Dérivation automatique
En mathématique et en calcul formel, la dérivation automatique (DA), également appelé dérivation algorithmique, dérivation formelle[1] - [2], ou auto-dérivation est un ensemble de techniques d'évaluation de la dérivée d'une fonction par un programme informatique.
Généralités
La dérivation automatique exploite le fait que chaque programme informatique, aussi compliqué soit-il, exécute une séquence d'opérations arithmétiques élémentaires (addition, soustraction, multiplication, division, etc.) et des fonctions élémentaires (exp, log,sin, cos, etc.). En appliquant de façon répétée la règle de dérivation des fonctions composées (règle de la chaîne) à ces opérations, les dérivées d'ordre arbitraire peuvent être calculées automatiquement et avec autant de précision que souhaitée. De plus calculer la dérivation automatique de la fonction ne modifie son temps de calcul qu'au plus d'un petit facteur constant, rendant ces techniques très efficaces en pratique.
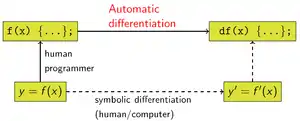
La dérivation automatique est distincte de la dérivation symbolique et de la dérivation numérique (méthode des différences finies). La dérivation symbolique peut conduire à un code inefficace et se heurte à la difficulté de convertir un programme informatique en une seule expression, tandis que la dérivation numérique peut introduire des erreurs d'arrondi lors de la discrétisation et de l'annulation. Ces deux méthodes classiques ont par ailleurs des problèmes lors du calcul de dérivées d'ordre plus élevées, car la complexité et/ou les erreurs augmentent. Enfin, ces deux méthodes sont lentes pour calculer les dérivées partielles d'une fonction lorsque cette dernière dépend de nombreuses variables, comme cela est nécessaire pour les algorithmes d'optimisation par descente de gradient. La dérivation automatique résout tous ces problèmes.
La règle de la chaîne : accumulation avant et arrière
La dérivation automatique repose fondamentalement sur la décomposition des dérivées fournie par la règle de la chaîne. Pour la composition simple

la règle de la chaîne donne alors:

Habituellement, deux modes de DA distincts sont présentés, l'accumulation directe (ou mode avant) et l'accumulation inverse (ou mode inverse). L'accumulation directe spécifie que l'on parcourt la règle de la chaîne de l'intérieur vers l'extérieur (c'est-à-dire le premier calcul et puis et enfin ), tandis que l'accumulation inverse a la traversée de l'extérieur vers l'intérieur (premier calcul et puis et enfin ). Plus succinctement,



- l'accumulation directe calcule la relation récursive: avec , et,
- l'accumulation inverse calcule la relation récursive: avec .




Accumulation directe
Lors d'une DA par accumulation directe, on fixe d'abord le variable indépendante par rapport à laquelle la dérivation est effectuée et on calcule la dérivée de chaque sous-expression récursivement. Dans un calcul papier-crayon, cela implique de substituer à plusieurs reprises la dérivée de la fonction intérieure dans la règle de chaîne :
![{\displaystyle {\begin{aligned}{\frac {\partial y}{\partial x}}&={\frac {\partial y}{\partial w_{n-1}}}{\frac {\partial w_{n-1}}{\partial x}}\\[6pt]&={\frac {\partial y}{\partial w_{n-1}}}\left({\frac {\partial w_{n-1}}{\partial w_{n-2}}}{\frac {\partial w_{n-2}}{\partial x}}\right)\\[6pt]&={\frac {\partial y}{\partial w_{n-1}}}\left({\frac {\partial w_{n-1}}{\partial w_{n-2}}}\left({\frac {\partial w_{n-2}}{\partial w_{n-3}}}{\frac {\partial w_{n-3}}{\partial x}}\right)\right)\\[6pt]&=\cdots \end{aligned}}}](https://img.franco.wiki/i/cb8633d881482245a77285d008ac3a902276c73c.svg)
Cela peut être généralisé à plusieurs variables en considérant le produit de matrices Jacobiennes. Par rapport à l'accumulation inverse, l'accumulation directe est naturelle et facile à mettre en œuvre car le flux d'information des dérivées coïncide avec l'ordre d'évaluation. Chaque variable w est augmentée de sa dérivée ẇ (stockée sous forme de valeur numérique et non d'expression symbolique),

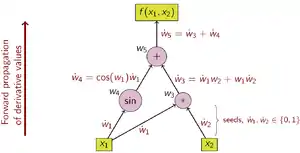
comme indiqué par le point. Les dérivées sont ensuite calculées de façon synchronisée lors des étapes d'évaluation du programme et combinées avec les autres dérivées via la règle de chaîne. À titre d'exemple, considérons la fonction:

Pour plus de clarté, les sous-expressions individuelles ont été étiquetées avec les variables wi. Le choix de la variable indépendante à laquelle la différenciation est effectuée affecte les valeurs initiales de ẇ1 et ẇ2. Si l'on s'intéresse à la dérivée de cette fonction par rapport à x1, les valeurs de départ doivent être définies par:

Une fois les valeurs de départ ainsi définies, les valeurs se propagent à l'aide de la règle de chaîne comme indiqué. La figure 2 montre une représentation picturale de ce processus sous forme de graphique de calcul.
Pour calculer le gradient de la fonction de cet exemple, il est nécessaire de calculer les dérivées de f par rapport à x1 et x2, un parcours supplémentaire est effectué sur le graphique de calcul avec les es valeurs de départ .

La complexité informatique du calcul de DA lors d'un parcours de l'accumulation directe est proportionnelle à la complexité du code d'origine.
L'accumulation directe est plus efficace que l'accumulation inverse pour les fonctions f : Rn → Rm avec m ≫ n puisque seul n parcours sont nécessaires, par rapport à m parcours pour l'accumulation inverse.
Accumulation inverse
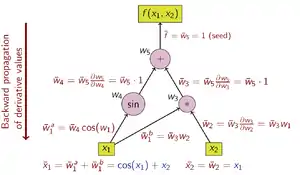
Lors d'une DA par accumulation inverse, la variable dépendante à dériver est fixe et la dérivée est calculée récursivement pour chaque sous-expression . Dans un calcul papier-crayon, la dérivée des fonctions extérieures sont substituées à plusieurs reprises dans la règle de chaîne:

Dans l'accumulation inverse, la quantité d'intérêt est l'adjoint, noté avec une barre (w̄); c'est une dérivée d'une variable dépendante choisie par rapport à une sous-expression w:

L'accumulation inverse traverse la règle de la chaîne de l'extérieur vers l'intérieur, ou dans le cas du graphique de calcul de la figure 3, de haut en bas. L'exemple de fonction est à valeur scalaire, et il n'y a donc qu'une seule graine pour le calcul de la dérivée, et un seul parcours du graphe de calcul est nécessaire pour calculer le gradient (qui a pourtant deux composantes). C'est seulement la moitié du travail par rapport à l'accumulation directe, mais l'accumulation inverse nécessite le stockage des variables intermédiaires wi ainsi que les instructions qui les ont produites dans une structure de données connue sous le nom de liste de Wengert (ou "bande")[3] - [4], ce qui peut consommer une mémoire importante si le graphe de calcul est volumineux. Cela peut être atténué dans une certaine mesure en ne stockant qu'un sous-ensemble des variables intermédiaires, puis en reconstruisant les variables de travail nécessaires en répétant les évaluations, une technique connue sous le nom de rematérialisation. Des Points de Contrôle peuvent également être utilisés pour enregistrer les états intermédiaires.
Les opérations pour calculer la dérivée en utilisant l'accumulation inverse sont présentées dans le tableau ci-dessous (notez l'ordre inversé): Le graphe de flux des données d'un calcul peut être manipulé pour calculer le gradient de son calcul d'origine. En ajoutant un nœud adjoint pour chaque nœud primaire, et en reliant par des liens adjoints parallèles aux bords primaires mais circulant dans le sens opposé. Les nœuds du graphe adjoint représentent la multiplication par les dérivées des fonctions calculées par les nœuds du primaire. Par exemple, l'addition dans le primaire provoque la sortie dans l'adjoint; la sortie dans le primaire provoque l'ajout dans l'adjoint;[note 1] a unaire fonction y = f (x) dans les causes primaires x̄ = ȳ f ′(x) dans l'adjoint; etc.
L'accumulation inverse est plus efficace que l'accumulation directe pour les fonctions f : Rn → Rm avec m ≪ n puisque seuls m parcours sont alors nécessaires (par rapport à n parcours pour l'accumulation directe).
La DA par accumulation inverse a été publiée pour la première fois en 1976 par Seppo Linnainmaa[5] - [6].
La rétropropagation des erreurs dans les perceptrons multicouches, une technique centrale dans l'apprentissage automatique, est un cas particulier de mode inverse de DA[2].
Au-delà de l'accumulation avant et arrière
Les accumulations avant et arrière ne sont que deux façons (extrêmes) de traverser la règle de la chaîne. Le problème du calcul d'un Jacobien complet de f : Rn → Rm avec un nombre minimum d'opérations arithmétiques est connu comme le problème d'accumulation optimale du Jacobien, qui est NP-complet[7]. Au cœur de cette preuve est l'idée que des dépendances algébriques peuvent exister entre les dérivées partielles locales qui étiquettent les arêtes du graphe. En particulier, deux étiquettes (ou plus) peuvent être reconnues comme égales. La complexité du problème reste ouverte si l'on suppose que toutes les étiquettes de bord sont uniques et algébriquement indépendantes.
Dérivation automatique à l'aide de nombres duaux
La dérivation automatique directe est réalisée en augmentant l'algèbre des nombres réels pour obtenir une nouvelle arithmétique. Une composante supplémentaire est ajouté à chaque nombre pour représenter la dérivée d'une fonction de ce nombre, et tous les opérateurs arithmétiques sont étendus pour l'algèbre augmentée. L'algèbre augmentée est l'algèbre des nombres duaux.
On obtient cette algèbre en remplaçant chaque nombre par le nombre , où est un nombre réel, mais est un nombre abstrait avec la propriété (un infinitésimal; voir Analyse infinitésimale fluide). En ajoutant uniquement cela, l'arithmétique régulière donne alors :






et de même pour la soustraction et la division. Maintenant, les polynôme peuvent être calculés dans cette arithmétique augmentée. Si , alors


où désigne la dérivée de en ce qui concerne son premier argument, et , (appelé la graine, ou valeur initiale), peut être choisi arbitrairement. Cette nouvelle arithmétique se compose de couples, éléments écrits , avec l'arithmétique ordinaire sur la première composante, et l'arithmétique de différenciation du premier ordre sur la deuxième composante, comme décrit ci-dessus. Étendre les résultats ci-dessus sur les polynômes à fonctions analytiques donne une liste de l'arithmétique de base et de certaines fonctions standard pour la nouvelle arithmétique:




et en général pour la fonction primitive ,


où et sont les dérivés de en ce qui concerne ses premier et deuxième arguments, respectivement.


Lorsqu'une opération arithmétique binaire de base est appliquée à des arguments mixtes - la paire et le nombre réel —le nombre réel est d'abord porté à . La dérivée d'une fonction au point est maintenant trouvé en calculant en utilisant l'arithmétique ci-dessus, ce qui donne pour résultat .







Arguments et fonctions vectoriels
Les fonctions multivariées peuvent être gérées avec les mêmes mécanismes (et la même efficacité) que les fonctions univariées en adoptant un opérateur de dérivé directionnel. Autrement dit, il suffit de calculer , la dérivée directionnelle de à dans la direction , et cela peut être calculé comme en utilisant la même arithmétique que ci-dessus. Si tous les éléments de sont désirés, alors évaluations de la fonction seront nécessaires. Notez que dans de nombreuses applications d'optimisation, la dérivée directionnelle est effectivement suffisante.








Ordre élevé et variables nombreuses
L'arithmétique ci-dessus peut être généralisée pour calculer les dérivées du second ordre (et supérieures) des fonctions multivariées. Cependant, les règles arithmétiques se compliquent rapidement: la complexité est quadratique au degré de dérivée le plus élevé. Au lieu de cela, l'algèbre tronquée des Polynôme de Taylor peut être utilisée. L'arithmétique résultante, définie sur des nombres duaux généralisés, permet un calcul efficace en utilisant des fonctions comme s'il s'agissait d'un type de données. Une fois que le polynôme de Taylor d'une fonction est connu, les dérivées sont facilement extraites.
Implémentation
La DA en mode direct est généralement implémentée par une interprétation non standard du programme dans lequel les nombres réels sont remplacés par des nombres duaux, les constantes sont remplacées par des nombres doubles avec un coefficient epsilon nul, et les primitives numériques sont remplacées pour fonctionner sur des nombres duaux. Cette interprétation non standard est généralement mise en œuvre à l'aide de l'une des deux stratégies suivantes : transformation du code source ou surcharge de l'opérateur.
Transformation du code source (TCS)
Le code source d'une fonction est remplacé par un code source généré automatiquement qui comprend des instructions de calcul des dérivées, entrelacés avec les instructions d'origine.
La transformation du code source peut être implémenté dans tous les langages de programmation, et elle rend également plus facile pour le compilateur l'optimisation du temps de compilation. Cependant, la mise en œuvre de la DA elle-même est plus difficile.
Surcharge d'opérateur (SO)
La surcharge d'opérateur est une possibilité lorsque le code source est écrit dans un langage le permettant. Les objets pour les nombres réels et les opérations mathématiques élémentaires doivent être surchargés pour répondre à l'arithmétique augmentée décrite ci-dessus. Cela ne nécessite aucun changement dans la forme ou la séquence des opérations ni dans le code source d'origine pour que la fonction soit automatiquement différenciée. Mais cela nécessite souvent des changements dans les types de données de base pour les nombres et les vecteurs afin de supporter la surcharge et implique également souvent l'insertion d'opérations de marquage spéciales.
La surcharge d'opérateur pour l'accumulation directe est facile à mettre en œuvre, mais elle est également possible pour l'accumulation inverse. Pour cette dernière cependant, les compilateurs actuels sont en retard dans l'optimisation du code par rapport à l'accumulation directe.
La surcharge d'opérateur, pour l'accumulation avant et arrière, peut être bien adaptée aux applications où les objets sont des vecteurs de nombres réels plutôt que des scalaires. En effet, la bande comprend alors des opérations vectorielles; et cela peut faciliter des implémentations efficaces sur le plan informatique où chaque opération vectorielle effectue de nombreuses opérations scalaires. Des techniques de dérivation algorithmique par adjoint vectoriel peuvent être utilisées, par exemple, pour dériver des valeurs calculées par simulation Monte-Carlo.
Des exemples d'implémentations de différenciation automatique par surcharge d'opérateurs en C++ sont disponibles dans les bibliothèques Adepte et Stan.
Notes et références
Notes
- In terms of weight matrices, the adjoint is the transpose. Addition is the covector , since and fanout is the vector since
![{\displaystyle [1\cdots 1]}](https://img.franco.wiki/i/bf45494491a9127a08ac5f529d6c2e7fa9df6bd1.svg)
![{\displaystyle [1\cdots 1]\left[{\begin{smallmatrix}x_{1}\\\vdots \\x_{n}\end{smallmatrix}}\right]=x_{1}+\cdots +x_{n},}](https://img.franco.wiki/i/7a9a62ad6b33394bb459d2a5fd08b3ed4394cfe6.svg)
![{\displaystyle \left[{\begin{smallmatrix}1\\\vdots \\1\end{smallmatrix}}\right],}](https://img.franco.wiki/i/d41449e0a185da184e5a72cfc317e2d99cbf6116.svg)
![{\displaystyle \left[{\begin{smallmatrix}1\\\vdots \\1\end{smallmatrix}}\right][x]=\left[{\begin{smallmatrix}x\\\vdots \\x\end{smallmatrix}}\right].}](https://img.franco.wiki/i/d33d5fcc124ef2bdffd63c5c21a8ac5de293d50c.svg)
Références
- Neidinger, « Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming », SIAM Review, vol. 52, no 3, , p. 545–563 (DOI 10.1137/080743627, lire en ligne)
- Baydin, Pearlmutter, Radul et Siskind, « Automatic differentiation in machine learning: a survey », Journal of Machine Learning Research, vol. 18, , p. 1–43 (lire en ligne)
- R.E. Wengert, « A simple automatic derivative evaluation program », Comm. ACM, vol. 7, no 8, , p. 463–464 (DOI 10.1145/355586.364791)
- Bartholomew-Biggs, Brown, Christianson et Dixon, « Automatic differentiation of algorithms », Journal of Computational and Applied Mathematics, vol. 124, nos 1–2, , p. 171–190 (DOI 10.1016/S0377-0427(00)00422-2, Bibcode 2000JCoAM.124..171B)
- Linnainmaa, « Taylor Expansion of the Accumulated Rounding Error », BIT Numerical Mathematics, vol. 16, no 2, , p. 146–160 (DOI 10.1007/BF01931367)
- Griewank, « Who Invented the Reverse Mode of Differentiation? », Optimization Stories, Documenta Matematica, vol. Extra Volume ISMP, , p. 389–400 (lire en ligne)
- Naumann, « Optimal Jacobian accumulation is NP-complete », Mathematical Programming, vol. 112, no 2, , p. 427–441 (DOI 10.1007/s10107-006-0042-z)
Bibliographie
- Louis B. Rall, Automatic Differentiation: Techniques and Applications, vol. 120, Springer, coll. « Lecture Notes in Computer Science », (ISBN 978-3-540-10861-0)
- Andreas Griewank et Andrea Walther, Evaluating Derivatives: Principles and Techniques of Algorithmic Differentiation, vol. 105, SIAM, coll. « Other Titles in Applied Mathematics », (ISBN 978-0-89871-659-7, lire en ligne)
- Neidinger, « Introduction to Automatic Differentiation and MATLAB Object-Oriented Programming », SIAM Review, vol. 52, no 3, , p. 545–563 (DOI 10.1137/080743627, lire en ligne, consulté le )
- Uwe Naumann, The Art of Differentiating Computer Programs, SIAM, coll. « Software-Environments-tools », (ISBN 978-1-611972-06-1)
- Marc Henrard, Algorithmic Differentiation in Finance Explained, Palgrave Macmillan, coll. « Financial Engineering Explained », (ISBN 978-3-319-53978-2)
Liens externes
- www.autodiff.org, Un "site d'entrée à tout ce que vous voulez savoir sur la différenciation automatique"
- Différenciation Automatique des Programmes OpenMP Parallèles
- Différenciation Automatique, Modèles C++ et Photogrammétrie
- Différenciation Automatique, Approche De Surcharge De L'Opérateur
- Calculez les dérivées analytiques de tout programme Fortran77, Fortran95 ou C via une interface Web Différenciation automatique des programmes Fortran
- Description et exemple de code pour la différenciation automatique en avant dans Scala
- extensions de différenciation automatique finmath-lib, Différenciation automatique pour les variables aléatoires (implémentation Java de la différenciation automatique stochastique).
- Différenciation Algorithmique Adjointe: Calibration et Théorème des Fonctions Implicites
- Article de différenciation automatique basé sur un modèle C++ et application
- Tangente Dérivés déboguables Source à Source
- , Grecs Exacts du Premier et du Second Ordre par Différenciation Algorithmique
- , Différenciation Algorithmique Adjointe d'une Application Accélérée par GPU
- , Méthodes Adjointes en Finance Informatique Support d'Outils Logiciels pour la Différenciation Algorithmiqueop