Arbre binaire de recherche
En informatique, un arbre binaire de recherche ou ABR (en anglais, binary search tree ou BST) est une structure de données représentant un ensemble ou un tableau associatif dont les clés appartiennent à un ensemble totalement ordonné. Un arbre binaire de recherche permet des opérations rapides pour rechercher une clé, insérer ou supprimer une clé.
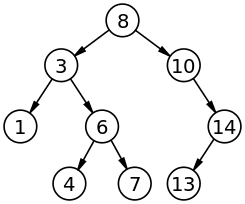
Définition
Définition générale
Un arbre binaire de recherche est un arbre binaire dans lequel chaque nœud possède une clé, telle que chaque nœud du sous-arbre gauche ait une clé inférieure ou égale à celle du nœud considéré, et que chaque nœud du sous-arbre droit possède une clé supérieure ou égale à celle-ci — selon la mise en œuvre de l'ABR, on pourra interdire ou non des clés de valeur égale. Les nœuds que l'on ajoute deviennent des feuilles de l'arbre.
Définitions spécifiques
- Un arbre binaire de recherche est dit complet si tous les niveaux de l'arbre sont remplis, sauf éventuellement le dernier, sur lequel les nœuds sont à gauche.
- Un arbre binaire parfait est un arbre complet dont toutes les feuilles sont à la même hauteur (le dernier niveau est complètement occupé).
- Un arbre binaire est dit dégénéré si chacun de ses nœuds a au plus un fils.
- Un arbre binaire est équilibré si tous les chemins de la racine aux feuilles ont la même longueur.
Opérations
Recherche

La recherche dans un arbre binaire d'un nœud ayant une clé particulière est un procédé récursif. On commence par examiner la racine. Si sa clé est la clé recherchée, l'algorithme se termine et renvoie la racine. Si elle est strictement inférieure, alors elle est dans le sous-arbre gauche, sur lequel on effectue alors récursivement la recherche. De même si la clé recherchée est strictement supérieure à la clé de la racine, la recherche continue dans le sous-arbre droit. Si on atteint une feuille dont la clé n'est pas celle recherchée, on sait alors que la clé recherchée n'appartient à aucun nœud, elle ne figure donc pas dans l'arbre de recherche. On peut comparer l'exploration d'un arbre binaire de recherche avec la recherche par dichotomie qui procède à peu près de la même manière sauf qu'elle accède directement à chaque élément d'un tableau au lieu de suivre des liens. La différence entre les deux algorithmes est que, dans la recherche dichotomique, on suppose avoir un critère de découpage de l'espace en deux parties que l'on n'a pas dans la recherche dans un arbre.
| Entrée = Un arbre binaire de recherche A, une clé e. Sortie = Vrai si la clé est dans l’arbre, faux sinon |
| fonction Recherche(A,e) si A = . renvoyer Faux sinon A = (x,FilsGauche,FilsDroit) si x = e renvoyer Vrai sinon si e < x renvoyer Recherche(FilsGauche,e) sinon renvoyer Recherche(FilsDroit,e) |
Cette opération requiert un temps en O(log(n)) dans le cas moyen, mais O(n) dans le cas critique où l'arbre est complètement déséquilibré et ressemble à une liste chaînée. Ce problème est écarté si l'arbre est équilibré par rotation au fur et à mesure des insertions pouvant créer des listes trop longues.
Insertion
L'insertion d'un nœud commence par une recherche : on cherche la clé du nœud à insérer ; lorsqu'on arrive à une feuille, on ajoute le nœud comme fils de la feuille en comparant sa clé à celle de la feuille : si elle est inférieure, le nouveau nœud sera à gauche ; sinon il sera à droite.
fonction Insertion(A,e)
Si A = .
retourner (e,.,.)
Sinon A = (x,FilsGauche,FilsDroit)
Si e < x
retourner (x,Insertion(FilsGauche,e),FilsDroit)
Sinon
retourner (x,FilsGauche,Insertion(FilsDroit,e))
La complexité est la même que pour la recherche : O(log n) dans le cas moyen et O(n) dans le cas critique.
Il est aussi possible d'écrire une procédure d'ajout d'élément à la racine d'un arbre binaire. Cette opération requiert la même complexité mais est meilleure en termes d'accès aux éléments.
Il est aussi possible d'écrire une procédure d'ajout d'élément à la racine d'un arbre binaire. Cette opération requiert la même complexité mais est meilleure en termes d'accès aux éléments.
Suppression
On commence par rechercher la clé du noeud à supprimer dans l'arbre. Plusieurs cas sont à considérer, une fois que le nœud à supprimer a été trouvé à partir de sa clé :
- Suppression d'une feuille : Il suffit de l'enlever de l'arbre puisqu'elle n'a pas de fils.
- Suppression d'un nœud avec un enfant : Il faut l'enlever de l'arbre en le remplaçant par son fils.
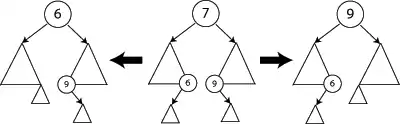
- Suppression d'un nœud avec deux enfants : Supposons que le nœud à supprimer soit appelé N (le nœud de valeur 7 dans le graphique ci-dessous). On échange le nœud N avec son successeur le plus proche (le nœud le plus à gauche du sous-arbre droit, ci-dessous, le nœud de valeur 9) ou son plus proche prédécesseur (le nœud le plus à droite du sous-arbre gauche, ci-dessous, le nœud de valeur 6). Cela permet de garder à la fin de l'opération une structure d'arbre binaire de recherche. Puis on applique à nouveau la procédure de suppression à N, qui est maintenant une feuille ou un nœud avec un seul fils.
fonction Suppression(A,e)
si A = .
retourner .
sinon A = (x,FilsGauche,FilsDroit)
si e > x
retourner (x,FilsGauche,Suppression(FilsDroit,e))
si e < x
retourner (x,Suppression(FilsGauche,e),FilsDroit)
sinon x = e
si FilsGauche = . et FilsDroit = .
retourner .
si FilsGauche = .
retourner FilsDroit
si FilsDroit = .
retourner FilsGauche
sinon
y = Max(FilsGauche)
retourner (y,Suppression(FilsGauche,y),FilsDroit)
Ce choix d'implémentation peut contribuer à déséquilibrer l'arbre. En effet, puisque ce sont toujours des feuilles du sous-arbre gauche qui sont supprimées, une utilisation fréquente de cette fonction amènera à un arbre plus lourd à droite qu'à gauche. On peut remédier à cela en alternant successivement la suppression du minimum du fils droit avec celle du maximum du fils gauche, plutôt que toujours choisir ce dernier. Il est par exemple possible d'utiliser un facteur aléatoire : le programme aura une chance sur deux de choisir le fils droit et une chance sur deux de choisir le fils gauche.
Dans tous les cas cette opération requiert de parcourir l'arbre de la racine jusqu'à une feuille : le temps d'exécution est donc proportionnel à la profondeur de l'arbre qui vaut n dans le pire des cas, d'où une complexité maximale en O(n).
Applications
Parcours ordonné
Il est possible de parcourir un arbre binaire de recherche par trois manières : un parcours infixe, préfixe ou postfixe. Ces trois algorithmes fonctionnent de manière récursive. Le parcours infixe consiste à, dans l'ordre, faire le parcours infixe du sous-arbre de gauche, récupérer la valeur du nœud, puis faire le parcours infixe du sous-arbre de droite. Alors que le parcours préfixe commence par récupérer la valeur du nœud, puis parcours le sous-arbre de gauche, puis le sous-arbre de droite. Le parcours postfixe commence par le sous-arbre de gauche, puis le sous-arbre de droite, et récupère en la valeur du nœud. Dans les trois cas, le parcours de l'arbre se fait en temps linéaire, puisqu'il doit passer par chaque nœud une seule fois.
fonction ParcoursInfixe(A):
si A = .
retourner []
sinon A = (x,FilsGauche,FilsDroit)
retourner ParcoursInfixe(FilsGauche) + [x] + ParcoursInfixe(FilsDroit)
fonction ParcoursPréfixe(A):
si A = .
retourner []
sinon A = (x,FilsGauche,FilsDroit)
retourner [x] + ParcoursPréfixe(FilsGauche) + ParcoursPréfixe(FilsDroit)
fonction ParcoursPostfixe(A):
si A = .
retourner []
sinon A = (x,FilsGauche,FilsDroit)
retourner ParcoursPostfixe(FilsGauche) + ParcoursPostfixe(FilsDroit) + [x]
Tri
On peut dès lors créer un algorithme de tri simple mais peu efficace, en insérant toutes les clés que l'on veut trier dans un nouvel arbre binaire de recherche puis en parcourant de manière ordonnée cet arbre comme ci-dessus.
A = .
pour e dans L faire
A = Insertion(A,e)
ListeTriee = ParcoursInfixe(A)
Le pire temps d'exécution est en O(n²) où n est le nombre de clés de l'arbre, obtenu lorsque les clés sont déjà ordonnées : on a alors une liste chaînée. Par exemple, si on donne dans cet ordre les clés 1, 2, 3, 4, 5, on obtient l'arbre (Vide, 1, (Vide, 2, (Vide, 3, (Vide, 4, (Vide, 5, Vide))))). Il y a de nombreuses façons d'éviter ce problème, la plus commune étant l'arbre équilibré. On peut alors arriver à un pire cas en O(n*ln(n)).
Files de priorité
Les arbres binaires de recherche peuvent servir d’implémentation au type abstrait de file de priorité. en effet, les opérations d’insertion d’une clé et de test au vide se font avec des complexités avantageuses (respectivement en O(log(n)) et en O(1) où n est le nombre de clés représentées dans l’arbre). Pour l’opération de suppression de la plus grande clé, il suffit de parcourir l’arbre depuis sa racine en choisissant le fils droit de chaque noeud, et supprimer la feuille terminale. cela demande un nombre d’opérations égal à la hauteur de l’arbre, donc une complexité logarithmique en le nombre de clés. L’avantage notoire de cette représentation d’une file de priorité est qu’avec un processus similaire, on dispose d'une opération de suppression de la plus petite clé en temps logarithmique également.
Equilibrage
L'insertion et la suppression s'exécutent en O(h) où h est la hauteur de l'arbre. Cela s'avère particulièrement coûteux quand l'arbre est très déséquilibré (un arbre peigne par exemple, dont la hauteur est linéaire en le nombre de clés), et on gagne donc en efficacité à équilibrer les arbres au cours de leur utilisation. Il existe des techniques pour obtenir des arbres équilibrés, c'est-à-dire pour garantir une hauteur logarithmique en nombre d'éléments :
- Les arbres AVL
- les arbres rouge-noir
- les arbres 2-3
- les arbres 2-3-4
- les B-arbres
Extensions
Un arbre splay est un arbre binaire de recherche qui rapproche automatiquement de la racine les éléments utilisés fréquemment. Dans un treap, chaque nœud possède aussi une priorité supérieure à chacun de ses fils.
Un arbre splay est un arbre binaire de recherche qui rapproche automatiquement de la racine les éléments utilisés fréquemment. Dans un treap, chaque nœud possède aussi une priorité supérieure à chacun de ses fils.