Robot d'indexation
Un robot d'indexation (en anglais web crawler ou web spider, littéralement araignée du Web) est un logiciel qui explore automatiquement le Web. Il est généralement conçu pour collecter les ressources (pages Web, images, vidéos, documents Word, PDF ou PostScript, etc.), afin de permettre à un moteur de recherche de les indexer.
Fonctionnant sur le même principe, certains robots malveillants (spambots) sont utilisés pour archiver les ressources ou collecter des adresses électroniques auxquelles envoyer des courriels.
En français, depuis 2013, crawler est remplaçable par le mot collecteur[1].
Il existe aussi des collecteurs analysant finement les contenus afin de ne ramener qu'une partie de leur information.
Principes d'indexation
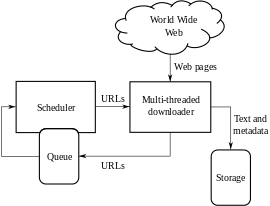
Pour indexer de nouvelles ressources, un robot procède en suivant récursivement les hyperliens trouvés à partir d'une page pivot. Par la suite, il est avantageux de mémoriser l'URL de chaque ressource récupérée et d'adapter la fréquence des visites à la fréquence observée de mise à jour de la ressource. Toutefois, si le robot respecte les règles du fichier robots.txt, alors de nombreuses ressources échappent à cette exploration récursive. Cet ensemble de ressources inexploré est appelé Web profond ou Web invisible.
Un fichier d'exclusion (robots.txt) placé dans la racine d'un site Web permet de donner aux robots une liste de ressources à ignorer. Cette convention permet de réduire la charge du serveur Web et d'éviter des ressources sans intérêt. Toutefois, certains robots ne se préoccupent pas de ce fichier.
Deux caractéristiques du Web compliquent le travail du robot d'indexation : le volume de données et la bande passante. Les capacités de traitement et de stockage des ordinateurs ainsi que le nombre d'internautes ayant fortement progressé, cela lié au développement d'outils de maintenance de pages de type Web 2.0 permettant à n'importe qui de mettre facilement en ligne des contenus, le nombre et la complexité des pages et objets multimédia disponibles, et leur modification, s'est considérablement accru dans la première décennie du XXIe siècle. Le débit autorisé par la bande passante n'ayant pas connu une progression équivalente, le problème est de traiter un volume toujours croissant d'information avec un débit relativement limité. Les robots ont donc besoin de donner des priorités à leurs téléchargements.
Le comportement d'un robot d'indexation résulte de la combinaison des principes suivants :
- Un principe de sélection, qui définit quelles pages télécharger ;
- Un principe de re-visite, qui définit quand vérifier s'il y a des changements dans les pages ;
- Un principe de politesse, qui définit comment éviter les surcharges de pages Web (délais en général) ;
- Un principe de parallélisation, qui définit comment coordonner les robots d'indexations distribués.
Les robots du Web 3.0
Le Web 3.0 définit des techniques avancées et de nouveaux principes de recherche sur Internet qui devront s'appuyer en partie sur les normes du Web sémantique. Les robots du Web 3.0 exploiteront des méthodes d'indexation impliquant des associations personne-machine plus intelligentes que celles qui sont pratiquées aujourd'hui.
Le Web sémantique se distingue de la sémantique appliquée aux langues : tandis que la sémantique linguistique comprend les significations des mots composés ainsi que les relations entre tous les mots d'une langue, le Web sémantique ne représente que l'architecture des relations et des contenus présents sur le Web.
Robots
- AppleBot, robot d'indexation d'Apple, supporte également l'assistant Siri.
- Baiduspider est le robot d'indexation du moteur de recherche chinois Baidu.
- Heritrix est le robot d'archivage de l'Internet Archive. Il a été écrit en Java.
- OrangeBot est le robot d'indexation du moteur d'Orange LeMoteur. Il possède sa propre base de données mise à jour par le robot.
- HTTrack est un logiciel aspirateur de site internet qui crée des miroirs des sites Web pour une utilisation hors ligne. Il est distribué sous la licence GPL.
- Googlebot de Google
- Qwantify est le robot du moteur de recherche Qwant.
- OpenSearchServer est un robot d'indexation de site Internet. Publié sous licence GPL, il s'appuie sur Lucene pour l'indexation.
- Nutch est un robot de collecte écrit en Java et publié sous Licence Apache. Il peut être utilisé avec le projet Lucene de la fondation Apache.
- Scooter de AltaVista
- MSNBot de MSN et Bing
- Slurp de Yahoo!
- ExaBot d'Exalead
- GNU Wget est un logiciel libre en ligne de commande écrit en C automatisant les transferts vers un client HTTP.
- YacyBot est le robot du moteur de recherche YaCy[2].
- BingBot, Adidxbot, BingPreview de Bing
- DuckDuckBot de DuckDuckGo
- AynidBot du moteur de recherche Aynid.
- WebCrawler a été utilisé pour construire le premier index public, en texte intégral, d'un sous-ensemble du Web. Son robot d'exploration en temps réel suivait les liens, en fonction de la similarité du texte associé à l'ancre, avec la requête fournie.
Robots historiques
- World Wide Web Worm était un crawler utilisé pour construire un index simple de titres de documents et d'URL. L'index pouvait être consulté à l'aide de la commande Unix grep.
- Yahoo! Slurp était le robot de Yahoo! Search jusqu'à ce que Yahoo! passe un contrat avec Microsoft pour utiliser Bingbot à la place,
Notes et références
- Olivier Robillart, « Collecteur et enregistreur de frappe remplacent les termes "Crawler" et "Keylogger" », Clubic, .
- (en) « YaCy-Bot », 2012.