Linguistique quantitative
La linguistique quantitative est une sous-discipline de la linguistique générale et, plus spécifiquement, de la linguistique mathématique. La linguistique quantitative traite de l'apprentissage des langues, de leur évolution et de leur application, ainsi que de la structure des langues naturelles. Elle étudie les langues à l'aide de méthodes statistiques, mais aussi d’autres champs mathématiques[1] Son objectif le plus exigeant est la formulation de lois linguistiques et, finalement, d’une théorie générale du langage, c'est-à-dire d’un ensemble de lois langagières interdépendantes[2]. La linguistique synergétique (la synergie étant une approche transdisciplinaire) a été dès son origine spécialement conçue à cet effet[3]. La linguistique quantitative est fondée sur les résultats des statistiques du langage ou d'objets linguistiques. Ce domaine n'est pas nécessairement lié à des ambitions théoriques substantielles. La linguistique de corpus et la linguistique informatique sont en rapport avec la linguistique quantitative. Elle recouvre toutes les méthodes mathématiques appliquées en linguistique. Comme pour toutes les études transdisciplinaires, le rapport entre mathématiques et linguistiques (quelle que soit l'étude) est une difficulté. Faits initialement par des ingénieurs, mathématiciens etc, ces liens intéressent aussi les linguistes aujourd'hui.
Histoire
Les premières approches de la linguistique quantitative remontent au monde grec et indien antiques. L' une des sources historiques se compose d'applications de combinatoires à des questions linguistiques[4]. Une autre est fondée sur des études statistiques élémentaires. La sténographie et la cryptographie sont les premiers domaines linguistiques à avoir une approche quantitative. Les cryptographes ont ainsi établi des tables de fréquence de lettres, et le sténographe Jean-Baptiste Estoup fut le premier à calculer les fréquences relatives de mots dans un texte[1].
Lois de la langue
En linguistique quantitative, le concept de loi désigne un système de lois déduites d'hypothèses théoriques, formulées mathématiquement, et validées par une démarche scientifique : elles doivent subir de nombreuses expériences et "résister" à toutes les réfutations possibles. Köhler écrit à propos de ces lois : "En outre, il peut être démontré que ces propriétés des éléments linguistiques et des relations entre elles sont conformes à des lois universelles qui peuvent être formulées strictement de manière mathématique, de la même manière qu’elles sont communes dans les sciences naturelles. Rappelez-vous que ces lois sont de nature stochastique [aléatoires, pouvant être bouleversées] et qu'elles ne sont pas observées dans tous les cas (cela ne serait ni nécessaire ni possible), mais plutôt qu'elles déterminent les probabilités des événements ou les proportions étudiées. Il est facile de trouver des contre-exemples. Toutefois, ces cas ne violent pas les lois correspondantes, car les variations autour de la moyenne statistique sont non seulement admissibles mais même essentielles, elles sont elles-mêmes déterminées quantitativement avec exactitude par les lois correspondantes. La situation est identique à celle des sciences naturelles, qui ont depuis longtemps abandonné les anciennes conceptions déterministe et causale du monde pour les remplacer par des modèles probabilistes. " [5]
Quelques lois linguistiques
Il existe un grand nombre de lois linguistiques proposées, parmi lesquelles[6] :
- diversification : si des catégories linguistiques telles que des parties du discours ou des terminaisons flexionnelles (une flexion étant une variation d'un radical, ex. conjugaison, déclinaison) apparaissent sous différentes formes, on peut montrer que les fréquences de leur occurrence dans les textes sont contrôlées par des lois ;
- distributions de longueur (ou plus généralement de complexité) : l’enquête de fréquences de textes ou de dictionnaires d’unités de tout genre en ce qui concerne leur longueur produit régulièrement un certain nombre de distributions, en fonction du type donné de l’unité à l’étude. À ce jour, les distributions suivantes ont été étudiées:
- longueurs de morphèmes (unités de sens)
- longueurs des unités rythmiques ;
- répartition des durées des phrases ;
- longueurs syllabiques ;
- longueurs de mots ;
Cette loi s'applique à d'autres unités : les lettres ou caractères de complexité différentes, par exemple. Il en va de même pour les distributions de sons (phonèmes, unité de son) de différentes durées.
- Loi de Martin. Elle concerne les chaînes lexicales obtenues en cherchant la définition d'un mot dans un dictionnaire, puis en cherchant la définition de la définition que l'on vient d'obtenir, etc. Enfin, toutes ces définitions forment une hiérarchie de significations de plus en plus générales, de sorte que le nombre de définitions diminue avec la généralité croissante. Parmi les niveaux de ce type de hiérarchie, il existe des lois liées à cette relation.
- Loi de Menzerath (ou loi Menzerath-Altmann). Elle stipule que la taille des composants (mots, syllabes…) d'une construction (phrase, mot…) est inversement proportionnelle à la taille de la construction étudiée. Ainsi, plus une phrase est longue (par exemple, en termes de nombre de clauses), plus les clauses sont courtes (en termes de nombre de mots), ou bien plus un mot est long (en syllabes ou morphes) moins les syllabes comptent de sons.
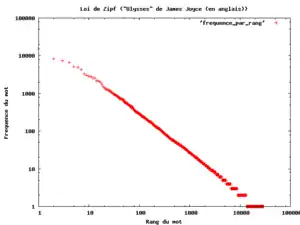
- Lois de la fréquence de rang. Pratiquement n'importe quel type d'unité linguistique respecte ces relations. Les mots d'un texte sont classés selon leur fréquence et se voient attribuer un numéro de classement et la fréquence correspondante. Depuis George Kingsley Zipf (auteur de la «loi de Zipf»), un grand nombre de modèles mathématiques de la relation entre rang et fréquence ont été proposés comme : des sons, phonèmes et lettres, des associations avec lesquelles les sujets réagissent sur un stimulus (mot)[7].
- Loi du changement de langue. Elle concerne les processus de croissance dans la langue, tels que la croissance du vocabulaire, la dispersion de mots étrangers ou d'emprunts, les modifications du paradigme, etc. La loi de Piotrowski est un cas du modèle dit logistique (cf. équation logistique). Elle concerne également les processus d’acquisition du langage (cf. loi sur l’acquisition du langage).
- Loi sur les blocs de texte. Les unités linguistiques (mots, lettres, fonctions syntaxiques et constructions, par exemple) montrent une distribution de fréquence spécifique dans des blocs de texte de taille égale.
Linguistique et théorie de l'information
La théorie de l'information découle de la statistique en linguistique. Théorisée par Claude Shannon, elle quantifie les informations d'un ensemble de message grâce au codage informatique suivant des lois de probabilités. Née après la Seconde Guerre mondiale, elle est appliquée aux téléphones pour réduire le coût de transport d'informations. Elle propose un modèle général de la communication utilisé en linguistique, où le bruit désigne ce qui perturbe l'émission du message (par exemple longue distance, inattention, bruit dans le sens courant).
Pour illustrer ce modèle, l'émetteur peut être un locuteur, un appareil de radio, le canal l'air, la ligne téléphonique. Ainsi, le linguiste Roman Jakobson utilise ce modèle pour définir six fonctions du langage, qui varient selon les paramètres de ce modèle (c'est-à-dire du canal, de l'émetteur, du message). Chaque unité linguistique (par exemple, lettre, phonème) est codée ; un lien est fait entre unité du message et unité du code. Réduire le coût d'émission revient donc à réduire le nombre de liens. Ce dernier dépend du nombre d'unités, mais aussi de la fréquence d'apparition de celles-ci : ainsi, une unité se caractérise par sa fréquence d'apparition. Cela suppose un calcul de la fréquence d'éléments linguistiques ; en cela c'est une application directe de la statistique. L'information apportée par une unité est inversement proportionnelle à sa fréquence (intuitivement, on peut se dire qu'une unité rare apporte de l'information). La redondance désigne un signe n'apportant aucune information donc dont la probabilité vaut 1. Un système non redondant ne contient pas de telles unités :
| Système redondant | Système non redondant |
|---|---|
| Contenant des unités sans information | Ne contenant pas d'unités sans information |
| Exemples : combinaison de son ou système alphabétique | Exemple : système numérique |
| Application : "j'pr'l'tr'"="je prends le train", "peux venir demain"="je pourrai venir demain" | Application : "82,7"≠"823,74" |
L'étude de la redondance s'étend à tous les éléments linguistiques ; elle a une valeur pratique (économie de l'information, élimination d'informations superflues) ou artistique (notamment en poésie)[1].
Stylistique
L’étude des styles aussi bien poétiques que non poétiques peut se fonder sur des méthodes statistiques ; de plus, il est possible de mener des recherches correspondantes sur la base de formes spécifiques (paramètres) que les lois linguistiques prennent dans des textes de styles différents. Dans de tels cas, la linguistique quantitative soutient la recherche en stylistique : l’un des objectifs généraux est de proposer des preuves aussi objectives que possible, y compris dans au moins une partie du domaine des phénomènes stylistiques, en faisant référence aux lois de la langue. L'une des hypothèses centrales de la linguistique quantitative est que certaines lois (par exemple, la distribution des longueurs de mots) nécessitent des modèles différents, au moins des valeurs de paramètre différentes des lois (distributions ou fonctions) selon le type d'un texte. Dans l'étude de poèmes, les méthodes quantitatives en linguistique forment une sous-discipline de l’étude quantitative de la littérature (stylométrie)[8].
Linguistique et logique
Avec la logique s'intéressant à l'articulation de la pensée, et le langage l'exprimant, il existe un lien entre linguistique et logique (comme le reflète l'analyse logique). L'utilisation de la logique justifiant la prescription ne relève cependant pas de la linguistique). Les notions d'inférence ou de transitivité s'appliquent en linguistique et en logique. Un énoncé logique est parfois limité par des imprécisions linguistiques : ainsi, la nature exacte de la coordination par la conjonction "et" est un problème sémantique, ainsi que la transitivité entre un élément et sa classe. Cette dernière incertitude est fondée sur des ambiguïtés logiques : soit, par exemple, les propositions "un chat est un animal" et "un éléphant est un animal". Peut-on inférer qu"un petit chat est un petit animal"? Et qu'"un petit éléphant est un petit animal"[1] ?
Linguistes dans ce domaine
- Gabriel Altmann (1931-2020) [9]
- Otto Behaghel (1854-1936); cf. Lois de Behaghel
- Karl-Heinz Best [10] - [11]
- Sergej Grigor'evič Čebanov (1897-1966) [12]
- William Palin Elderton (1877-1962) [13]
- Gertraud Fenk-Oczlon [14]
- Ernst Wilhelm Förstemann (1822–1906) [15]
- Wilhelm Fucks (1902–1990) [16]
- Peter Grzybek (1957-2019)
- Gustav Herdan (1897-1968)[17] - [18] ;
- Luděk Hřebíček (1934) [19]
- Friedrich Wilhelm Kaeding (1843-1928) [20]
- Reinhard Köhler
- Snježana Kordić (1964) [21] - [22]
- Werner Lehfeldt (1943) [23]
- Viktor Vasil'evič Levickij (1938-2012) [24]
- Haitao Liu [25]
- Helmut Meier (1897-1973)
- Paul Menzerath (1883-1954)[26], cf. loi de Menzerath
- Sizuo Mizutani (1926) [27]
- Auguste de Morgan (1806-1871).
- Charles Muller, Straßburg [28]
- Raijmund G. Piotrowski [29] - [30]
- LA Sherman
- Juhan Tuldava (1922-2003) [31]
- Andrew Wilson, Lancaster [32]
- Albert Thumb (1865-1915) [33]
- George Kingsley Zipf (1902-1950); cf. loi de Zipf
- Eberhard Zwirner (1899-1984). Phonométrie [34]
Voir aussi
Notes
- « linguistique quantitative », sur fracademic.com, (consulté le )
- Reinhard Köhler: Gegenstand und Arbeitsweise der Quantitativen Linguistik. In: Reinhard Köhler, Gabriel Altmann, Rajmund G. Piotrowski (Hrsg.): Quantitative Linguistik - Quantitative Linguistics. Ein internationales Handbuch. de Gruyter, Berlin/ New York 2005, pp. 1–16.
- Reinhard Köhler: Synergetic linguistics. In: Reinhard Köhler, Gabriel Altmann, Rajmund G. Piotrowski (Hrsg.): Quantitative Linguistik - Quantitative Linguistics. Ein internationales Handbuch. de Gruyter, Berlin/ New York 2005, pp. 760–774. (ISBN 3-11-015578-8).
- N.L. Biggs: The Roots of Combinatorics. In: Historia Mathematica 6, 1979, pp. 109–136.
- cf. note 1, pp. 1–2.
- cf. references: Köhler, Altmann, Piotrowski (eds.) (2005)
- H. Guiter, M. V. Arapov (eds.): Studies on Zipf's Law. Bochum: Brockmeyer 1982. (ISBN 3-88339-244-8).
- Alexander Mehler: Eigenschaften der textuellen Einheiten und Systeme. In: Reinhard Köhler, Gabriel Altmann, Rajmund G. Piotrowski (Hrsg.): Quantitative Linguistik - Quantitative Linguistics. Ein internationales Handbuch. de Gruyter, Berlin/ New York 2005, p. 325-348, esp. Quantitative Stilistik, pp. 339–340. (ISBN 3-11-015578-8); Vivien Altmann, Gabriel Altmann: Anleitung zu quantitativen Textanalysen. Methoden und Anwendungen. Lüdenscheid: RAM-Verlag 2008, (ISBN 978-3-9802659-5-9).
- Grzybek, Peter, & Köhler, Reinhard (eds.) (2007): Exact Methods in the Study of Language and Text. Dedicated to Gabriel Altmann on the Occasion of his 75th Birthday. Berlin/ New York: Mouton de Gruyter
- de:Benutzer:Dr._Karl-Heinz_Best
- index
- de:Sergei Grigorjewitsch Tschebanow
- Best, Karl-Heinz (2009): William Palin Elderton (1877-1962). Glottometrics 19, p. 99-101 (PDF ram-verlag.eu).
- Homepage_Gertraud Fenk
- de:Ernst Förstemann; Karl-Heinz Best: Ernst Wilhelm Förstemann (1822-1906). In: Glottometrics 12, 2006, pp. 77–86 (PDF ram-verlag.eu)
- Dieter Aichele: Das Werk von W. Fucks. In: Reinhard Köhler, Gabriel Altmann, Rajmund G. Piotrowski (Hrsg.): Quantitative Linguistik - Quantitative Linguistics. Ein internationales Handbuch. de Gruyter, Berlin/ New York 2005, pp. 152–158. (ISBN 3-11-015578-8)
- de:Gustav Herdan
- Herdan dimension - Laws in Quantitative Linguistics
- de:Luděk Hřebíček
- de:Friedrich Wilhelm Kaeding
- (de) Snježana Kordić, Wörter im Grenzbereich von Lexikon und Grammatik im Serbokroatischen [« Mots dans la zone frontalière du lexique et de la grammaire en serbocroate »], Munich, Lincom Europa, coll. « Studies in Slavic Linguistics » (no 18), , 280 p. (ISBN 3-89586-954-6, OCLC 47905097, LCCN 2005530314, DNB 963264087, SUDOC 083721398, présentation en ligne), p. 280
- (de) Snježana Kordić, Der Relativsatz im Serbokroatischen [« La proposition relative en serbocroate »], Munich, Lincom Europa, coll. « Studies in Slavic Linguistics » (no 10), (réimpr. 2002 et 2005) (1re éd. 1999), 330 p. (ISBN 978-3-89586-573-2 et 3-89586-573-7, OCLC 42422661, DNB 956417647, présentation en ligne, lire en ligne), p. 330
- Georg-August-Universität Göttingen - Lehfeldt, Werner, Prof. em. Dr
- Festschrift on the occasion of the 70. anniversary: Problems of General, Germanic and Slavic Linguistics. Papers for 70th Anniversary of Professor V. Levickij. Herausgegeben von Gabriel Altmann, Iryna Zadoroshna, Yuliya Matskulyak. Books, Chernivtsi 2008. (No ISBN.) Levickij dedicated: Glottometrics, Heft 16, 2008; Emmerich Kelih: Der Czernowitzer Beitrag zur Quantitativen Linguistik: Zum 70. Geburtstag von Prof. Dr. Habil. Viktor V. Levickij. In: Naukovyj Visnyk Černivec’koho Universytetu: Hermans’ka filolohija. Vypusk 407, 2008, pp. 3–10.
- Human-Language-Computer - staff Homepage, ZJU
- Karl-Heinz Best: Paul Menzerath (1883-1954). In: Glottometrics 14, 2007, pp. 86–98 (PDF ram-verlag.eu)
- Shizuo Mizutani; Portrait on the occasion of his 80. anniversary in: Glottometrics 12, 2006 PDF ram-verlag.eu); about Mizutani: Naoko Maruyama: Sizuo Mizutani (1926). The Founder of Japanese Quantitative Linguistics. In: Glottometrics 10, 2005, pp. 99–107(PDF ram-verlag.eu).
- Charles Muller: Initiation à la statistique linguistique. Paris: Larousse 1968; German: Einführung in die Sprachstatistik. Hueber, München 1972.
- Rajmund G. Piotrowski, R.G. Piotrovskij; cf. Piotrowski's law: http://lql.uni-trier.de/index.php/Change_in_language
- de:Piotrowski-Gesetz
- Journal of Quantitative Linguistics 4, Nr. 1, 1997 (Festschrift in Honour of Juh. Tuldava)
- Dr Andrew Wilson - Linguistics and English Language at Lancaster University
- de:Albert Thumb
- de:Eberhard Zwirner
Références
- Karl-Heinz Best: Linguistik quantitative. Eine Annäherung . 3., stark überarbeitete und ergänzte Auflage. Peust & Gutschmidt, Göttingen 2006, (ISBN 3-933043-17-4) . En allemand.
- Karl-Heinz Best, Otto Rottmann: La linguistique quantitative, une invitation. RAM-Verlag, Lüdenscheid 2017. (ISBN 978-3-942303-51-4). En anglais.
- Pierre Guiraud: Bibliographie critique de la statistique linguistique. Éditions Spectrum, Utrecht/Anvers 1954.
- Reinhard Köhler avec l'aide de Christiane Hoffmann: Bibliographie de linguistique quantitative. Benjamins, Amsterdam / Philadelphie 1995, (ISBN 90-272-3751-4) .
- Reinhard Köhler, Gabriel Altmann, Gabriel, Rajmund G. Piotrowski (eds. ): Linguistik quantitative - Linguistique quantitative. Ein internationales Handbuch - Un manuel international . de Gruyter, Berlin / New York 2005, (ISBN 3-11-015578-8).
- Jacqueline Léon, Sylvain Loiseau (eds.): History of Quantitative Linguistics in France. RAM-Verlag, Lüdenscheid 2016. (ISBN 978-3-942303-48-4).
- Haitao Liu et Wei Huang. Linguistique quantitative: état de l'art, théories et méthodes . Journal de l'Université du Zhejiang (sciences humaines et sociales) . 2012-2043 (2): 178-192. En chinois.