Loi de Zipf
La loi de Zipf est une observation empirique concernant la fréquence des mots dans un texte. Elle a pris le nom de son auteur, George Kingsley Zipf (1902-1950). Cette loi a d'abord été formulée par Jean-Baptiste Estoup[1] et a été par la suite démontrée à partir de formules de Shannon par Benoît Mandelbrot. Elle est parfois utilisée en dehors de ce contexte, par exemple au sujet de la taille et du nombre des villes dans chaque pays, lorsque cette loi semble mieux répondre aux chiffres que la distribution de Pareto[2].
| Loi de Zipf | |
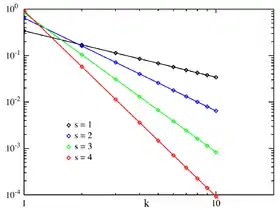 Fonction de masse pour N = 10 dans un repère log-log. L'axe horizontal est l'indice k. (La fonction est discrète, les droites de couleur n'indiquent pas de continuité.) | |
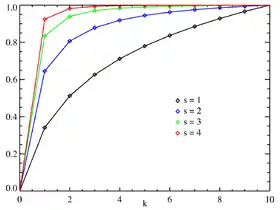 Fonction de répartition pour N = 10. L'axe horizontal est l'indice k. (la fonction est discrète, les courbes de couleur n'indiquent pas de continuité.) | |
| Paramètres | |
|---|---|
| Support | |
| Fonction de masse | |
| Fonction de répartition | |
| Espérance | |
| Mode | |
| Entropie | |
| Fonction génératrice des moments | |
| Fonction caractéristique | |










Genèse
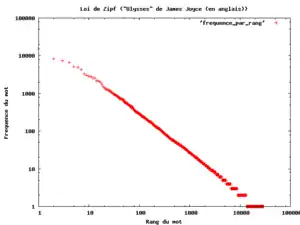
Zipf avait entrepris d'analyser une œuvre monumentale de James Joyce, Ulysse, d'en compter les mots distincts et de les présenter par ordre décroissant du nombre d'occurrences. La légende dit que :
- le mot le plus courant revenait 8 000 fois ;
- le dixième mot 800 fois ;
- le centième, 80 fois ;
- et le millième, 8 fois.
Ces résultats semblent, à la lumière d'autres études que l'on peut faire en quelques minutes sur son ordinateur, un peu trop précis pour être parfaitement exacts — le dixième mot dans une étude de ce genre devrait apparaître environ 1 000 fois, en raison d'un effet de coude observé dans ce type de distribution. Il reste que la loi de Zipf prévoit que dans un texte donné, la fréquence d'occurrence f(n) d'un mot est liée à son rang n dans l'ordre des fréquences par une loi de la forme où K est une constante.

Point de vue théorique
Mathématiquement, il est impossible pour la version classique de la loi de Zipf d'affirmer exactement qu'il existe une infinité de mots dans une langue, puisque pour toute constante de proportionnalité c > 0, la somme de toutes les fréquences relatives est proportionnelle à la série harmonique et doit être

Des observations citées par Léon Brillouin dans son livre Science et théorie de l'information suggérèrent qu'en anglais, les fréquences parmi les 1 000 mots les plus fréquemment utilisés étaient approximativement proportionnels à avec s juste légèrement plus grand que 1. On sait toutefois que le nombre de mots d'une langue est limité. Le vocabulaire (passif) d'un enfant de 10 ans tourne autour de 5 000 mots[3], celui d'un adulte moyennement cultivé de 20 000[4], et les dictionnaires en plusieurs volumes peuvent contenir de 130 000 à 200 000 mots.

Définition mathématique
Notons les paramètres de la loi de Zipf par N ∈ N* pour le nombre d'éléments (de mots), k ∈ N* leur rang, et le paramètre s > 0. La fonction de masse de la loi de Zipf est donnée par :

où est le Ne nombre harmonique généralisé. Cette loi est bien définie pour tout N entier fini.

La loi de Zipf où le paramètre N est infini (loi zêta), n'est définie que pour s > 1. En effet, la somme des valeurs de la fonction de masse est alors égale à la fonction zêta de Riemann :

Un cas particulier d'une loi générale
Benoît Mandelbrot démontra dans les années 1950 qu'une classe de lois dont celle de Zipf est un cas particulier pouvait se déduire de deux considérations liées à la théorie de l'information de Claude Shannon.
Loi statique de Shannon
Selon la loi statique, le coût de représentation d'une information augmente comme le logarithme du nombre des informations à considérer.
Il faut par exemple 5 bits pour représenter les entiers de 0 à 31, mais 16 pour les entiers de 0 à 65 535. De même, on peut former 17 576 sigles de 3 lettres, mais 456 976 de 4 lettres, etc.
Loi dynamique de Shannon
La loi dynamique indique comment maximiser l'utilité d'un canal par maximisation de l'entropie en utilisant prioritairement les symboles les moins coûteux à transmettre. Ainsi en code Morse le e, lettre fréquente, est codé par un simple point (.) tandis que le x, lettre plus rare, se représente par un trait point point trait (-..-). Le codage de Huffman met en application cette loi dynamique.
La synthèse de Mandelbrot
Mandelbrot émet l'hypothèse audacieuse que le coût d'utilisation est directement proportionnel au coût de stockage, ce qu'il constate comme étant vrai sur tous les dispositifs qu'il a observés, de l'écriture comptable jusqu'aux ordinateurs[5].
Il élimine donc le coût entre les deux équations et se retrouve avec une famille d'équations liant nécessairement la fréquence d'un mot à son rang si l'on veut que le canal soit utilisé de façon optimale. C'est la loi de Mandelbrot, dont celle de Zipf ne représente qu'un cas particulier, et qui est donnée par la loi :
- , où K est une constante

la loi se ramenant à celle de Zipf dans le cas particulier où a vaudrait 0, b et c tous deux 1, cas qui ne se rencontre pas dans la pratique. Dans la plupart des langues existantes, c est voisin de 1,1 ou 1,2, et proche de 1,6 dans le langage enfantin[5].
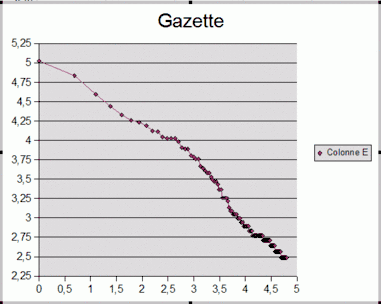
Les lois de Zipf et de Mandelbrot prennent un aspect spectaculaire si on les trace selon un système de coordonnées log-log : la loi de Zipf correspond alors à une belle droite, et celle de Mandelbrot à la même chose avec un coude caractéristique. Ce coude se retrouve précisément dans les textes littéraires disponibles sur la Toile, analysables en quelques minutes sur ordinateur personnel. La courbe fournie ici représente le logarithme décimal du nombre d'occurrences des termes d'un forum sur internet tracé en fonction du logarithme décimal du rang de ces mots.
- On constate que le mot le plus fréquent y apparaît un peu plus de 100 000 fois (105).
- La taille du vocabulaire effectivement utilisé (il serait plus exact de parler de la taille de l'ensemble des formes fléchies) est de l'ordre de 60 000 (104,7).
- L'aspect linéaire de Zipf y apparaît clairement, bien que le coude caractéristique expliqué par Mandelbrot n'y soit que léger. La pente n'est pas exactement de −1 comme le voudrait la loi de Zipf.
- L'intersection projetée de cette courbe avec l'axe des abscisses fournirait à partir d'un texte de taille limitée (quelques pages A4 dactylographiées) une estimation de l'étendue du vocabulaire d'un scripteur[Notes 1].
Similitudes
Le rapport entre lois de Zipf et de Mandelbrot d'une part, entre lois de Mariotte et de van der Waals d'autre part est similaire : on a dans les premiers cas une loi de type hyperbolique, dans les secondes une légère correction rendant compte de l'écart entre ce qui était prévu et ce qui est observé, et proposant une justification. Dans les deux cas, un élément de correction est l'introduction d'une constante manifestant quelque chose d'« incompressible » (chez Mandelbrot, le terme « a » de la loi).
On peut aussi noter une ressemblance avec la loi de Benford qui porte sur le premier chiffre de chaque nombre d'un ensemble de données statistiques, et qui se démontre aussi, cette fois-ci par des considérations d'invariance en fonction du système d'unités utilisé.
La distribution des vitesses dans un gaz répond aussi à une exigence d'invariance par rotation des coordonnées. Ce domaine des lois stables a été largement étudié par le mathématicien Paul Lévy, que Mandelbrot eut précisément à Polytechnique comme professeur.
Une loi à utiliser avec prudence

Il est tentant de croire que des informations classées par ordre décroissant suivent une loi de Zipf, mais elles ne le sont pas toujours. Prenons par exemple 100 entiers aléatoires entre 1 et 10 selon une loi uniforme discrète, que nous regroupons et que nous trions le nombre d'occurrences de chacun, nous obtenons la courbe ci-contre.
Si l'on se fie juste à la première impression visuelle, cette courbe paraît « zipfienne », alors que c'est un modèle qui a engendré la série des données. Or il n'est pas possible de faire commodément un Khi2 sur la loi de Zipf, le tri des valeurs venant faire obstacle à l'usage d'un modèle probabiliste classique (en effet, la répartition des occurrences n'est pas celle des probabilités d'occurrences ; cela peut conduire à beaucoup d'inversions dans les tris).
La famille de distributions de Mandelbrot est certes démontrée adéquate de façon formelle pour un langage humain sous ses hypothèses de départ concernant le coût de stockage et le coût d'utilisation, qui découlent elles-mêmes de la théorie de l'information. En revanche, il n'est pas prouvé qu'utiliser la loi de Zipf comme modèle pour la distribution des populations des agglomérations d'un pays soit un pertinent — bien que le contraire ne soit pas prouvé non plus.
En tout état de cause, il ne faut pas non plus s'étonner outre mesure qu'une loi prédisant une décroissance se vérifie sur des données que nous avons nous-mêmes classées au préalable en ordre décroissant[Notes 2]

De plus, l'estimation des paramètres de Mandelbrot à partir d'une série de données pose également problème et fait encore en 1989[6] l'objet de débats. Il ne saurait être question par exemple d'utiliser une méthode de moindres carrés sur une courbe en log-log[Notes 3] dont de surcroît le poids des points respectifs est loin d'être comparable. Mandelbrot n'a apparemment plus fait de nouvelle communication sur le sujet après la fin des années 1960.
Sur la distribution d'un texte, comme celui d'une traduction française du Coran (164 869 unités lexicales, 1 477 formes fléchies distinctes), le « coude » de la distribution de Mandelbrot apparaît de façon franche (voir ci-contre), et les pentes respectives de deux segments de droite peuvent être estimées visuellement. Des textes de ce type peuvent ainsi être comparés par les seuls termes a et c des distributions (b s'en déduisant).
Notes et références
Notes
- Deux précisions sont signalées par le physicien Léon Brillouin dans son ouvrage Science et théorie de l'information :
- nous nous livrons déjà subjectivement à la même estimation en lisant quelques pages d'un écrivain que nous ne connaissons pas, et c'est ce qui nous permet en feuilletant un ouvrage d'estimer si l'étendue de son vocabulaire est en adéquation avec la nôtre ;
- la répétition de mots se voulant savants comme extemporanément ou hiératique ne fera pas illusion, puisque c'est la répétition elle-même qui constitue l'indice de pauvreté du vocabulaire et non les mots utilisés, quels qu'ils soient.
- Un tri de N mots correspond au choix d'une permutation parmi N! (factorielle N), ce qui correspond à un log2(N!) bits, quantité d'information ajoutée par l'arbitraire du choix de cette permutation plutôt que d'une autre. (N!) s'estime facilement par la formule de Stirling.
- Quel sens donner en effet au carré d'un logarithme ?
Références
- Micheline Petruszewycz, « L'histoire de la loi d'Estoup-Zipf : documents » [archive du ] [PDF], (consulté le ), p. 41-56.
- Benoît Mandelbrot, Logique, langage et théorie de l'information, Paris, Presses universitaires de France, (lire en ligne [PDF]), « Étude de la loi d'Estoup et de Zipf : fréquences des mots dans le discours », p. 22-53.
- « Quelle est l'étendue de notre vocabulaire ? », C2P (carnets2psycho), août 2014.
- « Quelques mots sur les mots d’une langue » [PDF], EOLE (Éducation et ouverture aux langues à l'école), 2003.
- Léon Brillouin, La Science et la théorie de l'information, 1959, réédité en 1988, traduction anglaise rééditée en 2004
- Marc Barbut, « Note sur l'ajustement des distributions de Zipf-Mandelbrot en statistique textuelle », Histoire & Mesure, vol. 4, nos 1-2, , p. 107–119 (DOI 10.3406/hism.1989.879, lire en ligne).
Annexes
Bibliographie
- (en) H. Guiter et M. V. Arapov, Studies on Zipf's Law, Bochum, Brockmeyer, (ISBN 3-88339-244-8)
Articles connexes
Lien externe
(en) Eric W. Weisstein, « Zipf Distribution », sur MathWorld