Apprentissage par renforcement profond
L'apprentissage par renforcement profond (en anglais : deep reinforcement learning ou deep RL) est un sous-domaine de l'apprentissage automatique (en anglais : machine learning) qui combine l'apprentissage par renforcement et l'apprentissage profond (en anglais : deep learning). L'apprentissage par renforcement considère le problème d'un agent informatique (par exemple, un robot, un agent conversationnel, un personnage dans un jeu vidéo, etc.) qui apprend à prendre des décisions par essais et erreurs. L'apprentissage par renforcement profond intègre l'apprentissage profond dans la résolution, permettant aux agents de prendre des décisions à partir de données d'entrée non structurées sans intervention manuelle sur l'espace des états. Les algorithmes d'apprentissage par renforcement profond sont capables de prendre en compte de très grandes quantités de données (par exemple, chaque pixel affiché à l'écran dans un jeu vidéo) et de décider des actions à effectuer pour optimiser un objectif (par exemple, maximiser le score du jeu). L'apprentissage par renforcement profond a été utilisé pour diverses d'applications, y compris, de manière non exhaustive, la robotique, les jeux vidéo, le traitement du langage naturel, la vision par ordinateur, l'éducation, les transports, la finance et la santé[1].
Aperçu
L'apprentissage profond

L'apprentissage profond est une forme d'apprentissage automatique utilisant réseaux de neurones artificiels de transformant les données via des réseaux neuronaux convolutifs. Il a été démontré que les méthodes d'apprentissage profond, utilisant souvent l'apprentissage supervisé avec des ensembles de données étiquetés, se sont avérées capable de résoudre des tâches impliquant le traitement de données d'entrée brutes complexes et de grande dimension, telles que des images, avec moins de prétraitement manuel que les méthodes précédemment utilisées, ce qui a permis des progrès significatifs dans plusieurs domaines, notamment vision par ordinateur et traitement automatique du langage naturel (TALN).
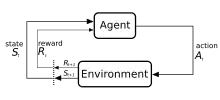
L'apprentissage par renforcement
L'apprentissage par renforcement est un processus dans lequel un agent apprend à prendre des décisions à partie d'expérimentations et d'erreurs. Ce problème est souvent modélisé mathématiquement comme un processus de décision Markovien (MDP), où, à chaque unité de temps, un agent se trouvant dans un état réalise une action , reçoit une récompense scalaire , et passe à l'état suivant selon la dynamique de l'environnement . L'agent tente d'apprendre une politique , ou correspondance des observations aux actions, afin de maximiser ses retours (somme des récompenses attendues). Dans l'apprentissage par renforcement (par opposition au contrôle optimal), l'algorithme n'a accès qu'à la dynamique par le biais de l'échantillonnage.






Apprentissage profond par renforcement
Dans de nombreux problèmes pratiques de prise de décision, l'ensemble des états des processus de décision Markovien est de grande dimension (par exemple, les images d'une caméra ou le flux des capteurs d'un robot) ne peuvent pas être résolus par les algorithmes d'apprentissage par renforcement traditionnels. Les algorithmes d'apprentissage par renforcement profond intègrent un apprentissage profond pour résoudre de tels processus de décision Markovien, représentant souvent la politique ou d'autres fonctions apprises via des réseaux de neurones, et développer des algorithmes spécialisés qui fonctionnent bien dans ce contexte.
Historique
Parallèlement à l'intérêt croissant pour les réseaux de neurones à partir du milieu des années 1980, l'intérêt s'est accru pour l'apprentissage par renforcement en profondeur, où un réseau de neurones est utilisé dans l'apprentissage par renforcement pour représenter des politiques ou des fonctions de valeur. Parce que dans un tel système, l'ensemble du processus de prise de décision, des capteurs aux moteurs dans un robot ou un agent, implique un seul réseau de neurones, il est aussi parfois appelé apprentissage par renforcement de bout en bout. L'une des premières applications réussies de l'apprentissage par renforcement avec les réseaux de neurones était TD-Gammon, un programme informatique développé en 1992 pour jouer au backgammon[2]. Quatre entrées ont été utilisées pour le nombre de pièces d'une couleur donnée à un endroit donné sur la carte, totalisant 198 signaux d'entrée. Sans aucune connaissance intégrée, le réseau a appris à jouer au jeu à un niveau intermédiaire par auto-apprentissage et apprentissage par différence temporelle( ).

Les manuels séminaux de Sutton et Barto sur l'apprentissage par renforcement[3], Bertsekas et Tsitiklis sur la programmation neuro-dynamique[4], et d'autres[5] progresser les connaissances et l'intérêt dans le domaine.
Le groupe de Katsunari Shibata a montré que diverses fonctions émergent dans ce cadre[6] - [7], notamment la reconnaissance d'images, la constance des couleurs, le mouvement des capteurs (reconnaissance active), la coordination œil-main et le mouvement de la main, l'explication des activités du cerveau, le transfert de connaissances, la mémoire[8], l'attention sélective, la prédiction et l'exploration[7] - [9].
À partir d'environ 2012, la révolution dite de l'apprentissage en profondeur a suscité un intérêt accru pour l'utilisation des réseaux de neurones profonds comme approximateurs de fonctions dans une variété de domaines. Ce qui a conduit à un regain d'intérêt pour la recherche dans le domaine de l'utilisation des réseaux de neurones profonds pour apprendre la politique, la valeur et/ou les fonctions Q présentes dans les algorithmes d'apprentissage par renforcement existants.
À partir de 2013, DeepMind a montré des résultats d'apprentissage impressionnants en utilisant l'apprentissage par renforcement profond pour jouer aux jeux vidéo Atari[10] - [11]. L'ordinateur joueur un réseau de neurones formé à l'aide d'un algorithme d'apprentissage de renforcement en profondeur, une version profonde de Q-learning qu'ils ont appelée Deep Q-networks (DQN), avec le score du jeu comme récompense. Ils ont utilisé un réseau de neurones convolutifs profonds pour traiter 4 pixels RVB (84x84) en tant qu'entrées. Les 49 jeux ont été appris en utilisant la même architecture de réseau et avec des connaissances préalables minimales, surpassant les méthodes concurrentes sur presque tous les jeux et performant à un niveau comparable ou supérieur à celui d'un testeur de jeu humain professionnel[11].
L' apprentissage de renforcement en profondeur a franchi une autre étape en 2015 lorsque AlphaGo[12], un programme informatique entrainé avec l'apprentissage par renforcement profond pour jouer au jeu de Go, est devenu le premier programme informatique du jeu de Go d'ordinateur pour battre un joueur professionnel humain sans handicap sur un plateau de taille réél 19 × 19. Dans un projet ultérieur en 2017, AlphaZero a amélioré les performances sur le jeu de Go tout en démontrant qu'ils pouvaient utiliser le même algorithme pour apprendre à jouer aux échecs et au shogi à un niveau compétitif ou supérieur aux programmes informatiques existants pour ces jeux, et s'est encore amélioré en 2019 avec MuZero[13]. Séparément, une autre étape a été franchie par des chercheurs de l'Université Carnegie Mellon en 2019 en développant Pluribus, un programme informatique pour jouer au poker qui a été le premier à battre les professionnels lors de parties multijoueurs de Texas Hold'em sans limite. OpenAI Five, un programme permettant de jouer à cinq contre cinq au Dota 2 a battu les précédents champions du monde lors d'un match de démonstration en 2019.
L'apprentissage par renforcement profond a également été appliqué à de nombreux domaines autre que les jeux. En robotique, il a été utilisé pour permettre aux robots d'effectuer des tâches ménagères simples[14] et de résoudre un Rubik's cube avec une main robotisé[15] - [16]. L'apprentissage par renforcement profond a également trouvé des applications en matière de durabilité, utilisées pour la réduction de la consommation d'énergie dans les centres de données[17]. L'utilisation de l'apprentissage par renforcement profond pour la conduite autonome est un domaine de recherche actif dans les milieux universitaires et l'industriels[18]. Loon a exploré ll'apprentissage par renforcement profond pour naviguer pour la navigation autonome de ses ballons à haute altitude[19].
Algorithmes
Il existe différentes techniques existent pour entraîner des politiques afin de résoudre des tâches avec des algorithmes d'apprentissage par renforcement en profondeur, chacune ayant leurs propres avantages. Au niveau plus élevé, il existe une distinction entre l'apprentissage par renforcement basé sur un modèle et l'apprentissage par renforcement sans modèle, qui fait référence au fait que l'algorithme tente ou non d'apprendre un modèle prévisionnel de la dynamique de l'environnement.
Dans les modèles de base algorithmes d'apprentissage par renforcement profond, un modèle avancé de la dynamique de l'environnement est estimé, généralement par apprentissage supervisé à l'aide d'un réseau de neurones. Ensuite, les actions sont obtenues en utilisant le commande prédictive du modèle utilisant le modèle appris. Comme la dynamique réelle de l'environnement diverge généralement de la dynamique apprise, l'agent replanifie souvent lorsqu'il effectue des actions dans l'environnement. Les actions sélectionnées peuvent être optimisées à l'aide de méthodes de Monte Carlo telles que la méthode d'entropie croisée, ou une combinaison de l'apprentissage par modèle avec des méthodes sans modèle.
Dans les algorithmes d'apprentissage par renforcement profond sans modèle, une politique est apprise sans modéliser explicitement la dynamique avant. Une politique peut être optimisée pour maximiser les rendements en estimant directement le gradient de politique[20], mais elle souffre d'une variance élevée, ce qui la rend peu pratique pour une utilisation de l'approximation de fonction en Deep RL. Des algorithmes ultérieurs ont été développés pour un apprentissage plus stable et largement appliqués[21] - [22]. Une autre classe d'algorithmes d'apprentissage par renforcement profond sans modèle s'appuie sur la programmation dynamique, inspirée de l'apprentissage par différence temporelle et du Q-learning. Dans les espaces d'action discrets, ces algorithmes apprennent généralement une fonction Q de réseau de neurones qui estime les rentabilités futurs en prenant des actions de l'état [23]. Dans les espaces continus, ces algorithmes apprennent souvent à la fois une estimation de valeur et une politique[24] - [25] - [26].

Recherche
L'apprentissage par renforcement profond est un domaine de recherche actif, avec plusieurs axes d'investigation.
Exploration
Un agent RL doit équilibrer le compromis exploration/exploitation : le problème de décider s'il faut poursuivre des actions qui sont déjà connues pour rapporter des récompenses élevées ou explorer d'autres actions afin de découvrir des récompenses plus élevées. Les agents RL collectent généralement des données avec un certain type de politique stochastique, comme une distribution de Boltzmann dans des espaces d'action discrets ou une distribution gaussienne dans des espaces d'action continus, induisant un comportement d'exploration de base. L'idée derrière l'exploration basée sur la nouveauté ou axée sur la curiosité donne à l'agent une motivation pour explorer des résultats inconnus afin de trouver les meilleures solutions. Cela se fait en "modifiant la fonction de perte (ou même l'architecture du réseau) en ajoutant des termes pour inciter à l'exploration"[27]. Un agent peut également être aidé dans l'exploration en utilisant des démonstrations de trajectoires réussies, ou en façonnant des récompenses, en donnant à un agent des récompenses intermédiaires qui sont personnalisées pour s'adapter à la tâche qu'il tente d'accomplir.
Apprentissage par renforcement Off-policy
Une distinction importante dans RL est la différence entre les algorithmes sur stratégie qui nécessitent d'évaluer ou d'améliorer la stratégie qui collecte les données, et les algorithmes hors stratégie qui peuvent apprendre une stratégie à partir de données générées par une stratégie arbitraire. En règle générale, les méthodes basées sur des fonctions de valeur telles que Q-learning sont mieux adaptées à l'apprentissage hors politique et ont une meilleure efficacité d'échantillonnage - la quantité de données requise pour apprendre une tâche est réduite car les données sont réutilisées pour l'apprentissage. À l'extrême, l'apprentissage par renforcement hors ligne (ou "par lots") envisage d'apprendre une politique à partir d'un ensemble de données fixe sans interaction supplémentaire avec l'environnement.
Apprentissage par renforcement inverse
Le RL inverse fait référence à la déduction de la fonction de récompense d'un agent compte tenu du comportement de l'agent. L'apprentissage par renforcement inverse peut être utilisé pour apprendre à partir de démonstrations (ou apprentissage par apprentissage) en déduisant la récompense du démonstrateur, puis en optimisant une politique pour maximiser les retours avec l'apprentissage par renforcement. Des approches d'apprentissage en profondeur ont été utilisées pour diverses formes d'apprentissage par imitation et de l'apprentissage par renforcement inverse[28].
Apprentissage par renforcement conditionné par les objectifs
Un autre domaine de recherche actif est l'apprentissage des politiques conditionnées par des objectifs, également appelées politiques contextuelles ou universelles. qui prennent dans un objectif supplémentaire comme entrée pour communiquer un objectif souhaité à l'agent[29]. La relecture d'expérience rétrospective est une méthode d'apprentissage par renforcement conditionnée par un objectif qui implique le stockage et l'apprentissage des précédentes tentatives infructueuses d'accomplir une tâche[30]. Bien qu'une tentative infructueuse n'ait peut-être pas atteint l'objectif visé, elle peut servir de leçon sur la façon d'atteindre le résultat inattendu grâce à un réétiquetage rétrospectif.


Apprentissage par renforcement multi-agents
De nombreuses applications de l'apprentissage par renforcement n'impliquent pas un seul agent, mais plutôt un ensemble d'agents qui apprennent ensemble et s'adaptent ensemble. Ces agents peuvent être compétitifs, comme dans de nombreux jeux, ou coopératifs comme dans de nombreux systèmes multi-agents du monde réel. L'apprentissage multi-agent étudie les problèmes introduits dans ce cadre.
Généralisation
La promesse d'utiliser des outils d'apprentissage profond dans l'apprentissage par renforcement est la généralisation : la capacité d'opérer correctement sur des entrées inédites. Par exemple, les réseaux de neurones entraînés pour la reconnaissance d'images peuvent reconnaître qu'une image contient un oiseau même s'il n'a jamais vu cette image particulière ou même cet oiseau particulier. Étant donné que le l'apprentissage par renforcement profond autorise les données brutes (par exemple les pixels) en entrée, il est moins nécessaire de prédéfinir l'environnement, ce qui permet de généraliser le modèle à plusieurs applications. Avec cette couche d'abstraction, les algorithmes d'apprentissage par renforcement profond peuvent être conçus d'une manière qui leur permet d'être généraux et le même modèle peut être utilisé pour différentes tâches[31]. Une méthode pour augmenter la capacité des politiques formées avec des politiques RL profondes à généraliser est d'incorporer l' apprentissage de la représentation.
Articles connexes
Notes et références
- Francois-Lavet, Henderson, Islam et Bellemare, « An Introduction to Deep Reinforcement Learning », Foundations and Trends in Machine Learning, vol. 11, nos 3–4, , p. 219–354 (ISSN 1935-8237, DOI 10.1561/2200000071, Bibcode 2018arXiv181112560F, arXiv 1811.12560).
- Tesauro, « Temporal Difference Learning and TD-Gammon », Communications of the ACM, vol. 38, no 3, , p. 58–68 (DOI 10.1145/203330.203343, lire en ligne [archive du ], consulté le )
- Richard Sutton et Andrew Barto, Reinforcement Learning: An Introduction, Athena Scientific,
- John Bertsekas et Dimitri Tsitsiklis, Neuro-Dynamic Programming, Athena Scientific, (ISBN 1-886529-10-8, lire en ligne)
- W. Thomas Miller, Paul Werbos et Richard Sutton, Neural Networks for Control,
- Katsunari Shibata et Yoichi Okabe « Reinforcement Learning When Visual Sensory Signals are Directly Given as Inputs » () (lire en ligne)
—International Conference on Neural Networks (ICNN) 1997 - Katsunari Shibata et Masaru Iida « Acquisition of Box Pushing by Direct-Vision-Based Reinforcement Learning » () (lire en ligne)
—SICE Annual Conference 2003 - Hiroki Utsunomiya et Katsunari Shibata « Contextual Behavior and Internal Representations Acquired by Reinforcement Learning with a Recurrent Neural Network in a Continuous State and Action Space Task » () (lire en ligne)
—International Conference on Neural Information Processing (ICONIP) '08 - Katsunari Shibata et Tomohiko Kawano « Learning of Action Generation from Raw Camera Images in a Real-World-like Environment by Simple Coupling of Reinforcement Learning and a Neural Network » () (lire en ligne)
—International Conference on Neural Information Processing (ICONIP) '08 - Volodymyr Mnih « Playing Atari with Deep Reinforcement Learning » () (lire en ligne)
—NIPS Deep Learning Workshop 2013. - Mnih et al., « Human-level control through deep reinforcement learning », Nature, vol. 518, no 7540, , p. 529–533 (PMID 25719670, DOI 10.1038/nature14236, Bibcode 2015Natur.518..529M)
- Silver, Huang, Maddison et Guez, « Mastering the game of Go with deep neural networks and tree search », Nature, vol. 529, no 7587, , p. 484–489 (ISSN 0028-0836, PMID 26819042, DOI 10.1038/nature16961, Bibcode 2016Natur.529..484S)

- Schrittwieser, Antonoglou, Hubert et Simonyan, « Mastering Atari, Go, chess and shogi by planning with a learned model », Nature, vol. 588, no 7839, , p. 604–609 (PMID 33361790, DOI 10.1038/s41586-020-03051-4, Bibcode 2020Natur.588..604S, arXiv 1911.08265, lire en ligne)
- Levine, Finn, Darrell et Abbeel, « End-to-end training of deep visuomotor policies », JMLR, vol. 17, (arXiv 1504.00702, lire en ligne)
- « OpenAI - Solving Rubik's Cube With A Robot Hand », OpenAI
- OpenAI « Solving Rubik's Cube with a Robot Hand » () (arXiv 1910.07113, lire en ligne)
- « DeepMind AI Reduces Google Data Centre Cooling Bill by 40% », DeepMind
- George Hotz, interview par Lex Fridman, Winning - A Reinforcement Learning Approach,
- Bellemare, Candido, Castro et Gong, « Autonomous navigation of stratospheric balloons using reinforcement learning », Nature, vol. 588, no 7836, , p. 77–82 (PMID 33268863, DOI 10.1038/s41586-020-2939-8, Bibcode 2020Natur.588...77B, lire en ligne)
- Williams, « Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning », Machine Learning, vol. 8, nos 3–4, , p. 229–256 (DOI 10.1007/BF00992696)
- John Schulman, Sergey Levine, Philipp Moritz, Michael Jordan et Pieter Abbeel « Trust Region Policy Optimization » () (arXiv 1502.05477, lire en ligne)
—International Conference on Machine Learning (ICML) - John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford et Oleg Klimov « Proximal Policy Optimization Algorithms » () (arXiv 1707.06347, lire en ligne)
- Volodymyr Mnih « Playing Atari with Deep Reinforcement Learning » () (lire en ligne)
—NIPS Deep Learning Workshop 2013 - Timothy Lillicrap, Jonathan Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver et Daan Wierstra « Continuous control with deep reinforcement learning » () (arXiv 1509.02971, lire en ligne)
—International Conference on Learning Representations (ICLR) - Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirzi, Alex Graves, Tim Harley, Timothy Lillicrap, David Silver et Koray Kavukcuoglu « Asynchronous Methods for Deep Reinforcement Learning » () (arXiv 1602.01783, lire en ligne)
—International Conference on Machine Learning (ICML) - Tuomas Haarnoja, Aurick Zhou, Sergey Levine et Pieter Abbeel « Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor » () (arXiv 1801.01290, lire en ligne)
—International Conference on Machine Learning (ICML) - (en) Auteur inconnu, « Attention-based Curiosity-driven Exploration in Deep Reinforcement Learning », .
- (en) Auteur inconnu, « Maximum Entropy Deep Inverse Reinforcement Learning », .
- Tom Schaul, Daniel Horgan, Karol Gregor et David Silver « Universal Value Function Approximators » () (lire en ligne)
—International Conference on Machine Learning (ICML) - Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin et Pieter Abbeel « Hindsight Experience Replay » () (arXiv 1707.01495, lire en ligne)
—Advances in Neural Information Processing Systems (NeurIPS) - (en) Auteur inconnu, « Assessing Generalization in Deep Reinforcement Learning », .