference on Field Programmable Logic and Applications (FPL), , p. 1-7 (ISBN 978-3-00-044645-0, DOI 10.1109/FPL.2014.6927507)
- (en) O. Yanovskaya, M. Yanovsky et V. Kharchenko, « The concept of green Cloud infrastructure based on distributed computing and hardware accelerator within FPGA as a Service », Proceedings of IEEE East-West Design & Test Symposium (EWDTS 2014), , p. 1-4 (ISBN 978-1-4799-7630-0, DOI 10.1109/EWDTS.2014.7027089)
- (en) K. Neshatpour, M. Malik, M. A; Ghodrat, A. Sasan et H. Homayoun, « Energy-efficient acceleration of big data analytics applications using FPGAs », 2015 IEEE International Conference on Big Data (Big Data), , p. 115-123 (ISBN 978-1-4799-7630-0, DOI 10.1109/BigData.2015.7363748)
- (en) Christian Krieg, Clifford Wolf et Axel Jantsch, « Malicious LUT: a stealthy FPGA trojan injected and triggered by the design flow », ICCAD '16: Proceedings of the 35th International Conference on Computer-Aided Design, no Article No : 43, , p. 1-8 (ISBN 9781450344661, DOI 10.1145/2966986.2967054)
- (en) Naif Tarafdar, Nariman Eskandari, Thomas Lin et Paul Chow, « Designing for FPGAs in the Cloud », IEEE Design & Test, vol. 35, no Issue 1, , p. 23-29 (ISSN 2168-2356, DOI 10.1109/MDAT.2017.2748393)
- (en) Francois Abel, Jagath Weerasinghe, Christoph Hagleitner, Beat Weiss et Stephan Paredes, « An FPGA Platform for Hyperscalers », 2017 IEEE 25th Annual Symposium on High-Performance Interconnects (HOTI), , p. 29-32 (ISBN 978-1-5386-1013-8, DOI 10.1109/HOTI.2017.13)
- (en) S. Pinneterre, S. Chiotakis, M. Paolino et D. Raho, « vFPGAmanager: A Virtualization Framework for Orchestrated FPGA Accelerator Sharing in 5G Cloud Environments », 2018 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), , p. 1-5 (ISSN 2155-5052, DOI 10.1109/BMSB.2018.8436930)
- (en) M. Paolino, S. Pinneterre et D. Raho, « FPGA virtualization with accelerators overcommitment for network function virtualization », 2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig), , p. 1-6 (ISBN 978-1-5386-3797-5, DOI 10.1109/RECONFIG.2017.8279796)
- (en) Jagath Weerasinghe, François Abel, Christoph Hagleitner et Andreas Herkersdorf, « Enabling FPGAs in Hyperscale Data Centers », 2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), , p. 1078-1086 (ISBN 978-1-4673-7211-4, DOI 10.1109/UIC-ATC-ScalCom-CBDCom-IoP.2015.199)
- (en) T. J. Ham, D. Bruns-Smith, B. Sweeney, Y. Lee, S. H. Seo, U. G. Song, Y. H. Oh, K. Asanovic, J. W. Lee et L. W. Wills, « Genesis: A Hardware Acceleration Framework for Genomic Data Analysis », 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), , p. 254-267 (ISBN 978-1-7281-4661-4, DOI 10.1109/ISCA45697.2020.00031)
- (en) Ishan M Safarulla et Karthika Manilal, « Design of Soft error tolerance technique for FPGA based soft core processors », 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, , p. 1036-1040 (ISBN 978-1-4799-3914-5, DOI 10.1109/ICACCCT.2014.7019254)
- (en) Aitzan Sari, Dimitris Agiakatsikas et Mihalis Psarakis, « A soft error vulnerability analysis framework for Xilinx FPGAs », FPGA '14: Proceedings of the 2014 ACM/SIGDA international symposium on Field-programmable gate arrays, , p. 237-240 (ISBN 9781450326711, DOI 10.1145/2554688.2554767)
- (en) Roy T. Fielding et Richard N. Taylor, « Architectural Styles and the Design of Network-based Software Architectures », PhD thesis, , p. 1-162 (ISBN 978-0-599-87118-2)
- (en) Andrea Manuzzato, « SINGLE EVENT EFFECTS ONF PGAs », PhD thesis, , p. 1-105
- (en) C. Herder, M Yu et F Koushanfar, « Physical Unclonable Functions and Applications: A Tutorial », Proceedings of the IEEE, vol. 102, no 8, , p. 1126-1141 (ISSN 1558-2256, DOI 10.1109/JPROC.2014.2320516)
- (en) Oliver Knodel, Paul R. Genssler, Fredo Erxleben et Rainer G. Spallek, « FPGAs and the Cloud – An Endless Tale of Virtualization, Elasticity and Efficiency », International Journal on Advances in Systems and Measurements, vol. 11, no 3 & 4, , p. 230-249
- (en) Joon-Myung Kang, Hadi Bannazadeh et Alberto Leon-Garcia, « SAVI testbed: Control and management of converged virtual ICT resources », IFIP/IEEE International Symposium on Integrated Network Management (IM 2013), , p. 664-667 (ISBN 978-3-901882-50-0)
- (en) Théotime Bollengier, Mohamad Najem Najem, Jean-Christophe Le Lann et Loïc Lagadec, « Overlay Architectures For FPGA ResourceVirtualization », HAL archives-ouverte, no hal-0140591, , p. 1-2
Liens externes
- « Instances F1 Amazon EC2 » (consulté le )
- (en) « Cloud FPGA, IBM Research Europe Zurich » (consulté le )
- « Cloud Computing FPGA Applications - Intel FPGA » (consulté le )
- « Déployer des modèles ML sur des réseaux de portes programmables in situ » (consulté le )
- (en) « FPGAs in the Cloud - Bittware FPGA Acceleration » (consulté le )
- (en) « FPGAs and the New Era of Cloud » (consulté le )
- (en) « Live Demo of the World’s Fastest Cloud-Hosted Memcached on AWS F1 » (consulté le )
- (en) « Achieving 10Gbps Line-rate Key-value Stores with FPGAs » (consulté le )
- (en) « Vivado Design Suite User Guide Partial Reconfiguration UG909 » (consulté le )
- (en) « Accelize » (consulté le )
- « OVH lance l’accélération as a Service » (consulté le )
- (en) « Xillybus Ltd., Haifa, Israel, An FPGA IP core for easy DMAover PCIe » (consulté le )
- (en) « Amazon AWS - FPGA Cloud Crypto » (consulté le )
- (en) « Amazon FPGA-Accelerated Deep-Learning Inference with Binarized Neural Networks » (consulté le )
- (en) « Huawei FPGA Accelerated Cloud Server » (consulté le )
- (en) « Compute optimized instance families with FPGAs » (consulté le )
- (en) « Deploy ML models to field-programmable gate arrays (FPGAs) with Azure Machine Learning » (consulté le )
- (en) « Virtio-vsock Zero-configuration host/guest communication » (consulté le )
- (en) « OpenStack. (2013) OpenStack. [Online]. Available: http://www.openstack.org/ » (consulté le )
- (en) « NFV Workloads - Networking Applications with Intel FPGA » (consulté le )
- (en) « Xilinx Inc., SDAccel Development Environment. [Online] » (consulté le )
- (en) « The Khronos Group, OpenCL Standard. [Online] » (consulté le )
- (en) « Measurement and reporting of alpha particle and terrestrial cosmic ray-induced soft errors in semiconductor devices. » (consulté le )