Inégalité d'Azuma
L’inégalité d'Azuma, parfois appelée inégalité d'Azuma-Hoeffding, est une inégalité de concentration concernant les martingales dont les accroissements sont bornés. C'est une généralisation de l'inégalité de Hoeffding, une inégalité de concentration ne concernant, elle, que les sommes de variables aléatoires indépendantes et bornées.
Énoncé courant
Un des énoncés les plus courants est


![{\displaystyle \forall t\in [\![1,m]\!],\qquad \mathbb {P} (|M_{t}-M_{t-1}|\leq 1)=1.}](https://img.franco.wiki/i/22cd2db2cd82d8ff8f6852a27bec9680c9aa5fd0.svg)

![{\displaystyle {\begin{aligned}\mathbb {P} \left(M_{m}-\mathbb {E} [M_{m}]\geq \lambda \right)&\leq \exp \left(-{\frac {\lambda ^{2}}{2m}}\right),\\\mathbb {P} \left(M_{m}-\mathbb {E} [M_{m}]\leq -\lambda \right)&\leq \exp \left(-{\frac {\lambda ^{2}}{2m}}\right),\\\mathbb {P} \left(\left|M_{m}-\mathbb {E} [M_{m}]\right|\geq \lambda \right)&\leq 2\exp \left(-{\frac {\lambda ^{2}}{2m}}\right).\end{aligned}}}](https://img.franco.wiki/i/ce511a72a205397115c2439fe08ee51b41428dc4.svg)
Notons que le choix entraine que

![{\displaystyle M_{0}=\mathbb {E} [M_{m}].\ }](https://img.franco.wiki/i/d7c86ec3bb2fdc2c10eb55735dcb0ca13a92772a.svg)
Énoncé général
Un énoncé plus général (McDiarmid, Théorème 6.7) est le suivant
Théorème — Soit une martingale par rapport à une filtration Supposons qu'il existe une suite de variables aléatoires et une suite de constantes telles que, pour tout



![{\displaystyle k\in [\![1,m]\!],\ }](https://img.franco.wiki/i/6ece6b0f330ccfa1a3f0482080b17419bdfb4db7.svg)
- soit -mesurable ;



Alors, pour tout
![{\displaystyle {\begin{aligned}\mathbb {P} \left(M_{m}-\mathbb {E} [M_{m}]\geq \lambda \right)&\leq \exp \left(-{\frac {2\lambda ^{2}}{\sum _{i=1}^{m}\ell _{i}^{2}}}\right),\\\mathbb {P} \left(M_{m}-\mathbb {E} [M_{m}]\leq -\lambda \right)&\leq \exp \left(-{\frac {2\lambda ^{2}}{\sum _{i=1}^{m}\ell _{i}^{2}}}\right),\\\mathbb {P} \left(\left|M_{m}-\mathbb {E} [M_{m}]\right|\geq \lambda \right)&\leq 2\exp \left(-{\frac {2\lambda ^{2}}{\sum _{i=1}^{m}\ell _{i}^{2}}}\right).\end{aligned}}}](https://img.franco.wiki/i/5043c84ed3b4347df03c88a77c5825e5d1c80aa7.svg)
L'énoncé courant, donné à la section précédente, est obtenu en spécialisant l'énoncé général aux choix


![{\displaystyle {\begin{aligned}\mathbb {P} \left(c_{i}\leq Y_{i}\leq d_{i}\right)&=1,\\d_{i}-c_{i}&=\ell _{i},\\M_{m}-\mathbb {E} [M_{m}]&=Y_{1}+Y_{2}+\dots +Y_{m}.\end{aligned}}}](https://img.franco.wiki/i/5ca3429db05a5133eb520b7bb8c19ee292cffd42.svg)

![{\displaystyle {\begin{aligned}\mathbb {P} \left(M_{m}-\mathbb {E} [M_{m}]\geq \lambda \right)&\leq \mathbb {E} \left[e^{s(M_{m}-\mathbb {E} [M_{m}])}\right]e^{-s\lambda }\\&=\mathbb {E} \left[e^{s(Y_{1}+Y_{2}+\dots +Y_{m})}\right]e^{-s\lambda }\end{aligned}}}](https://img.franco.wiki/i/d64d5f412e6b2e28071476cef6d7fac4afee9aa3.svg)
![{\displaystyle {\begin{aligned}\mathbb {E} \left[e^{sY_{m}}\left|{\mathcal {F}}_{m-1}\right.\right]&\leq \exp \left(s^{2}\ell _{m}^{2}/8\right),\end{aligned}}}](https://img.franco.wiki/i/babfa9bf688f4bf9468840cbc8fd5d066ada3011.svg)

![{\displaystyle \mathbb {E} [Y]=0\ }](https://img.franco.wiki/i/ec5da4aed985f79191c55e6e370dc83687f69f71.svg)



![{\mathbb {E}}\left[e^{{sY}}\right]\leq \exp \left(s^{2}(d-c)^{2}/8\right).](https://img.franco.wiki/i/95dfb6d5469b5e53e9a936ec8d80fd1c1264901a.svg)
![{\displaystyle {\begin{aligned}\mathbb {E} \left[Y_{m}\left|{\mathcal {F}}_{m-1}\right.\right]&=0,\\\mathbb {P} \left(c_{m}\leq Y_{m}\leq c_{m}+\ell _{m}\left|{\mathcal {F}}_{m-1}\right.\right)&=1,\end{aligned}}}](https://img.franco.wiki/i/94199faf8465e5cbb5eac44baa0ba2651cb2a474.svg)



![{\displaystyle {\begin{aligned}\mathbb {E} \left[e^{s(Y_{1}+Y_{2}+\dots +Y_{m})}\right]&=\mathbb {E} \left[\mathbb {E} \left[e^{s(Y_{1}+Y_{2}+\dots +Y_{m})}\left|{\mathcal {F}}_{m-1}\right.\right]\right]\\&=\mathbb {E} \left[e^{s(Y_{1}+Y_{2}+\dots +Y_{m-1})}\ \mathbb {E} \left[e^{sY_{m}}\left|{\mathcal {F}}_{m-1}\right.\right]\right]\\&\leq \mathbb {E} \left[e^{s(Y_{1}+Y_{2}+\dots +Y_{m-1})}\right]\ e^{s^{2}\ell _{m}^{2}/8}\\&\leq \exp \left((\sum _{i=1}^{m}\ell _{i}^{2})s^{2}/8\right),\end{aligned}}}](https://img.franco.wiki/i/7432dbb0173825a6d478eed631443cf2ffb6edda.svg)
Principe de Maurey
Le principe de Maurey a été énoncé pour la première fois par Maurey dans une note aux Comptes rendus de l'Académie des Sciences en 1979, et découvert plus tard, semble-t-il indépendamment, par Harry Kesten, en théorie de la percolation. Il est d'usage fréquent en théorie des graphes aléatoires, dans l'analyse des algorithmes randomisés, et en théorie de la percolation. Il est parfois appelé method of bounded differences ou MOBD.
Énoncé
Soit deux ensembles A et B et soit l'ensemble des applications de B dans A. On se donne une filtration


Définition — Une application est dite -lipshitzienne si, pour tout et pour tout on a l'implication :


![{\displaystyle t\in [\![1,m]\!]\ }](https://img.franco.wiki/i/970314adc11963865571d9ba22c64c574751ca76.svg)


Autrement dit, si les deux applications coïncident à l'intérieur de et à l'extérieur de (i.e. dans les zones vertes et bleues de la figure ci-dessous), alors X varie peu de l'une à l'autre.


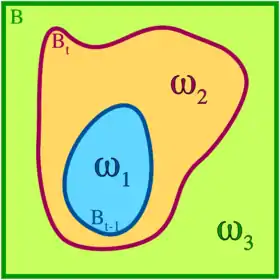
Théorème — On suppose muni d'une structure d'espace probabilisé telle que les images forment une famille de variables aléatoires indépendantes. On suppose également que la variable aléatoire réelle X, définie sur , est -lipshitzienne. Alors, pour tout



![{\displaystyle {\begin{aligned}\mathbb {P} \left(X-\mathbb {E} [X]\geq \lambda \right)&\leq \exp \left(-{\frac {\lambda ^{2}}{2m}}\right),\\\mathbb {P} \left(X-\mathbb {E} [X]\leq -\lambda \right)&\leq \exp \left(-{\frac {\lambda ^{2}}{2m}}\right),\\\mathbb {P} \left(\left|X-\mathbb {E} [X]\right|\geq \lambda \right)&\leq 2\exp \left(-{\frac {\lambda ^{2}}{2m}}\right).\end{aligned}}}](https://img.franco.wiki/i/d84972eea3d871390063a3a44598820eefc7de2b.svg)



![{\displaystyle M_{t}=\mathbb {E} \left[X\left|\ {\mathcal {F}}_{t}\right.\right].}](https://img.franco.wiki/i/ca98dab411c4ca05c7d08793e1febc88768123dc.svg)

![{\displaystyle M_{0}=\mathbb {E} \left[X\right],\ }](https://img.franco.wiki/i/02b3847dea3d86f6ed8f3fd93715f0bdb9ef8134.svg)















&=\int _{A^{C_{3}}}X(\omega _{1},\,\omega _{2},\,w_{3})\mathbb {P} _{3}(dw_{3}),\\&=\int _{A^{C_{3}}}\left(\int _{A^{C_{2}}}X(\omega _{1},\,\omega _{2},\,w_{3})\mathbb {P} _{2}(dw_{2})\right)\mathbb {P} _{3}(dw_{3}).\\\mathbb {E} \left[X\left|\ {\mathcal {F}}_{t-1}\right.\right](\omega )&=\int _{A^{C_{3}}}\left(\int _{A^{C_{2}}}X(\omega _{1},\,w_{2},\,w_{3})\mathbb {P} _{2}(dw_{2})\right)\mathbb {P} _{3}(dw_{3}).\end{aligned}}}](https://img.franco.wiki/i/de4cb8938991711bce445a586dbb2d157e30aab3.svg)







Application à un modèle d'urnes et de boules
Dans cet exemple, l'intérêt d'une inégalité de concentration précise est de justifier une méthode statistique de comptage approximatif[1] pouvant servir, par exemple, à déceler une attaque de virus informatique.
Une inégalité de concentration
On jette m boules au hasard dans n boîtes, expérience probabiliste dont un événement élémentaire est décrit par une application de dans : est le numéro de la boîte dans laquelle est rangée la boule numéro k. Ainsi les sont bien des variables aléatoires indépendantes, et, accessoirement, des variables aléatoires uniformes. Considérons l'application X, qui, à une distribution de m boules dans n boîtes, associe le nombre de boîtes vides à la fin de cette distribution On peut calculer l'espérance de X aisément à l'aide d'une décomposition de X en somme de variables de Bernoulli. On trouve alors que

![{\displaystyle B=[\![1,m]\!]\ }](https://img.franco.wiki/i/31b5b5f0554e5e43f9bbb44cf10431095c1e0cb0.svg)
![{\displaystyle A=[\![1,n]\!]\ }](https://img.franco.wiki/i/8bd7342c3e25f297b1acfebe7f1dd6ece185aa48.svg)



![{\displaystyle \mathbb {E} [X]\ =\ n\left(1-{\tfrac {1}{n}}\right)^{m}.}](https://img.franco.wiki/i/6654859d116ecdc97e4f412bcff94f6202881fd0.svg)
Pour le choix l'application X est -lipshitzienne : en effet, si, d'une distribution à une autre, seule la place de la boule n°t change ( est réduit au seul élément t ), alors le nombre de boîtes vides varie d'au plus une unité. Ainsi, en vertu du principe de Maurey,
![{\displaystyle B_{t}=[\![1,t]\!],\ }](https://img.franco.wiki/i/7b397ae2a4f03c483e609c95768a7be9fabc6e5b.svg)


Une inégalité plus précise[2] est obtenue en appliquant la forme générale de l'inégalité d'Azuma.
Un problème de comptage approché
Il s'agit d'estimer le nombre m d'utilisateurs différents, identifiés, à un nœud du réseau, par l'entête du paquet de données qu'ils envoient. L'idée est qu'une attaque de virus ne se traduit pas par une augmentation décelable du volume du trafic (le gros du volume étant fourni, par exemple, par des téléchargements de fichiers, lesquels sont scindés en nombreux paquets qui ont tous le même entête, caractérisant le même utilisateur), mais par une augmentation drastique du nombre d'utilisateurs différents, à cause d'un envoi massif et concerté de mails (tous de petit volume, comparés à des téléchargements).
Chaque fois qu'un paquet de données est reçu à un nœud du réseau, l'utilisateur b émetteur du paquet est reconnu à l'aide de l'entête du paquet de données (une suite de longueur L de 0 et de 1). Cet entête est haché, i.e. transformé en un nombre aléatoire uniforme sur l'intervalle [0,1] : cette transformation (la fonction de hachage) est conçue de telle sorte que m paquets émis par m utilisateurs différents produisent m entêtes différents et, après hachage de ces entêtes, produisent une suite de m variables aléatoires indépendantes et uniformes sur l'intervalle [0,1]. Par contre paquets émis par le même utilisateur b produisent fois la même entête , et hachages successifs de cet entête produisent une suite de valeurs aléatoires identiques, toutes égales au même nombre tiré au hasard, une fois pour toutes, uniformément sur l'intervalle [0,1].





On reçoit un grand nombre (P) de paquets en un laps de temps très court. On dispose seulement de n cases mémoires et on veut compter le nombre m d'utilisateurs différents émetteurs de ces paquets. Par manque de place mémoire, il est impossible de stocker au fur et à mesure les entêtes des paquets déjà reçus, et par manque de temps il serait impossible de tester si un nouvel entête reçu fait partie de la liste des entêtes déjà récoltés. Un calcul exact de m est donc impossible. On se donne alors n cases, numérotées de 1 à n, considérées comme libres, ou bien occupées. Au départ toutes les cases sont considérées comme libres. À chaque paquet reçu, l'entête correspondant est haché, produisant un nombre U aléatoire uniforme sur [0,1], et la case n° est marquée occupée, quel qu'ait été son statut antérieur. Qu'une entête apparaisse une fois ou 10 000 fois, le résultat sera le même : c'est, du fait de cet entête, le même nombre aléatoire U qui sera engendré et la même case n° qui sera marquée occupée.

Ainsi l'état de l'ensemble des n cases après réception des P paquets ne dépend pas du volume P du trafic, mais uniquement de la suite des m entêtes hashés correspondant aux m utilisateurs différents. Plus précisément, le nombre X de cases libres à la fin du processus a même loi que dans le problème de boîtes et de boules évoqué à la section précédente. L'inégalité de concentration assure que, pour n et m assez grands, avec une forte probabilité, l'approximation de par X, c'est-à-dire :

![{\displaystyle \mathbb {E} [X]\ }](https://img.franco.wiki/i/007eef6a285ebbb9773b2bc87b4c1763dba1bd08.svg)

est assez précise pour permettre de reconstituer le ratio r=m/n, et, partant de là, le nombre m d'utilisateurs différents, inconnu jusque-là, en fonction de X et de n, qui sont connus : on choisit comme approximation de r le nombre Dans cette situation particulière, on sera satisfait si la précision de l'approximation permet de déceler un changement brutal de la valeur de m d'un moment à l'autre, changement annonciateur d'une attaque de virus : pour cela, une approximation grossière de m devrait suffire.

Voir aussi
Notes
- proposée par (en) Kyu-Young Whang et Ravi Krishnamurthy, « Query optimization in a memory-resident domain relational calculus database system », ACM Transactions on Database Systems (TODS), New York, NY, USA, ACM, vol. 15, no 1, , p. 67–95 (ISSN 0362-5915, lire en ligne)
- (en) Rajeev Motwani et Prabhakar Raghavan, Randomized Algorithms, Cambridge, New York et Melbourne, Cambridge University Press, (réimpr. 1997, 2000), 1re éd., 476 p. (ISBN 978-0-521-47465-8, lire en ligne), chap. 4 (« Tail inequalities »), p. 94–95, Théorème 4.18.
Bibliographie
- (en) N. Alon et J. Spencer, The Probabilistic Method, New York, Wiley,
- (en) K. Azuma, « Weighted Sums of Certain Dependent Random Variables », Tôhoku Math. Journ., vol. 19, , p. 357–367
- (ru) Sergei N. Bernstein, « [traduction] On certain modifications of Chebyshev's inequality », Doklady Akademii Nauk SSSR, vol. 17, no 6, , p. 275–277
- (en) C. McDiarmid, « On the method of bounded differences », London Math. Soc. Lectures Notes, Cambridge (UK), Cambridge Univ. Press, no 141 « Surveys in Combinatorics », , p. 148–188
- (en) W. Hoeffding, « Probability inequalities for sums of bounded random variables », J. Amer. Statist. Assoc., vol. 58, , p. 13–30
- B. Maurey, « Constructions de suites symétriques », CR Acad. Sci. Paris, Série A–B, vol. 288, , p. 679–681
Pour aller plus loin
- (en) S. Boucheron, G. Lugosi et P. Massart, « Concentration inequalities using the entropy method », Annals of Probability,