Régression elliptique
La régression elliptique consiste à trouver la « meilleure ellipse », au sens des moindres carrés, décrivant un ensemble de points. C'est un cas de régression géométrique, c'est-à-dire que la distance point-courbe modèle à laquelle on s'intéresse est une distance perpendiculaire à la courbe — méthode des moindres carrés totaux (TLS pour total least squares, ou FLS pour full least squares) —, et non une distance verticale (en y). La régression elliptique est une généralisation de la régression circulaire.
Méthodes de la distance algébrique
Une ellipse peut être définie par l'équation cartésienne

où F est la formule quadratique :

La fonction F est également appelée « distance algébrique » du point (x, y) à l'ellipse.
On dispose des coordonnées des n points expérimentaux, notées (xi, yi)1 ≤ i ≤ n. On cherche à minimiser la somme des carrés des distances algébriques, c'est-à-dire
- .

On peut écrire le problème sous forme matricielle : on définit la matrice des monômes

et la matrice des paramètres de l'ellipse

le problème consiste alors à minimiser

Régression quadratique multilinéaire
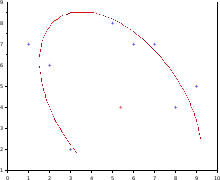
La méthode de la régression quadratique consiste à faire une régression linéaire multiple (à l'instar de la régression polynomiale). En effet, on peut transformer l'équation en

en choisissant arbitrairement A1 = –1[1]. On peut alors poser :

on a donc bien un modèle multilinéaire

Le résultat de cette régression pour un nuage de points[2] est donné sur la figure ci-contre.
Présenté comme ceci, la méthode consiste à minimiser
- .

On peut remarquer que l'on pourrait extraire un autre facteur, en posant Y = y2, xy, x ou bien y, et qu'il n'y a pas de raison d'avoir le même résultat à chaque fois.
Le deuxième problème est que la forme quadratique définit de manière générale une conique ; le meilleur candidat peut donc être une hyperbole ou une parabole. Il faut donc ajouter une contrainte propre aux ellipses, à savoir que le discriminant de la forme quadratique associée soit strictement négatif :

Les coefficients Ai sont définis à un facteur multiplicatif près. On peut donc exprimer cette condition par

L'ajout de cette contrainte complique la résolution. Plusieurs solutions ont été développées pour éviter de passer par une étape itérative, source potentielle d'instabilité numérique.
Résolution par décomposition en valeurs singulières
Gander et coll.[2] proposent d'effectuer une décomposition en valeurs singulières de D :

où U est une matrice unitaire n × n, V une matrice unitaire 6 × 6 et S est une matrice n × 6 qui contient les valeurs singulières de D. On a alors

Les coefficients sont définis à une constante multiplicatrice près. Cette méthode consiste donc, d'une manière ou d'une autre, à appliquer la contrainte

Le principal inconvénient de cette méthode est que la contrainte n'est pas invariante par les transformations euclidiennes, et en particulier par les isométries : translation, rotation, symétrie. Ainsi, le demi-grand axe et le demi-petit axe de l'ellipse peuvent être différents si l'on tourne le nuage de points.
Bookstein[3] a proposé à la place d'utiliser la contrainte

ce qui revient à imposer une contrainte sur l'équation réduite, qui est elle indépendante des isométries :
- équation cartésienne réduite :
- contrainte de Bookstein :


Bookstein propose de résoudre ce problème par décomposition spectrale (recherche des valeurs et vecteurs propres), mais Gander et coll. proposent plutôt de résoudre le problème par décomposition en valeurs singulières. Pour cela, on définit la matrice de données modifiée

et les vecteurs de paramètres


et l'on doit donc minimiser

avec la contrainte ∥w∥ = 1. Pour cela, on fait la factorisation QR de D', puis on scinde la matrice R (matrice triangulaire supérieure) pour avoir un bloc R22 de dimensions 3 × 3, et donc deux blocs R11 et R12 de dimension 3 × (n – 3) :

Le problème se ramène alors à chercher le minimum de R22w. On effectue pour cela la décomposition en valeurs singulières de R22.
Utilisation des multiplicateurs de Lagrange
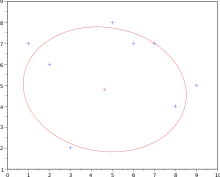
Fitzgibbon et coll.[4] a proposé de minimiser la somme des carrés des distances algébriques, et d'utiliser la méthode des multiplicateurs de Lagrange pour intégrer la contrainte. En effet, il s'agit bien de minimiser une fonction φ(A1, …, A6) définie par

les points (xi, yi)1 ≤ i ≤ n étant connus, avec une contrainte ψ(A1, …, A6) = 0, la fonction ψ étant définie par

les fonctions φ et ψ étant de classe C∞ (polynômes), donc a fortiori de classe C1.
On note pour la suite a le vecteur de R6

et les matrices représentatives des applications linéaires de R6 dans R6 :
- matrice de conception (design matrix)
- matrice de contrainte


et l'on a donc


où tM désigne la transposée de la matrice M. On peut donc poser la fonction L :

Si a0 est une solution recherchée (φ est minimale en a0 et a0 satisfait la condition de contrainte), alors il existe une valeur λ0 non nulle telle que la différentielle dL soit nulle en (a0, λ0) : ∂L/∂Ai = 0 pour tout i, et ∂L/∂λ = 0. En calculant les dérivées partielles, on arrive au système d'équations

En posant la matrice de dispersion ('scatter matrix) S =tDD on a
![{\displaystyle \left\{{\begin{aligned}\mathbf {S} \mathbf {a} &\ =\lambda \mathbf {C} \mathbf {a} &[1]\\{}^{\mathrm {t} }\mathbf {a} \mathbf {C} \mathbf {a} &\ =1&[2]\end{aligned}}\right.}](https://img.franco.wiki/i/44bd9125072614aeb098d75c58a6c19dd93b940d.svg)
Les matrices S et C sont des matrices carrées 6×6.
Notons que l'équation [2] peut s'écrire

comme S est en général définie positive, cela revient à dire que λi doit être positive.
Il reste donc à résoudre l'équation [1] ; cela peut se faire de plusieurs manières.
Par construction, la matrice S a de grandes chances d'être définie positive, donc inversible. L'équation [1] peut donc s'écrire

si λ est non nulle. Ainsi, a est un vecteur propre de S-1Ca, associé à la valeur propre 1/λ.
On peut aussi remarquer que l'équation [1] est un problème aux valeurs propres généralisé, c'est-à-dire à une recherche du sous-espace caractéristique (notion généralisée des valeurs propres et vecteurs propres).
On obtient donc six solutions (λi, ai) à l'équation [1], mais rien ne garantit qu'elles vérifient l'équation [2]. Cependant, si ai est un vecteur propre, alors μiai est aussi un vecteur propre pour tout μi non nul, il faut donc trouver une valeur de μi telle que

La valeur de μi est réelle si taiCai est positif, donc si (1/λi)taiSai. S étant définie positive, taiSai est strictement positive, donc
- μi est réelle si λi est positive.
Donc, une condition nécessaire pour qu'un vecteur de coefficients ai corresponde à la meilleure ellipse est que ce soit un vecteur propre associé à une valeur propre positive. Fitzgibbon et coll. démontrent qu'il n'y a qu'une seule valeur propre positive, donc que la solution est unique.
Scission des matrices
Halíř et coll.[5] on proposé des améliorations :
- la matrice C est singulière, et S est presque singulière (elle l'est si tous les points sont exactement sur l'ellipse), la détermination des valeurs propres est donc numériquement instable et peut générer des résultats infinis ou complexes ;
- si tous les points sont exactement sur l'ellipse, la valeur propre est 0 ; donc la valeur propre recherchée est proche de 0, et de fait, l'approximation numérique peut donner des résultats légèrement négatifs, solution qui serait alors rejetée par l'algorithme.
Pour résoudre ces problèmes, ils proposent de scinder les matrices (matrices par blocs) :
- avec et ;
- avec S1 = tD1D1, S2 = tD1D2 et S3 = tD2D2 ;
- avec
- avec et .









L'équation [1] devient alors le système
![{\displaystyle \left\{{\begin{aligned}\mathbf {S_{1}} \mathbf {a_{1}} +\mathbf {S_{2}} \mathbf {a_{2}} &=\lambda \mathbf {C_{1}} \mathbf {a_{1}} &[3]\\^{\mathrm {t} }\mathbf {S_{2}} \mathbf {a_{1}} +\mathbf {S_{3}} \mathbf {a_{2}} &=0&[4]\\\end{aligned}}\right.}](https://img.franco.wiki/i/532c11ce87c5cef2257796f0dc460f8a7af56db1.svg)
La matrice S3 correspond à une régression linéaire ; elle est singulière si les points sont strictement alignés, or cela n'a pas de sens de faire une régression elliptique sur des points alignés. On peut donc considérer que S3 est régulière (inversible). La matrice C1 est elle aussi régulière, le système d'équation devient donc
![{\displaystyle \left\{{\begin{aligned}\mathbf {M} \mathbf {a_{1}} &=\lambda \mathbf {a_{1}} &[5]\\-\mathbf {S_{3}} ^{-1}\,^{\mathrm {t} }\mathbf {S_{2}} \mathbf {a_{1}} &=\mathbf {a_{2}} &[6]\\\end{aligned}}\right.}](https://img.franco.wiki/i/7b37f97470d62931d77e225270d38808d5a0a796.svg)
avec M la matrice de dispersion réduite
- M = C1-1(S1 - S2S3-1 tS2).
L'équation [2] devient
- ta1C1a1 = 1 [7]
On se retrouve donc à résoudre le système d'équations {[5] ; [6] ; [7]}, soit :
- [5] : déterminer les valeurs propres et vecteurs propres de M ;
- trouver a1 : retenir la valeur propre positive, ou mieux :
[7] trouver l'unique vecteur tel que ta1C1a1 > 0 ; - [6] : calculer a2 ;
- rassembler a1 et a2 pour former le vecteur a.
Méthode des moindres carrés totaux
La méthode des moindres carrés totaux est, comme dans le cas du cercle, non linéaire. On a donc recours à un algorithme itératif.
Le principal problème est de déterminer la distance d'un point à l'ellipse modèle. La méthode la plus simple consiste à prendre une équation paramétrique de l'ellipse :

où (xc, yc) sont les coordonnées du centre de l'ellipse et Q(α) est la matrice de rotation d'angle α (inclinaison de l'ellipse).
On se retrouve ici avec n + 6 inconnues : les six paramètres de l'ellipse (xc, yc, a, b, α) et les n paramètres φi, le point (x(φi), x(φi)) étant le point de l'ellipse le plus proche du point expérimental i.
Pour initialiser les paramètres de l'ellipse, on peut utiliser une méthode de distance algébrique, ou bien une régression circulaire ; le cas du cercle pouvant donner une matrice jacobienne singulière, il peut être nécessaire de démarrer en « elliptisant » le cercle, par exemple en créant de manière arbitraire une ellipse dont le demi-grand axe a le rayon du cercle et le demi-petit axe vaut la moitié.
Pour initialiser φi, on peut utiliser l'angle par rapport à l'axe x du segment reliant le centre initial de l'ellipse au point expérimental i.
On peut utiliser les méthodes itératives classiques (méthodes de Gauss-Newton ou de Levenberg-Marquardt).
Applications
Analyse d'image
Une ellipse peut être considéré comme un cercle selon une « vue inclinée » : c'est la projection orthogonale d'un cercle sur un plan sécant au plan le contenant. C'est donc une figure qui est susceptible d'apparaître dans de nombreuses images.
Cela peut être utilisé pour des algorithmes de reconnaissance de forme, par exemple reconnaître l'ovale des visages sur une photographie, pour de l'imagerie médicale, des inspections industrielles, la conversion d'une image matricielle en image vectorielle, ou encore en archéologie — pour déterminer la taille d'une poterie à partir d'un fragment, le col de la poterie formant un arc de cercle qui, du fait de la perspective, est vu comme un arc d'ellipse[5].
Notes et références
- Ce choix est valide grâce au paradoxe de Cramer : une ellipse sera totalement déterminée par cinq points.
- Walter Gander, Gene H. Golub et Rolf Strebel, « Least-Squares Fitting of Circles and Ellipses », BIT Numerical Mathematics, Springer, vol. 34, no 4, , p. 558-578 (ISSN 0006-3835 et 1572-9125, lire en ligne)
- Fred L. Bookstein, « Fitting Conic Sections to Scattered Data », Computer Graphics and Image Processing, no 9, , p. 56-71
- (en) Andrew W. Fitzgibbon, Maurizio Pilu et Robert B. Fisher, « Direct least squares fitting of ellipses », IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 21, no 5, , p. 476-480 (lire en ligne)
- (en) Radim Halíř et Jan Flusser, « Numerically Stable Direct Least Squares Fitting of Ellipses », Winter School of Computer Graphics, vol. 6, (ISSN 1213-6972 et 1213-6964, lire en ligne)