Gestion des incidents dans un centre de calcul
La gestion des incidents en centre de calcul est le processus utilisé pour répondre tout événement qui perturbe, ou pourrait perturber, un service informatique. Ces processus sont pour la plupart issus d'ITIL qui est un ensemble d'ouvrages recensant les bonnes pratiques (best practices) du management du système d'information. Ces processus de gestion des incidents ont également été adaptés par les grands acteurs du Cloud. Alors que les plans de continuité d’activité font partie des moyens pour limiter les interruptions de service, la prise en compte en amont des ressources nécessaires dans la construction des datacenters est un élément primordial pour leur bon fonctionnement. L’impact des incidents peut avoir des conséquences pour des millions d’utilisateurs à travers le monde.
Enjeux de la gestion des incidents en centre de calcul (Datacenter)
Les données étant l’une des principales valeurs liées à l’activité des entreprises; il est crucial de pouvoir y accéder à tout moment, et de veiller à leur conservation. Le Cloud fournit des ressources informatiques, logiciel applicatif ou matérielles accessibles à distance en tant que service[1]. Ces ressources sont hébergées dans des datacenters qui sont l’un des éléments nécessaires au traitement et stockage des données numériques. Concrètement, il s’agit d’un lieu physique contenant les serveurs informatiques qui stockent les données numériques, et dans lequel les entreprises peuvent notamment louer un espace de stockage et ainsi éviter la présence de serveurs dans leurs locaux[2]. La disponibilité de ces ressources se traduit par un contrat appelé Service Level Agrement (SLA) ou niveau de service. Il correspond au niveau de service garanti, c’est-à-dire aux engagements pris par le fournisseur[1]. La gestion des incidents a pour but de rétablir le service le plus rapidement possible et de réduire l’impact sur l'entreprise afin de répondre à l’accord sur les niveaux de services.
Les centres de calcul concentrent de plus en plus de puissance de calcul et de stockage et deviennent critiques pour les services (au sens ITIL[3] du terme); pour l'entreprise, ce sont des centaines de millions d’euros qui transitent chaque jour dans ces centres. À titre d’exemple, une panne de 5 minutes équivaut à une perte de 2,9 millions de dollars chez Apple, 1,4 million de dollars chez Amazon, ou encore, 21 500 dollars chez Twitter (source Ivision.fr).
Documents de références sur la gestion des incidents
Expectation for Computer Security Incident Response
En juin 1998 la publication de la RFC 2350[4] décrit pour la première fois de manière formelle l’organisation, la structure, les services et les modes opératoires d’une structure de réponse aux incidents[5].
National Institute of Standards and Technology
Le NIST[6] détaille un modèle d’organisation et de traitement lui aussi basé sur le cycle de vie d’un incident dans le guide intitulé Computer Security Incident Handling Guide initialement publié en 2004 et dont la dernière révision date de 2012[7]. Ce modèle, qui prend ses racines dans les travaux menés par l’US Navy puis par le SANS Institute[8], est semblable au modèle de l’ISO 27035:2011 au nombre de phases près, soit quatre phases sont identifiées au lieu de cinq, les deux phases post-incident de l’ISO étant regroupées en une seule :
- la phase ‘Préparer’ (Preparation) organisée autour de deux volets : préparer et éviter les incidents.
- la phase ‘Détecter et Analyser’ (Detection and Analysis) contenant sept volets : les vecteurs d’attaque, les signes d’un incident, les sources d’information, l’analyse de l’incident, la documentation de l’incident, la gestion des priorités et la notification de l’incident.
- la phase ‘Contenir, Eradiquer et Restaurer’ (Containment, Eradication and Recovery) présentée en quatre volets : choisir une stratégie d’isolation, relever et gérer les éléments de preuve, identifier les systèmes attaquant, éradiquer et restaurer.
- la phase ‘Gérer l’après-incident’ (Post-Incident Activity) scindée en trois volets : les leçons acquises, l’utilisation des données collectées et la conservation des éléments de preuve.
Il discerne l’existence d’un cycle entre les deux phases actives du traitement, les phases 2 et 3, lesquelles peuvent être déroulées alternativement pour affiner le traitement et ceci au fur et à mesure de la progression dans l’analyse et de la connaissance que l’on acquiert de l’incident, de ses atteintes et de ses conséquences[5].
European Union Agency for Cybersecurity
Publié fin 2010 par l'ENISA[9] et en anglais uniquement, le guide Good Practice Guide for Incident Management[10] traite de l’ensemble de la problématique de la mise en œuvre d’une structure de gestion des incidents. Il propose à ce titre, une organisation de la gestion des incidents autour des différents services susceptibles d’être offerts et dont le traitement d’un incident n’est qu’une composante. L’ENISA[9] s’inspire ici du modèle fondateur initié en 2004 par le CERT Carnegie Mellon[11] dans son document Defining Incident Management Processes for CSIRTs: A Work in Progress[12] :
- la détection.
- le triage.
- l’analyse.
- la réponse.
ISO 27035
En 2016, la norme ISO/IEC 27035-1:2016 Information Security Incident Management[13] présente un modèle d’organisation de l’activité de réponse aux incidents s’appuyant sur le cycle de vie d’un incident. Celui-ci se décompose en cinq phases :
- phase de planification et de préparation (Plan and prepare).
- phase de détection et de rapport (Detection and reporting).
- phase d’analyse et de décision (Assessment and decision).
- phase de réponses (Responses).
- phase de retour d’expérience (Lessons learnt).
ITIL
Publié en 2019, la version 4 de l'ITIL est un ensemble de livres présentant de nombreuses pratiques, procédures et méthodes utilisées dans la gestion des systèmes d’information. Le concept central est l’apport de valeur aux clients. La publication des premiers éléments par la CCTA[14] date de la fin des années 1980. Depuis plusieurs versions ont été éditées : ITIL V2 (2001), ITIL V3 (2007 puis 2011), ITIL V4 (2019)[15]. Dans sa version la plus déployée (V3), la gestion des services ITIL supporte ces transformations à travers l’utilisation du cycle de vie des services qui comprend cinq étapes :
- Stratégie des services.
- Conception des services.
- Transition des services.
- Exploitation des services.
- Amélioration continue des services.
La gestion des incidents se situe au niveau de l’exploitation des services qui comprend également la gestion des événements, l'exécution des requêtes, la gestion des problèmes, la gestion des accès.
ITIL, un modèle pour la gestion des incidents
Définition, évolution et convergence
Définition de l’ITIL
L’ITIL est un ensemble d’ouvrages recensant les bonnes pratiques de management des systèmes d’information. Ce référentiel, né dans les années 1980, a su s’imposer au sein des DSI comme la référence concernant la gestion des services informatiques ITSM[16], ou IT Service Management) en permettant, grâce à une approche par processus clairement définie et contrôlée, d’améliorer la qualité des SI et des Services d'assistance aux utilisateurs.
Les quatre fondements de l’ITIL sont basés sur des processus détaillés et une documentation très lourde (plusieurs centaines de pages) :
- ITIL décrit avec détails les processus permettant une qualité de service robuste.
- La documentation est très fournie. Les ouvrages ITIL sont composés de plusieurs centaines de pages.
- Passer des accords contractuels et respecter les accords de services (SLA, pour Service Level Management) est un des fondements d’ITIL.
- Certains processus peuvent se montrer inflexibles vis-à-vis du plan initialement prévu, comme le processus de gestion des changements nécessitant encore très souvent un passage en CAB (Change Advisory Board, comité de validation des changements).
ITIL est structuré autour du cycle de vie d’un service, répartit en 5 étapes :
- La stratégie du service dont l’objectif est de comprendre les clients IT, définir l’offre répondant aux besoins des clients, les capacités et ressources nécessaires au développement de service et identifier les moyens de succès pour une exécution réussie.
- La conception du service assure que les nouveaux services et ceux modifiés soient conçus efficacement, en termes de technologie et d’architecture, afin de satisfaire les attentes du client. Les processus sont aussi pris en considération dans cette phase.
- La transition du service intègre la gestion du changement, le contrôle des actifs et de la configuration, la validation, les tests et la planification de la mise en fonction du service afin de préparer la mise en production.
- L’exploitation du service fournit le service de manière continue et le surveille quotidiennement.
- L’amélioration continue du service permet au service Technologies de l'information et de la communication de mesurer et d’améliorer le service, la technologie ainsi que l’efficacité et l’efficience dans la gestion générale des services.
Le site ITIL France[17], devenu LaBoutique ITSM[16] depuis la sortie en français de la version 4 du référentiel ITIL, propose, outre, les archives de la version 3 (2007 puis 2011), ainsi qu’une présentation de l’ITIL4.
L'ITIL se compose de cinq volumes qui décrivent l'intégralité du cycle de vie ITSM[16] conformément à la définition d'AXELOS[18]:
- volume "Stratégie des services" décrit comment concevoir, développer et implémenter la gestion des services en tant qu'actif stratégique.
- volume "Conception des services" décrit comment concevoir et développer des services et des processus de gestion des services.
- volume "Transformation des services" décrit le développement et l'amélioration des capacités pour transformer les services nouveaux et modifiés en opérations.
- volume "Fonctionnement des services" décrit les pratiques de gestion du fonctionnement des services.
- volume "Amélioration continue des services" dirige la création et la préservation des valeurs pour les clients.
En décembre 2017, dans son article "ITIL : renaissance ou dernier soupir ?"[19], M. Alain Bonneaud écrivait sur le blog de la transformation digitale, que l’ITIL commençait à prendre de l’âge.
AXELOS, propriétaire du référentiel, se défendait en indiquant que l’ITIL est "l’approche la plus largement utilisée pour la gestion des Technologies de l'information et de la communication dans le monde". La société indiquait non seulement qu’il existait des millions de praticiens d’ITIL dans le monde, mais aussi que le référentiel était utilisé par la majorité des grandes organisations pour gérer leurs opérations informatiques.
Méthode Agile et ITIL 4 : l’avènement de l’IT Service Management Agile
L’agilité a su au fil du temps convaincre les DSI et imposer ses principes et ses méthodes afin de transformer en profondeur les façons de travailler. Les entreprises ont ainsi pu délivrer de façon plus rapide leurs projets tout en évitant l’effet tunnel que confèrent les méthodes plus traditionnelles et en restant focalisé au maximum sur les besoins et attentes des clients. L’enjeu est de savoir “comment s’agiliser en respectant les bonnes pratiques d’ITIL ?”[20]
De façon historique, ITIL et les méthodes agiles ne sont rien d’autre que des bonnes pratiques appliquées respectivement à la production Technologies de l'information et de la communication et au développement IT. En effet, ITIL donne un cadre de référence au travers des processus définis et fortement documentés, mais n’impose pas une manière particulière d’exécuter les tâches. L’agilité est, elle, avant tout un ensemble de pratiques et de méthodes de travail dont les principes aident à la réactivité et à la flexibilité.
Et dans une organisation s’inspirant d’ITIL, les bonnes pratiques agiles arrivent à coexister et à s’adapter aux nouveaux modèles opérationnels.
ITIL 4 : La dernière version d’ITIL qui s’adapte aux enjeux de l’agilité, du Lean et du DevOps
Axelos, l’organisme propriétaire d’ITIL, a publié en 2019 la nouvelle version du référentiel ITIL, nommée ITIL 4 Edition. Cette nouvelle édition a redessiné les principes déjà bien établis de l’ITSM[16] en prenant compte les nouveaux enjeux technologiques et les nouveaux modes de fonctionnements, tels que l’agilité, le Lean[21] ou encore DevOps[22] - [23]. Cette nouvelle version encourage les organisations à casser les silos, à favoriser la collaboration et la communication au sein-même des organisations, et à s’adapter aux nouvelles tendances IT. ITIL incite également ses pratiquants à conserver des pratiques simples et pragmatiques, ce qui peut se traduire par une reconnaissance du fait que trop d’organisations ont tenté par le passé de mettre en œuvre ITIL au pied de la lettre, rendant l’ITSM[16] complexe et peu flexible.
Outre l’émergence de nouveaux concepts ou l’adaptation de notions déjà existantes, la documentation a complètement été revisitée afin de la rendre plus synthétique et aisée à la lecture. Elle est notamment accompagnée de nombreux exemples pratiques. L’ouvrage ITIL Foundation illustre même en fil rouge les péripéties d’une entreprise fictive vis-à-vis de ses pratiques ITIL.
Le Service Value System (SVS) : un système de cocréation de valeur adapté aux concepts de l’agilité, du DevOps et du Lean
L’élément cœur d’ITIL 4 est le concept de Service Value System (SVS). Celui-ci décrit comment les composants et les activités d’une organisation s’articulent dans le but de créer de la valeur. Ce système s’interface avec les autres organisations, formant tout un écosystème pouvant également délivrer de la valeur à ces organisations et aux parties prenantes.
Pour supporter les activités de la Service Value Chain, des capacités appelées practices ont été définies comme des collections de ressources de différentes natures (appelées les 4 dimensions du service management), affectées par de multiples facteurs externes (politiques, technologiques, environnementaux etc.) :
- Organisations et personnes.
- Information & technologie.
- Partenaires & fournisseurs.
- Flux de valeurs & processus.
ITIL 4 propose un modèle d’amélioration continue pouvant s’appliquer à l’ensemble des éléments du Service Value System (practices, SVC…). Ce modèle se veut représenter un guide à haut niveau pour accompagner les initiatives d’amélioration, en mettant un gros point d’attention sur la valeur client, et en assurant la cohérence avec la vision de l’organisation. Le modèle, s’inscrivant dans les principes de l’agilité, introduit une approche itérative et divise les tâches en objectifs pouvant être atteints de façon incrémentale.
Les principes directeurs ITIL 4
Pour guider toutes ces activités, ITIL 4 pose des principes directeurs (guiding principles), définis comme des recommandations qui guident une organisation en toute circonstance, indépendamment de ses objectifs, de sa stratégie ou de sa structure. Les principes directeurs d’ITIL 4 sont :
- Se concentrer sur la valeur, englobant notamment la prise en compte de l’expérience client et utilisateur.
- Commencer à partir de l’existant, sans forcément faire table rase de l’existant.
- Avancer de façon itérative, avec des feedbacks à chaque fin de cycle.
- Promouvoir la collaboration et la visibilité du travail accompli.
- Penser de façon holistique, afin de pouvoir coordonner les activités globalement.
- Délivrer des choses simples et pratiques.
- Optimiser et automatiser, et concentrer les interventions des ressources humaines là où elles délivrent réellement de la valeur.
Ces principes directeurs peuvent s’appliquer à tous les éléments du système, incluant la gouvernance du Service Value System.
L’ITSM Agile, ou la combinaison du meilleur des deux mondes
Appliquer la philosophie et les modes de fonctionnement ITSM[16] agiles au sein des productions informatiques est compatible avec les pratiques éprouvées de l’IT Service Management. Les deux pratiques ont su montrer au fil du temps les gains qu’ils pouvaient apporter aux organisations, et leur synergie permet d’optimiser l’efficacité au sein des DSI. ITIL 4 vient asseoir cette proximité en offrant un cadre adapté aux récentes tendances que sont l’agilité, le Lean[21] IT, DevOps ou encore le Cloud computing. Il convient ainsi de s’appuyer sur la philosophie initiale d’ITIL : s’inspirer des bonnes pratiques et les appliquer afin qu’elles conviennent le mieux aux organisations.
ITIL et Facilities Management
Il y a deux mondes qui se côtoient dans les centres de données : les équipes de la DSI et celles du Facilities Management[24]. Leur périmètre technique est assez bien délimité, leurs objectifs aussi… Ces deux équipes auraient tout intérêt à se parler, se comprendre, agir en cohérence pour garantir l’orientation client.
ITIL est connu depuis 30 ans, et l’effort a été marqué dans les années 2007/2009 du côté des DSI. Plus que jamais, ITIL devrait être au centre des préoccupations des managers et des directions de ces centres avant que le déploiement des solutions matérielles et logiciel applicatif de FM des centres de données.
Avec les résultats bien connus d’ITIL (les priorités et les criticités des événements et incidents identifiés, des incidents évités ou minimisés, les activités organisées et planifiées, les informations remontées complètes et économes…), de notables bénéfices sont habituellement réalisés (un centre de coût qui peut évoluer en centre de profit ; un profit et un CA qui croient aussi vite (ou plus) que le marché moyen, chaque € est investi à bon escient, en termes de technologies, de personnels, de partenariats, un personnel impliqué et motivé, des clients rassurés et fidèles…).
Une approche pragmatique, adaptée, partielle et progressive d’ITIL au sein des départements chargés du Facilities Management des centres de données, peut rester simple, rapide et pas chère.
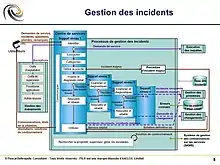
Gestion des incidents - Processus
Pour une meilleure appropriation du processus, il est intéressant de consulter la section "Gestion des incidents" du glossaire ITIL[25].
La Gestion des incidents[26] est un processus ITIL qui fait partie de la phase "Exploitation des services". Selon le référentiel ITIL, l'objectif du processus de Gestion des incidents est de rétablir le service le plus rapidement possible, en ayant un minimum d’impacts sur les opérations courantes.
« LaBoutique ITSM »[17] détaille très précisément La Gestion des incidents sous les items suivants : But ; Objectifs ; Activités ; Echelles de temps et modèle d'incident ; Priorité d’un incident ; Exemple de grille de calcul ; Types d'escalade ; Schéma du processus avec les différents niveaux de support ; Interfaces entre gestion des incidents et gestion des problèmes ; Apport de valeur pour l'entreprise et pour le fournisseur de services ; Perte de valeur avec l’absence d’un processus performant ; Défis classiques
Objectifs
Les objectifs du processus de Gestion des incidents sont :
- Veiller à ce que des méthodes et des procédures normalisées soient utilisées pour répondre, analyser, documenter, gérer et suivre efficacement les incidents.
- Augmenter la visibilité et la communication des incidents à l'entreprise et aux groupes de soutien IT.
- Améliorer la perception des utilisateurs par rapport à l'IT via une approche professionnelle dans la communication et la résolution rapide des incidents lorsqu'ils se produisent.
- Harmoniser les activités et les priorités de gestion des incidents avec ceux de l'entreprise.
- Maintenir la satisfaction de l'utilisateur avec la qualité des services IT.
Champ d'application
La Gestion des incidents inclut tout événement qui perturbe, ou pourrait perturber, un service. Ceci inclut les événements communiqués directement par les utilisateurs, via le Centre de services[27], une interface web ou autrement.
Même si les incidents et les demandes de service sont rapportés au Centre de services, cela ne veut pas dire qu'ils sont de même type. Les demandes de service ne représentent pas une perturbation de service comme le sont les incidents. Voir le processus Exécution des requêtes pour plus d'information sur le processus qui gère le cycle de vie des demandes de service.
Valeur
La valeur qu'apporte la Gestion des incidents est en lien direct avec la réduction des travaux non planifiés et des coûts causés par les incidents, autant pour l'entreprise que les ressources IT, la détection et la résolution efficace des incidents, améliore la disponibilité des services. cela contribue à l'alignement des activités Technologies de l'information et de la communication avec les priorités de l'entreprise ; la gestion des incidents inclut la capacité d'identifier les priorités d'affaires et d'allouer les ressources nécessaires, mais aussi à l'identification des améliorations potentielles des services ; on y arrive en comprenant mieux de quoi est constitué un incident et aussi en connaissant mieux les activités du personnel de l'organisation. Le Centre de service peut également, pendant le traitement des incidents, identifier des besoins additionnels en service ou en formation.
La Gestion des incidents est hautement visible à l'entreprise ; il est par conséquent plus facile de démontrer sa valeur en comparaison aux autres processus présents dans la phase d'Exploitation des services. C'est la raison pour laquelle il est souvent le premier processus à être implanté.
Délais
Des délais doivent être convenus pour les incidents selon leur priorité ; ceci inclut des cibles de réponse et de résolution. Tous les groupes d'intervention doivent être avisés de ces cibles et des délais. L'outil devrait être en mesure d'automatiser les délais et d'escalader les incidents basés sur des règles prédéfinies.
Modèles d'incident
Un modèle d'incident est un gabarit qui peut être réutilisé pour des incidents récurrents. Il peut être pratique de prédéfinir des modèles d'incidents standard et de les appliquer lorsqu'ils surviennent, pour une saisie et un traitement plus rapides.
Incidents majeurs
Une procédures séparée, avec des délais plus rapides et une urgence plus élevée, doit être utilisée pour les incidents majeurs. Une définition de ce qui constitue un incident majeur doit être convenue et incluse dans la structure de priorisation des incidents. Lorsque nécessaire, une équipe spéciale peut être invoquée par le gestionnaire des incidents afin de s'assurer que les ressources adéquates et le focus soient fournis pour trouver une solution rapide.
Suivi du statut des incidents
Au cours du cycle de vie des incidents, cinq statuts différents interviennent.
- Nouveau : un incident est soumis, mais n'a pas été assigné à un groupe ou une ressource pour résolution.
- Assigné : un incident est assigné à un groupe ou une ressource pour résolution.
- En traitement : l'incident est en cours d'investigation pour résolution.
- Résolu : une résolution a été mise en place.
- Fermé : la résolution a été confirmée par l'utilisateur comme quoi le service normal est rétabli.
En résumé, ITIL est largement utilisé pour la gestion des Technologies de l'information et de la communication. Mais l’évolution rapide des technologies basées sur le Cloud, les nouvelles approches telles que DevOps et l’enracinement des méthodologies agiles ont remis en question bon nombre de méthodes, apparemment rigides et bureaucratiques, souvent associées à ITIL[28]. D’autres méthodes ont vu le jour comme VeriSM[29] ou existent depuis des années comme TOGAF[30]
Sur la partie gestion d’incident la version 4 d’ITIL adapte le processus aux nouveaux modèles opérationnels agiles dans lesquels les pratiques et processus ont été modifiés. La collaboration et les échanges sont fluidifiés, et les équipes disposent de plus d’autonomie sur leurs périmètres. Par exemple, lors d’un incident majeur, différentes parties prenantes sont mobilisées au sein d’une task force et collaborent ensemble, jusqu’à ce que l’entité la plus à même de résoudre l’incident soit identifiée. Pendant que les autres peuvent retourner à leurs tâches habituelles, celle-ci est autonome et dispose de tous les moyens nécessaires pour résoudre l’incident majeur. Elle possède également toute la légitimité de mobiliser différents acteurs de l’organisation au besoin[31].
Plan de Continuité d’Activité - Plan de Reprise d’Activité
Le Plan de Continuité d’Activité (PCA) et le Plan de reprise d'activité (PRA) ont pour objectif de poursuivre ou de reprendre les activités informatiques avec un temps d’interruption minimum des services. Les contraintes propres à chaque entreprise sont généralement mesurées avec l’aide de deux indicateurs : le RTO (Recovery Time Objective) qui traduit le temps maximal admissible avant reprise[32], et le RPO (Recovery Point Objective) qui spécifie la fraîcheur minimale des systèmes restaurés. Une étude réalisée par le cabinet d’analyse Forrester et le Disaster Recovery Journal en 2017, donne un éclairage intéressant sur le niveau de préparation des entreprises face à une reprise sur sinistre un exemple avec l'incident Bull Chorus le 27/06/13[33]. Seulement 18 % des entreprises interrogées s’estiment parfaitement préparées au déclenchement des processus de reprise, plus de 45 % des organisations indiquent qu’elles ne disposent pas d’une coordination centrale des processus de reprise, seulement 19 % des entreprises sont en mesure de tester leurs processus de reprise plus d’une fois par an, et près de 21 % ne les testent jamais. Lors d’un sinistre, c’est bien le temps de réaction de l’organisation, le fameux RTO qui va déterminer le niveau de l’impact sur les activités métier. Temps de détection des problèmes, temps de prise de décision, temps d’exécution des procédures de reprise, temps de contrôle des systèmes après reprise... la durée cumulée de toutes ces opérations doit être inférieure au RTO qui a été défini dans le cadre du PRA.
Étapes essentielles à la conception d’un plan de reprise d’activité
1. Réaliser un audit de tous les risques de pannes possibles sur le système d’information et en identifier les causes probables : panne matérielle, panne logicielle, cyberattaque, coupures électriques, incendie, catastrophe naturelle, erreur humaine, etc.
2. Détecter et évaluer chaque risque afin d'identifier les applications métiers qui ne pourront pas fonctionner en mode dégradé. Il est donc nécessaire de bien appréhender et mesurer la tolérance aux pannes de l’ensemble du système d’information.
3. Définir la criticité des environnements applicatifs et les besoins de sauvegarde et réplication ainsi que de restauration qui devront s’appliquer. Devront être définis ici le RTO (Recovery Time Objective) et le RPO (Recovery Point Ojective).
4. Prévoir des sauvegardes automatiques à une fréquence correspondant au besoin de l’organisation.
5. Faire du « Crisis Management » (Attribution de rôles et de tâches à des personnes identifiées, qui auront la responsabilité d’intervenir le moment venu. Il s'agit donc d'organiser et de mobiliser ses équipes dans le but d'agir efficacement au moment du sinistre.)
6. Définir des priorités et un coût de reprise d’activité : Évaluation des seuils d’indisponibilité des services, pour ensuite les prioriser afin de définir le coût de remise en service de l’infrastructure. Dans certains cas, la reprise d’activité devra pouvoir s’effectuer en moins d’une minute. La mise en place nécessaire d’environnements synchrones peut alors rapidement élever les coûts.
7. Définir le choix de l’équipement de sauvegarde et de reprise d’activité ainsi que le budget qui y sera consacré. Dans certains cas, le doublement simple du matériel existant sur un site distant, peut être insuffisant. C'est pourquoi, le choix du matériel est important s'il doit supporter la charge d’une remise en service.
8. Tester régulièrement le Plan de reprise d'activité : bien que le coût d’un test de Plan de reprise d'activité informatique soit conséquent, il est impératif d’évaluer régulièrement sa fiabilité au moins deux fois par an.
9. Faire évoluer le Plan de reprise d'activité en fonction des changements apportés à un système d’information en constante évolution.
10. Documenter précisément le PRA, par le retour d’expériences des acteurs garants de la fiabilité du Plan de reprise d'activité. Le partage de la connaissance du SI va directement affecter les performances d’un Plan de reprise d'activité informatique. Ainsi, les phases de tests ou les remontées d’échecs doivent être systématiquement documentées, ce qui est généralement peu souvent le cas.
11. Prendre en compte les contraintes réglementaires auxquels certaines typologies d’organisations doivent se conformer dans l’exécution de leurs activités.
Le portail du Ministère de l’économie et des finances met à disposition une ressource documentée, intitulée "Informations sur la méthodologie d’un PCA[34]". Chaque entreprise avance différemment dans sa stratégie de sauvegarde et de protection de ses données numériques. Certaines disposent déjà d’un Plan de reprise d'activité associé à un PCA, d’autres ont initié des démarches préliminaires auprès de prestataires spécialisés ou évaluent simplement la pertinence d’un Plan de reprise d'activité / PCA pour leur organisation[35]. Parmi ces stades d’avancement autour d’un projet de Plan de reprise d'activité informatique, certaines interrogations doivent être levées en amont : quel périmètre peut couvrir un prestataire dans la réalisation d’un Plan de reprise d'activité informatique ? Quels sont les éléments qui doivent être pris en charge par le prestataire et consignés dans le contrat de Plan de reprise d'activité ? En cas de panne, quelles sont les garanties de retrouver ses services, ses données et sous quels délais ? Quelle sera la capacité du prestataire à détecter d’éventuels risques futurs et quelle sa réactivité pour en alerter l’entreprise ? Que l’on parle d’un Plan de reprise d'activité sur site ou dans un datacenters, la transparence des informations et la nature des communications entre le prestataire et l’entreprise sont essentielles à la tenue d’un Plan de reprise d'activité qui soit performant. La qualité du Plan de reprise d'activité repose également sur la capacité d’une équipe technique à remettre en cause régulièrement la fiabilité de son infrastructure et ce, pendant toute la durée du contrat.
Les 3 défis du Rétablissement de l’Activité
1. Les hommes
Le propre d’un sinistre est qu’il se produit toujours au moment où on ne l’attend pas. Il convient donc rester prudent et réaliste, quant à ses capacités de réunir les bonnes compétences, au bon endroit, au bon moment. Des expériences comme une catastrophe naturelle, une épidémie de grippe, ont montré que les systèmes d’astreinte les plus élaborés peuvent être défaillants. Lors d’incendies ou d’inondations majeures notamment, une partie significative des équipes impliquées dans l’exécution du Plan de reprise d'activité peuvent en effet être concernées par des évacuations obligatoires. Ces défections imprévisibles par nature peuvent ralentir les processus de reprise, faute d’avoir sous la main le spécialiste indispensable à une opération ou tout simplement le détenteur d’un mot de passe.
2. Les changements
Le meilleur ennemi du PRA reste certainement les changements qui sont apportés aux infrastructures et applications postérieurement à l’établissement du PRA. Ainsi, des inconsistances critiques peuvent apparaître dans les procédures de reprise, et mettre en échec le redémarrage des activités, si le plan n'est pas régulièrement mis à jour. Il est donc indispensable de centraliser ces changements dans le but de mettre à jour les procédures du PRA. C’est une problématique qui dépasse souvent les limites d’une gouvernance classique basée sur une CMDB, puisque l’on traite de procédures opérationnelles très granulaires, comme des scripts de nettoyage ou de redémarrage. Le plus souvent dispersées dans l’ensemble du système d’information, ces procédures sont fréquemment mal référencées. Une bonne pratique consiste à jouer ces Plan de reprise d'activité de façon périodique pour vérifier l’adéquation à l’architecture de production.
3. Les priorités
Focaliser ses ressources sur ce qui est réellement important, est essentiel. Cela parait être une évidence car toutes les activités de l’entreprise n’ont pas la même valeur, pas la même criticité. Pourtant les systèmes sont aujourd’hui de plus en plus complexes, interconnectés et dépendent les uns des autres comme cela n'avait jamais été envisagé auparavant. Piloter efficacement les équipes techniques dans la période de stress intense que constitue une reprise d’activité, est donc nécessaire. Cette phase nécessite une parfaite visibilité sur l’ordonnancement et l’avancement des opérations, non seulement pour permettre de faire des choix judicieux mais aussi pour informer en continu les équipes de management.
L’automatisation du Plan de Rétablissement d’Activité
L’étude réalisée par Gartner en 2017 sur le recouvrement d’activité, indique que près de trois quarts des entreprises n’ont pas encore automatisé les procédures de reprise impliquées dans le PRA. Ce sont donc des entreprises qui dépendent presque entièrement du facteur humain pour redémarrer leurs activités. Pourtant l’automatisation reste une solution de choix pour pallier l’indisponibilité des équipes, centraliser les changements et gérer efficacement la priorisation des redémarrages en fonction des dépendances entre systèmes, quelle que soit leur complexité. L’automatisation des processus permet en outre de soulager les différents intervenants des tâches manuelles et répétitives, offrant de meilleures perspectives pour tester régulièrement les procédures de reprise. Face à la multiplication des risques de toutes natures, les organisations informatiques doivent veiller à assurer leur résilience. Si le Plan de reprise d'activité formalise les moyens et les objectifs, il ne faut pas néanmoins sous-estimer la difficulté des aspects opérationnels dans un moment de grande tension. Comme souvent, l’automatisation y trouve toute sa place.
L'incidentologie en Datacenter
Les principales sources d'incidents en DataCenter

L’Uptime Institute[36] a publié en mars 2019 son Publicly Reported Outages 2018-19[37].
En 2018 lors de la sortie du 8th Annual Industry Survey[38], l’Uptime Institute avait indiqué qu’un tiers (30,8 %) des opérateurs de datacenters interrogés avaient subis une coupure ou une sévère dégradation de service durant l’année 2017. Le rapport 2019[39] basé sur les incidents rendus publics dans des médias montre une tendance à la hausse avec près de 3 fois plus d’incidents en 2018 qu’en 2016. Ceci ne signifie pas nécessairement qu’il se soit produits plus d’incidents mais est plutôt le signe d’une visibilité accrue dans les médias ce qui a permis une amélioration de la collecte des données.

L’enquête intitulée Systematic survey of public cloud service outage donne une volumétrie d’incidents sur le top 5 des fournisseurs de Cloud public. Cette étude a été effectuée sur des incidents du Cloud public en utilisant l’approche SLR (Systematic Literature Review). Au total l’étude a collecté 112 évènements liés à des pannes de service. Les données montrent que chacun des fournisseurs de Cloud ont subi des pannes sans oublier qu’il y a aussi les incidents n’ayant pas été déclarés[40].
Pour qualifier l’impact des incidents rendus publics, l’Uptime Institute a créé une échelle de criticité à 5 niveaux[39] :
| Type | Classement | Impact de l'incident |
|---|---|---|
| Catégorie 1 | Négligeable | Incident tracé mais avec peu ou pas d'impact évident sur le service, pas d'interruption de service |
| Catégorie 2 | Minime | Interruption de service. Effet minime sur les utilisateurs/clients et sur l'image de marque |
| Catégorie 3 | Significatif | Interruption de service pour les clients/utilisateurs, scope principalement limité en durée ou en effet. Effet financier minime ou nul. Quelques impacts sur l'image de marque ou sur des aspects juridiques. |
| Catégorie 4 | Sérieux | Interruption de service et/ou d'opération. Conséquences incluant des pertes financières, violation juridiques, dommage sur l'image de marque, atteinte à la sécurité. Perte de clients. |
| Catégorie 5 | Sévère | Interruption ou dommage majeur sur le service et/ou les opérations avec des conséquences incluant des pertes financières importantes, des problèmes de sécurité, des violations juridiques, des pertes de clients, des dommages sur l'image de marque |
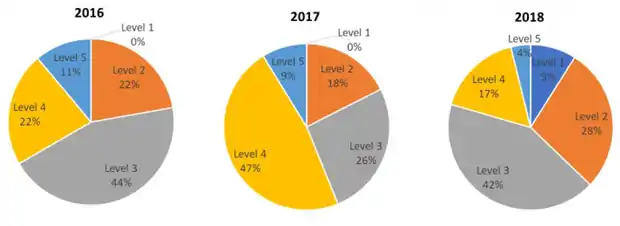
En 2018, la plupart des incidents rendus publics sont d’une sévérité basse à moyenne. En regardant sur les trois années on constate un changement significatif : La proportion des incidents de niveau 5 (sévère, incidents critique pour le business) chute alors que le nombre d’incidents moins critiques enregistrés augmente[41].
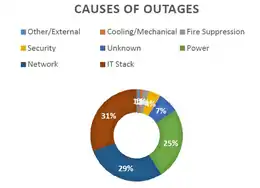
Le résultat de l’étude montre que les systèmes informatiques sont la cause la plus courante des pannes. Suivent le réseau et l’alimentation électrique.
L’alimentation électrique, le refroidissement, les incendies et leur extinction cumulées restent une cause importante des pannes (32 %)[42]. En plus, des coupures classées dans « systèmes informatiques (IT) » et réseau sont en fait causées par des problèmes d’alimentation au niveau d’un système ou d’une baie et ne sont pas classés comme des problèmes d’alimentation de l’ensemble du datacenters[43].
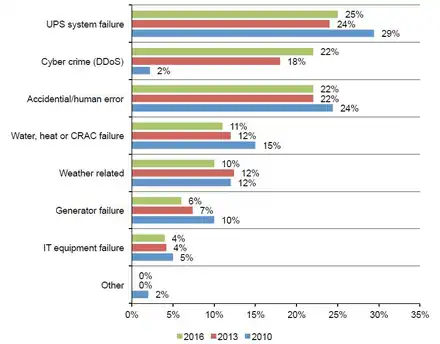
Dans son étude triennale (2010,203,2016) intitulée Cost of Data Center Outages january 2016[44] du Ponemon Institute[45], les pannes d'alimentations électriques arrivent en tête avec 25 % (2016).
La déclinaison du processus de gestion des incidents chez Google
Ce processus est décrit dans le document Google Cloud Whitepaper. Il répertorie les différentes phases en détaillant le déroulement des actions et procédures liées à la gestion d’incidents. Pour Google un incident lié aux données défini est comme une violation de la sécurité qui entraîne, de manière accidentelle ou illégale, la destruction, la perte, l'altération ou encore la divulgation non autorisée des données client sur des systèmes ou encore l'accès non autorisé à ces données[46].
Identification
Le but de cette phase d’identification est de surveiller les événements liés à la sécurité (journaux système et réseau, processus de détection des intrusions, examens de la sécurité logicielle et du code source, anomalies d'utilisation…) afin de détecter et de signaler les éventuels incidents relatifs aux données. Des outils de détection avancés, ainsi que des signaux et des mécanismes d'alerte qui permettent d'identifier rapidement les incidents potentiels[47].

Coordination
Dans cette phase un chargé d’incident va évaluer la nature, la gravité de l’incident et de déployer une équipe d'intervention adaptée. Un chef de produit et un responsable juridique sont chargés de prendre les décisions clés concernant la marche à suivre. Le chargé d'incidents attribue les rôles pour l'enquête et les faits sont rassemblés[48].
Résolution
L’objectif de cette phase est multiple : Recherche de la cause première, la limitation de l'impact de l'incident, la résolution des risques immédiats à la sécurité, la mise en œuvre des correctifs nécessaires dans le cadre de la résolution ainsi que la restauration des systèmes, données et services affectés. Un point important de la résolution est l’information des clients sur les incidents impactant leurs données[49].
Clôture
Après la résolution, l'équipe de gestion des incidents capitalise sur les causes et son déroulement afin d’identifier les principaux points à améliorer. En cas de problèmes critiques une analyse post-mortem peut être lancée par le chargé d'incidents[50].
Amélioration continue

Les axes d’amélioration vont être trouvés grâce à l’exploitation des informations obtenues lors de l'analyse des incidents. Ces améliorations peuvent concerner les outils, les processus, les formations, le programme global de sécurité, les règles de sécurité et/ou les efforts de réponse. Ces enseignements facilitent également la hiérarchisation des démarches d'ingénierie à mener et la conception de meilleurs produits[51].
Domaines de responsabilité suivant le type de service cloud
Suivant le type de service, les domaines de responsabilité pour la gestion d’incidents dépendent des offres souscrites auprès du Cloud Service Provider (CSP). La figure ci_dessous illustre le partage de la responsabilité entre le client et Google en fonction de l'étendue des services gérés exploités par le client. Lorsque le client passe de solutions sur site à des offres de cloud computing IaaS, PaaS et SaaS, Google gère une plus grande partie du service Cloud global, déchargeant d'autant le client en matière de responsabilités de sécurité[52].
Amazon Web Services et la gestion des incidents dans le cloud
Amazon Web Services (AWS) propose un large éventail de produits internationaux basés sur le Cloud : calcul, stockage, bases de données, analyse, mise en réseau, services mobiles, outils de développement, outils de gestion, Internet des objets, sécurité et applications d'entreprise[53].
AWS utilise l'infrastructure d'adoption du Cloud (Cloud Adoption Framework / CAF)[54] qui propose des directives complètes pour établir, développer et exécuter des fonctionnalités informatiques basées sur le Cloud. À l'instar de l'ITIL, la CAF organise et décrit les activités et processus impliqués dans la planification, la création, la gestion et la prise en charge des Technologies de l'information et de la communication modernes.
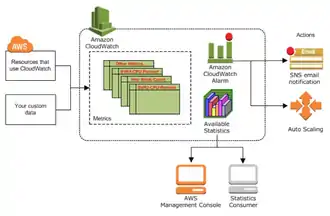
Avec l’API Amazon CloudWatch, AWS prend en charge l'instrumentation en fournissant des outils pour publier et interroger les évènements. L’API peut également envoyer des notifications ou modifier des ressources automatiquement en fonctions de règles définies par le client. Il est possible de superviser l’utilisation des processeurs, les écritures disques des instances comme les machines viturelles, des métriques venant d’applications métiers… etc etc[55]
La gestion des incidents s’effectue grâce à des évènements catégorisés comme des avertissements ou des exceptions qui peuvent déclencher des processus. Ces processus restaurent le fonctionnement normal des services aussi rapidement que possible et minimisent les impacts négatifs sur les opérations métier ou être orienté vers le centre de services de l’entreprise cliente[56].
En complément de CloudWatch, l’application Auto Scaling proposée par AWS peut permettre de contrôle vos applications et l’ajustement automatique de la capacité à maintenir des performances constantes et prévisibles[57].
Incidents dans les datacenters : le top 7 des plus importantes pannes Cloud en 2019
Le Cloud (nuage) a séduit ces dernières années, grâce à ses nombreux avantages en termes de flexibilité, de simplicité et même de coût, tant les entreprises que les particuliers. Le nuage permet ainsi d’accéder à ses fichiers et documents depuis n’importe quel appareil et depuis n’importe où, et les entreprises n’ont plus besoin de développer leurs propres infrastructures, alliant ainsi simplicité et réduction des charges.
Cependant, les utilisateurs de Cloud font aussi le choix de confier la sécurité et la sûreté de leurs données à leurs fournisseurs. En migrant leurs données et applications sur les serveurs d’un fournisseur, plutôt que sur leurs propres Data Centers, les entreprises acceptent de vouer une confiance aveugle à leur prestataire. Or, de nombreuses pannes survenues en 2019 nous rappellent que le Cloud est loin d’être infaillible et d’être synonyme de sécurité, et que la dépendance à cette technologie comporte bien des risques, démontrant que le Cloud.
Les 7 plus importantes pannes Cloud qui ont secoué l’année 2019[58].
Amazon Web Services
En août 2019, un Data Center US-EAST-1 appartenant à AWS et situé en Virginie du Nord, a été frappé par une panne d’électricité. L’interruption de service a été recensée par le site spécialisé Downdetector[59]. Les générateurs de backup du centre de données sont donc tombés en panne. 7,5 % des instances Amazon Elastic Compute Cloud (EC2) et des volumes Amazon Elastic Block Store (EBS) sont restés temporairement indisponibles[60], d’une part, et d’autre part, après que le courant ait été restauré, Amazon a annoncé que certaines des données stockées sur le hardware endommagé ne pourraient pas être récupérées. Ainsi, des informations précieuses ont donc été définitivement perdues par certains clients.
Apple iCloud
En juillet 2019, de nombreux utilisateurs de l’iCloud d’Apple sont restés dans l’incapacité d’accéder au service pendant plusieurs heures. Plusieurs services Apple tels que l’App Store, Apple Music, Apple TV, Apple Books et Apple ID ont été affectés. De même, des fonctionnalités telles que « Trouver mon iPhone » étaient indisponibles durant l’incident. Apple a associé cette panne à un problème de « BGP route flap » qui a provoqué d’importantes pertes de données pour un grand nombre d’utilisateurs.
Cloudflare
En juillet 2019, les visiteurs de Cloudflare ont reçu des erreurs 502, erreurs causées par un pic d’utilisation de CPU sur le réseau, ce pic lui-même causé par un déploiement de logiciel raté [61]. Durant 30 minutes, le service est resté en panne jusqu’à ce que le déploiement soit annulé.
Facebook et Instagram
Bien qu’il ne s’agisse pas de services Cloud à proprement parler, Facebook et Instagram reposent fortement sur le nuage. En 2019, un changement de configuration de serveur a provoqué une panne de ces réseaux sociaux, pendant près de 14 heures (problèmes d’accès et fonctionnalités telles que la publication ou la messagerie Messenger inaccessibles).
Google Cloud
Google Cloud Platform a été victime de deux pannes majeures en 2019. En juillet, un problème avec le Cloud Networking et le Load Balancing a contraint Google à séparer les serveurs de la région US-east1 du reste du monde[62], causant des dommages physiques à de multiples bundles de fibre concurrents servant les ponts réseau de la région. En novembre 2019, plusieurs services de la Google Cloud Platform (Cloud Dataflow, stockage Cloud, et Compute Engine) ont été affectés par d’importants problèmes[63], affectant de nombreux produits à l’échelle mondiale.
Microsoft Azure
En mai 2019, une délégation de nom de serveur incorrecte a affecté la résolution DNS et la connectivité réseau de Microsoft Azure. Pendant plus d’une heure, les services Microsoft Office 365, Microsoft Teams ou encore Xbox Live sont restés inaccessibles. Il reste cependant à noter que les enregistrements DNS des clients n’ont pas été affectés après la restauration des services.
Salesforce
En mai 2019, le déploiement d’un script de base de données sur le service Pardot Marketing Cloud de Salesforce a provoqué un grave incident[64], accordant aux utilisateurs ordinaires des permissions d’un niveau supérieur. Afin d’éviter que les employés dérobent des données sensibles à leurs entreprises, Salesforce a dû bloquer de nombreux utilisateurs puis bloquer l’accès à d’autres services tels que Sales Cloud et Service Cloud. Ainsi, pendant plus de 20 heures, les clients étaient dans l’incapacité d’accéder à Pardot Marketing Cloud. Il aura fallu 12 jours pour que les autres services tels que Sales Cloud et Service Cloud soient déployés. L’intégralité de l’infrastructure Cloud de Salesforce a donc été affectée par un simple script…
Focus sur des incidents redoutables de type « cascade » dans un data center tels que vécu par OVHcloud en novembre 2017
OVHcloud et la loi de Murphy, situation improbable vécue par OVHcloud, jeudi 9 novembre 2017.
Juste après 7 heures, son data center de Strasbourg a perdu simultanément ses deux alimentations électriques principales. Deux groupes électrogènes, qui auraient dû pallier ces ruptures d’alimentations électriques EDF et prendre le relais sans coupure, n’ont pas démarré, et sont restés désespérément hors service.
Moins d’une heure plus tard, les liaisons en fibre optique reliant un autre de ses data center à Roubaix et plusieurs Nœud (réseau)|nœuds d’interconnexions d’Internet[65], des lieux fondamentaux où s’interconnectent les grands acteurs du secteur (fournisseurs d’accès à Internet, GAFAM, hébergeurs de contenus …) cessaient de fonctionner. Par répercussions, les données hébergées par OVHcloud à Roubaix ne pouvaient plus atteindre ces échangeurs autoroutiers de l’Internet[66] - [67], environ 3 millions de sites web étaient inaccessibles. Les effets de bords sont rapidement perçus et affectent les géants du Net, les premiers à s’enquérir de prendre des nouvelles chez OVHcloud sont les GAFAM, ils proposent même leur aide à OVHcloud. En effet, ces incidents ont des effets négatifs sur des flux conséquents de données qui transitent via leurs propres data center.
Deux pannes rares
Résultat de ces deux pannes combinées : des centaines de sites Internet hébergés chez OVHcloud ont été inaccessibles pendant plusieurs heures, le temps pour les équipes d’OVHcloud de redémarrer les serveurs à Strasbourg et de rétablir les liaisons optiques de Roubaix. La concomitance de ces deux pannes est exceptionnelle, voire improbables dans des scénarios de PRA. Le PDG et fondateur d’OVHcloud, Octave Klaba[68] a fait part du déroulement des opérations au fil de l’eau sur Twitter dans la résolution des problèmes ainsi que la mise à jour du portail Web travaux.OVHcloud.net[69] avec un rapport de clôture de l'incident. Cette communication via Twitter permanente a été prépondérante dans cette gestion de crise aiguë ; le capital de confiance et de crédibilité d’OVHcloud avait déjà été écorné lors d'un premier incident critique au mois de juin 2017[70].
Dans un premier bilan publié à la mi-journée, OVHcloud a expliqué que l’interruption des liaisons en fibre optique était due à un « bug logiciel », depuis corrigé. Après réparation, la situation est rapidement revenue à la normale sur ce front. À Strasbourg, le processus de redémarrage des serveurs informatiques a pris plus de temps. Si l’électricité a été totalement rétablie, certains services étaient encore en cours de rétablissement en début d’après-midi.
L’entreprise Électricité de Strasbourg (filiale d’EDF) qui alimente le centre de données alsacien d’OVHcloud a évoqué sans plus de précisions un défaut physique sur le câble souterrain qui alimentait le centre de données Après l’échec du démarrage des groupes électrogènes, l’entreprise a déployé en urgence un câble de remplacement, rétablissant le courant vers OVHcloud après trois heures et demie de coupure. Il n'existe pas à ce jour de rapport post mortem sur cette panne énergétique.
Les ressources nécessaires pour les Datacenters
L’impact spatial et énergétique des datacenters sur les territoires
Face à la croissance massive des échanges de données et des besoins de stockage, l’impact spatial et énergétique des datacenters Centre de données va être de plus en plus structurant pour les territoires. Leur diversité d’usages, d’acteurs, de tailles et d’implantations rend aujourd’hui complexe la lecture de leurs dynamiques et de leurs effets spatiaux. En février 2019, Cécile Diguet et Fanny Lopez(dir.), ont proposé, pour l'ADEME[71], un rapport intitulé "L’Impact spatial et énergétique des datacenters sur les territoires"[72].
Le rapport s’attache à donner une image du paysage des datacenters en Île-de-France et dans trois territoires des États-Unis, représentant chacun des situationsspatiales et énergétiques différentes(ville dense, espace périphérique, rural). Facteur potentiel de déséquilibre des systèmes énergétiques locaux, objets dont l’accumulation urbaine et la dispersion rurale questionnent, les datacenters font dans ce rapport, l’objet d’une analyse approfondie pour mieux appréhender les nouveaux territoires numériques en construction, les solidarités énergétiques à construire et les alliances d’acteurs à mettre en place.
Un focus est également réalisé sur les infrastructures numériques alternatives et citoyennes, qui se développent aussi bien en Afrique, Amérique du Sud, que dans les territoires mal couverts en Europe ou aux États-Unis. Dédiées à l’accès à Internet et de plus en plus, aux services d’hébergement et de Cloud, elles peuvent constituer une réponse distribuée et pair-à-pair, dont l’impact écologique pourrait finalement se révéler plus limité que les infrastructures centralisées de grande échelle car calibrées au plus près des besoins locaux, mais aussi plus résilientes car moins centralisées techniquement et moins concentrées spatialement. Elles constituent ainsi une option à considérer, soutenir mais aussi à mieux évaluer, pour réduire les impacts spatiaux et énergétiques des datacenters.
Le rapport propose également des visions prospectives qui combinent des tendances de fond et des signaux faibles pour imaginer les mondes numériques de demain, basés sur la croissance et l'ultracentralisation numérique, la stabilisation du Système Technique numérique et diversité infrastructurelle cela nécessite de traiter les aspects de résilience, mais aussi sur les bases du modèle actuel fondé sur l'ultradécentralisation numériques. Des recommandations sont proposées autour de trois axes, les acteurs et la gouvernance, l’urbanisme et l’environnement, et l’énergie. Des pistes d’approfondissement et d’études sont également présentées.
L'énergie consommée par les datacenters
La consommation des data centers à la base du réseau internet ne cesse de croître, au point de représenter 4 % de la consommation énergétique mondiale en 2015. La climatisation et les systèmes de refroidissement représentent de 40 à 50 % de la consommation énergétique des data Centers[73]. Les data centers américains ont consommé 91 milliards de kilowatt-heure (kWh) en 2013 et 56 milliards en Europe (prévision : 104 milliards en 2020).
Le site Planetoscope, avec son "ConsoGlobe"[74], permet de suivre en direct cette consommation.
Localisation - Implantation du bâtiment
Une entreprise australienne, Cloudscene[75] s’est donnée pour vocation de diffuser une information aussi exhaustive et transparente que possible sur les datacenters et fournisseurs de services Cloud : elle agrège de l’information sur environ 4700 data centers et 4200 fournisseurs de service Cloud présents dans 110 pays.
ORANGE avec l'ancrage de l'un de ses principaux datacenters à Val-de-Rueil[76] s'est assuré des meilleures garanties sur ses sources d'approvisionnement énergétiques, mais aussi sur la sécurité du secteur d'implantation dans une zone géographique tactique particulièrement sous surveillance avec un centre de test stratégique des Armées[77] dans son périmètre ainsi qu'un centre de calcul EDF[78]. Le site d'EDF héberge entre autres des calculateurs scientifiques utilisés par la recherche et développement mais aussi l’ingénierie nucléaire.
L'aménagement paysager du site vise souvent à l’intégrer au mieux dans le paysage environnant et à respecter les prescriptions de règlement de zone du plan local d'urbanisme (PLU).
L'implantation du bâtiment est primordiale, tant pour lui-même que pour l'environnement ; la prise en compte de la localisation dans un périmètre "raisonnable" de distance avec les populations (minimum 500 mètres), en accord avec les paysages, les biens matériels, les patrimoines culturels et archéologiques, et bien sûr, les données physiques et climatiques, et éviter les zones où le sismiques est non négligeable (ou tout au moins prévoir une conception antisismique (piliers sur amortisseurs)et équiper le bâtiment de détecteurs sismiques sur alarme), les zones inondables (ou prévoir des constructions sur une butte (altitude 100 mètres), sur une zone non soumise au ruissellement et aux coulées de boue. Le terrain d'implantation d'un datacenters doit disposer d'un réseau d'évacuation sophistiqué des eaux pluviales et de drains. La végétalisation du terrain doit également participer à minorer les risques d'inondations. Un datacenter peut également être construit sur pilotis.
En complément de ces données, il convient de faire une étude en termes de sols et eaux souterraines (absence de nappe), eaux de surface, de qualité de l'air et odeurs, de niveaux sonores, de vibrations, d'émissions lumineuses, limiter les risques sur le bâtiment, éviter qu'il soit situé à proximité d'un axe routier (une déflagration sur la route pourrait avoir un impact sur le bâtiment), ou dans un couloir aérien, et privilégier les zones hors SEVESO[79].
Il faut également tenir compte des espaces naturels, agricoles, forestiers et maritimes, de la faune et de la flore, des habitats naturels et équilibres biologiques, et de la continuité écologique.
Alimentation électrique et climatisation
C'est de la fourniture continue de l’alimentation électrique de Haute Qualité des équipements informatiques et de la climatisation des salles informatiques, que dépend le fonctionnement correct des équipements informatiques. Ainsi, la conception d'un datacenters repose sur une certaine répétition, redondance des infrastructures techniques au sein des bâtiments techniques, des moyens de génération électrique Haute Qualité et de production froid (climatisation). Les bâtiments techniques peuvent être équipés de moyens de production électrique (groupes électrogènes), dispositifs de productions peuvent être eux-mêmes redondés, ceci afin de parer une éventuelle perte des arrivées électriques sur le site.
Les data centers stockant les données informatiques des clients sont soumis un dispositif composé de règles importantes et indispensables à leur bon fonctionnement (la température, l’hygrométrie et la qualité de l’air), un dispositif qui doit être constamment maîtrisé.
En effet, les composants électroniques des serveurs provoquant des dégagements de chaleur très importants, une température élevée peut entrainer non seulement un risque pour le bon fonctionnement des équipements, mais aussi une dégradation du matériel. La climatisation des locaux est une des solutions mise en place pour éviter des problèmes de surchauffe des serveurs. En contribuant à maintenir la température ambiante des salles blanches, la climatisation influe donc sur la température, sur la qualité de l’air ainsi que sur l’hygrométrie, c’est-à-dire le taux d’humidité dans l’air.
Les équipements informatiques sont très sensibles à la qualité de leur alimentation électrique. Les infrastructures techniques doivent être conçues pour leur délivrer une énergie électrique de Haute Qualité, à savoir une fourniture électrique « propre », peu sensible aux variations de charge, débarrassée de toute perturbation ou anomalie et exempte de coupure ou microcoupure. Les onduleurs et les batteries assurent cette génération d’énergie électrique Haute Qualité. Des unités de production électrique (groupes électrogènes) prennent le relais, en cas d'une coupure électrique prolongée sur le site.
Un datacenters doit pouvoir s'appuyer, au moins, sur des équipements tels que des onduleurs, des réserves d’énergie (batteries) et des groupes électrogènes, afin d’optimiser ces infrastructures techniques.
Dans le cadre du datacenters Val-de-Reuil[76], il est nécessaire de maintenir les serveurs informatiques à une température inférieure à 17–26 °C. C'est pourquoi, l’exploitation du site nécessite un système de refroidissement des installations. Des centrales de traitement de l’air (CTA) utilisant l’air extérieur, constituent essentiellement ce système. Cependant, il arrive que la température de l’air extérieur soit trop élevée pour garantir une température suffisamment basse au niveau des serveurs (soit environ 15 à 20 % du temps) ; il convient alors de faire appel à des groupes froids pour obtenir cette température satisfaisante.
Pour le chauffage, la ventilation, et la climatisation (CVC) des bâtiments informatiques : utilisation à 86 % du Free Cooling (ventilation avec de l’air sans utilisation des groupes froids). Lors de l’utilisation des groupes froids, production d’eau à 20/30 °C, ventilation double flux avec récupération de chaleur pour les communs.
Le Free Cooling permet de refroidir un bâtiment en utilisant la différence de température entre l’air extérieur et l’air intérieur. Le jour, le Free Cooling utilise l’air extérieur pour rafraîchir un bâtiment, lorsque la température extérieure est inférieure à la température intérieure.
Monitoring
Le monitoring est un ensemble de pratiques d'instrumentation des plates-formes de production, qui a pour objectif la production de métriques de performance. Il existe cinq niveaux distincts de monitoring pour réagir aux événements qui surviennent dans les environnements de production. Ce sont généralement les mêmes produits qui fournissent les services de mesure et de supervision. Les outils utilisés sont principalement des solutions d'éditeurs de logiciels. Des solutions open source de qualité comme Nagios, Zenoss, ou plus récemment depuis 2019 avec des versions stables Prometheus[80], voient leurs parts de marché progresser régulièrement. Les cinq types de monitoring sont déclinés en cinq catégories de métriques :
- La disponibilité.
- Les temps de réponses.
- Temps de réponses détaillés.
- Activité métier.
- Expérience utilisateur.
Les offres de monitoring pour les services de disponibilité et les temps de réponses sont nombreuses. Il n'en est pas de même pour les temps de réponses et de disponibilité des applications. Prometheus est une des solutions les plus en vue de l'Open source pour permettre de prendre en compte l'ensemble des métriques des catégories à superviser.
Optimiser la gestion des incidents et en limiter l'impact : des solutions pour aujourd'hui et pour demain...
Le Cloud n’est donc pas toujours synonyme de sécurité. Par ailleurs, les architectures informatiques traditionnelles ne sont plus du tout adaptés à la rigueur du temps réel et donc de l’économie numériques actuelle. Mais même les services Cloud - initialement mis en place pour remplacer les anciennes technologies "onsite" par des équivalents en ligne - pourraient ne plus suffire.
Des innovations en cours et à venir se profilent, tant pour assurer la sécurité du stockage des données, permettant d'optimiser la gestion des incidents et d'en limiter l'impact, mais également pour maximiser et perfectionner le fonctionnement même d'un datacenters.
La numérisation de notre vie quotidienne génère une masse de données inimaginables et il va sans dire que notre dépendance vis-à-vis des datacenters qui traitent et stockent ces données ne fera que croître, tout comme le temps nécessaire pour en assurer la gestion. les entreprises se doivent de tirer parti de l’accroissement de ce volume de données tout en réduisant le temps consacré à sa gestion sans pour autant perdre en efficacité.
Un datacenter autonome
Le défi de la complexité
Les organisations ont besoin de rationaliser le management de leurs datacenters et de s’attaquer aux manques d’efficacité qui peuvent exister en la matière. La gestion traditionnelle des datacenters implique beaucoup de travail pour les équipes d’exploitations, qui passent leurs journées (et parfois même leurs nuits...) à "bricoler" manuellement l’infrastructure afin de pouvoir gérer au mieux les événements imprévus.
Tout ceci crée une perte colossale de temps et de ressources.
Avec la complexité croissante des technologies de stockage des données, cette situation présente un risque de plus en plus important et ne peut être efficacement traitée avec des outils classiques de gestion des datacenters. Les entreprises ont dorénavant besoin d’une nouvelle génération de solutions de management, d’outils d’automatisation et de traitement analytiques pour libérer les administrateurs de datacenters des travaux quotidiens fastidieux et leur permettre de se consacrer à des activités créatrices de valeur pour l’entreprise. En d’autres termes, les entreprises ont besoin d’un datacenter | datacenters autonome[81].
Une nouvelle génération de stockage vient de naître
Une infrastructure de datacenters dotée d’Intelligence artificielle (IA) permettrait de dépasser les limites des approches traditionnelles, grâce à l’utilisation d’algorithmes intelligents qui traitent les données des capteurs installés sur les équipements et leur permettent de fonctionner de manière autonome. Avec l’IA, ce moteur intelligent pourra automatiquement détecter les mauvais fonctionnements, les goulets d’étranglement ou encore les configurations incorrectes, et potentiellement apporter automatiquement les actions correctives ; ce qui réduira le temps alloué aux interventions. L’IA est également capable de dresser une liste des problèmes déjà détectés, afin d’éviter les répétitions et d’empêcher les clients de se heurter à des problèmes déjà rencontrés.
L’utilisation de l’IA dans le datacenters peut non seulement détecter et résoudre les problèmes, mais peut proactivement apporter des suggestions d’amélioration. En tirant parti des données et de la valeur qu’elles recèlent, l’IA peut identifier des opportunités d’amélioration des systèmes et de leurs performances, ayant un impact positif sur les processus métiers, l’efficacité des équipes Technologies de l'information et de la communication et finalement, sur l’expérience client.
Comment est-ce possible ?
Pour faire simple, l'IA dans le datacenters offre une supervision simultanée de tous les systèmes existants. Elle permet au système de comprendre l'environnement de fonctionnement idéal pour chaque charge de travail et chaque application, puis d'identifier les comportements anormaux par rapport aux modèles réguliers des E/S sous-jacentes. Autrement dit, plus la richesse et le volume des données générés dans une entreprise augmentent, plus l'efficacité du système d'IA s’améliore en apprenant des modèles de données. La pérennité de l'IA s’en trouve à son tour prolongé car le système cherchera en permanence à améliorer l’infrastructure informatique, soit en corrigeant les nouveaux problèmes qui émergent, soit en suggérant de nouvelles méthodes pour optimiser et améliorer les processus.
Le système peut utiliser des données métrologiques détaillées pour constituer un socle de base de connaissances et d’expériences, concernant chaque système en relation avec le moteur d’IA. La technologie des algorithmes de recherche comportementale permet d’analyser et de prévoir si un autre équipement du datacenters est susceptible de rencontrer des problèmes similaires à ceux déjà traités. De plus, cette capacité permet de modéliser la performance des applications et de l’optimiser pour chaque nouvelle infrastructure d’accueil, en fonction de l’historique des configurations et des modèles de charge de travail, ce qui réduit les risques lors des déploiements sur de nouvelles configurations, et diminue significativement les coûts de mise en œuvre.
Une nouvelle approche prédictive voit le jour
En s’appuyant sur les outils d’analyse prédictive et la base de connaissances sur les moyens d’optimiser la performance des systèmes, l’IA peut suggérer des recommandations adaptées pour établir un environnement de travail idéal et appliquer de façon automatique les modifications en lieu et place des administrateurs IT. De plus, si l’automatisation des actions n’est pas souhaitée, des recommandations peuvent être proposées aux équipes d’exploitation par celle des dossiers de support. Cela libérera tout de même les équipes d’exploitation des multiples recherches manuelles nécessaires à l’identification des causes de dysfonctionnement, et leur éviter également des improvisations en matière de gestion de l’infrastructure.
L’utilisation d’un moteur d’analyse prédictive permet aux clients de résoudre 86 % des problèmes avant que ceux-ci n’affectent l’activité business. Dans les 14 % de cas restants, l’utilisateur possède un accès immédiat à des ingénieurs expérimentés pour trouver une solution le plus rapidement possible. De même, des études menées par le cabinet d’analystes ESG révèlent que 70 % des clients qui utilisent cette technologie peuvent résoudre des problèmes ou remédier à de mauvais fonctionnements en moins d’une heure, et que plus de 26 % d’entre eux l’ont fait en moins de 15 minutes.
Avec une approche traditionnelle de la gestion des datacenters, il faut en moyenne 84 minutes à un tiers (32 %) des utilisateurs pour qu’un problème rencontré soit remonté à un ingénieur disposant du niveau d’expertise requis pour le résoudre.
En plaçant l’IA au cœur des outils de gestion du datacenters, les organisations seront en mesure de prédire, d’éviter et de résoudre les incidents plus rapidement. Ceci peut amener des gains significatifs en termes d’efficacité et d’amélioration opérationnelle, tout en rendant l’infrastructure plus intelligente et plus résiliente. Plus important encore, les entreprises bénéficieront d’une réduction majeure des temps d’interruption de service et des délais de résolution des problèmes IT. Ainsi, les équipes Technologies de l'information et de la communication pourront mieux se consacrer à des tâches qui apportent réellement de la valeur, et qui améliorent l’expérience client.
Le Cloud hybride
Une étude publiée par Nutanix en 2018 révèle que 91 % des responsables Technologies de l'information et de la communication d’entreprises considèrent que le modèle idéal est celui du Cloud hybride, qui marie les bienfaits du Cloud public avec ceux du Cloud privé[82].
Cloud hybride - Définition
Dans le cas d’un Cloud privé, les serveurs sont dédiés à une seule entreprise. Ces serveurs peuvent être sur site, ou hors-site. Dans le cas d’un Cloud public, les serveurs sont partagés entre les différents clients d’un fournisseur. Les serveurs sont toujours hors-site, puisqu’ils sont situés dans les Data Centers du fournisseur.
Selon Forrester Research, le Cloud hybride consiste à connecter un ou plusieurs Clouds publics à un Cloud privé ou à une infrastructure de Data Center sur site traditionnelle. Pour faire simple, il s’agit donc d’un savant mélange entre les ressources Technologies de l'information et de la communication sur site et hors site.
De manière plus élaborée, le Cloud hybride est un environnement Cloud constitué de ressources de Cloud privé sur site combinées avec des ressources de Cloud public tiers connectées entre elles par un système d’orchestration.
Selon la définition « officielle » du National Institute of Standards and Technology, le Cloud hybride est "une infrastructure Cloud composée de deux infrastructures Cloud distinctes ou plus pouvant être privées ou publiques et qui restent des entités uniques, mais sont connectées par une technologie standard ou propriétaire permettant la portabilité des données et des applications".
Cloud hybride - Les avantages
- Il permet de transférer les workloads et les données entre le Cloud public et le Cloud privé de façon flexible en fonction des besoins, de la demande et des coûts. Ainsi, les entreprises bénéficient d’une flexibilité accrue et d’options supplémentaires pour le déploiement et l’usage des données.
- La flexibilité : dans le cas d’une infrastructure sur site, la gestion des ressources nécessite du temps et de l’argent. L’ajout de capacité requiert donc une planification en amont. Au contraire, le Cloud public est déjà prêt et les ressources peuvent être ajoutées instantanément pour répondre aux besoins de l’entreprise. Ainsi, en s’appuyant sur le Cloud hybride, une entreprise pourra exploiter des ressources du Cloud public lorsque ses besoins dépassent les ressources disponibles sur Cloud privé, par exemple lors de pics saisonniers. Le Cloud hybride permet donc de profiter d’une élasticité nécessaire pour faire face aux variations de la demande qui peuvent être liées à de multiples facteurs.
- Accès rapide aux données les plus critiques ; il est donc possible de garder les données fréquemment utilisées sur site, et de transférer les données « froides » sur le Cloud.
- Réduction des charges de l’entreprise grâce aux faibles coûts des ressources Technologies de l'information et de la communication proposées sur le Cloud public. En effet, la plupart des fournisseurs de Cloud public proposent à leurs clients de payer uniquement pour les ressources qu’ils consomment. Les dépenses inutiles sont donc évitées.
- traitement de Big Data ; il est par exemple possible pour une entreprise d’utiliser le stockage Cloud hybride pour stocker ses données et d’effectuer des requêtes analytiques sur le Cloud public où les clusters Hadoop (ou autre) pourront être scalés pour s’adapter aux tâches de computing les plus exigeantes.
Cloud hybride - Les inconvénients
- Le Cloud hybride n’est pas adapté à toutes les situations (ex : les petites entreprises disposant d’un budget Technologies de l'information et de la communication limité, préfèreront s'en tenir au Cloud public, les coûts liés à l’installation et à la maintenance de serveurs privés du Cloud hybride pouvant être trop élevés).
- Une application nécessitant une latence minimale n’est pas toujours adaptée au Cloud hybride ; il peut être préférable d’opter pour une infrastructure sur site.
L'intelligence artificielle et le machine learning
Lorsqu'elle est déployée stratégiquement et associée à une supervision humaine pertinente, l'Intelligence artificielle peut générer une foule de nouvelles fonctionnalités pour les datacenters de nouvelle génération par exemple avec Matlab[83].
Force est de constater que les entreprises qui ne parviendront pas à intégrer le potentiel révolutionnaire des technologies émergentes - du cloud computing et aux quantités de données volumineuses en passant par l'Intelligence artificielle (IA) - dans leur infrastructure de centre de données centre de données, pourraient bientôt se retrouver distancées loin derrière leurs principaux concurrents.
En fait, Gartner[84] prévoit que plus de 30 % des centres de données qui ne se préparent pas suffisamment à l'IA, ne seront plus viables sur le plan opérationnel ou économique. Il incombe donc aux entreprises et aux fournisseurs tiers, d'investir dans des solutions qui les aideront à tirer le meilleur parti de ces techniques de pointe.
Voici trois façons proposées aux entreprises qui souhaitent exploiter l'IA pour améliorer les opérations quotidiennes de leur datacenters :
- Exploiter l'analyse prédictive pour optimiser la distribution de la charge de travail
Il fut un temps où il relevait de la responsabilité des professionnels de l'informatique, d'optimiser les performances des serveurs de leur entreprise, en s'assurant que les charges de travail étaient réparties de manière stratégique dans leur portefeuille de centres de données ; difficile cependant, eu égard aux contraintes de personnel et/ou des ressources devant surveiller la répartition des charges de travail 24 heures sur 24.
En adoptant un outil de gestion basé sur l'analyse prédictive, il est désormais possible de déléguer à un ordonnanceur, la grande majorité des responsabilités de l’équipe informatique, en matière de distribution de la charge de travail (optimisation du stockage, calcul de la répartition des charges de travail en temps réel).
Au-delà de la simple autogestion, l’avantage est que les serveurs gérés par des algorithmes d'analyse prédictive gagnent en efficacité au fil du temps : au fur et à mesure que les algorithmes traitent davantage de données et se familiarisent avec les flux de travail de l'entreprise, ils commencent à anticiper la demande des serveurs avant même que les requêtes ne soient faites.
- Refroidissement piloté par des algorithmes d'apprentissage machine
Les centres de données consomment une énorme quantité de puissance, pour les opérations de calcul et le stockage des serveurs d’une part, mais aussi pour les fonctions de refroidissement des centres informatiques. Cette consommation d'énergie peut rapidement devenir une charge financière importante.
Un système de recommandation alimenté par l'IA pourrait réduire la consommation d'énergie, diminuer les coûts et rendre les installations plus durables sur le plan environnemental. Il est à noter que Google et DeepMind ont expérimenté l'utilisation de l'IA pour optimiser leurs activités de refroidissement ; ainsi, l'application des algorithmes d'apprentissage machine de DeepMind dans les centres de données de Google a permis de réduire de 40 % l'énergie utilisée pour le refroidissement, sans compromettre les performances des serveurs.
- Utilisation de l'IA pour atténuer les pénuries de personnel
L'émergence de nouvelles offres - généralement plus complexes - dans l'espace du Cloud computing a transformé le centre de données typique en un centre d'échange de haute technologie pour une variété de charges de travail critiques pour les entreprises.
Le besoin de professionnels des Technologies de l'information et de la communication avec les compétences requises pour ces centres de haute technologie est exponentiel ; pourtant, face à une pénurie de candidats suffisamment qualifiés, les équipes de gestion des centres de données sont donc confrontées à une grave pénurie de personnel qui pourrait un jour menacer la capacité des entreprises à entretenir correctement leurs actifs numériques.
Afin de permettre aux centres de données de prospérer en l'absence d'une surveillance humaine approfondie, la technologie d'IA offre la possibilité de prendre en charge une série de fonctions de serveur sans automatiser entièrement la gestion informatique, comme effectuer de manière autonome des tâches de routine comme la mise à jour des systèmes, les correctifs de sécurité et les sauvegardes de fichierss.
Les professionnels de l'informatique peuvent alors assumer des tâches plus nuancées et plus qualitatives, ou des rôles de supervision de tâches qui nécessitaient auparavant leur attention minutieuse.
Pour les entreprises individuelles et les fournisseurs de datacenters tiers, cette approche basée sur le partenariat constitue un juste milieu entre l'automatisation pure et simple et le manque chronique de personnel. Ainsi, ce modèle de gestion « hybride » sera probablement la norme dans l'ensemble du secteur des centres de données, cette « entraide » permettant le bon fonctionnement d'un centre de données.
La progression du "serverless"
Le " serveless", suite logique du cloud-native, en est encore à ses débuts, mais son développement progresse, et les premiers à avoir franchi le pas en voient déjà les avantages[85].
Ne pas refléchir aux limites et capacités des serveurs
La prochaine étape serait le serveless, qui ne nécessite pas de rotation ou de provisionnement des serveurs. Bien sûr, le serveless repose toujours sur des serveurs, mais les développeurs et professionnels Technologies de l'information et de la communication n’auront pas à réfléchir à leurs limites et capacités. Le serveless est « la suite logique du cloud-native », car il s’agit du modèle de calcul utilitaire le plus pur qui soit sur de nombreux points. Amazon propose en la matière sa solution AWS Lambda[86] ou Microsoft avec sa solution Cloud AZURE[87] permet d'analyser les problèmes d’intégrité, suivre l’impact sur les ressources Cloud, obtenir des conseils et du support et transmettre des informations fiabilisées.
Une approche serveless est attrayante « en raison de la quantité limitée de personnel et de talents disponibles pour construire, gérer et maintenir la nouvelle génération de systèmes numériques ». L'attrait du serveless augmentera également avec l'ajout de dispositifs IoT.
Avec la maturité vient le progrès
Pour un certain nombre d’organisations, le serveless est toujours un travail en cours, et beaucoup n’en voient pas encore les avantages, d’après un récent sondage. Quatre entreprises sur dix ont adopté le serveless, mais n’en voient pas encore les impacts positifs, comme le montre l'enquête menée auprès de 1 500 cadres par O'Reilly. Cependant, pour ceux qui ont plus de trois ans d’expérience dans le domaine du serveless, 79 % estiment que leurs efforts sont « majoritairement fructueux » ou mieux, avec des avantages tels que la réduction des coûts d’exploitation et la mise à l'échelle automatique, ou encore la possibilité d'éviter les maintenances de serveur et la réduction des coûts de développement.
Les avantages du Serverless :
- réduction des coûts d'exploitation ;
- mise à l’échelle automatique ;
- absence de problèmes liés aux maintenances de serveur ;
- réduction des coûts de développement ;
augmentation de la productivité des développeurs, et donc augmentation de la valeur de l'entreprise.
Les défis du serverless :
Il n'y a pas véritablement de cursus de formation du personnel actuel (le serveless étant relativement récent, il est difficile de trouver une formation officielle, il faut produire une documentation spécifique et il est difficile de trouver des études de cas dont on peut tirer des leçons). Le verrouillage des fournisseurs (écrire du code pour une plateforme de fournisseur ne la rend pas amovible ou simple à déplacer ailleurs ; parce que le serverless architecture est un domaine naissant, il semble que le marché attend de voir ce qui va se passer en ce qui concerne la question de la portabilité entre les fournisseurs.). Il faut prendre en compte la difficulté des tests d'intégration/débogage (les tests sont plus complexes et demandent plus de travail pour les architectures serveless, avec plus de scénarios à traiter et différents types de dépendances - latence, démarrage, mocks - ce qui change le paysage de l'intégration). Les coûts imprévisibles/variables (il semble que les coûts inattendus qui découlent de l’utilisation du serveless représentent un obstacle, au même niveau que la réduction des coûts représente un avantage. Ce paradoxe met en évidence les espoirs que peuvent porter le serveless, et justifier commercialement son adoption. Le risque survient plus tard, avec les coûts potentiels d’une fuite).
Qu’est-ce que l’ingénierie du chaos et comment la mettre en place ?
Services Cloud, offres open source, Intelligence artificielle, Internet des objets… Les infrastructures informatiques deviennent de plus en plus complexes, et dans ces conditions, assurer leur fiabilité en cas d’incident devient une véritable gageure pour les DSI. C’est pourquoi certains services Technologies de l'information et de la communication ont tâché de développer des méthodes innovantes pour mettre à l’épreuve leur système d’information. Baptisées “ingénierie du chaos”, il s’agit de mettre à l’épreuve ses infrastructures avec le déclenchement volontaire d’incidents.
Initiées par Netflix, ces méthodes ont été adoptées par des grands de l’IT tels qu'Amazon ou encore Microsoft. En France, c’est la SNCF avec son entité Technologies de l'information et de la communication VSC Technologies, qui expérimente actuellement le concept. Ivision vous présente le concept de l’ingénierie du chaos et quelques recommandations utiles à la mise en place de telles procédures au sein de votre SI.
L’ingénierie du chaos
L’ingénierie du chaos[88] est une discipline qui consiste à éprouver la résilience de tout ou partie d’une infrastructure informatique en générant volontairement et de façon contrôlée des pannes dans un système en production.il s’agit de mettre à l’épreuve ses infrastructures avec le déclenchement volontaire d’incidents. Initiées par Netflix avec le logiciel Chaos Monkey[89], ces méthodes ont été adoptées par des grands de l’IT tels que Amazon[90] - [91] ou encore Microsoft[92]. En France, c’est la SNCF avec son entité IT services informatiques VSC Technologies, qui expérimente actuellement le concept. Un test grandeur nature a déjà été réalisé en 2018 avec la simulation de la perte d’un datacenters[93]. Concrètement, cela signifie qu’il faut se préparer d’une part, à ce que les tests aient des répercussions sur le fonctionnement de l’entreprise[94], puisqu’il s’agit de tests réalisés en environnement de production, en conditions réelles, et auxquels il faut apporter de vrais réponses, mais il faut également se préparer, dans un deuxième temps, à ce que les conséquences de ces tests soient maîtrisés, pour éviter à l’entreprise des pertes ou des coûts inattendus.
Mettre en œuvre un test d’ingénierie du chaos :
Pour bien mettre en œuvre un test d’ingénierie du chaos[94], il faut tout d’abord avoir identifié un objectif précis et mesurable. Avant de réaliser le test en production, une première précaution est de le réaliser en environnement de test. Cela permet dans un premier temps de limiter les risques de voir échapper le contrôle du test, sans toutefois écarter toutes les possibilités, puisque l’environnement de test ne sera jamais totalement identique à l’environnement de production[95]. En amont du test en production, il est important de bien informer toutes les personnes susceptibles d’être affectées par l’expérience, toujours dans l’optique de limiter les effets de bord ou de réaction en chaîne liées aux conséquences de l’expérience.
Des exemples d’expérimentation possibles :
- Simuler une panne de datacenters
- Simuler une panne DNS
- Rendre inaccessibles certains services de façon aléatoire
- Créer des perturbations réseaux, problèmes d’accès ou de lenteur
- Introduire des latences entre différents services, pour un pourcentage de trafic et un temps donné.
Vers de nouvelles solutions de stockage de données
Le stockage de données est l’ensemble des méthodes et technologies permettant d’entreposer et de conserver les informations numériques. D’ici 2025, selon IDC, le volume de données généré par l’humanité sera multiplié par cinq et atteindra 163 zettabytes. En conséquence directe, nos besoins en espace de stockage vont augmenter de façon drastique. Il sera non seulement nécessaire d’augmenter la capacité des supports actuels, mais aussi d’en inventer de nouveaux.
Le projet Silica
Microsoft et Warner Bros ont collaboré pour stocker le premier film Superman, sorti en 1978, sur un morceau de "verre", qui est en réalité du quartz. Une technologie innovante qui permettrait de restituer des fichiers sans altérer leur qualité, mais également de stocker à moindre coût de grandes quantités de données. La première validation du concept du Project Silica, mené par Microsoft Research a été annoncée le 4 novembre 2019[96].
Le principe repose sur un laser femtoseconde qui encode les données dans le verre en créant des couches d'indentations et déformations tridimensionnelles, à différents angles et profondeurs, à l'échelle nanométrique. Des algorithmes de machine learning peuvent ensuite lire les données en décodant les images et motifs créés lorsque de la lumière polarisée passe à travers le verre. Cette surface de verre peut contenir jusqu’à 75,6 Go de données.
Le principal bénéfice : le quartz, composé de silice (d'où le nom du projet), peut supporter d'être trempé dans l'eau bouillante, cuit dans un four, passé au micro-ondes, ou d'être frotté avec de la laine d'acier… et les autres menaces environnementales.
La réduction des coûts nécessaires au stockage de données, des coûts de stockage alimentés par la nécessité de transférer de manière répétée des données sur un nouveau support avant que les informations ne soient perdues.
La conservation des données plus longue : contrairement à un disque dur, qui a une durée de vie de trois à cinq ans, ou à une bande magnétique (cinq à sept ans), le stockage sur quartz "permet de conserver les données pendant des siècles" selon Microsoft. On obtient par ce procédé une limitation de la dégradation des données : les données n’étant écrites qu'une seule fois sur le quartz, elles ne subissent pas de dégradation comme lors de migration de données classique. Autre source de réduction des coûts et d’empreinte environnementale : le quartz n’a pas besoin, contrairement à des datacenters par exemple, de système de climatisation ou d’aération. Il existe un point d'amélioration à étudier : la vitesse à laquelle les données doivent être écrites et lues.
Stockage de données à mémoires flash
Les entreprises sont de plus en plus nombreuses à troquer leurs équipements traditionnels de stockage magnétique de données sur disques durs avec des solutions de stockage électronique à mémoire flash. C’est le cas d’AG2R La Mondiale[97]. Le stockage primaire dans l’un de ses trois datacenters s’appuie désormais exclusivement sur des puces électroniques flash. Une expérience considérée comme une étape avant la conversion de l’ensemble de son infrastructure de stockage primaire à cette technologie.
Les datacenter de proximité
La liste des objets connectés qui nous entourent est longue et en constante évolution : ordinateurs, téléphones, tablettes, bracelets, montres, casques, téléviseurs, mais aussi lunettes, valises, vélos, chaussures...
L’augmentation exponentielle des objets connectés soulève la question du traitement des informations et du stockage des données que ne pourra plus à terme assurer le réseau informatique tel que nous le connaissons aujourd’hui.
Il suffit de se tourner vers un phénomène mondial, et l’engouement suscité par Pokemon GO développé par Niantic Labs, pour en avoir une idée plus précise ; l'application téléchargée par 75 millions d'utilisateurs dans le monde a provoqué de nombreuses pannes des serveurs en 2016[98] (application en téléchargement permanent ou messages d’erreur). Cet écueil technique n'est nullement insoluble, mais difficile à régler dans l’urgence : l’incapacité des datacenters traditionnels à répondre à une demande inédite devenue trop forte.
Pokémon GO reproduit un environnement de l’Internet des objets (IoT) où de nombreux appareils transmettent des données à un site central. Les exigences de performance soulignées par l’application phénomène sont ainsi très comparables aux enjeux plus sérieux, qui attendent, demain, les fabricants d’objets connectés et les nombreux autres acteurs de l’économie numériques.
La réponse la plus adaptée aux problèmes de latence (délai entre le moment où une information est envoyée et celui où elle est reçue) ou de saturation des réseaux, est apportée aujourd’hui par le Edge Computing, qui se définit comme la mise à disposition de "ressources informatiques proches de l’utilisateur final ou de la source de données ".
Un serveur près de chez vous : Plusieurs micro- datacenters installés dans le pays pourraient par exemple prendre en charge les messages transmis aux joueurs, les statistiques et les scores. Ce n’est que de manière ponctuelle qu’il leur faudrait envoyer des données à un datacenters "central", et uniquement des données choisies. Pareille configuration permettrait de réduire la latence mais également le besoin en bande passante, de chaque aller-retour de manière significative. Les données ne seraient plus transmises du téléphone de tel utilisateur à un datacenters situé à quelques centaines de kilomètres, mais à un micro datacenters situé à proximité.
Ainsi, plus de Cloud en surcharge, plus de serveurs en panne ! Le Edge Computing va véritablement changer la donne en permettant de gérer le flux d’informations reçues et transmises aux utilisateurs. Il semble souhaitable que cette approche trouve rapidement un écho auprès des décideurs pour que soient implémentées les infrastructures "micro-dc" permettant aux quelque vingt milliards d’objets connectés en 2020 (source Gartner), de mieux fonctionner, afin que les applications innovantes portées par le développement des technologies puissent susciter plus d’engouement que de frustration dans les années à venir.
Vers des datacenters moins énergivores pour gagner en fiabilité
Les data centers font aujourd’hui partie des bâtiments les plus énergivores dans le monde[99]. En 2016, ces derniers ont représenté 5 % de la consommation mondiale d’électricité et exploité pas moins de 626 milliards de litres d’eau. L’un dans l’autre, ils ont été tenus responsables pour environ 3 % des émissions de gaz à effet de serre.
Les clés du refroidissement des datacenters confiées à des algorithmes
Google profite des avancées de Deepmind dans l'Intelligence artificielle pour gérer très finement la consommation électrique et le refroidissement de ses centres de données, et piloter automatiquement la dissipation thermique des immenses fermes de serveurs qu'il exploite, ceci de façon autonome, sans assistance humaine[100].
Le principe est de faire travailler l'outil sur des instantanés périodiques du système de refroidissement du centre de données. Toutes les cinq minutes, un « cliché » du système est pris, à partir de milliers de capteurs, puis envoyé dans le Cloud de l’entreprise. De là, il est traité par des algorithmes qui reposent sur des réseaux neuronaux profonds, la grande spécialité de DeepMind, qui ont été au cœur de ses multiples percées.
Google dit ainsi avoir obtenu des économies d’énergie de 30 % après seulement quelques mois d'exploitation du mécanisme.
Refroidissement d'un datacenters, façon "Vingt mille lieues sous les mers"
Le français Naval Group apporte son savoir-faire de marinier à Microsoft pour développer et déployer un datacenters sous-marin de présérie[101] ; Microsoft Research poursuit son projet Natick en partenariat avec Naval Group pour tester les performances d'un centre de données placé sous l'eau[102]. Objectifs de ce datacenters immergé : diminuer drastiquement les besoins en refroidissement, qui représentent les principaux coûts énergétiques, permettre une construction plus rapide, et bénéficier d'un accès privilégié aux énergies renouvelables et des durées de latence réduites, la moitié de la population mondiale vivant à moins de 200 kilomètres d'une côte.
Immersion dans des cuves remplies d'un fluide ICE (Immersion Coolant for Electronics)
À l’occasion du salon Viva Technology en mai 2019, la start-up Immersion 4 a présenté sa solution visant à placer les data center dans un système DTM (Dynamic Thermal Management)[103]. Dans les faits, ces cuves remplies d'un fluide ICE (Immersion Coolant for Electronics) sont capables de réduire drastiquement leur empreinte énergétique. "Il s’agit d’une nouvelle génération d'huile diélectrique 100 % synthétique, qui circule grâce à un dispositif que nous avons spécialement développé, baptisé FlowHT et qui facilite la récupération calorifique. Les systèmes DTM permettent a l’électronique immergée de fonctionner en permanence au maximum de la puissance, voire d'augmenter la vitesse d’horloge [aussi appelée overclocking] sans pour autant avoir la dépense énergétique normalement associée lorsqu’elle est refroidie par l'air.
La technologie des datacenters repensée, pour plus d'efficacité et de sécurité, aux forts enjeux économiques...
Forum Teratec - Juin 2019 : quatre innovations pour accélérer sur le calcul à haute performance ( HPC)
Avec des données en augmentation constante — on parle "d'explosion de la donnée" —, l'enjeu est désormais de bien savoir gérer ce flot d'informations. Pour répondre à cette problématique, Aldwin-Aneo, Atos, Activeeon et Ucit ont présenté leurs projets dans le domaine du Superordinateur[104].
- Tester des milliers de molécules : Aldwin-Aneo permet d'accélérer le développement d’un nouveau médicament, particulièrement au moment du docking. Ce processus consiste à tester la compatibilité des molécules en fonction des combinaisons spatiales de celles-ci. L’entreprise serait capable de faire passer la durée d'un docking de 68 ans à une heure seulement grâce à la modélisation 3D, qui permet d'observer en temps réel la dynamique de la molécule, ainsi qu'au cloud computing. Cette méthode permet de réduire significativement le temps d'acquisition des résultats tout en améliorant l'expérience utilisateur.
- Un chef d'orchestre pour la donnée : Activeeon, société spécialisée dans la planification de tâches et l'orchestration pour toutes les infrastructures, prend aussi en charge la gestion et l'automatisation d'applications comme de services complexes, multi-VM et multi-clouds. En partenariat avec l’Inria, la société a annoncé en mars 2019 une accélération conséquente de l'analyse métagénomique. En effet la société permet de traiter simultanément un nombre d’échantillons pouvant atteindre et même dépasser plusieurs milliers d’unités en répartissant la donnée entre 1 000 CPU (Central Processing Unit).
- Comprendre l'utilisation des clusters : Ucit a pour ambition de démocratiser et de simplifier le calcul à haute performance. À l'occasion du Forum Teratec, la société a dévoilé en avant-première le logiciel Analyze-IT, qui analyse les logs des clusters. Ces données sont relatives à leur utilisation afin de comprendre les usages, les comportements des utilisateurs et faire évoluer les structures en conséquence. Une fois les indicateurs analysés, les équipes accompagnent les clients pour optimiser leur utilisation en identifiant les ressources et capacités nécessaires dans le futur, par exemple pour le passage vers l'hybride Superordinateur et le Cloud.
- Simulation des programmes quantiques : Atos a présenté le programme myQLM, lancé le 16 mai 2019. Ce projet permet de démocratiser la programmation quantique en fournissant un écosystème de simulation. Il serait alors possible de simuler des programmes sur le poste de travail personnel, sans ordinateurs quantique, permettant ainsi aux professionnels mais aussi aux étudiants de se familiariser avec cette technologie. L'environnement Python permettra d’utiliser les langages AQASM (Atos Quantum Assembler) et pyAQASM pour tester les développements. Atos assure également l'interopérabilité avec d'autres solutions de calcul quantique en fournissant des traducteurs open source de myQLM vers d'autres environnements de programmation quantique.
Le développement de processeurs plus performants
Amazon Web Services (AWS) aurait développé en 2019, une seconde génération de processeurs pour ses datacenters. Toujours basée sur l’architecture ARM, elle serait 20 % plus performante que le premier modèle, Graviton, la première génération de puce spécialisé sortie en 2018[105].
Cette nouvelle génération permettrait aussi aux puces de s'interconnecter pour accélérer le traitement de certaines tâches comme la reconnaissance d’images.
Les processeurs basés sur l'architecture ARM sont moins puissants que ceux d'Intel et AMD, qui utilisent l'architecture x86, mais ils sont aussi moins gourmands en énergie et beaucoup moins chers à produire. Cela représente au bas mot une différence de plusieurs milliers d'euros par serveur.
L'enjeu pour le géant du Cloud serait de réduire sa dépendance vis-à-vis d'Intel.
Intel se muscle dans l'Intelligence artificielle en s'emparant d'Habana Labs pour 2 milliards de dollars
Fin 2019, Intel s'empare de la start-up israélienne Habana Labs, spécialisée dans les accélérateurs d'apprentissage profond programmable destinés aux datacenters, pour 2 milliards de dollars[106].
Habana commercialise Goya, un processeurs d'interférence qui propose un débit et des temps de latence en temps réel, et qui est très compétitif au niveau de l'énergie, selon Intel. L'Israélien développe aussi Gaudi, un processeurs programmable destiné à l'IA pour les datacenters. Habana espère que ce processeurs Gaudi, qui est doté d'un grand nombre de nœuds, augmente jusqu'à 4 fois le débit d'entrée et de sortie par rapport aux systèmes ayant un nombre équivalent de GPU.
Les ambitions de Lenovo
L’ambition du géant chinois dans ce monde qui change est de devenir l’acteur numéro un du monde des datacenters, et sa stratégie est simple : combiner son héritage d'excellence venu d'IBM avec son héritage chinois qui lui permet de mieux réduire les coûts[107].
L’activité serveurs x86 d’IBM a été créée il y a 25 ans, Lenovo est donc déjà très bien implanté. L'entreprise possède aussi 7 centres de recherche sur les datacenters, et 5 usines de fabrication à travers le monde ; elle déclare fabriquer plus de 100 serveurs par heure à Shenzhen.
Pour répondre aux exigences de ces clients très particuliers, Lenovo lance deux nouvelles marques : ThinkAgile et ThinkSystem. ThinkSystem est une architecture matérielle personnalisée, des serveurs complètement customisés suivant les besoins de ses clients. Lenovo peut se charger de l’installation sur site, soit directement soit via des partenaires. Une solution aux besoins de plus en plus spécifiques des Google et autres Facebook, qui conçoivent leur matériel eux-mêmes.
Articles connexes
- Gestion des incidents
- ITIL
- ISO/CEI 20000
- ISO/IEC 27001
- ISO 31000
- Gestion énergétique des centres de calcul
- Recherche approfondie sur l’origine du mot "bug"[108] - [109] - [110] - [111].
Références
- La Disponibilité : Un critère déterminant dans le choix d'un hébergement Cloud
- Data center : bienvenue dans les usines à données
- ITIL FRANCE
- (en) « Expectation for Computer Security Incident Response », Request for comments no 2350.
- CERT France 2019
- National Institute of Standards and Technology
- Computer SecurityIncident Handling Guide
- SANS Institute
- ENSI
- Good Practice Guide for Incident Management
- Carnegie Mellon University
- Defining Incident Management Processes for CSIRTs
- ISO 27035
- Central Computer and Telecommunications Agency
- ITIL France
- Increasing Information Systems Availabiliy Through Accuracy, Awareness, Completeness and Manageability of ITSM.
- ITIL France
- Gestion des évènements ITIL ITIL dans le cloud
- ITIL : Renaissance ou dernier soupir
- Agile et ITIL ITIL 4 : l’avènement de l’IT Service Management Agile
- Lean manufacturing: a process for all seasons.
- DevOps : l'évolution naturelle de l'agilité et du 'lean IT'
- Incorporation of Good Practices in the Development and Deployment of Applications through Alignment of ITIL and Devops
- ITIL et DATA CENTERS
- Glossaire ITIL ITIL
- Gestion des incidents : Processus ITIL
- Implementation of the Service Center according to best practices recommended by ITIL
- ITIL : Renaissance ou dernier soupir
- Service Management for the digital edge
- TOGAF The Open Group Architecture Framework
- ITIL : Agile et ITIL 4 : l’avènement de l’IT Service Management Agile
- Risk and Data Center Planning, p. 8
- BULL Chorus
- Guide PCA
- DUMAS Thomas Tellier
- Uptime Institute
- Publicly Reported Outages 2018-19
- 8th annual Data Center Survey
- Publicly Reported Outages 2018-19, p. 3
- A systematic survey of public lcoud outage
- Publicly Reported Outages 2018-19, p. 4
- Risk and Data Center Planning
- Publicly Reported Outages 2018-19, p. 5
- Cost of Data Center Outages
- Ponemon Institute
- Google Cloud Whitepaper Data incident response process
- Google Cloud Whitepaper Data incident response process, p. 8
- Google Cloud Whitepaper Data incident response process, p. 9
- Google Cloud Whitepaper Data incident response process, p. 10
- Google Cloud Whitepaper Data incident response process, p. 11
- Google Cloud Whitepaper Data incident response process, p. 12
- Processus de gestion des incidents liés aux données
- Amazon Web Services
- Cloud Adoption Framework, p. 5
- AWS CloudWatch, p. 9
- AWS CloudWatch, p. 12
- AWS Auto Scaling
- Top 7 pannes 2019
- Problems at Amazon Web Services
- Amazon AWS Outage Shows Data in the Cloud is Not Always Safe
- Cloudflare outage
- Google Cloud Networking Incident #19016
- Google Compute Engine Incident #19008
- Salesforce
- Maillage de l'infrastructure Internet en France
- Travaux OVHcloud Fibre
- retour expérience OVH
- PDG OVH
- Travaux OVH
- Travaux OVH EMC
- Agence de l'Environnement et de la Maîtrise de l'Énergie
- L’impact spatial et énergétique des data center sur les territoires
- Best Practices for Sustainable Datacenters
- Energie consommée par les data centers
- Cloudscene
- Orange - Construction d'un data center Val de Reuil
- DGA VDR
- Data Center EDF
- Directive SEVESO
- Prometheus
- Vivement le datacenter datacenters autonome, parce que vous avez déjà assez de problèmes à gérer…
- Cloud hybride : qu’est-ce que c’est et à quoi ça sert
- An Introduction to Matlab BT - Numerical Methods
- Gartner
- Cloud computing : la lourde tendance 2020, le "Serverless architecture serveless" progresse
- AMAZON WEB SERVICES Lambda
- AZURE
- Study on engineering cost estimation based on chaos theory and cost-significant theory
- NETFLIX CHAOS
- AWS CHAOS
- AWS CHAOS GameDay
- Inside Azure Search: Chaos Engineering
- L'ingénierie du chaos chez OUI.sncf
- Research on characteristics of chaos in enterprise strategic system and chaos management
- Security Chaos Engineering for Cloud Services: Work In Progress
- Project Silica : Pour Microsoft, le futur du stockage de données est... un morceau de verre
- AG2R La Mondiale se convertit au stockage de données à mémoire (informatique) mémoire flash
- Le phénomène Pokémon GO révèle nos besoins en datacenter datacenters de proximité
- Energie consommée par les data centers
- IA : Google confie les clés du Méthodes de refroidissement pour ordinateur et refroidissement de ses datacenter datacenters à ses algorithmes
- Comment Naval Group aide Microsoft à créer et déployer un datacenter datacenters sous-marin
- Microsoft poursuit son projet fou de data center sous-marin avec Naval Group
- La start-up Immersion 4 rafraîchit les data centers… et veut réutiliser l’énergie qu’ils dégagent
- Quatre innovations pour accélérer sur le calcul à haute performance (Superordinateur)
- AWS développerait un nouveau processeur , processeurs ARM et ARM (société) 20% plus performant pour ses datacenter datacenters
- Intel se muscle dans l'Intelligence artificielle en s'emparant d'Habana Labs pour 2 milliards de dollars
- Cloud, Superordinateur, Intelligence artificielle... Lenovo fait une démonstration de force dans les serveurs
- Grace Hopper
- L'origine du terme Bug
- Télégraphe Vibroplex
- Thomas Edison
Bibliographie
- (en) J. Andreeva, P. Beche, S. Belov, I. Dzhunov et I. Kadochnikov, « Processing of the WLCG monitoring data using NoSQL », Journal of Physics, vol. 513, , p. 36-43 (ISSN 1742-6588, DOI 10.1088/1742-6596/513/3/032048)
- (en) K. Dahbur, B. Mohammad, A. Tarakji et A. Bisher, « A survey of risks, threats and vulnerabilities in cloud computing », ACM Press, , p. 1-6 (DOI 10.1145/1980822.1980834)
- (en) O. Burton, « American Digital History », Social Science Computer Review, vol. 23, , p. 206-220 (ISSN 0894-4393, DOI 10.1177/0894439304273317)
- (en) T. Antoni, D. Bosio et M. Dimou, « WLCG-specific special features in GGUS », Journal of Physics: Conference Series, vol. 219, , p. 062032 (ISSN 1742-6596, DOI 10.1088/1742-6596/219/6/062032)
- (en) J. Molina-Perez, D. Bonacorsi, O. Gutsche, A. Sciabà et J. Flix, « Monitoring techniques and alarm procedures for CMS Services and Sites in WLCG », Journal of Physics: Conference Series, vol. 396, no 4, , p. 042041 (ISSN 1742-6588, DOI 10.1088/1742-6596/396/4/042041)
- (en) P. Saiz, A. Aimar, J. Andreeva, M. Babik et L. Cons, « WLCG Monitoring Consolidation and further evolution », Journal of Physics: Conference Series, vol. 664, no 6, , p. 062054 (ISSN 1742-6588, DOI 10.1088/1742-6596/664/6/062054)
- (en) B. Campana, A. Brown, D. Bonacorsi, V. Capone et D De. Girolamo, « Deployment of a WLCG network monitoring infrastructure based on the perfSONAR-PS technology », Journal of Physics: Conference Series, vol. 512, no 6, , p. 062008 (ISSN 1742-6588, DOI 10.1088/1742-6596/513/6/062008)
- (en) H. Marten et T. Koening, « ITIL and Grid services at GridKa », Journal of Physics: Conference Series, vol. 219, no 6, , p. 062008 (ISSN 1742-6596, DOI 10.1088/1742-6596/513/6/062008)
- (en) J. Shiers, « Lessons learnt from WLCG service deployment », Journal of Physics: Conference Series, vol. 119, no 5, , p. 052030 (ISSN 1742-6596, DOI 10.1088/1742-6596/119/5/052030)
- (en) Z. Toteva, R Alvarez. Alonso, E Alvarez. Granda, M-E. Cheimariou et I. Fedorko, « Service management at CERN with Service-Now », Journal of Physics: Conference Series, vol. 396, no 6, , p. 062022 (ISSN 1742-6588, DOI 10.1088/1742-6596/396/6/062022)
- (en) C. Magherusan-Stanciu, A. Sebestyen-Pal, E. Cebuc, G. Sebestyen-Pal et V. Dadarlat, « Grid System Installation, Management and Monitoring Application », 2011 10th International Symposium on Parallel and Distributed Computing, , p. 25-32 (DOI 10.1109/ISPDC.2011.14)
- M. Fairouz, « Le calcul scientifique des expériences LHC - Une grille de production mondiale », Reflets de la physique, , p. 11-15 (ISSN 1953-793X, DOI 10.1051/refdp/2010016)
- (en) Rafael de Jesus. Martins, Luis Augusto Dias. Knob, Eduardo Germano. da Silva, Juliano Araujo. Wickboldt, Alberto. Schaeffer-Filho et Lisandro Zambenedetti. Granville, « Specialized CSIRT for Incident Response Management in Smart Grids », Journal of Network and Systems Management, , p. 269-285 (ISSN 1064-7570, DOI 10.1007/s10922-018-9458-z)
- (en) R. Trifonov, S. Yoshinov, S. Manolov, G. Tsochev et G. Pavlova, « Artificial Intelligence methods suitable for Incident Handling Automation », MATEC Web of Conferences, vol. 292, , p. 01044 (ISSN 2261-236X, DOI 10.1051/matecconf/201929201044)
- M. Hubert, « L'informatique en France de la seconde Guerre Mondiale au Plan Calcul. », Revue d'anthropologie des connaissances, vol. 5, 1, no 1, , p. 155 (ISSN 1760-5393, DOI 10.3917/rac.012.0155)
- (en) J. Andreeva, D. Dieguez Arias, S. Campana, J. Flix et O. Keeble, « Providing global WLCG transfer monitoring », Journal of Physics: Conference Series, vol. 396, no 3, , p. 032005 (ISSN 1742-6588, DOI 10.1088/1742-6596/396/3/032005)
- (en) J. Sigarch, D. Dieguez Arias, S. Campana, J. Flix et O. Keeble, « High Performance Computing, Networking, Storage and Analysis (SC) », Institute of Electrical and Electronics Engineers, (ISBN 9781450307710)
- (en) N. Simakov, J. White, R. DeLeon, A. Ghadersohi et T. Furlani, « Application kernels: HPC resources performance monitoring and variance analysis », Concurrency and Computation: Practice and Experience, vol. 27, no 17, , p. 5238-5260 (DOI 10.1002/cpe.3564)
- (en) J. Palmer, S. Gallo, T. Furlani, M. Jones et R. DeLeon, « Open XDMoD: A Tool for the Comprehensive Management of High-Performance Computing Resources », Computing in Science & Engineering, vol. 17, no 4, , p. 52-62 (ISSN 1521-9615, DOI 10.1109/MCSE.2015.68)
- (en) T. Furlani, M. Jones, S. Gallo, A. Bruno et CD. Lu, « Performance metrics and auditing framework using application kernels for high-performance computer systems », Concurrency and Computation: Practice and Experience, vol. 25, no 7, , p. 918-931 (DOI 10.1002/cpe.2871)
- (en) M. Wiboonrat, « Data center infrastructure management WLAN networks for monitoring and controlling systems », The International Conference on Information Networking 2014, , p. 226-231 (DOI 10.1109/ICOIN.2014.6799696)
- (en) Z. Li, M. Liang, L. O'Brien et H. Zhang, « The Cloud's Cloudy Moment: A Systematic Survey of Public Cloud Service Outage », International Journal of Cloud Computing and Services Science, (DOI 10.11591/closer.v2i5.5125)
- (en) K. Dahbur, B. Mohammad et A. Tarakji, « A survey of risks, threats and vulnerabilities in cloud computing », International Conference on Intelligent Semantic Web-Services and Applications, , p. 1-6 (ISBN 9781450304740, DOI 10.1145/1980822.1980834)
- (en) JG. Lou, Q. Lin, R. Ding, Q. Fu, D. Zhang et T. Xie, « Software analytics for incident management of online services: An experience report », IEEE/ACM International Conference on Automated Software, , p. 475-485 (DOI 10.1109/ASE.2013.6693105)
- (en) V. Munteanu, A. Edmonds, T. Bohnert et T. Fortiş, « Cloud incident management, challenges, research directions, and architectural approach », IEEE/ACM 7th International Conference on Utility and Cloud Computing, , p. 786-791 (ISBN 9781479978816, DOI 10.1109/UCC.2014.128)
- (en) E. Karakoc et F. Dikbiyik, « Rapid migration of VMs on a datacenter under cyber attack over optical infrastructure », International Symposium on Smart MicroGrids, , p. 54-58 (ISBN 9781509037841, DOI 10.1109/HONET.2016.7753450)
- (en) A. Herrera et L. Janczewski, « Cloud supply chain resilience », Information Security for South Africa - Proceedings of the ISSA 2015 Conference, , p. 54-58 (ISBN 9781479977550, DOI 10.1109/ISSA.2015.7335076)
- (en) H. Liu, X. Wu, M. Zhang, L. Yuan, R. Wattenhofer et D. Maltz, « zUpdate: Updating data center networks with zero loss », SIGCOMM 2013 - Proceedings of the ACM, , p. 411-422 (ISBN 9781450320566, DOI 10.1145/2486001.2486005)
- (en) G. Carnino et C. Marquet, « Les datacenters enfoncent le cloud : enjeux politiques et impacts environnementaux d’internet », Zilsel, vol. 3, no 1, , p. 19 (ISSN 2551-8313, DOI 10.3917/zil.003.0019)
- (en) X. Wu, D. Turner, CC. Chen, D. Maltz, X. Yang, L. Yuan et M. Zhang, « NetPilot », ACM SIGCOMM 2012 conference, , p. 419 (ISBN 9781450314190, DOI 10.1145/2342356.2342438)
- (en) J. Maza, T. Xu, K. Veeraraghavan et O. Multu, « A Large Scale Study of Data Center Network Reliability », ACM Press, , p. 393-407 (ISBN 9781450356190, DOI 10.1145/3278532.3278566)
- (en) N. Shelly, B. Tschaen, KT. Forster, M. Chang, T. Benson et L. Vanbever, « Destroying networks for fun (and profit) », ACM Press, , p. 1-7 (ISBN 9781450340472, DOI 10.1145/2834050.2834099)
- (en) A. Prazeres et E. Lopes, « Disaster Recovery – A Project Planning Case Study in Portugal », Procedia Technology, vol. 9, , p. 795-805 (ISSN 2212-0173, DOI 10.1016/J.PROTCY.2013.12.088)
- (en) A. TaherMonfared et MG. TurnerJaatun, « Handling compromised components in an IaaS cloud installation », Journal of Cloud Computing, vol. 1, no 1, , p. 16 (ISSN 2192-113X, DOI 10.1186/2192-113X-1-16)
- (en) V. Munteanu, A. EDmonds, TM. Bohnert et TF. Fortis, « Cloud Incident Management, Challenges, Research Directions, and Architectural Approach », ACM International Conference on Utility and Cloud Computing, , p. 786-791 (ISBN 978-1-4799-7881-6, DOI 10.1109/UCC.2014.128)
- (en) X. Wu, BK. Raju et G. Geethakumari, « A novel approach for incident response in cloud using forensics », ACM India Computing Conference, , p. 1-6 (ISBN 9781605588148, DOI 10.1145/2675744.2675766)
- (en) D. Perez-Palacin et J. Merseguer, « Performance Evaluation of Self-reconfigurable Service-oriented Software With Stochastic Petri Nets », Electronic Notes in Theoretical Computer Science, vol. 261, , p. 181-201 (DOI 10.1016/j.entcs.2010.01.012)
- (en) A. Fox, E. Kiciman et D. Patterson, « Combining statistical monitoring and predictable recovery for self-management », ACM Press, , p. 49-53 (ISBN 1581139896, DOI 10.1145/1075405.1075415)
- (en) J. Villamayor, D. Rexachs, E. Luque et D. Lugones, « RaaS: Resilience as a Service », ACM International Symposium, , p. 356-359 (ISBN 978-1-5386-5815-4, DOI 10.1109/CCGRID.2018.00055)
- (en) H. Kurra, Y. Al-Nashif et S. Hariri, « Resilient cloud data storage services », ACM Cloud and Autonomic Computing Conference, , p. 1 (ISBN 9781450321723, DOI 10.1145/2494621.2494634)
- (en) H. Gunawi, M. Hao, RO. Suminto, A. Aksono, AD. Satria, J. Adityatame et KJ. Eliazar, « Why Does the Cloud Stop Computing? », ACM Symposium on Cloud Computing, , p. 1-16 (ISBN 9781450345255, DOI 10.1145/2987550.2987583)
- (en) X. Wu, D. Turner, CC. Chen, D. Maltz, X. Yang, L. Yuan et M. Zhang, « Power attack defense », ACM Press, vol. 44, no 3, , p. 493-505 (DOI 10.1145/3007787.3001189)
- (en) P. Huang, C. Guo, L. Zhou, JR. Lorch, y. Dang, M. Chintalapati et R. Yao, « Gray Failure - The Achilles' Heel of Cloud-Scale Systems », ACM Digital Library, vol. 292, , p. 150-155 (ISBN 9781450350686, DOI 10.1145/3102980.3103005)
- (en) HS. Gunawi, C. McCaffrey, D. Srinivasan, B. Panda, A. Baptist, G. Grider, PM. Fields, K. Harms, RB. Ross et A. Jacobson, « Fail-Slow at Scale », ACM Transactions on Storage, vol. 14, no 3, , p. 1-26 (DOI 10.1145/3242086)
- (en) P. Cichonski, T. Millar, T. Grance, M. Chang et K. Scarfone, « Computer SecurityIncident Handling Guide », National Institute of Standards and Technology Special Publication, , p. 1-79 (DOI 10.6028/NIST.SP.800-61r2)
- (en) U. Franke, « Optimal IT Service Availability: Shorter Outages, or Fewer? », IEEE, vol. 9, no 1, , p. 22-33 (ISSN 1932-4537, DOI 10.1109/TNSM.2011.110811.110122)
- (en) J. Cusick et G. Ma, « Creating an ITIL inspired Incident Management approach: Roots, response, and results », IEEE / IFIP, , p. 142-148 (DOI 10.1109/NOMSW.2010.5486589)
- (en) A. Greenberg, J. Hamilton, D. Maltz et P. Patel, « The cost of a cloud », ACM, vol. 39, no 1, , p. 68 (DOI 10.1145/1496091.1496103)
- (en) C. Cao et Z. Zhan, « Incident management process for the cloud computing environments », IEEE, , p. 225-229 (DOI 10.1109/CCIS.2011.6045064)
- Pascal Grosjean et Médéric Morel, « Performance des architectures IT Ressource électronique : Comprendre, résoudre et anticiper », Dunod, (ISBN 978-2-10-056252-7)
- (en) G. Lindfield et J. Penny, « An Introduction to Matlab BT - Numerical Methods », Academic Press, no 3, , p. 1-66 (ISBN 9780123869883, DOI 10.1016/B978-0-12-386942-5.0000)
- (en) V. Dinesh Reddy, Brian Setz, G. Subrahmanya, G.R. Gangadharan et Marco Aiello, « Best Practices for Sustainable Datacenters », IT Professional, vol. 20, , p. 57-67 (ISSN 1941-045X, DOI 10.1109/MITP.2018.053891338)
- (en) Alberto Belalcázar Belalcázar, « Incorporation of Good Practices in the Development and Deployment of Applications through Alignment of ITIL and Devops », IEEE, (ISBN 978-1-5386-2645-0, DOI 10.1109/INCISCOS.2017.31)INSPEC Accession Number: 17661490
- (en) P. Juliard, « Lean manufacturing: a process for all seasons », IEEE, (ISBN 0-7803-3959-2, DOI 10.1109/EEIC.1997.651323)Conference Location: Rosemont, IL, USA, USA
- (en) « Implementation of the Service Center according to best practices recommended by ITIL », IEEE, vol. 16, no 6, , p. 1809 - 1816 (ISSN 1548-0992, DOI 10.1109/TLA.2018.8444403)
- (en) Sergio Varga, Gilmar Barreto et Paulo D. Battaglin, « Increasing Information Systems Availabiliy Through Accuracy, Awareness, Completeness and Manageability of ITSM », IEEE, (ISSN 2166-0727, DOI 10.23919/CISTI.2019.8760686)
- (en) Duan Xiao-chen, Liu Jing-yan et Di Jie, « Study on engineering cost estimation based on chaos theory and cost-significant theory », IEEE, (ISBN 978-1-4244-4247-8, DOI 10.1109/CCCM.2009.5267688)Conference Location: Sanya, China
- (en) Kennedy A. Torkura, Sukmana Muhammad I.H., Feng Cheng et Meinel Christoph, « Security Chaos Engineering for Cloud Services: Work In Progress », IEEE, (ISSN 2643-7929, DOI 10.1109/NCA.2019.8935046)Conference Location: Cambridge, MA, USA, USA
- (en) Hao Zhang et Zhang Tie-nan, « Research on characteristics of chaos in enterprise strategic system and chaos management », IEEE, (ISSN 2155-1847, DOI 10.1109/ICMSE.2008.4668945)Conference Location: Long Beach, CA, USA
- (en) Kurt J. Engemann et Holmes E., « Risk and Data Center Planning », Engineering and Management of Data Centers, , p. 73-89 (ISSN 1865-4924, DOI 10.1007/978-3-319-65082-1_4)
- (en) KJ. Engenmann et HE. Miller, « Risk and Data Center Planning », Engineering and Management of Data Centers. Service Science, , p. 1-21 (DOI 10.1007/978-3-319-65082-1_4)
- (en) J. Shiers, « Lessons learnt from WLCG service deployment », Journal of Physics, vol. 119, no 5, , p. 052030 (ISSN 1742-6596, DOI 10.1088/1742-6596/119/5/052030)
Liens externes
(en) « Uptime Institute » (consulté le )
(en) « ITIL Résultats », sur Uptime Institute (consulté le )
(en) « 2019 Annual Data Center Survey Results », sur Uptime Institute, (consulté le )
(en) « NASA's Ames Research Cente » (consulté le )
« Directive SEVESO » (consulté le )
(en) « Swiss National Supercomputing Centre » (consulté le )
(en) « Centre Calcul IN2P3 » (consulté le )
(en) « CNRS IN2P3 » (consulté le )
(en) « Worldwide LHC Computing Grid » (consulté le )
(en) « WLCG Service Incident Reports » (consulté le )
(en) « Institut du developpement et des ressources en informatique scientifique » (consulté le )
(en) « European Advanced Computing Services for Research » (consulté le )
(en) « European Technology Platform for HPC » (consulté le )
(en) « Journal of grid computing. », sur Springer Science+Business Media. (consulté le )
(en) « TOP500 Supercomputer Sites » (consulté le )
(en) « ANSSI Agence Nationale de la Sécurité des Système d'Information » (consulté le )
(en) « NIST National Institute of Standards and Technology » (consulté le )
(en) « Bulletin d’actualité CERTFR-2016-ACT-014 » (consulté le )
(en) « ISO 27035 Information security incident management » (consulté le )
(en) « SANS Institute » (consulté le )
(en) « ENISA European Union Agency for cybersecurity » (consulté le )
(en) « Good Practice Guide for Incident Management » (consulté le )
(en) « Carnegie Mellon University » (consulté le )
(en) « Defining Incident Management Processes for CSIRTs » (consulté le )
(en) « Publicly Reported Outages 2018-19 » (consulté le )
(en) « 8th annual Data Center Survey » (consulté le )
« ITIL France » (consulté le )
« La Disponibilité : Un critère déterminant dans le choix d'un hébergement Cloud » (consulté le )
« Data center : bienvenue dans les usines à données » (consulté le )
« ITIL : Renaissance ou dernier soupir » (consulté le )
(en) « Service Management for the digital edge » (consulté le )
(en) « TOGAF The Open Group Architecture Framework » (consulté le )
« Agile et ITIL 4 : l’avènement de l’IT Service Management Agile » (consulté le )
(en) « AWS Auto Scaling » (consulté le )
« ITIL et DATA CENTERS » (consulté le )
« APL : Avis d'expert » (consulté le )
« Gestion des incidents : Processus ITIL » (consulté le )
« Un datacenter Google frappé par la foudre » (consulté le )
« Panne de Google Cloud : le géant du web relativise l’incident » (consulté le )
« Panne de Google Cloud : les faiblesses du Cloud mises en lumière » (consulté le )
« Vérifier l'état actuel d'un service G Suite » (consulté le )
« Carte des pannes de Google » (consulté le )
« Processus de gestion des incidents liés aux données » (consulté le )
« IA : Google confie les clés du refroidissement de ses data centers à ses algorithmes » (consulté le )
« Incendie dans le datacenter : histoires vraies de PRA qui s'envolent en fumée » (consulté le )
« Guide sur le CloudComputing et les dataCenters à l’attention des collectivités locales » (consulté le )
« Comment OVH évite le coup de chaud à ses datacenters » (consulté le )
« Energie consommée par les data centers » (consulté le )
« Incidents et Google Cloud Status Dashboard » (consulté le )
« Supervision d’un data center : Organisation et méthodologie (© 2012 Amadeus IT Group SA) » (consulté le )
« Solution d'interconnexion de data centers » (consulté le )
« Google donne plus de détails sur l'incident de mise en réseau de ses services cloud » (consulté le )
« Google Cloud Status Dashboard » (consulté le )
« Pics de canicule : pourquoi les datacenters français tiennent le coup » (consulté le )
« Arrêt de Chorus : les raisons de la panne du datacenter de Bull » (consulté le )
« Pourquoi Google construit 12 nouveaux datacenters dans le monde ? » (consulté le )
« Plan de continuité informatique - Principes de base » (consulté le )
(en) « Failure Diagnosis for Datacenter Applications » (consulté le )
« Les géants d’internet et du cloud disposent de 300 datacenters dans le monde » (consulté le )
« Gestion des évènements ITIL dans le cloud » (consulté le )
« AMS exploite l’infrastructure AWS en faveur de clients d’entreprises et de partenaires » (consulté le )
« AWS développerait un nouveau processeur ARM 20% plus performant pour ses data centers » (consulté le )
« Le calcul scientifique des expériences LHC - Résumé » (consulté le )
« DGA VDR » (consulté le )
« Le calcul scientifique des expériences LHC - Une grille de production mondiale » (consulté le )
« Travaux OVH » (consulté le )
« retour expérience OVH » (consulté le )
« Amazon passe à la vitesse supérieure dans la création des puces de son cloud » (consulté le )
« Cloud computing : la lourde tendance 2020, le "serverless" progresse » (consulté le )
« L’impact spatial et énergétique des data center sur les territoires » (consulté le )
« Orange - Construction d'un data center Val de Reuil » (consulté le )
« Evaluation of Incident Detection Methodologies » (consulté le )
« L’intelligence artificielle est "dans l’impasse" » (consulté le )
« Livre blanc : Approches contemporaines en hébergement et gestion de données » (consulté le )
(en) « Software analytics for incident management of online services : an experience report » (consulté le )
« Microsoft Cloud Infrastructure » (consulté le )
(en) « Inside a Google data center » (consulté le )
« Intel se muscle dans l'intelligence artificielle en s'emparant d'Habana Labs pour 2 milliards de dollars » (consulté le )
« Project Silica : Pour Microsoft, le futur du stockage de données est... un morceau de verre » (consulté le )
« Plus de 500 méga datacenters opérés par les géants d’internet et du cloud » (consulté le )
« Avec 3 milliards d’euros investis dans ses data centers européens, Google se pose en champion de la greentech » (consulté le )
« Quatre innovations pour accélérer sur le calcul à haute performance (HPC) » (consulté le )
« La start-up Immersion 4 rafraîchit les data centers… et veut réutiliser l’énergie qu’ils dégagent » (consulté le )
« Vivement le datacenter autonome, parce que vous avez déjà assez de problèmes à gérer… » (consulté le )
« Comment Naval Group aide Microsoft à créer et déployer un datacenter sous-marin » (consulté le )
« Microsoft poursuit son projet fou de data center sous-marin avec Naval Group » (consulté le )
« Cloud, HPC, intelligence artificielle... Lenovo fait une démonstration de force dans les serveurs » (consulté le )
« AG2R La Mondiale se convertit au stockage de données à mémoires flash » (consulté le )
Maillage de l'infrastructure Internet en France
« Le phénomène Pokémon GO révèle nos besoins en datacenters de proximité » (consulté le )
« Data Center Research : actualités des data center » (consulté le )
« L'origine du terme Bug » (consulté le )
(en) « Google Cloud Networking Incident #19009 » (consulté le )
« Une panne du cloud d’Amazon met en panique tout l’internet mondial » (consulté le )
« Top 7 pannes 2019 » (consulté le )
« Thomas Edison » (consulté le )
(en) « Ponemon Institute » (consulté le )
(en) « Cost of Data Center Outages » (consulté le )
« Cloud hybride : qu’est-ce que c’est et à quoi ça sert » (consulté le )
« Agence de l'Environnement et de la Maîtrise de l'Énergie » (consulté le )
« AMAZON WEB SERVICES Lambda » (consulté le )
« AWS CHAOS GameDay » (consulté le )
« AWS CHAOS » (consulté le )
« AZURE » (consulté le )
« Infoq » (consulté le )
« Travaux OVH Fibre » (consulté le )
« Travaux OVH EMC » (consulté le )
« Gartner » (consulté le )
« Guide PCA » (consulté le )
« BULL Chorus » (consulté le )
« Prometheus » (consulté le )
« Agile et ITIL 4 : l’avènement de l’IT Service Management Agile » (consulté le )
« cloudflare outage » (consulté le )
(en) « Google Cloud Whitepaper Data incident response process » (consulté le )