Web sémantique
Le Web sémantique, ou toile sémantique[1], est une extension du Web standardisée par le World Wide Web Consortium (W3C)[2]. Ces standards encouragent l'utilisation de formats de données et de protocoles d'échange normés sur le Web, en s'appuyant sur le modèle Resource Description Framework (RDF).

Le Web sémantique est par certains qualifié de Web 3.0.
Selon le W3C, « le Web sémantique fournit un modèle qui permet aux données d'être partagées et réutilisées entre plusieurs applications, entreprises et groupes d'utilisateurs »[3]. L'expression a été inventée par Tim Berners-Lee[4] (inventeur du Web et directeur du W3C), qui supervise le développement des technologies communes du Web sémantique. Il le définit comme « une toile de données qui peuvent être traitées directement et indirectement par des machines pour aider leurs utilisateurs à créer de nouvelles connaissances ». Pour y parvenir, le Web sémantique met en œuvre le Web des données qui consiste à lier et structurer l'information sur Internet pour accéder simplement à la connaissance qu'elle contient déjà[3].
Alors que ses détracteurs ont mis en doute sa faisabilité, ses promoteurs font valoir que les applications réalisées par les chercheurs dans l'industrie, la biologie et les sciences humaines et sociales ont déjà prouvé la validité de ce nouveau concept[5]. L'article original de Tim Berners-Lee en 2001 dans le Scientific American a décrit une évolution attendue du Web existant vers un Web sémantique[6], mais cela n'a pas encore eu lieu. En 2006, Tim Berners-Lee et ses collègues ont déclaré : « Cette idée simple… reste largement inexploitée[7]. »
Histoire
Le concept du « modèle de réseau sémantique » a été inventé dans les années 1960 par le chercheur en sciences cognitives Allan M. Collins, le linguiste Ross Quillian (en) ainsi que la psychologue Elizabeth Loftus et exposé dans diverses publications[8] - [9] - [10] - [11] - [12] comme manière de représenter des connaissances structurées. Appliqué au contexte de l'internet, ce modèle étend le réseau de liens hypertextes des pages Web lisibles humainement en insérant des métadonnées lisibles par la machine sur les pages. Ces métadonnées sont liées les unes aux autres, permettant à des agents d'accéder au Web de manière plus intelligente et effectuer des tâches pour le compte d'utilisateurs. Le Web sémantique est considéré comme une passerelle pour accéder aux données entre différentes applications et systèmes. Ses applications sont nombreuses dans l'édition, les blogs, et dans plusieurs autres domaines.
Tim Berners-Lee à l'origine exprimait la vision du Web sémantique comme suit :
« I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web — the content, links, and transactions between people and computers. A “Semantic Web”, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The “intelligent agents” people have touted for ages will finally materialize. »
« Je rêve d'un Web [dans lequel les ordinateurs] deviennent capables d'analyser toutes les données du Web : le contenu, les liens, et les transactions entre personnes et ordinateurs. Un « Web Sémantique », qui devrait rendre cela possible, n'a pas encore émergé, mais quand il le fera, les mécanismes journaliers du commerce, de l'administration et de nos vies quotidiennes seront traités par des machines dialoguant avec d'autres machines. Les « agents intelligents » qu'on nous vante depuis longtemps se concrétiseraient enfin. »
La plupart des technologies proposées par le W3C existaient déjà avant. Celles-ci sont utilisées dans des contextes différents, en particulier celles relatives à l'information qui englobe un domaine limité et défini, et où le partage de données est une nécessité commune, tels que la recherche scientifique ou l'échange de données entre les entreprises. En outre, d'autres technologies ayant des objectifs similaires ont vu le jour, telles que les microformats.
Le but principal du Web sémantique est d'orienter l'évolution du Web pour permettre aux utilisateurs sans intermédiaires de trouver, partager et combiner l'information plus facilement. Les êtres humains sont capables d'utiliser le Web pour effectuer des tâches telles que trouver le mot Paris pour réserver un livre à la bibliothèque, trouver un plan et réserver son billet de transport. Cependant, les machines ne peuvent pas accomplir toutes ces tâches sans direction humaine, car les pages web sont conçues pour être lues avant tout par des personnes. Le Web sémantique vise à rendre les pages explorables tout aussi bien par l'homme que par la machine. Cela permettrait d'effectuer de façon automatisée les travaux fastidieux et répétitifs dans le domaine de la recherche d'information tout en améliorant et consolidant l'information sur le Web pour ses utilisateurs.
Le Web sémantique, comme il était prévu au départ, est un système qui permet aux machines de « comprendre » et de répondre aux demandes complexes de l'homme en fonction du sens de celles-ci. Une telle « compréhension » exige que les sources d'information pertinentes aient été sémantiquement structurées au préalable. Cette structure accessible pour les machines permet une capacité de découverte nettement supérieure à ce qui est possible simplement avec le Web des documents. L'utilisation du RDF pour structurer ces données permet de tirer profit de la performance des machines; leur aptitude au traitement des données permet d'étudier l'information dégagée de ces données afin de tirer de nouvelles conclusions de connaissances existantes. À l'aide du RDF, les documents produits en HTML deviennent des données qui, par un travail commun des machines et des utilisateurs, produisent de nouvelles connaissances[15].
Souvent, les expressions « sémantique », « métadonnée », « ontologies » et « Web sémantique » sont utilisées de manière incohérente. En particulier, elles sont employées tous les jours par les chercheurs et les praticiens dont la terminologie couvre un vaste paysage de technologies, de concepts et de domaines d'application. En outre, il y a une confusion entre les technologies envisagées pour le mettre en œuvre et le mouvement du Web sémantique. Dans un document présenté par Gerber, Barnard et Van der Merwe[16] le paysage du Web sémantique est tracé et un bref résumé des termes connexes et des technologies génériques sont présentés. Le modèle architectural proposé par Tim Berners-Lee est utilisé comme base pour représenter l'état des technologies actuelles et émergentes[17].
Les solutions apportées par le Web sémantique aux limites du HTML
Exemple
Dans l'exemple suivant, le texte « Paul Schuster est né à Dresde » d'une page web va être annoté en reliant la personne à son lieu de naissance. Le bout de code HTML affiché ci-dessous montre comment on décrit un mini-graphe en utilisant la syntaxe RDFa avec le vocabulaire de Schema.org et un identifiant Wikidata :

<div vocab="http://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> est né à
<span property="birthPlace" typeof="Place" rel="nofollow" href="https://www.wikidata.org/entity/Q1731">
<span property="name">Dresde</span>.
</span>
</div>Cet exemple définit les cinq triplets (en) suivants, affichés dans le format Turtle. Chaque triplet représente une arête du graphe généré : son premier élément (le sujet) est le nom du nœud d'où part l'arête, le deuxième élément (le prédicat) indique le type de l'arête, et le dernier (l'objet) est soit le nom du nœud cible soit une valeur littérale (texte, nombre, etc.).
_:a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Person> . _:a <http://schema.org/name> "Paul Schuster" . _:a <http://schema.org/birthPlace> <http://www.wikidata.org/entity/Q1731> . <http://www.wikidata.org/entity/Q1731> <http://schema.org/itemtype> <http://schema.org/Place> . <http://www.wikidata.org/entity/Q1731> <http://schema.org/name> "Dresde" .
Limites du HTML
Beaucoup de fichiers sur un ordinateur peuvent plus ou moins être classés en deux catégories : les documents lisibles par l'homme et les données lisibles par la machine. Des documents comme des courriers électroniques, rapports ou brochures sont lisibles pour les humains. Par contre, les données contenues dans des calendriers, carnets d'adresses, listes de lecture ou feuilles de calcul sont lisibles à condition d'utiliser une application qui permet de les lire, les fouiller et les transformer de différentes manières.
Actuellement, le World Wide Web est basé principalement sur des documents écrits en un langage de balisage hypertexte (HTML), c'est-à-dire une convention de balisage qui est utilisée pour coder un texte parsemé d'objets multimédias tels que des images et des formulaires interactifs. Les balises de métadonnées fournissent une méthode par laquelle les ordinateurs peuvent catégoriser le contenu des pages web ; par exemple :
<meta name="keywords" content="computing, computer studies, computer" />
<meta name="description" content="Cheap widgets for sale" />
<meta name="author" content="John Doe" />Avec le HTML et un outil pour l'afficher (pouvant être un navigateur web ou un autre « agent utilisateur »), on peut créer et présenter une page qui affiche des articles à vendre. Le HTML d'une page d'un catalogue peut se faire simplement, le document contenant des affirmations telles que « le titre de ce document est “Supermarché de Gadgets” », mais le code HTML est incapable d'affirmer sans ambiguïté que, par exemple, l'article numéro X586172 est une table avec un prix de 199 €, ni qu'il s'agit d'un produit de consommation. Le HTML peut seulement dire que la plage de texte « X586172 » est quelque chose qui doit être positionné à proximité de « Meuble » et de « 199 € », etc. Il n'y a pas moyen de dire que « ceci est une page de catalogue », ni encore de dire que « Meuble » est une sorte de titre, ni même de savoir que « 199 € » est un prix. Il n'y a aucun moyen d'exprimer que ces morceaux d'information sont liés entre eux pour décrire un élément discret, distinct des autres articles qui peuvent être listés sur une même page.
HTML sémantique fait référence à l'utilisation de balises HTML pour insérer des informations supplémentaires dans le document. Par exemple, l'utilisation de l'élément HTML del désignant un contenu supprimé plutôt que strike qui se contente d'afficher un texte barré et qui ne spécifie que sa mise en forme[18]. Le HTML sémantique laisse la mise en page au navigateur en y ajoutant des feuilles de style en cascade. Mais cette pratique atteint ses limites quand il s'agit de spécifier la sémantique des objets tels que des articles à vendre.
Les microformats sont des tentatives officieuses visant également à étendre la syntaxe HTML pour qu'une machine puisse lire le balisage sémantique à propos d'objets dans un document tels que des articles à vendre ou des contacts (exemple avec hcard).
Les solutions du Web sémantique
Le Web sémantique propose des langages spécialement conçus pour les données : RDF (Resource Description Framework), OWL (Ontology Web Language), et XML (eXtensible Markup Language). HTML décrit les documents et les liens entre eux. RDF, OWL, et XML, en revanche, peuvent décrire également des choses, comme des personnes, des réunions, ou des pièces d'avion. Selon Tim Berners-Lee, « RDF est aux données ce que HTML est aux documents. RDF permet de relier une donnée à une catégorie. »[19]
Ces technologies sont combinées afin de fournir des descriptions qui complètent ou remplacent le contenu des documents Web. Ainsi, le contenu peut se manifester sous forme de données descriptives stockées dans des bases de données accessibles sur le Web[20] ou à travers des balises dans les documents (via HTML ou sa variante XHTML — XML HTML —). Ces données peuvent être alors entrecoupées de XML, ou parfois publiées uniquement en XML, avec une mise en page et des données stockées séparément. Les descriptions lisibles par une machine permettent aux gestionnaires de contenu d'ajouter du sens à leurs contenus, c'est-à-dire de décrire la structure des connaissances au sein du contenu. De cette manière, une machine peut :
- traiter la connaissance elle-même, au lieu du texte, en utilisant des procédés similaires à un raisonnement déductif humain et de l'inférence,
- obtenir des résultats plus significatifs tout en aidant les ordinateurs à effectuer de la collecte d'informations automatisée et ainsi faciliter la recherche.
Voici un exemple de balise qui serait utilisé dans une page web non sémantique :
<item>cat</item>
Le codage d'informations similaires dans une page web sémantique pourrait ressembler à ceci :
<item rdf:about="http://dbpedia.org/resource/Cat">Cat</item>
Tim Berners-Lee pousse à l'émergence d'un réseau de données liées (linked data, en anglais), ou Web des données (en français), pour obtenir le Graphe Global Géant, contrairement au Web qui est une toile mondiale basée sur des pages HTML. Tim Berners-Lee pose comme principe que si, par le passé, on partageait des documents, alors, dans l'avenir, nous partagerons des données. Sa réponse à la question « comment ? » repose sur trois piliers. Un, une URL doit pointer vers les données. Deux, n'importe qui accédant à l'URL doit pouvoir récupérer des données. Trois, les relations dans les données doivent pointer vers d'autres URL avec des données[21].
Web 3.0
Tim Berners-Lee a décrit le web sémantique comme une composante du Web 3.0[22] :
« People keep asking what Web 3.0 is. I think maybe when you've got an overlay of scalable vector graphics — everything rippling and folding and looking misty — on Web 2.0 and access to a semantic Web integrated across a huge space of data, you'll have access to an unbelievable data resource. »
« Les gens demandent tout le temps ce qu'est le Web 3.0. Je suppose que lorsque vous aurez une superposition de dessins vectoriels — toute en vagues et en plis brumeux — décrivant le Web 2.0 et l'accès à un Web sémantique intégré dans un immense espace de données, vous aurez accès à une incroyable ressource de données. »
« Web sémantique » est parfois utilisé comme synonyme de « Web 3.0 », bien que la définition de chaque expression varie. Comme « Web 2.0 », « Web 3.0 » est un néologisme et un buzzword[23]. Dans le cas du Web 2.0, l'emploi du terme fait débat entre ceux qui pensent qu'il s'agit d'un terme marketing sans réel changement et ceux qui pensent qu'il y a eu une réelle évolution.
Les défis
Quelques-uns des défis du Web sémantique sont l'immensité, l'imprécision, l'incertitude, l'incohérence et la tromperie. Les systèmes de raisonnement automatisé devront faire face à toutes ces questions afin d'être à la hauteur de la promesse du Web sémantique.
Cette liste de défis est plus illustrative qu'exhaustive, car elle se concentre sur les défis de la couche de « logique d'unification » et de « preuve » pour la mise en œuvre du Web sémantique[24]. La plupart des techniques mentionnées ici devront étendre le langage OWL (Web Ontology Language) par exemple pour annoter la probabilité conditionnelle d'une information. Il s'agit d'un domaine de recherche actif[25].
Immensité
Le World Wide Web contient plusieurs milliards de pages[26]. L'ontologie de la terminologie médicale SNOMED CT (en) contient à elle seule 370 000 noms de classes, et aucune technologie existante n'a été encore en mesure d'éliminer tous les doublons du point de vue sémantique de cette ontologie. À l’avènement du Web sémantique, tous les systèmes de raisonnement automatisé devront alors gérer une quantité de paramètres vraiment énorme.
Imprécision
Il existe des notions imprécises comme « jeune » ou « grand ». Ceci découle de l'imprécision des requêtes des utilisateurs qui s'alignent sur les termes utilisés par les fournisseurs de contenu. Les fournisseurs ayant des bases de connaissances qui se chevauchent, recréent cependant différents concepts avec des différences subtiles. La logique floue est la technique la plus courante pour faire face à l'imprécision.
Incertitude
Ce sont des concepts précis avec des valeurs incertaines. Par exemple, un patient peut présenter un ensemble de symptômes qui correspondent à un certain nombre de diagnostics différents, chacun avec une probabilité différente. Les techniques de raisonnement probabiliste sont généralement employées pour traiter l'incertitude.
Incohérence
Ce sont des contradictions logiques qui surgiront inévitablement au cours du développement des grandes ontologies, et quand les ontologies à partir de sources distinctes seront combinées. Le raisonnement déductif échouera face à cette incohérence parce que d'une contradiction on peut déduire n'importe quoi (principe d'explosion). Le raisonnement révisable et le raisonnement paraconsistant sont deux techniques qui peuvent être utilisées pour faire face à l'incohérence.
Tromperie
Cela arrive quand le producteur d'une information désire volontairement tromper le consommateur de ce type d'information. Les techniques de cryptographie sont actuellement utilisées pour remédier à cette menace et ainsi veiller à l'intégrité des données.
Spécifications
La normalisation du Web sémantique est encadrée par le W3C[27].
Cadre de référence
L'expression « Web sémantique » est souvent utilisée plus spécifiquement pour désigner des formats et des technologies qui lui permettront d'exister[3]. La collecte, la structuration et la récupération des données reliées fonctionneront à l'aide des technologies qui fourniront une description formelle des concepts, termes et relations au sein d'un domaine de connaissances donné. Ces technologies sont standardisées par le W3C et comprennent notamment :
- Resource Description Framework (RDF)
- RDF Schema (RDFS)
- Simple Knowledge Organization System (SKOS)
- SPARQL
- Notation3 (N3)
- N-Triples
- Turtle
- Web Ontology Language (OWL)
- Rule Interchange Format (RIF)
La Semantic Web Stack est une illustration pour représenter l'architecture du Web sémantique. Les fonctions et les relations des composants peuvent être résumées comme suit[28] :
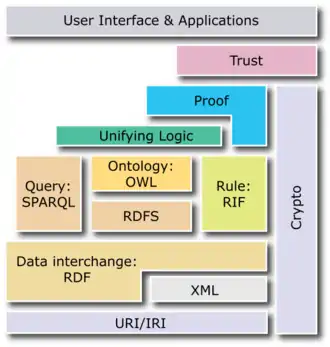
- Le XML fournit une syntaxe élémentaire, pour la structure du contenu dans les documents, mais il ne décrit pas la sémantique du document. XML n'est pas à l'heure actuelle une composante nécessaire des technologies du Web sémantique. Dans la plupart des cas, des syntaxes alternatives comme Turtle existent. Turtle est un standard de facto car moins verbeux que XML, mais n'a pas été choisi à travers un processus de normalisation formelle.
- Le XSD est un langage de description de format de document XML permettant de définir la structure et le type de contenu d'un document XML. Cette définition permet notamment de vérifier la validité de ce document.
- Le RDF est un langage simple pour exprimer des modèles de données sous forme d'objets (« ressources ») et de leurs relations. Un modèle basé sur RDF peut être représenté à travers plusieurs syntaxes d'échanges, par exemple, RDF/XML, N3, Turtle, et RDFa[29]. RDF est une norme fondamentale du Web sémantique[30] - [31] - [32].
- RDF Schema étend le RDF et son vocabulaire pour pouvoir structurer les propriétés et les classes au sein d'une ressource décrite en RDF.
- OWL ajoute plus de vocabulaire pour décrire les propriétés et les classes : comme avec les relations entre les classes, la cardinalité (par exemple « exactement un »), l'égalité, le typage des propriétés, les caractéristiques de propriétés (par exemple la symétrie), etc.
- SPARQL (prononcé sparkle ; en anglais : « étincelle »[33]) est un langage de requête et un protocole qui permettra de rechercher, d'ajouter, de modifier ou de supprimer des données RDF disponibles dans le Web à travers l'Internet.
État d'avancement
Les standards encore nécessaire pour mettre en œuvre le Web sémantique passent par le processus de recommandation des groupes de travail du W3C (World Wide Web Consortium). Cela signifie que chaque nouvelle recommandation a été soumise à une revue publique [34]. Ensuite, les recommandations du W3C qui seront largement adoptées, deviendront naturellement les standards du « Web sémantique ».
Voici la liste des standards et des principales recommandations sur laquelle repose le Web sémantique :
Voici les recommandations actives en cours[35] :
- RIF (Rule Interchange Format) est la couche de règles dans la Semantic Web Stack.
Par contre, de nombreuses étapes pour mettre en œuvre un « Web sémantique » sont encore à imaginer, clarifier et spécifier. Tim Berners-Lee, à travers sa Semantic Web Stack, résume ces étapes à travers les couches suivantes :
- Couche de logique d'unification
- Couche de preuve
- Couche de confiance / intégrité
- Couche de cryptographie
En attendant que toutes ces couches soient mises en œuvre, les technologies déjà disponibles, comme SPARQL, permettent déjà d'offrir une interopérabilité avec une meilleure granularité sur les données que celle qu'offrent les services Web (le W3C a d'ailleurs retiré la standardisation des services Web de ses priorités).
L'ensemble des sources de données qui partagent leurs données avec les standards du Web sémantique, a été nommé le Web des données (ou en anglais « Linked Open Data ») pour en faciliter l'adoption par le public. Le Web des données repose sur les technologies du Linked Data qui recouvrent les technologies du Web sémantique qui ont été déjà largement adoptées. Le Linked Data est l'une des principales technologies utilisées dans le mouvement « open data » en Angleterre qui vise à partager de manière massive les données publiques pour accélérer la recherche et le commerce. L’émergence du Web sémantique est considéré par certains comme la prochaine rupture technologique et donc économique qu'ils nomment déjà le Web 3.0[36] - [37].
Le but sera ainsi dans l'avenir d'améliorer l’accès et l'utilité du Web et des ressources interconnectées à travers lui comme :
- Les serveurs qui exposent des données en utilisant le RDF et SPARQL. Plusieurs convertisseurs RDF existent pour diverses applications. Par exemple, un serveur peut convertir les données contenues dans une base de données relationnelle sans affecter son fonctionnement et mettre ainsi à disposition des données en RDF et répondre à des requêtes SPARQL.
- Les documents « tagués » avec des informations sémantiques (une extension des balises
<meta>HTML utilisées dans les pages Web permet de fournir des informations aux moteurs de recherche Web à l'aide de robots d'indexation ). Le contenu contient ainsi une information lisible par une machine en rapport avec le document telle que le créateur, le titre, la description, etc. Ces informations peuvent également contenir des métadonnées représentant un ensemble de faits (tels que les autres ressources et services en relation avec le site). Notez que tout peut être identifié à travers un URI (Uniform Resource Identifier) et ainsi pourra être décrit, pour permettre au web sémantique de raisonner sur les animaux, les personnes, les lieux, les idées, etc. Ces balises ou tags sémantiques sont souvent générés automatiquement, plutôt que manuellement. - Le vocabulaire partagé des métadonnées (ontologies) est un référentiel entre ce vocabulaire qui permet aux créateurs de documents de savoir comment marquer leurs documents sémantiquement afin que les agents puissent utiliser les informations contenues dans les métadonnées fournies.
- Les agents automatisés qui effectuent les tâches des utilisateurs du web sémantique en utilisant ces données structurées et disponibles.
- Les services Web (souvent à leur propres agents) fourniront des informations précises aux agents, par exemple, un service de réputation qui a un agent peut se demander si certains magasins en ligne ont une bonne ou mauvaise réputation et la vérifier.
Observations sceptiques
Faisabilité pratique
Les principales critiques[38] portent sur la faisabilité complète ou même partielle du Web sémantique. Cory Doctorow parle de « metacrap » (un mot-valise constitué des mots metadata et crap, qu'on peut essayer de traduire en français courant par « métamerde »), une critique qui repose sur l'observation sarcastique du comportement humain[39]. Par exemple, les gens peuvent inclure des microdonnées parasites dans des pages Web pour tromper les moteurs du Web sémantique qui auront « naïvement » confiance en la véracité de toutes les données. Ce phénomène est bien connu pour tromper : les moteurs d'indexation, comme Google, cherchent à détecter ce type de manipulation. Peter Gärdenfors et Timo Honkela (en) avaient remarqué que la logique des technologies du Web sémantique ne couvre qu'une fraction des phénomènes qui impacteront la sémantique du Web[40] - [41].
En 2001, Cory Doctorow a fait une liste des sept obstacles[39] prétendument insurmontables pour obtenir des métadonnées assez fiables pour faire fonctionner un possible Web sémantique. Selon lui :
- Les gens mentent.
- Les gens sont paresseux.
- Les gens sont stupides.
- Il est difficile de se décrire soi-même.
- Les classifications ne sont pas neutres.
- L'unité de mesure retenue influence les résultats.
- Il y a plusieurs façons de décrire une même chose.
Il inclut également d'autres raisons liées à l'obsolescence des métadonnées :
- Les données peuvent devenir fausses au fil du temps.
- Les données ne peuvent pas intégrer de nouvelles idées.
Cory Doctorow en déduit que les recherches sur un tel système ne pourraient renvoyer que des données obsolètes et incorrectes en partie ou totalement.
L'architecture, les outils et les concepts mêmes du Web sémantique ont été souvent critiqués, citant que les technologies ou processus pour maintenir la qualité des données, insérées par des êtres humains et donc faillibles, ne peuvent pas encore fonctionner à l'échelle du Web[42]. Ces limites sont autant de nouveaux problèmes que la recherche tente actuellement de résoudre à travers les défis du Web sémantique. La science web (en) est la dénomination qu'on donne à la « discipline »[43] qui a pour objectif de résoudre les nouveaux problèmes scientifiques qu'a fait émerger le Web. Cependant, les technologies du web sémantique ont été adoptées au sein des communautés spécialisées dans la mise en œuvre de systèmes d'information, mais principalement dans des systèmes fermés (exemple : intranet)[44], comme dans des entreprises ou des bibliothèques.
La censure et la vie privée
L'enthousiasme pour le Web sémantique pourrait être tempéré par des considérations telles que le refus de la censure et la volonté de protéger la vie privée. Par exemple, on peut actuellement facilement leurrer les analyseurs de texte en utilisant d'autres mots, des métaphores, ou en utilisant des images à la place de mots. Il est beaucoup plus simple pour les gouvernements de visualiser, et donc de contrôler, la création de l'information en ligne si celle-ci utilise une structure sémantique, car l'information est alors beaucoup plus facile à interpréter et éventuellement à bloquer au moyen d'un système automatisé. En outre, la question a également été soulevée de l'utilisation de méta-données telles que FOAF ou encore d'API de géolocalisation (en), qui remettent en cause l'anonymat sur le World Wide Web. Ces préoccupations font de la sécurité des données personnelles un sujet de recherche actif, comme dans le projet « Policy Aware Web »[45].
Doubler les formats en sortie
Une autre critique parle d'une augmentation du temps de création et de publication du contenu dû au besoin d'en produire deux versions: une pour la visualisation par les êtres humains et une autre pour les machines. Cependant, beaucoup d'applications web font déjà face à ce problème en créant un format lisible pour un navigateur Web ou à la demande d'un lecteur RSS comme pour un blog. Le développement des microformats a été une réaction à ce genre de critique. À sa défense, le Web sémantique fera probablement diminuer l'effort lié aux tâches de recherche d'informations et compensera ainsi le coût supplémentaire qu'impose la mise à disposition d'un format compatible pour les machines.
L'une des premières solutions a été d'utiliser le langage GRDDL, un mécanisme qui utilise uniquement le contenu déjà présent dans une page HTML (avec des microformats potentiellement) pour en extraire du RDF. Cependant, la multiplicité et l'instabilité des microformats ainsi que la difficulté de créer le convertisseur XSLT pour GRDDL ont poussé à spécifier RDFa à intégrer simplement et explicitement du RDF au sein des pages HTML. La méthode RDFa sera d'ailleurs intégrée directement dans le standard HTML5 à travers les microdonnées, ce qui simplifiera encore l'insertion de données RDF dans un document.
Projets
Cette section énumère quelques-uns des nombreux projets et des outils qui existent au sein du mouvement Web sémantique.
Europe : ERCIM
L'avancement du Web sémantique dans le monde est suivi par le W3C dans le cadre du projet Semantic Web Advanced Deployment (SWAD). Le projet SWAD-Europe s'est déroulé de à .
L'organisme européen hôte des projets W3C et qui suit l'avancement du Web sémantique est ERCIM (European Research Consortium for Informatics and Mathematics).
Projet Data.bnf.fr de la Bibliothèque nationale de France
La Bibliothèque nationale de France s'introduit dans le Web sémantique à travers son projet data.bnf.fr[46]. Ce projet intègre des données produites dans des formats divers, notamment Intermarc, XML-EAD, et Dublin Core, pour la bibliothèque numérique. Les données sont modélisées et regroupées par des traitements automatiques et publiées dans divers standards RDF : RDF-XML, RDF-N3, et RDF-NT. Il existe aussi une publication de données en JSON. Le projet utilise la plateforme de développement sémantique CubicWeb.
La Bibliothèque nationale de France fournit ainsi :
- des URI pour les ressources grâce à des identifiants pérennes, attribués selon le mécanisme ARK qui permet d’accéder à toutes les ressources de la bibliothèque.
- pour chaque ressource, un ensemble de métadonnées associées à l’URI de la ressource sous forme de triplets RDF, selon les technologies du linked open data. Ces métadonnées sont récupérables sur chaque page (export) et pour toute la base (dump). Elles sont également requêtables par l'intermédiaire d'une console Sparql[46].
En 2013, le projet partage avec Gallica le Stanford Prize for Innovation in Research Libraries (SPIRL)[47].
Depuis 2017, le modèle de données de data.bnf.fr s'appuie sur le modèle conceptuel de référence IFLA LRM lui permettant de naviguer dans les relations entre entités[46].
DBpedia et SemanticPedia
DBpedia est le premier effort historique pour publier des données structurées extraites de Wikipédia : les données sont extraites des pages et notamment des boîtes d'information de Wikipédia publiées en RDF et mises à disposition sur le Web des données via HTTP et SPARQL sous la licence GFDL[48].
SemanticPedia est une plateforme de publication de données issues des différents projets Wikimedia en français portée par le Ministère de la Culture et de la Communication, Inria et Wikimédia France. Une version en français de DBpedia a été développée par l'équipe Wimmics sous la responsabilité de Fabien Gandon au centre de recherche d'Inria Sophia Antipolis. Ce chapitre francophone est appelé DBpedia.fr[49] et contribue pour le français à l’internationalisation de l’initiative DBpedia extrayant et publiant des données des différents chapitres linguistiques de Wikipédia. Ce chapitre francophone de DBpedia permet de soutenir de nombreuses applications[50]. La Ministre de la Culture de France, Aurélie Filippetti, a annoncé le que le chantier suivant concernerait le Wiktionnaire et ses deux millions de termes.
Wikidata
Wikidata est l'un des projets de la fondation Wikimédia. Il a pour objectif de mettre librement à disposition des contributeurs toutes les données structurées de tous les projets de la fondation sans intermédiaire.
Wikipédia est l'un des projets connectés à Wikidata. Chaque article de Wikipédia possède maintenant un identifiant unique sous forme d'IRI et constitue une entité dans la communauté Wikidata. Chaque entité est composée de plusieurs propriétés possédant une à plusieurs valeurs (des triplets). Ces entités et propriétés sont marquées d'un identifiant unique (par exemple : Q90 est l'identifiant unique de Paris), ce qui permet de rendre la base indépendante de la langue utilisée. La valeur de ces propriétés peut être une autre entité, mais aussi une chaîne, un nombre, une date, etc. Les données ainsi structurées sont réutilisables sous divers formats (XML, JSON, Turtle...) et peuvent servir à terme à alimenter les infoboxes de Wikipédia, évitant ainsi de modifier manuellement celles-ci dans toutes les langues puisqu'à chaque modification de Wikidata, toutes les infoboxes sont modifiées en même temps.
Les données de Wikidata sont sous licence CC0. Toutes les données partagées sont donc gratuites et libres pour tous types d'utilisation.
Pour le Web sémantique, Wikidata est l'un des rares endpoint SPARQL connecté en temps réel aux producteurs de données. Cela signifie que les modifications dans Wikidata impactent immédiatement la base de données RDF et permet ainsi de réutiliser ces données dans d'autres applications par l'entremise de SPARQL. Du côté de son ontologie, la structure est construite au fil de l'eau de manière consensuelle entre les contributeurs. La structure de cette ontologie peut donc changer à tout moment en fonction des besoins des contributeurs.
AKSW
AKSW (Agile Knowledge Engineering and Semantic Web) est un groupe de recherche qui est hébergé par la chaire de Betriebliche Informationssysteme (BIS) de l'Institut für Informatik (IFI) de l'université de Leipzig ainsi que par l'Institut pour l'Informatique Appliquée (InfAI)[51]. Le groupe de recherche AKSW a lancé un certain nombre de projets comme DBpedia.
Datalift
Datalift[52] est une plate-forme originale destinée à l'exploitation des données qui intègre dans une unique solution open source toutes les fonctions utiles à l'interconnexion des données, depuis leur capture jusqu'à leur publication finale. Dans Datalift, les données d'entrée sont des données brutes provenant de formats hétérogènes (bases de données, CSV, XML, RDF, RDFa, GML, Shapefile...). Les données produites sont des données liées. La plate-forme Datalift participe activement à la mutation du Web vers le Web des données.
FOAF
FOAF (Friend Of A Friend) est un vocabulaire qui utilise RDF pour décrire les relations que les gens ont avec d'autres personnes et les « choses » autour d'eux. FOAF est un exemple de tentative du Web sémantique de faire usage des relations au sein d'un contexte social.
Semantically-Interlinked Online Communities (SIOC)
Le SIOC est un vocabulaire permettant de décrire des objets couramment utilisés sur les sites communautaires et leurs relations.
Autres
Le Web des données offre le développement de nouveaux usages qui rendent concrète la notion d'intelligence collective comme :
- Le social bookmarking.
- Les wikis sémantiques, qui permettent de créer des contenus en précisant leur sens et en caractérisant leurs relations via une syntaxe de type wiki.
Notes et références
- Commission d’enrichissement de la langue française, « toile sémantique », sur FranceTerme, ministère de la Culture (consulté le ).
- (en) « XML and Semantic Web W3C Standards Timeline », (version du 26 octobre 2019 sur Internet Archive).
- (en) « W3C Semantic Web Activity », World Wide Web Consortium (W3C), (consulté le ).
- (en) Tim Berners-Lee, James Hendler et Ora Lassila, « The Semantic Web », Scientific American Magazine, (lire en ligne, consulté le ).
- (en) Lee Feigenbaum, « The Semantic Web in Action », Scientific American, (consulté le ).
- (en) Berners-Lee, Tim, « The Semantic Web », Scientific American, (consulté le ).
- (en) Nigel Shadbolt, Wendy Hall, Tim Berners-Lee, « The Semantic Web Revisited », IEEE Intelligent Systems, (consulté le ).
- (en) Allan M. Collins et M. R. Quillian, « Retrieval time from semantic memory », Journal of verbal learning and verbal behavior, vol. 8, no 2, , p. 240–247 (PMID 615603750, DOI 10.1016/S0022-5371(69)80069-1).
- (en) Allan M. Collins et M. Ross Quillian, « Does category size affect categorization time? », Journal of verbal learning and verbal behavior, vol. 9, no 4, , p. 432–438 (DOI 10.1016/S0022-5371(70)80084-6).
- (en) Allan M. Allan M. Collins et Elizabeth F. Loftus, « A spreading-activation theory of semantic processing », Psychological Review, vol. 82, no 6, , p. 407–428 (DOI 10.1037/0033-295X.82.6.407).
- (en) MR Quillian, « Word concepts — A theory and simulation of some basic semantic capabilities », Behavioral Science, vol. 12, no 5, , p. 410–430 (PMID 6059773, DOI 10.1002/bs.3830120511).
- (en) Semantic memory |book : Marvin Minsky (editor) : Semantic information processing, MIT Press, Cambridge, Massachusetts, .
- (en) Tim Berners-Lee, Fischetti, Mark, Weaving the Web, HarperSanFrancisco, (ISBN 978-0-06-251587-2), chapitre 12.
- (en) Tim Berners-Lee, Fischetti, Mark, Weaving the Web, HarperSanFrancisco, (ISBN 978-0-06-251587-2), chapitre 12.
- Yannick Maignien, « Les enjeux du web sémantique », dans Marcello Vitali-Rosati, Michael E. Sinatra, Pratiques de l'édition numérique, Montréal, Presses de l'Université de Montréal, , 224 p. (ISBN 9782760632035, lire en ligne), p. 77-94.
- (en) Gerber, AJ, Barnard, A, & Van der Merwe, Alta (2006) « A Semantic Web Status Model, Integrated Design & Process Technology » Special Issue : IDPT 2006.
- (en) Gerber, Aurona ; Van der Merwe, Alta ; Barnard, Andries (2008) « A Functional Semantic Web architecture » European Semantic Web Conference 2008 ESWC’08, Tenerife, juin 2008.
- (en) Alignment, font styles, and horizontal rules, HTML 4.01 Specification, 24 décembre 1999.
- Tim Berners-Lee, « Le web va changer de dimension », La Recherche, no 413, , p. 34.
- (en) Artem Chebotko et Shiyong Lu, « Querying the Semantic Web: An Efficient Approach Using Relational Databases », LAP Lambert Academic Publishing, (ISBN 978-3-8383-0264-5), 2009.
- « Blog de Tim Berners Lee ».
- (en) Victoria Shannon, « A 'more revolutionary' Web », International Herald Tribune, (consulté le ).
- mot à la mode, en particulier dans le domaine des technologies, plus ou moins vide de sens
- (en) « Uncertainty Reasoning for the World Wide Web », sur www.w3.org, Incubator Group for Uncertainty Reasoning for the World Wide Web (URW3‑XG), (consulté le ).
- (en) Thomas Lukasiewicz et Umberto Straccia, « Managing uncertainty and vagueness in description logics for the Semantic Web », Journal of Web Semantics, vol. 6, no 4, , p. 291-308 (lire en ligne).
- http://www.worldwidewebsize.com ].
- (en) Semantic Web Standards published by the W3C.
- (en) « OWL Web Ontology Language Overview », World Wide Web Consortium (W3C), (consulté le ).
- (en) « RDF tutorial », Dr Leslie Sikos (consulté le ).
- (en) « Resource Description Framework (RDF) », World Wide Web Consortium.
- (en) « Standard websites », Dr Leslie Sikos (consulté le ).
- (en) Allemang, D., Hendler, J., RDF —The basis of the Semantic Web ; in : Semantic Web for the Working Ontologist (2e éd.), Morgan Kaufmann, (DOI 10.1016/B978-0-12-385965-5.10003-2).
- (en) Jim Rapoza, « SPARQL Will Make the Web Shine », eWeek (en), (consulté le ).
- « The designation “W3C Recommendation” signifies that a document has been subjected to a public review and that it has been circulated amongst W3C member organizations for review. » (version du 5 août 2012 sur Internet Archive).
- « Le W3C publie les recommandations RDF et OWL », sur w3.org (consulté le )
- la rédaction JDN, « Qu'est-ce que le Web 3.0 ? », sur journal du net.fr, (consulté le )
- Jean-François Ruiz, « De l'ADN du Web 2.0 à la rupture du Web 3.0 en passant par le Web sémantique, même Dædalus se perdrait dans le Webyrinthe… », sur Webdeux.info, (consulté le )
- (en) Which Semantic Web?.
- (en) Cory Doctorow, « Metacrap: Putting the torch to seven straw-men of the meta-utopia », www.well.com, 2001 [last update] (consulté le ).
- (en) Peter Gärdenfors, « How to make the Semantic Web more semantic » (Formal Ontology in Information Systems: proceedings of the third international conference (FOIS-2004)), Frontiers in Artificial Intelligence and Applications, IOS Press, , p. 17–34.
- (en) Timo Honkela, Ville Könönen, Tiina Lindh-Knuutila and Mari-Sanna Paukkeri, « Simulating processes of concept formation and communication », Journal of Economic Methodology, .
- « « L'ontologie est surfaite », par Clay Shirky, traduction par Christophe Ducamp » (version du 28 juin 2008 sur Internet Archive).
- (en) James Hendler, Nigel Shadbolt, Wendy Hall, Tim Berners-Lee, et Daniel Weitzner. 2008. « Web science : an interdisciplinary approach to understanding the web » Communication ACM 51, 7 (juillet 2008), 60-69. DOI 10.1145/1364782.1364798.
- (en) Ivan Herman, « State of the Semantic Web », Semantic Days 2007, (consulté le ).
- www.policyawareweb.org.
- « Web sémantique et modèle de données », sur bnf.fr (consulté le ).
- (en) « 2013 Prizes », sur Stanford Libraries (consulté le ).
- Exemple du site DBpedia.fr.
- « DBpedia FR », sur fr.dbpedia.org (consulté le ).
- Camille Gévaudan, « Wikipédia va ménager les robots », Libération, (lire en ligne, consulté le ).
- AKSW (Agile Knowledge Engineering and Semantic Web).
- http://www.datalift.fr
Voir aussi
Articles connexes
Liens externes
- (en) Site officiel du Web sémantique, W3C.
- Collins A. M. & Quillian M. R, Retrieval time from semantic memory, 1969.
- « Web : et 1, et 2, et 3.0 », La Méthode scientifique, France Culture, 26 janvier 2022.
- Julien Plu, Introduction au Web sémantique, .
- Pourquoi et comment le monde est devenu numérique ? Un condensé de l'histoire de l'informatique, INRIA, 2010. Vidéo pédagogique d'environ 24 minutes à destination des lycéens. Présentation du Web sémantique par Rose Dieng-Kuntz ; début : 15 min.
- Ressource relative à la santé :
- Notices dans des dictionnaires ou encyclopédies généralistes :
Bibliographie
- Bachimont, Bruno. 2011. « Enjeux et technologies: des données au sens » . Documentaliste-Sciences de l’Information 48 (4): p. 24‑41.
- Fabien Gandon, Catherine Faron Zucker et Olivier Corby, Le Web sémantique : comment lier les données et les schémas sur le Web?, Dunod, (ISBN 978-2-10-057294-6 et 2-10-057294-6, OCLC 795501050)
- Yannick Maignien, « Les enjeux du web sémantique », dans Michael E. Sinatra, Marcello Vitali-Rosati (dir.), Pratiques de l’édition numérique (édition augmentée), Presses de l’Université de Montréal, Montréal, 2014, isbn : 978-2-7606-3592-0,