Méthode de la transformée inverse
La méthode de la transformée inverse est une méthode permettant d'échantillonner une variable aléatoire X de loi donnée à partir de l'expression de sa fonction de répartition F et d'une variable uniforme sur [0, 1].
| Type |
Méthode statistique (d) |
|---|
Principe
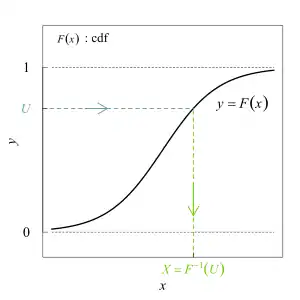
Cette méthode repose sur le principe suivant, parfois connu sous le nom de théorème de la réciproque : soient F une fonction de répartition, Q la fonction quantile associée, et U une variable uniforme sur [0, 1]. Alors, la variable aléatoire X = Q(U) a pour fonction de répartition F. Ainsi, pour échantillonner une variable aléatoire de loi donnée, il suffit de savoir échantillonner des variables uniformes sur [0, 1] et de pouvoir calculer la fonction quantile de la loi souhaitée.
Le nom méthode de la transformée inverse provient du fait que la fonction quantile n'est autre que l'inverse généralisé à gauche de la fonction de répartition :

En particulier, si la fonction de répartition F est continue et strictement croissante, alors elle est bijective et Q = F−1 est sa bijection réciproque.
Exemples
Pour certaines lois, on sait inverser la fonction de répartition F, comme le montre la liste suivante :
| Fonction de répartition F | Fonction de répartition inverse F−1(U) | |
|---|---|---|
| loi exponentielle de paramètre λ | ||
| loi de Cauchy standard | ||
| loi logistique standard | ||
| loi de Laplace |






![{\displaystyle F(x)=0,5(1+\mathrm {sgn} (x)[1-\mathrm {e} ^{-|x|}])}](https://img.franco.wiki/i/a21fdb912ddce09fabac8dde26a2cf8d40c1e72a.svg)

Ainsi, par exemple, échantillonner une variable selon la loi exponentielle de paramètre λ :
- on tire un nombre U uniformément sur [0, 1]
- on calcule .

A noter ici que, puisque U suit la loi uniforme sur [0, 1] si et seulement si 1 - U suit la loi uniforme sur [0, 1], on pourrait également utiliser . Toutefois, pour des raisons de précision numérique, on utilisera généralement , la fonction qui à x associe ln(1 + x) étant implémentée dans de nombreux langages de programmation.



Calcul de l'inversion
Dans le cas général, on ne sait pas inverser la fonction de répartition F de façon analytique, c'est-à-dire qu'on ne dispose pas d'une formule explicite donnant, pour u appartenant à [0, 1], x tel que F(x) = u. Il faut alors résoudre l'équation F(x) = u numériquement, en utilisant au choix une fonction tabulée, la méthode de dichotomie, la méthode de la fausse position, la méthode de la sécante ou encore la méthode de Newton.
Implémentation
La plupart des langages de programmation permettant de produire des nombres pseudo-aléatoires de distribution uniforme, il suffit de calculer l'antécédent des nombres tirés selon la fonction de répartition F.
Voir aussi
- Aléatoire
- Pseudo-aléatoire
- Générateur de nombres aléatoires
- Générateur de nombres pseudo-aléatoires
- Méthode de rejet
- Cette méthode est aussi importante sur le plan théorique. Voir en particulier le Théorème de la réciproque dans l'article Fonction de répartition.
Références
- (en) Luc Devroye, Non-Uniform Random Variate Generation, New York, Springer-Verlag, (lire en ligne)