Apprentissage fédéré
En intelligence artificielle et en apprentissage machine, l'apprentissage fédéré (en anglais : federated learning ou collaborative learning) est un paradigme d'apprentissage dans lequel plusieurs machines entrainent collaborativement un modèle d'intelligence artificielle tout en gardant leur données localement[1]. Ainsi, les machines impliquées dans l'apprentissage se contentent d'envoyer les modèles appris sur leurs données locales, et non les données elles-mêmes[2]. Ce paradigme s'oppose à l'apprentissage centralisé dans lequel toutes les données sont transmises à un serveur central chargé d'exécuter l'apprentissage du modèle.

| Type |
Intelligence artificielle, apprentissage automatique, système distribué (d) |
|---|
Un objectif majeur de l'apprentissage fédéré est d'offrir un meilleur respect de la vie privée des utilisateurs[3], même si l'efficacité des protections actuelles peut être remise en question[4].
Définition
En apprentissage automatique, on représente souvent les données d'apprentissage par une matrice. En apprentissage fédéré, chaque agent connait une partie de cette matrice. L'enjeu de l'apprentissage fédéré est d'entrainer un modèle d'apprentissage sans que les agents n'aient à transmettre leur part de la matrice. Beaucoup de modèles en apprentissage automatique sont obtenus en résolvant un problème d'optimisation. Les algorithmes d'apprentissage fédéré sont souvent une solution décentralisée à ces problèmes d'optimisation[5].
Un "modèle local" est un modèle d'apprentissage entrainé sur les données locales d'un agent. Le modèle global est le résultat de la combinaison de l'ensemble des modèles locaux[6]. Le déroulement standard d'un protocole d'apprentissage fédéré requiert l'échange de modèles locaux afin d'obtenir un modèle global satisfaisant le problème d'optimisation choisi.
Paradigmes d'apprentissage fédéré
Apprentissage inter-silo et apprentissage inter-appareil
L'apprentissage fédéré inter-silo (en anglais : cross-silo learning)[1] correspond à un apprentissage impliquant un nombre limité de serveurs puissants. Par exemple, la collaboration entre plusieurs hôpitaux proposée par Owkin[7] - [8] correspond à un apprentissage inter-silo. D'un autre côté, l'apprentissage inter-appareil (en anglais : cross-device learning)[1] implique un large nombre d'appareils peu puissants : par exemple, des millions de smartphones. L'utilisation d'apprentissage fédéré pour le Gboard par Google[9] - [10] correspond à un apprentissage inter-appareil.
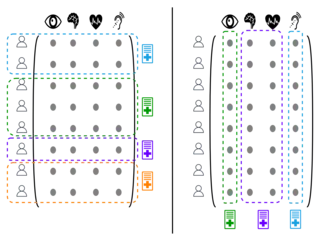
Apprentissage horizontal et apprentissage vertical
Cette dualité caractérise la connaissance qu'a chaque agent de la matrice contenant les données d'apprentissage.
En apprentissage fédéré horizontal[11], chaque agent connait une ou plusieurs lignes de la matrice de données d'apprentissage. En d'autres termes, chaque agent possède l'ensemble des données d'un ou plusieurs individus. Par exemple, l'apprentissage fédéré utilisé par le Gboard est horizontal car chaque smartphone connait l'ensemble des données de son utilisateur.
En apprentissage fédéré vertical[11], chaque agent connait une ou plusieurs colonnes complètes de la matrice de données d'apprentissage. En d'autres termes, chaque agent a des informations partielles sur l'ensemble des individus. Par exemple, différents hôpitaux peuvent avoir des données complémentaires sur le même ensemble de patients.
Apprentissage fédéré centralisé et apprentissage fédéré décentralisé
.png.webp)
L'apprentissage fédéré centralisé est le paradigme le plus étudié : les agents communiquent avec un serveur central unique qui orchestre l'apprentissage[1]. Dans les protocoles les plus simples, ce serveur est chargé d’agréger les modèles locaux et de diffuser le modèle global[5] - [12].
L'apprentissage fédéré (complètement) décentralisé (appelé fully decentralized federated learning ou gossip learning en anglais) correspond à un paradigme où il n'existe pas de serveur central : les agents communiquent directement les uns avec les autres et diffusent leurs modèles locaux en pair-à-pair[13] - [14].
Défis de l'apprentissage fédéré
Il y a 5 problèmes majeurs qui concentrent l'attention de la recherche en apprentissage fédéré[1]: la scalabilité des protocoles, la préservation de la vie privée, la résistance aux attaques, l'équité algorithmique (en) et l'apprentissage personnalisé.
Scalabilité des protocoles
L'apprentissage fédéré (particulièrement l'apprentissage inter-appareils) apporte de fortes contraintes liées à la mise à l'échelle. Premièrement, plusieurs techniques[6] - [15] visent à réduire le cout du protocole. Ces techniques permettent, par exemple, de rendre les couts abordables pour des appareils peu puissants tels que des smartphones.
Deuxièmement, la présence de milliers (voire millions) d'appareils introduit des problématiques liées à la distribution des données : il est fort probable que les données ne soient pas indépendantes et identiquement distribuées (i.i.d.). L'hypothèse i.i.d. est une hypothèse simplificatrice souvent utilisée pour obtenir des premiers résultats mais elle « n'est clairement presque jamais vérifiée en pratique »[1]. Ainsi, des chercheurs travaillent sur des algorithmes robustes à une distribution non i.i.d. des données[16] - [17].
Préservation de la vie privée
L'apprentissage fédéré est souvent promu comme une technologie améliorant la confidentialité grâce à sa non-publication des données d'apprentissage[18]. Cependant, cette non-publication des données locales n'est pas suffisante pour préserver la vie privée. En effet, le modèle appris localement peut contenir des informations personnelles.
Plusieurs attaques arrivent à extraire des informations sensibles à partir des modèles entrainés[19] et démontrent le risque lié au déploiement d'apprentissage fédéré sans méthode pour renforcer la confidentialité. On distingue deux types d'attaques : les attaques par inférence d'appartenance (en anglais : membership inference attacks)[19] visant à inférer si un individu est présent dans les données d'apprentissage et les attaques de reconstruction (en anglais : reconstruction attacks)[20] visant à reconstruire les données d'apprentissage à partir du modèle.
Ainsi, il est nécessaire d'utiliser des techniques cryptographiques (p. ex., du chiffrement homomorphe)[21] ou de la confidentialité différentielle[22] afin de compléter la préservation de la vie privée.
Résistance aux attaques
Dans un protocole impliquant de nombreux agents, il est fort probable que certains d'entre eux soient malveillants. Mis à part les attaques portant atteinte à la vie privée, certaines attaques peuvent menacer la réussite du protocole d'apprentissage. Par exemple, les attaques visant à "empoisonner" le modèle global (c'est-à-dire biaiser le modèle pour en réduire sa qualité) sont le sujet de nombreux articles[23]. Cependant, il existe d'autres attaques comme les free-rider attacks[24] dans lesquelles l'attaquant profite du résultat de l'apprentissage sans participer activement à l'apprentissage. Certaines contre-mesures émergent, notamment pour les attaques d'empoisonnement [25] - [26].
Équité algorithmique
L'équité algorithmique vise à corriger les biais des modèles d'apprentissage[27]. L'enjeu de ces recherches est d'éviter les discriminations dans les systèmes d'intelligence artificielle[28] - [29]. Bien que l'équité algorithmique concerne l'apprentissage automatique dans son ensemble, des techniques spécifiques à l'apprentissage fédéré[30] - [31] sont proposées afin de combiner algorithme décentralisé et équité algorithmique.
Apprentissage personnalisé
L'apprentissage personnalisé vise à entrainer des modèles spécifiques à chaque agent ou chaque groupe d'agent plutôt que d’entrainer un unique modèle global[1]. La personnalisation est surtout étudiée en apprentissage fédéré décentralisé[14] car ce paradigme empêche par construction la constitution d'un modèle global unique (à cause de l'absence d'agent centralisateur).
Applications
Bien que l'apprentissage fédéré ait bénéficié d'un intérêt récent lancé en 2016[5] - [32], plusieurs applications concrètes de l'apprentissage fédéré ont déjà été décrites voire déployées.
Clavier intelligent
La première application concrète promue fut celle des chercheurs de Google à l'origine d'un article fondateur de l'apprentissage fédéré[5]. Cette application propose d'utiliser l'apprentissage fédéré afin d’entrainer le modèle de recommandation du clavier intelligent pour smartphone: le Gboard[9] - [10]. Dans ce projet, les smartphones entrainent un modèle durant leur période de veille et les modèles locaux sont ensuite agrégés par un serveur central[9].
Médecine
L'apprentissage fédéré apporte des solutions aux problématiques de décentralisation et de confidentialité des données inhérentes à l'utilisation de données médicales[7] - [8] - [33] - [34]. Ainsi, ce paradigme permettrait aux hôpitaux et aux laboratoires médicaux d’entrainer de meilleurs modèles d'apprentissage tout en restant en conformité avec les contraintes fortes imposées par des législations telles que le RGPD sur l'utilisation des données médicales. Plusieurs applications médicales spécifiques ont déjà été présentées telles que la détection du cancer de la prostate[35] ou le traitement de patients atteints du COVID-19[36].
Recommandation d'articles d'information
Dans la foulée de Google, l'entreprise Brave Software (développant le navigateur Brave) a également utilisé l'apprentissage fédéré pour résoudre un problème de recommandation. Brave News (le système de flux d'actualité de Brave) [10] - [37] utilise l'apprentissage fédéré pour fournir des recommandations d'articles d'information respectueuses de la vie privée. Ce projet s'inscrit dans la politique globale de l'entreprise qui promeut des technologies Web plus respectueuse de la vie privée[38].
Marketing
Les données personnelles sont au centre du modèle économique du nombreuses entreprises technologiques[39]. L'apprentissage fédéré peut être vu comme une solution permettant de concilier ces intérêts économiques avec les contraintes légales telles que le RGPD. Par exemple, Google a propose le concept de Federated Learning of Cohorts afin de remplacer les cookies dans le système de publicité en ligne[40] et des chercheurs d'Orange ont utilisé l'apprentissage fédéré pour détecter préventivement les résiliations de contrat[41].
Ville intelligente
La ville intelligente peut également bénéficier d'apprentissage fédéré afin de traiter au mieux les données produites par les capteurs servant à optimiser les services des villes[42] - [43].
Voiture autonome
Les voitures autonomes sont des systèmes complexes remplis de capteurs et fonctionnant à l'aide de nombreux modèles d'intelligence artificielle. Étant donné la quantité colossale de données produite par une voiture autonome, l'apprentissage fédéré est vu comme un passage nécessaire pour permettre une amélioration continue des modèles d'apprentissage sans avoir à surcharger le réseau en transmettant de grandes quantités de données[44].
Notes et références
- (en) Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet et al., « Advances and Open Problems in Federated Learning », Foundations and Trends in Machine Learning, vol. 14, nos 1–2, , p. 1–210 (ISSN 1935-8237 et 1935-8245, DOI 10.1561/2200000083, lire en ligne, consulté le )
- Yann Bocchi, « Apprentissage fédéré : une nouvelle approche de l’apprentissage machine. », sur Carnet de route d’un monde connecté, (consulté le )
- (en) « Federated Learning, a step closer towards confidential AI / Hacker Noon », sur hackernoon.com (consulté le ).
- « Google a empoisonné la communauté scientifique, qui amplifie maintenant sa désinformation », Science4All (consulté le )
- Jakub Konečný, H. Brendan McMahan, Daniel Ramage et Peter Richtárik, « Federated Optimization: Distributed Machine Learning for On-Device Intelligence », arXiv:1610.02527 [cs], (lire en ligne, consulté le )
- Jakub Konečný, H. Brendan McMahan, Felix X. Yu et Peter Richtárik, « Federated Learning: Strategies for Improving Communication Efficiency », arXiv:1610.05492 [cs], (lire en ligne, consulté le )
- Ambassade de France aux Etats-Unis - Service pour la Science et la Technologie, « Le « federated learning », un paradigme d’apprentissage en plein essor aux Etats-Unis – France-Science » (consulté le )
- (en) Marion Oberhuber, « Federated learning in healthcare – the future of collaborative clinical and biomedical research », sur Owkin Blog, (consulté le )
- (en) « Federated Learning: Collaborative Machine Learning without Centralized Training Data », sur ai.googleblog.com (consulté le )
- Laboratoire d'Innovation Numérique de la CNIL, « Chacun chez soi et les données seront bien gardées : l’apprentissage fédéré », sur linc.cnil.fr, (consulté le )
- (en) Qiang Yang, Yang Liu, Tianjian Chen et Yongxin Tong, « Federated Machine Learning: Concept and Applications », ACM Transactions on Intelligent Systems and Technology, vol. 10, no 2, , p. 12:1–12:19 (ISSN 2157-6904, DOI 10.1145/3298981, lire en ligne, consulté le )
- (en) Kalista Bonawitz, Vladimir Ivanov, Ben Kreuter et Antonio Marcedone, « Practical Secure Aggregation for Privacy-Preserving Machine Learning », Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ACM, , p. 1175–1191 (ISBN 978-1-4503-4946-8, DOI 10.1145/3133956.3133982, lire en ligne, consulté le )
- (en) Aurélien Bellet, Rachid Guerraoui, Mahsa Taziki et Marc Tommasi, « Personalized and Private Peer-to-Peer Machine Learning », Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, PMLR, , p. 473–481 (lire en ligne, consulté le )
- (en) Yacine Belal, Aurélien Bellet, Sonia Ben Mokhtar et Vlad Nitu, « PEPPER: Empowering User-Centric Recommender Systems over Gossip Learning », Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 6, no 3, , p. 101:1–101:27 (DOI 10.1145/3550302, lire en ligne, consulté le )
- (en) Zachary Charles, Kallista Bonawitz, Stanislav Chiknavaryan et Brendan McMahan, « Federated Select: A Primitive for Communication- and Memory-Efficient Federated Learning », arXiv, (lire en ligne, consulté le )
- (en) Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri et Sashank Reddi, « SCAFFOLD: Stochastic Controlled Averaging for Federated Learning », Proceedings of the 37th International Conference on Machine Learning, PMLR, , p. 5132–5143 (lire en ligne, consulté le )
- (en) Maxence Noble, Aurélien Bellet et Aymeric Dieuleveut, « Differentially Private Federated Learning on Heterogeneous Data », arXiv, (lire en ligne, consulté le )
- -lapprentissage-federe/ « Quoi de neuf dans les TAC ? L’apprentissage fédéré - Hello Future Orange », sur Hello Future, (consulté le )
- (en) Hongsheng Hu, Zoran Salcic, Lichao Sun et Gillian Dobbie, « Membership Inference Attacks on Machine Learning: A Survey », ACM Computing Surveys, vol. 54, no 11s, , p. 235:1–235:37 (ISSN 0360-0300, DOI 10.1145/3523273, lire en ligne, consulté le )
- (en) Borja Balle, Giovanni Cherubin et Jamie Hayes, « Reconstructing Training Data with Informed Adversaries », 2022 IEEE Symposium on Security and Privacy (SP), , p. 1138–1156 (DOI 10.1109/SP46214.2022.9833677, lire en ligne, consulté le )
- (en) Mohamad Mansouri, Melek Önen, Wafa Ben Jaballah et Mauro Conti, « SoK: Secure Aggregation based on cryptographic schemes for Federated Learning », Proceedings on Privacy Enhancing Technologies, (lire en ligne [PDF])
- (en) Martin Abadi, Andy Chu, Ian Goodfellow et H. Brendan McMahan, « Deep Learning with Differential Privacy », Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ACM, , p. 308–318 (ISBN 978-1-4503-4139-4, DOI 10.1145/2976749.2978318, lire en ligne, consulté le )
- (en) Subhash Sagar, Chang-Sun Li, Seng W. Loke et Jinho Choi, « Poisoning Attacks and Defenses in Federated Learning: A Survey », arXiv, (lire en ligne, consulté le )
- (en) Yann Fraboni, Richard Vidal et Marco Lorenzi, « Free-rider Attacks on Model Aggregation in Federated Learning », Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, PMLR, , p. 1846–1854 (lire en ligne, consulté le )
- (en) Amrita Roy Chowdhury, Chuan Guo, Somesh Jha et Laurens van der Maaten, « EIFFeL: Ensuring Integrity for Federated Learning », arXiv, (lire en ligne, consulté le )
- (en) James Bell, Adrià Gascón, Tancrède Lepoint et Baiyu Li, « ACORN: Input Validation for Secure Aggregation », Cryptology ePrint Archive, (lire en ligne, consulté le )
- (en) Simon Caton et Christian Haas, « Fairness in Machine Learning: A Survey », arXiv:2010.04053 [cs, stat], (lire en ligne, consulté le )
- Déborah Loye, « La discrimination, côté obscur de l’intelligence artificielle », sur Les Echos Start, (consulté le )
- Rémy Demichelis, « IA : les biais, une arme de discrimination massive », sur Les Echos, (consulté le )
- (en) Han Yu, Zelei Liu, Yang Liu et Tianjian Chen, « A Fairness-aware Incentive Scheme for Federated Learning », Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Association for Computing Machinery, aIES '20, , p. 393–399 (ISBN 978-1-4503-7110-0, DOI 10.1145/3375627.3375840, lire en ligne, consulté le )
- (en) Yahya H. Ezzeldin, Shen Yan, Chaoyang He et Emilio Ferrara, « FairFed: Enabling Group Fairness in Federated Learning », arXiv, (lire en ligne, consulté le )
- (en) Reza Shokri et Vitaly Shmatikov, « Privacy-Preserving Deep Learning », Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, ACM, , p. 1310–1321 (ISBN 978-1-4503-3832-5, DOI 10.1145/2810103.2813687, lire en ligne, consulté le )
- « Protection des données : quatre questions à Julien Guérin, directeur des Data à l’Institut Curie | Institut Curie », sur curie.fr (consulté le )
- (en) Nicola Rieke, Jonny Hancox, Wenqi Li et Fausto Milletarì, « The future of digital health with federated learning », npj Digital Medicine, vol. 3, no 1, , p. 119 (ISSN 2398-6352, PMID 33015372, PMCID PMC7490367, DOI 10.1038/s41746-020-00323-1, lire en ligne, consulté le )
- Fei Kong, Jinxi Xiang, Xiyue Wang et Xinran Wang, « Federated contrastive learning models for prostate cancer diagnosis and Gleason grading », arXiv:2302.06089 [cs, q-bio], (lire en ligne, consulté le )
- (en) Ittai Dayan, Holger R. Roth, Aoxiao Zhong et Ahmed Harouni, « Federated learning for predicting clinical outcomes in patients with COVID-19 », Nature Medicine, vol. 27, no 10, , p. 1735–1743 (ISSN 1546-170X, DOI 10.1038/s41591-021-01506-3, lire en ligne, consulté le )
- (en) « Using Federated Learning to Improve Brave’s On-Device Recommendations While Protecting Your Privacy », sur Brave Browser, (consulté le )
- Vincent Hermann, « Brave : entre défense de la vie privée et philosophie publicitaire, un manque de finition », sur www.nextinpact.com, (consulté le )
- Shoshana Zuboff, The age of surveillance capitalism : the fight for a human future at the new frontier of power, (ISBN 978-1-61039-569-4, 1-61039-569-7 et 978-1-5417-5800-1, OCLC 1049577294, lire en ligne)
- Mathieu Chartier, « FLoC : comment la méthode de ciblage sans cookies de Google veut révolutionner la pub en ligne », sur www.lesnumeriques.com (consulté le )
- Sébastien Godard, Nicolas Voisine, Tanguy Urvoy et Vincent Lemaire, « Apprentissage fédératif pour la prédiction du churn : une évaluation », Revue des Nouvelles Technologies de l'Information « Extraction et Gestion des connaissances, RNTI-E-35 », , p. 141-152 (lire en ligne [PDF])
- (en) Karisma Trinanda Putra, Hsing-Chung Chen, Prayitno et Marek R. Ogiela, « Federated Compressed Learning Edge Computing Framework with Ensuring Data Privacy for PM2.5 Prediction in Smart City Sensing Applications », Sensors, vol. 21, no 13, , p. 4586 (ISSN 1424-8220, PMID 34283140, PMCID PMC8271576, DOI 10.3390/s21134586, lire en ligne, consulté le )
- (en) Ji Chu Jiang, Burak Kantarci, Sema Oktug et Tolga Soyata, « Federated Learning in Smart City Sensing: Challenges and Opportunities », Sensors, vol. 20, no 21, , p. 6230 (ISSN 1424-8220, PMID 33142863, PMCID PMC7662977, DOI 10.3390/s20216230, lire en ligne, consulté le )
- Tianyue Zheng, Ang Li, Zhe Chen et Hongbo Wang, « AutoFed: Heterogeneity-Aware Federated Multimodal Learning for Robust Autonomous Driving », arXiv:2302.08646 [cs], (lire en ligne, consulté le )