PageRank
Le PageRank[alpha 1] ou PR est l'algorithme d'analyse des liens concourant au système de classement des pages Web utilisé par le moteur de recherche Google. Il mesure quantitativement la popularité d'une page web. Le PageRank n'est qu'un indicateur parmi d'autres dans l'algorithme qui permet de classer les pages du Web dans les résultats de recherche de Google. Ce système a été inventé par Larry Page, cofondateur de Google[1]. Ce mot est une marque déposée.

Le théorème de point fixe est le concept mathématique qui a rendu possible le calcul du PageRank.
Fonctionnement
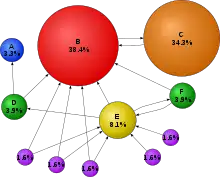
Le principe de base est d'attribuer à chaque page une valeur (ou score) proportionnelle au nombre de fois que passerait par cette page un utilisateur parcourant le graphe du Web en cliquant aléatoirement, sur un des liens apparaissant sur chaque page. Ainsi, une page a un PageRank d'autant plus important qu'est grande la somme des PageRanks des pages qui pointent vers elle (elle comprise, s'il y a des liens internes). Le PageRank est une mesure de centralité sur le réseau du web.
Plus formellement, le déplacement de l'utilisateur est une marche aléatoire sur le graphe du Web, c'est-à-dire le graphe orienté dont les sommets représentent les pages du Web et les arcs les hyperliens. En supposant que l'utilisateur choisisse chaque lien indépendamment des pages précédemment visitées (le réalisme d'une telle hypothèse pouvant être discuté), il s'agit d'un processus de Markov. Le PageRank est alors simplement la probabilité stationnaire d'une chaîne de Markov, c'est-à-dire un vecteur de Perron-Frobenius de la matrice d'adjacence du graphe du Web[2] - [3]. La taille (gigantesque) de ce graphe et son évolution dynamique (modifications de pages et hyperliens, connexion ou déconnexion de serveur web…) rendent cependant impossible un calcul direct de ce vecteur propre : des algorithmes d'approximation sont utilisés.
De nombreuses corrections et améliorations ont été apportées à cet algorithme, certaines étant décrites dans le brevet déposé le [4], d'autres ne restant connues que de Google. En particulier, il est important de garantir que des modifications trop locales du graphe du Web n'entraînent pas d'augmentation disproportionnée du PageRank de certaines pages, ceci afin d'éviter que des utilisateurs (par exemple des sites commerciaux) ne « boostent » artificiellement leur PageRank. Par exemple, dans l'algorithme de base décrit ci-dessus, ajouter de nombreux liens internes sur une page Web (ce qui est très simple à faire pour un particulier) permet d'augmenter son PageRank (cette stratégie ne marche pas avec le PageRank actuel de Google).
Jusqu'en 2016, les internautes pouvaient obtenir une approximation du classement de chaque page en consultant la zone PageRank de la barre d'outils Google, qui indiquait sa valeur sur une échelle de 0 à 10 (Échelle logarithmique). Jusqu'à cette date, il existait aussi de nombreux outils pour l'obtenir sans afficher la toolbar, même s'ils se basaient eux aussi sur la valeur renvoyée par la barre d'outils de Google. Depuis 2016[5], Google ne fournit plus aucune valeur de PageRank, il est donc impossible de le connaître désormais. Ainsi, certaines sociétés privées telles que Moz et Majestic SEO tentent de s'en approcher par le biais de leurs indicateurs (citation flow, trust flow, Domain authority, page authority) afin d'avoir une idée du PageRank Réel et permettent aux webmasters de comparer les différents sites.
Historique
Les précurseurs
Avant l’invention du PageRank, il y eut les tentatives d’Archie en 1990 et de Veronica en 1992 ; le WebCrawler de Brain Pinkerton en 1994 ; et le moteur d’AltaVista de Louis Monnier en 1995[6].
L’algorithme de Google s’inspire du Science Citation Index (SCI) fondé par Eugène Garfield en 1964, un indice de classement des articles scientifiques en fonction du nombre de citations produit par l'Institute for Scientific Information (ISI)[6] - [7]. Google reprend le principe de la citation et y substitue la notion de lien entrant.
En 1996, Jon Kleinberg soulève à IBM l’idée d’un classement à partir de la structure des liens hypertextes (par opposition à l’analyse sémantique). Le chercheur de l’université Cornell sera lui aussi une source d’inspiration pour les créateurs de PageRank[6].
La naissance de PageRank
L’idée de PageRank est officiellement présentée pour la première fois en 1998 par Sergey Brin et Larry Page, les fondateurs de Google, dans « The Anatomy of a Large-Scale Hypertexual Web Search Engine[8] »[6].
Le premier brevet, Method for Node Ranking in a Linked Database[9], est cependant déposé dès avant d’être enregistré le . Il est d’abord la propriété de l'Université Stanford[10], qui octroie ensuite la licence à Google la même année (amendée en 2000 et 2003), deux mois après sa fondation. Il s'agissait d'une licence exclusive jusqu'en 2011[11]. Les recherches qui ont abouti au développement de la technologie du PageRank ont été financées en partie par la National Science Foundation[12]. Il est donc précisé dans le brevet que le gouvernement a certains droits sur cette invention[13].
Principaux critères du score d'une page web
Selon le brevet Google, les critères de classement sont :
- les liens entrants et sortants;
- les ancres;
- le trafic associé à la page;
- le comportement des internautes : le choix de la page dans les résultats;
- le nom de domaine.
Outils et valeurs
Le TrustRank
Il s'agit d'un critère d'autorité accordé aux pages, du fait que l'auteur dispose d'une qualité de sérieux et de compétence reconnue. Ce critère est associé aux sites gouvernementaux, et aux sites de référence tels le W3C. Le terme TrustRank vient de Yahoo! et non pas de Google, qui cependant inclut aussi un critère de confiance dans le calcul du positionnement.
Le PageRank thématique
Le monde du référencement s'accorde à dire aujourd'hui que Google a introduit des valeurs sémantiques dans le calcul du PageRank[14]. Le vote d'une page vers une autre, représenté par un lien, est pondéré par la thématique de la page émettrice. Le corpus de mots utilisés influence le classement d'une page dans les résultats du moteur de recherche, mais aussi la valeur des liens qu'elle transmet.
nofollow
La valeur nofollow de l'attribut HTML rel a été définie par Google en 2005, hors des processus normatifs du W3C. Selon Google, un lien ainsi qualifié dans une page Web ne transmet aucune valeur de PageRank aux pages ainsi liées[15] - [3].
Le , Matt Cutts, responsable de qualité de l'index de Google, a annoncé[16] un changement de traitement des liens en nofollow. Ce type de lien continuera à être ignoré mais sera indirectement pris en compte dans la formule de calcul. Ce changement de traitement est une réaction à l'usage abusif effectué par les webmasters (PageRank Sculpting). D'une manière générale, la nouvelle formule prend en compte tous les liens présents dans une page (même les liens javascript[17] ou publicitaires).
Futur PageRank
Beaucoup d'outils proposent de calculer le futur classement d'une page après le prochain passage du googlebot. Ces outils ne sont pas fiables car ils se basent uniquement sur la valeur « RK » de la somme de contrôle de Google. L'utilité de cette donnée n'est connue que de Google et n'a rien à voir avec un futur PageRank, sauf sur les analyses transactionnelles.
La balise Canonical
La balise Canonical[18], qui doit être incluse entre les balises <head> et </head>, permet de faire le tri entre plusieurs pages qui ont le même contenu et ne donner aux moteurs de recherche qu'une seule page à crawler. On va alors transférer la valeur des doublons à une seule page, la page canonique. La balise canonique peut aussi être utilisée d'un site A vers un site B.
Critique
La façon de classer, de trier et de hiérarchiser des algorithmes n'est pas objective. Elle est toujours fondée sur une conception particulière de ce qui est important et légitime[19]. PageRank ne fait pas exception à ce constat.
Le premier critère de PageRank renvoie au classement des pages à partir des liens entrants : plus le nombre de pages citant un document est grand, plus ce document est considéré comme important. Ce principe de classement n’est pas neutre ou objectif. Il renvoie à une conception de la crédibilité des contenus, qui s’oppose à un autre principe de légitimation : l’autorité — principe pris en compte par le TrustRank. Le principe de classement de PageRank fait correspondre visibilité — plutôt que qualité — et légitimité. Le principal problème est que l'algorithme ne prend pas en considération les raisons pour lesquelles un article est cité[19], et il arrive couramment qu'un contenu soit cité justement parce qu’il est faux, ce qui lui fait inopportunément gagner de l'importance dans le classement de PageRank.
La course aux liens et le Matthew Effect
L'autre problème possible correspond au Matthew Effect[20] : le classement élevé — en fonction de la fréquence de citation — d'un article entraîne d’autres citations, ce qui crée une boucle qui rend de plus en plus visible — et donc légitime — un ensemble restreint de contenus.
Aussi, les référenceurs et les webmestres créent parfois massivement des liens retour, par échanges de liens ou en inscrivant un site sur une quantité d'annuaires, ce qui permettait de gonfler artificiellement l'indice de popularité d'un contenu. Toutefois, Google réagit, d'une part en instaurant des filtres, tels que la Sandbox, d'autre part en détectant et sanctionnant les campagnes massives de liens artificiels ; par ailleurs, il intègre des critères qualitatifs à l'analyse sémantique de la confiance l'indice TrustRank qui entre autres étudie le comportement des utilisateurs.
Sources
- (en) Sergey Brin et Lawrence Page, « The Anatomy of a Large-Scale Hypertextual Web Search Engine », Université de Stanford, (lire en ligne)
- Dominique Cardon, « Dans l'esprit du PageRank : Une enquête sur l'algorithme de Google », Réseaux, vol. 1, no 177, , p. 63-95 (DOI 10.3917/res.177.0063, lire en ligne)
- Matteo Pasquinelli (trad. Clément Blachier, Victor Lockwood et Xiaomeng Zuo), « Google PageRank : une machine de valorisation et d'exploitation de l'attention », dans Yves Citton, L'économie de l'attention : Nouvel horizon du capitalisme ?, Paris, La Découverte, coll. « Sciences humaines », , 328 p. (ISBN 9782707178701, lire en ligne), p. 161-178
- Henk van Ess (trad. du néerlandais de Belgique par Jean-Marc Delprato), Da Google Code, Montreuil, Pearson Education France, , 157 p. (ISBN 978-2-7440-2460-3 et 2744024600, lire en ligne)
- Bruno-Bernard Simon: Vos recherches avec Google[21], 2014.
- Site internet de Travaux d'intérêt personnel encadré : PageRank.
Notes et références
Notes
- Antonomase du nom de marque inventé par Larry Page, cofondateur de Google, composé des mots anglais page (« page ») et rank (« rang »).
Références
- TIC Mag, « Le Top 10 des milliardaires high tech les plus riches du monde en 2016 - TIC Mag », TIC Mag, (lire en ligne, consulté le )
- [PDF] Le théorème de Perron-Frobenius, document pour l'agrégation de mathématiques par B. Bekka, Université de Rennes 1.
- [PDF] Comment fonctionne le PageRank ?, explication mathématique de l'algorithme PageRank par M. Eisermann, Université Grenoble 1.
- Comment Google attribue un score à une page Web.
- « Tout savoir sur le PageRank de Google »
- Dominique Cardon, « Dans l'esprit du PageRank : Une enquête sur l'algorithme de Google », Réseaux, vol. 1, no 177, , p. 63-95 (DOI 10.3917/res.177.0063, lire en ligne)
- (en) Eugene Garfield, « The evolution of the Science Citation Index », International Microbiology, vol. 20, , p. 65-69 (ISSN 1139-6709, lire en ligne)
- (en) Sergey Brin et Lawrence Page, « The Anatomy of a Large-Scale Hypertextual Web Search Engine », Université de Stanford, (lire en ligne)
- US 6.285.999 B1.
- Le texte du brevet est accessible sur le site du bureau des brevets des États-Unis (l'USPTO).
- Le texte du contrat de licence, dans sa version amendée de 2003, est accessible à cette adresse.
- (Grant NSF - IRI-9411306-4).
- « The Government has certain rights in the invention. » Voir le texte du brevet.
- Définition du PageRank thématique.
- « From now on, when Google sees the attribute (rel="nofollow") on hyperlinks, those links won't get any credit when we rank websites in our search results. This isn't a negative vote for the site where the comment was posted; it's just a way to make sure that spammers get no benefit from abusing public areas like blog comments, trackbacks, and referrer lists », source.
- (en) Matt Cutts, « PageRank sculpting », sur MattCutts.com, (consulté le ).
- SEOLand (13 juillet 2010), .
- « Utiliser des URL canoniques », sur google.com.
- Benoît Epron et Marcello Vitali-Rosati, L'édition à l'ère du numérique, Paris, Édition La Découverte, , 114 p. (ISBN 978-2-7071-9935-5, lire en ligne), p. 77
- (en) Robert K. Merton, « The Matthew Effect in Science: The reward and communication systems of science are considered », Science, vol. 159, no 3810, , p. 56–63 (ISSN 0036-8075 et 1095-9203, PMID 5634379, DOI 10.1126/science.159.3810.56, lire en ligne, consulté le )
- Bruno-Bernard Simon, Vos recherches avec Google, Paris, Editions Klog, , 162 p. (ISBN 979-10-92272-01-7).
Liens externes
- Technologie Google Vue d'ensemble sur la technologie du moteur de recherche.
- (en) Web PageRank prediction with Markov models Michalis Vazirgiannis, Dimitris Drosos, Pierre Senellart, Akrivi Vlachou - Research paper