DBpedia
DBpedia est un projet universitaire et communautaire d'exploration et extraction automatiques de données dérivées de Wikipédia. Son principe est de proposer une version structurée et normalisée au format du web sémantique des contenus de Wikipedia. DBpedia vise aussi à interconnecter Wikipédia avec d'autres ensembles de données ouvertes provenant du Web des données. DBpedia a été conçu par ses auteurs comme l'un des « noyaux du Web émergent de l'open data »[1], connu également sous le nom de Web des données, et l'un de ses possibles points d'entrée. Ce projet est conduit par l'université de Leipzig, l'université libre de Berlin et l'entreprise OpenLink Software.
| Première version | |
|---|---|
| Dernière version | 2016-10 () |
| Dépôt | github.com/dbpedia |
| Assurance qualité | Intégration continue |
| Écrit en | Java et Scala |
| Langues | Multilingue |
| Type |
Base de connaissance Base de données en ligne (en) Database derived from Wikimedia projects (d) Graphe de connaissances |
| Licence | Creative Commons Attribution – Partage dans les Mêmes Conditions 3.0 non transposé (d), CC0 et licence publique générale GNU version 2 |
| Site web | dbpedia.org |
Historique
Le projet a été lancé par l'université libre de Berlin et l'université de Leipzig, en collaboration avec OpenLink Software. Le premier ensemble de données accessibles au public a été publié en 2007. Disponible sous licence libre, ces données peuvent être réutilisées.
Les articles de Wikipédia se composent principalement de texte, mais ils comprennent également des informations structurées intégrées aux articles, telles que des infobox (panneaux déroulants qui apparaissent en haut à droite de l'affichage par défaut de nombreux articles de Wikipédia ou au début de l'affichage mobile), des informations sur la catégorisation, des images, des coordonnées géographiques et des liens vers des pages Web externes. Ces informations structurées sont extraites et placées dans un ensemble de données uniforme qui peut être interrogé.
Structure du dépôt de données
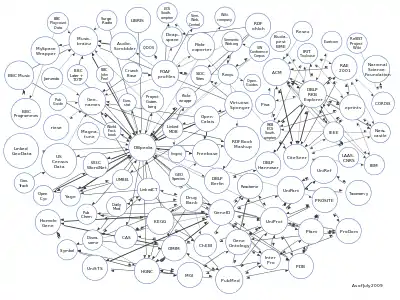
DBpedia adopte les normes du réseau linked open data et du Web sémantique. La ressource est donc livrée sous une forme de dépôt en format RDF regroupé au sein de documents dérivés de l'encyclopédie Wikipédia. Ainsi, pour chaque document encyclopédique, il existe une page de ressources contenant toutes les données sous forme de triplets RDF. Ces triplets peuvent représenter une information telle que, par exemple, la date de naissance d'une personne qui prendra la forme : personne, date de naissance et date.
Contenus
En novembre 2010, la base de données décrivait 3,4 millions d'entités[2], incluant au moins :
- 312 000 personnes
- 413 000 lieux
- 94 000 albums de musique
- 49 000 films
- 15 000 jeux vidéo
- 140 000 organisations (31 000 sociétés, 31 000 établissements d'enseignement)
- 146 000 espèces
- 4 600 maladies
- 1 461 000 liens vers des images
- 5,54 millions de liens vers des pages extérieures
- 4,87 millions de liens vers des datasets externes
- 565 000 catégories Wikipédia
- 75 000 catégories YAGO[2]
En avril 2016, elle est passée à 6,0 millions d'entités, incluant 5,2 millions correctement classées dans une ontologie et comprenant : 1,5 million de personnes, 810 000 lieux, 135 000 albums de musique, 106 000 films, 20 000 jeux vidéo, 275 000 organisations, 301 000 espèces et 5 000 maladies.
En juin 2021, elle contient plus d'un billion d'entités[3].
Insertion dans le linked open data
Dès son lancement, le projet DBpedia ambitionne de s'insérer dans la structure normalisée qui organise le web des données, le réseau linked open data. Pour atteindre cet objectif, les concepteurs de DBpedia complètent les extracteurs de données par un ensemble de correspondance entre les documents sources de Wikipédia, utilisés pour extraire les données, et un ensemble de ressources du réseau linked open data[4] en utilisant la balise standard sameAs du format RDF et du web sémantique. Il résulte de ce travail de mise en relation systématique, et régulièrement enrichi au fil des années, que DBpedia est interconnecté avec de très nombreux autres dépôts du web de données et que les objectifs initiaux de ses concepteurs ont été atteints. Les dépôts GeoNames, MusicBrainz, CIA World Factbook, le projet Gutenberg et Eurostat, entre autres[4], font partie de ces dépôts reliés par DBpedia.
Éditions linguistiques
La première version de DBpedia était extraite depuis la version anglophone de Wikipédia, les extracteurs d'informations n'étant conçus que pour être appliqués sur les infoboxes de cette version. Ce choix a pour conséquence que seules les entrées de la version anglophones bénéficiaient d'une représentation sous forme de données dans DBpedia : les entrées encyclopédiques qui ne se retrouvaient que localement tels que des hommes ou des femmes politiques uniquement présentés dans d'autres éditions germanophones ou francophones de Wikipédia ou des concepts spécifiques à une culture, par exemple, n'étaient pas reflétés sous forme de données RDF dans DBpedia.
Cette version originale de DBpedia, bénéficiant de la grande exhaustivité de la version anglophone de Wikipédia, a pu se contenter dans un premier temps de cette source d'extraction d'information restreinte, malgré sa non représentativité. Par nature, un dépôt RDF du web sémantique n'est pas contraint par une langue particulière puisqu'il organise des données uniquement d'après leur sens.
Néanmoins, la création de données d'après une encyclopédie anglophone a rapidement montré des limites de couverture. Il a donc été décidé de poursuivre le développement d'éditions linguistiques de DBpedia.
Version francophone
Une version entièrement francophone, agrémentée de fonctionnalités nouvelles, a été officiellement révélée en mars 2012[5]. Elle est développée par l'équipe de recherche Wimmics, dirigée par Fabien Gandon, chez Inria, avec le soutien du ministère de la Culture et l'expertise de l'association Wikimédia France.
Elle est disponible à la fois sur le site de DBpedia (l'équipe qui le développe étant également responsable du « chapitre » francophone de DBpedia.org[6]) et sur la plateforme SemanticPedia.org qui accueille différents projets de sémantisations de la galaxie Wikimédia, à commencer par DBpedia en français.
Cet effort de recherche a fait l'objet d'une convention signée le 19 novembre 2012 par le ministère de la culture et de la communication, l'Inria et Wikimédia France[7]. Il s'agit du premier partenariat entre ces trois institutions, de même qu'entre l'Inria et le ministère, et Wikimédia France et le ministère.
Disponibilité
Le contenu de la base est disponible sous double licence Creative Commons BY-SA 3.0 et GFDL depuis la version 3.4. Les bases de données qui constituent le dépôt peuvent être récupérées dans divers formats tels SQL ou CSV. Il est ainsi possible de créer un dépôt miroir ou encore d'intégrer les connaissances de DBpedia dans une application tierce, par exemple d'annotation sémantique.
Bien que le contenu soit seulement dérivé de Wikipédia par des méthodes heuristiques et constitué de données structurées, les promoteurs adoptent depuis le lancement les mêmes licences que Wikipédia[8] permettant d'améliorer l'interopérabilité entre Wikipédia et DBpedia.
L'accès aux dépôt de données se fait avec des requêtes sur la base de données via SPARQL. Les informations étant stockées avec Resource Description Framework (RDF), on peut aussi récupérer des documents ressource en relation avec un concept directement via une URI, avec les formats CSV ou RDF (notamment via les formats N-Triple, N3, JSON, XML).
Applications
La plupart des usages qui peuvent être faits des données du web sémantique sont valables avec DBpedia. Actuellement, les plus connues de ces applications sont celles réalisées avec des annotateurs sémantiques tels que DBpedia Spotlight ou Wikimeta. Ces applications permettent d'enrichir un document textuel avec des annotations sémantiques (c'est-à-dire qui représentent le sens exact d'un mot) utilisant les documents DBpedia en tant que point d'entrée.
Par exemple, la société de logiciel de crowdsourcing, Ushahidi, a construit un prototype de son programme du même nom utilisant DBpedia pour effectuer des annotations sémantiques sur des informations soumises par le public. Le prototype, appelé COMRADES[9], incorporait le service « YODIE », un système d'extraction d'informations ouvertes[10], développé par l'Université de Sheffield, qui utilise DBpedia pour effectuer les annotations. L'objectif pour Ushahidi était d'améliorer la vitesse et la facilité avec laquelle des informations entrantes pourraient être validées et gérées.
Exemples
DBpedia extrait des informations factuelles des pages Wikipédia permettant ainsi aux utilisateurs de trouver des réponses à des questions dont les informations sont réparties sur plusieurs articles Wikipédia. L'accès aux données se fait à l'aide d'un langage d'interrogation de type SQL pour RDF, appelé SPARQL.
Par exemple, imaginez que vous vous intéressiez à la série shōjo japonaise Tokyo Mew Mew et que vous recherchiez d'autres œuvres réalisées par son illustrateur Mia Ikumi.
DBpedia combine des informations provenant des entrées de Wikipédia sur Tokyo Mew Mew, Mia Ikumi et sur des œuvres telles que Super Doll Licca-chan et Koi Cupid.
Étant donné que DBpedia normalise l'information dans une seule base de données, la requête suivante peut être posée sans qu'il soit nécessaire de savoir exactement quelle entrée contient chaque fragment d'information :
PREFIX dbprop: <http://dbpedia.org/ontology/>
PREFIX db: <http://dbpedia.org/resource/>
SELECT ?who, ?WORK, ?genre WHERE {
db:Tokyo_Mew_Mew dbprop:author ?who .
?WORK dbprop:author ?who .
OPTIONAL { ?WORK dbprop:genre ?genre } .
}
Elle aura comme résultat la liste des genres d'oeuvres ressemblantes.
Utilisation
L'initiative OpenCalais (en) de Thomson Reuters, le projet Linked Open Data du New York Times, l'API Zemanta[11] et DBpedia Spotlight [12]incluent également des liens vers DBpedia.
La BBC utilise DBpedia pour organiser son contenu.
Faviki, outil de bookmarking social, utilisait DBpedia pour son balisage sémantique.
Samsung utilise également DBpedia dans sa "Plateforme de partage de connaissances[13]".
Une source aussi riche de connaissances structurées et inter-disciplinaires est un outil pour les systèmes d'intelligence artificielle. Par exemple, DBpedia a été utilisé comme l'une des sources de connaissances du système Watson d'IBM.
Amazon fournit un ensemble de données public DBpedia qui peut être intégré dans les applications Amazon Web Services.
Les données sur les créateurs, intégrées dans DBpedia, peuvent être utilisées pour enrichir les observations lors de vente d'œuvres d'art.
Techniques d'extraction
Le moteur d'extraction de données est un logiciel libre diffusé sous Licence publique générale GNU et écrit en Scala[14]. Son code source est distribué : il est hébergé sur SourceForge.net et disponible via Subversion.
Notes et références
- Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak et Zachary Ives, DBpedia: A Nucleus for a Web of Open Data; The Semantic Web Lecture Notes in Computer Science, 2007, Volume 4825/2007, 722-735, DOI: 10.1007/978-3-540-76298-0_52 (Résumé)
- wiki.dbpedia.org Source : Datasets
- (en-GB) Julia Holze, « Announcement: DBpedia Snapshot 2021-06 Release », sur DBpedia Association, (consulté le )
- Page du site de DBpedia contenant un ensemble d'informations sur les méthodes et les ressources d'inter-relations
- DBpedia fr
- (en) « Overview », sur DBpedia Association (consulté le ).
- « culturecommunication.gouv.fr/A… »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?).
- Références sur la licence
- ushahidi/platform-comrades, Ushahidi, (lire en ligne)
- « GATE.ac.uk - applications/yodie.html », sur gate.ac.uk (consulté le )
- « Zemanta API », sur dev.zemanta.com (consulté le )
- « DBpedia Spotlight - Shedding light on the web of documents », sur www.dbpedia-spotlight.org (consulté le )
- Samsung/KnowledgeSharingPlatform, Samsung, (lire en ligne)
- wiki.dbpedia.org : Documentation
Voir aussi
Articles connexes
Liens externes
- (en) Site officiel
- (en) « Accueil du projet DBpedia », sur SourceForge.net.
- (fr) Présentation du projet francophone