Algorithme de Hopcroft-Karp
En informatique, l'algorithme de Hopcroft-Karp est un algorithme qui prend en entrée un graphe biparti et qui produit en sortie un couplage de cardinalité maximum, c'est-à-dire un ensemble d'arêtes aussi grand que possible avec la propriété que deux arêtes ne partagent jamais une extrémité. L'algorithme a une complexité en temps en dans le pire des cas, où est l'ensemble des arêtes et est l'ensemble des sommets du graphe, et il est supposé que . Dans le cas de graphes denses, la borne devient , et pour des graphes aléatoires creux, le temps est pratiquement linéaire (en ).






| Découvreurs ou inventeurs |
John Hopcroft, Richard Karp, Alexander V. Karzanov (en) |
|---|---|
| Date de découverte | |
| Problèmes liés |
Algorithme, algorithme de la théorie des graphes (d) |
| Structure des données | |
| Basé sur |
| Pire cas |
|---|

| Pire cas |
|---|

L'algorithme a été décrit par John Hopcroft et Richard Karp en 1973[1]. De même nature que d'autres algorithmes antérieurs de calcul de couplages comme l'algorithme hongrois ou la méthode d'Edmonds[2], l'algorithme de Hopcroft-Karp incrémente itérativement la taille d'un couplage partiel par le calcul de chemins d'augmentation : ce sont des suites d'arêtes qui sont alternativement dans et en dehors du couplage, de sorte que le remplacement des arêtes dans le couplage par celles qui sont en dehors produit un couplage plus grand. Toutefois, au lieu de déterminer juste un seul chemin d'augmentation à chaque itération, l'algorithme calcule à chaque phase un ensemble maximal de chemins d'augmentation de longueur minimale. Il en résulte que itérations suffisent. Le même principe a aussi été employé pour développer des algorithmes plus compliqués de couplage dans des graphes non bipartis, avec la même complexité en temps que l’algorithme de Hopcroft-Karp.

Chemins d’augmentation
Un sommet qui n'est pas extrémité d'une arête d'un couplage partiel est appelé un sommet libre. La notion de base sur laquelle repose l’algorithme est celle de chemin d'augmentation ; c'est un chemin qui commence en un sommet libre, qui finit en un sommet libre, qui alterne des arêtes hors du couplage et dans le couplage, et qui passe au plus une fois par chaque sommet, c'est-à-dire un chemin qui commence et finit en des sommets libres distincts, qui alterne des arêtes hors du couplage et dans le couplage, et qui passe au plus une fois par chaque arête. Il résulte de cette définition que, à l'exception de ses extrémités, tous les sommets d'un chemin d'augmentation, s'il y en a, sont de sommets non libres. Un chemin d'augmentation peut consister en une seule arête qui est hors du couplage et dont les deux extrémités sont des sommets libres. Plus généralement, un chemin d'augmentation a une arête de plus hors du couplage que dans le couplage.

Si est un couplage et est un chemin d'augmentation relativement à , alors la différence symétrique des deux ensembles d'arêtes constitue un couplage de taille . Ainsi, en trouvant des chemins d'augmentation, on accroît par différence symétrique la taille d'un couplage.



Réciproquement, si un couplage n'est pas optimal, soit la différence symétrique où est un couplage maximal. Comme et sont tous deux des couplages, chaque sommet a degré au plus 2 dans ; l'ensemble est donc constitué d'un ensemble de cycles disjoints, d'un ensemble de chemins avec autant d'arêtes dans que en dehors de , de chemins d'augmentation pour , et de chemins d'augmentation pour ; mais ce dernier cas est exclu puisque est maximal. Les cycles et les chemins qui ont autant d'arêtes dans et en dehors du couplage ne contribuent pas à la différence de taille entre et , de sorte que cette différence est égale au nombre de chemins d'augmentation pour dans . Ainsi, chaque fois qu'il existe un couplage plus grand que le couplage courant , il doit aussi exister un chemin d'augmentation. Si un tel chemin d'augmentation ne peut être trouvé, l'algorithme par incrémentation termine puisque alors est optimal.


La notion de chemin d'augmentation dans un problème de couplage est étroitement liée à celle de chemin augmentant dans le problème de flot maximum ; ce sont des chemins où on peut augmenter la quantité de flot entre les extrémités. On peut transformer le problème du couplage biparti en une instance du problème du flot maximum, de sorte que les chemins alternants du problème de couplage deviennent des chemins augmentant dans le problème de flot[3]. En fait, une généralisation de la technique utilisée dans l'algorithme de Hopcroft-Karp à des réseaux de flots arbitraire est connue sous le nom d'algorithme de Dinic.
Algorithme
L'algorithme peut être décrit par le pseudo-code suivant :
- Entrée: un graphe biparti
- Sortie: un couplage
- répéter
- ensemble maximal de chemins d'augmentation sans sommets communs et de longueur minimale
- jusqu'à






Plus précisément, soient et les deux ensembles dans la bipartition des sommets de , et soit le couplage courant entre et . Une arête dans est dite couplée, les autres sont non couplées. L'algorithme opère par phases, et chaque phase consiste en les étapes suivantes :



- Un algorithme de parcours en largeur partitionne les sommets du graphe en couches. Les sommets libres de sont utilisés comme sommets de départ du parcours et forment la première couche de la partition. Au premier niveau du parcours il n'y a que des arêtes non couplées puisque par définition les sommets libres ne sont pas extrémités d'une arête couplée. Dans les étapes suivantes du parcours, le arêtes traversées doivent alternativement être couplées et non couplées. Plus précisément, lors de la recherche des successeurs d'un sommet de , seules des arêtes non couplées peuvent être parcourues, alors qu'à partir d'un sommet de , seules des arêtes couplées peuvent être parcourues. La recherche se termine à la première couche où un ou plusieurs sommets libres de sont atteints.

- Les sommets libres de de la couche sont réunis en un ensemble . Ainsi, un sommet est dans l'ensemble si et seulement s'il est l'extrémité d'un chemin d'augmentation de longueur minimale.


- L'algorithme détermine un ensemble maximal de chemins d'augmentation de longueur sans sommet commun[4]. L'ensemble de chemins disjoints est calculé par un algorithme de parcours en profondeur partant de l'ensemble vers les sommets libres dans , en utilisant les couches du parcours en largeur pour guider le parcours : le parcours en profondeur ne peut suivre que des arêtes vers des sommets pas encore utilisés de la couche suivante, et les chemins dans l'arbre du parcours en profondeur doivent suivre alternativement des arêtes couplées et non couplées. Lorsqu'un chemin d'augmentation pour un des sommets de est trouvé, la recherche en profondeur redémarre à partir du sommet de départ suivant dans . Tout sommet rencontré durant le parcours en profondeur est immédiatement marqué comme utilisé ; en effet, s'il n'y a pas de chemin de ce sommet vers à ce moment du parcours, alors le sommet ne pourra pas être utilisé non plus à un moment ultérieur du parcours. Ceci garanti que le temps du parcours en profondeur est en . On peut aussi opérer dans l'autre direction, des sommets libres de vers ceux de [5], qui est la variante utilisée dans le pseudo-code ci-dessous.
- Tous les chemins ainsi trouvés sont utilisés pour agrandir .

L'algorithme se termine quand on ne trouve plus de chemin d'augmentation dans le parcours en largeur utilisée dans la première partie d'une phase.
Exemple
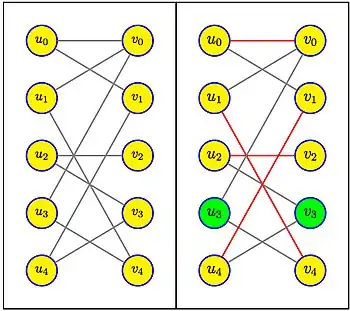
Le graphe biparti de l'exemple ci-contre a 5 sommets et 10 arêtes. Dans la partie gauche, avant la première phase, tous les sommets sont libres, le couplage est vide. Tous les chemins d'augmentation sont réduits à une seule arête entre un sommet de et un sommet de . Un parcours en largeur sélectionne par exemple les arêtes , , et (en choisissant, pour chaque sommet de U éligible, le sommet de V de plus petit indice). Cet ensemble de chemins est bien maximal, tous ont même longueur 1, le couplage obtenu est de taille 4, et il reste deux sommets libres, et .







Dans la deuxième phase, il s'agit de trouver les chemins d'augmentation de longueur minimale, à partir du seul sommet libre de U (ou à partir du seul sommet libre de V). Le chemin indiqué en gras alterne des arêtes noires, hors couplage, et des arêtes rouges, dans le couplage. Il est de longueur 5. On voit bien qu'il n'existe pas de chemin de longueur 3 (les chemins sont toujours de longueur impaire), mais il y a un chemin de longueur 7, à savoir . Le couplage résultant de la différence symétrique du couplage précédent avec le chemin de longueur 5 donne le couplage de taille 5 de l'exemple. Il est maximal parce qu'il n'y a plus aucun sommet libre.


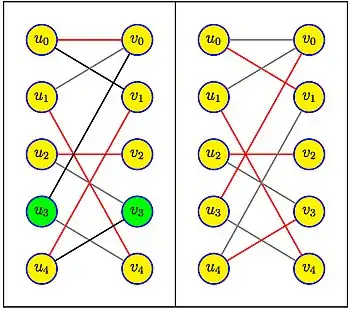
Analyse
Chaque phase consiste en un parcours en largeur suivi d'un parcours en profondeur. Chaque phase peut donc être réalisée en temps . Par conséquent, les premières phases, pour un graphe à sommets et arêtes, prennent un temps .


On peut montrer[5] que chaque phase augmente d'au moins 1 la longueur du plus court chemin d'augmentation : dans une phase, on détermine un ensemble maximal de chemins d'augmentation d'une certaine longueur, donc tout autre chemin d'augmentation doit être plus long. Par conséquent, une fois les phases initiales de l'algorithme exécutées, le plus court chemin d'augmentation restant contient au moins arêtes. Or, la différence symétrique entre un couplage éventuellement optimal et le couplage partiel obtenu après les phases initiales de l’algorithme est une collection de chemins d'augmentation sans sommets communs, et de cycles alternants. Si chaque chemin dans cette collection a longueur au moins , il y a au plus chemins dans cette collection, et la taille d'un couplage optimal diffère de la taille de par au plus arêtes. Comme chaque phase de l’algorithme augmente la taille du couplage d'au moins une unité, il y a au plus phases supplémentaires avant que l'algorithme termine .
Comme l'algorithme exécute au total au plus phases, il prend un temps en dans le pire des cas.

Dans de nombreux cas, le temps d'exécution peut être plus court que ce qu'indique cette analyse dans le pire des cas. Par exemple, l'analyse de la complexité en moyenne pour des graphes creux biparti aléatoires menée par Bast et al. 2006, améliorant des résultats antérieurs de Motwani 1994, montre qu'avec une grande probabilité, tous les couplages non optimaux ont des chemins d'augmentation de longueur logarithmique. Il en résulte que, pour ces graphes, l'algorithme de Hopcroft-Karp requiert phases et un temps total en .


Comparaison avec d'autres algorithmes de couplage
Pour des graphes creux, l'algorithme de Hopcroft-Karp continue d'être l'algorithme le plus rapide connu dans le pire des cas, mais pour des graphes denses (pour lesquels ) un algorithme ultérieur de Alt et al. 1991 donne une borne légèrement meilleure, à savoir . Leur algorithme commence par l'emploi de l'algorithme de poussage/réétiquetage et quand le couplage obtenu par cette méthode est près de l'optimum, bascule sur la méthode de Hopcroft-Karp.


Divers auteurs ont réalisé des comparaisons expérimentales de d’algorithmes de couplage de graphes bipartis. Leurs résultats, tels que résumés dans un rapport technique de Setubal 1996, tendent à montrer que la méthode de Hopcroft-Karp n'est pas aussi bonne en pratique qu'en théorie : d'autres méthodes sont plus rapides, en utilisant des parcours en largeur ou en profondeur plus simples pour la détermination des chemins d'augmentation, ou des techniques de poussage/réétiquetage.
Graphes non biparti
La même façon de déterminer un ensemble maximal de chemins d'augmentation de longueur minimale pour trouver un couplage de taille maximale s'applique aussi dans des graphes non biparti, et pour la même raison les algorithmes basés sur cette idée demandent au plus phases. Toutefois, pour les graphes non biparti, trouver les chemins d'augmentation pour chacune des phases est plus difficile. En s'appuyant sur divers travaux antérieurs Micali et Vazirani 1980 ont montré comment implémenter chaque phase de l'algorithme en temps linéaire, ce qui finalement donne un algorithme pour le couplage dans les graphes non bipartis qui a la même borne de complexité que l'algorithme de Hopcroft-Karp pour les graphes bipartis. La technique de Micali-Vazirani est complexe, et leur article ne contient pas tout le détail des preuves ; une version qui se veut plus claire a été publiée ensuite par Peterson et Loui 1988, et d'autres méthodes ont été proposées par d'autres auteurs[6]. En 2012, Vazirani a fourni une démonstration simplifiée de l'algorithme de Micali-Vazirani algorithm[7].
Pseudo-code
Dans les pseudo-code ci-dessous, et forment la partition des sommets du graphe, et NIL est un somme spécial. Pour un sommet u de U, Pair_U[u] est NIL si u est libre, et sinon est égal à l'autre extrémité de l'arête à laquelle il est couplé. De même pour Pair_V[v].
Algorithme
function Hopcroft-Karp
for each u in U
Pair_U[u] = NIL
for each v in V
Pair_V[v] = NIL
matching = 0
while BFS()
for each u in U
if Pair_U[u] == NIL
if DFS(u)
matching = matching + 1
return matching
Au départ, tous les sommets de U et V sont libres. Chaque phase commence par un parcours en largeur, suivi d'un parcours en profondeur à partir des sommets libres de U. Chaque parcours en profondeur réussi fournit un chemin d'augmentation.
Parcours en largeur
function BFS ()
for each u in U
if Pair_U[u] == NIL
Dist[u] = 0
Enqueue(Q,u)
else
Dist[u] = ∞
Dist[NIL] = ∞
while not Empty(Q)
u = Dequeue(Q)
if Dist[u] < Dist[NIL]
for each v in Adj[u]
if Dist[ Pair_V[v] ] == ∞
Dist[ Pair_V[v] ] = Dist[u] + 1
Enqueue(Q,Pair_V[v])
return Dist[NIL] != ∞
Parcours en profondeur
function DFS (u)
if u != NIL
for each v in Adj[u]
if Dist[ Pair_V[v] ] == Dist[u] + 1
if DFS(Pair_V[v])
Pair_V[v] = u
Pair_U[u] = v
return true
Dist[u] = ∞
return false
return true
Explication
Soit U, V la partition des sommets. L'idée est d'ajouter deux sommets fictifs, un de chaque côté du graphe: uDummy est relié à tous les sommets libres de U et vDummy est relié à tous les sommets libres de V. Ainsi, en exécutant un parcours en largeur BFS depuis uDummy vers vDummy, on obtient un chemin le plus court entre un sommet libre de U et un sommet libre de V. Comme le graphe est biparti, ce chemin zigzague entre U et V. Cependant, il faut vérifier que l'on sélectionne toujours une arête couplée pour aller de V à U. Si une telle arête n'existe pas, on termine au sommet vDummy. Si ce critère est observé au cours de BFS, alors le chemin généré répond aux critères pour être un chemin d'augmentation de longueur minimale. Les sommets uDummy et vDummy qui servent à cette explication ne figurent pas explicitement dans le pseudo-code.
Une fois un chemin d'augmentation de longueur minimale trouvé, il faut s'assurer d'ignorer les autres chemins, plus longs. Pour cela, l'algorithme BFS décore les nœuds dans le chemin avec leur distance avec la source. Ainsi, après le parcours BFS, on commence par chaque sommet libre dans U, et on suit le chemin en suivant des nœuds dont la distance augmente de 1. Quand on arrive finalement au sommet destination vDummy, si sa distance est 1 de plus que le dernier nœud dans V alors on sait que le chemin suivi est l'un des chemins les plus courts possibles. Dans ce cas, on peut procéder à la mise à jour du couplage sur le chemin de U à V. Chaque sommet dans V sur ce chemin, sauf le dernier, est un sommet non libre. Ainsi, la mise à jour du couplage pour ces sommets dans V aux sommets correspondants dans U équivaut à supprimer l'arête précédemment couplée et d'ajouter une nouvelle arête libre au couplage. Cela revient à faire la différence symétrique (c'est-à-dire supprimer les arêtes communes au couplage précédent et ajouter des arêtes non communes du chemin d'augmentation au nouveau couplage).
On n'a pas à vérifier explicitement que les chemins d'augmentation sont disjoints : après avoir fait la différence symétrique pour un chemin, aucun de ses sommets ne peut être considéré à nouveau justement parce que Dist[Pair_V[v]] est différent de Dist[u]+1 (puis qu'il est égal à Dist[u]).
Les deux lignes du pseudo-code :
Dist[u] = ∞ return false
servent dans le cas où il n'y a pas de chemin d'augmentation de longueur minimale à partir d'un sommet donné ; dans ce cas, DFS retourne la valeur false. Pour marquer qu'il est inutile de visiter ces sommets à nouveau, on pose Dist[u]= ∞.
Enfin, comme déjà annoncé, on n'a pas explicitement besoin de uDummy ; il sert seulement à mettre les sommets libres de U dans la file au démarrage de BFS ce que l’on peut aussi bien faire à l'initialisation. Le sommet vDummy peut être ajouté à V par commodité (et s'y trouve dans de nombreuses implémentations) ; il sert à coupler les sommets de V vers vDummy. De cette façon, si le sommet final dans V n'est pas couplé à un sommet dans U alors on termine le chemin d'augmentation en vDummy. Dans le pseudo-code ci-dessus, vDummy est noté NIL.
Notes
- Hopcroft et Karp 1973.
- Edmonds 1965
- Voir par exemple Ahuja, Magnanti et Orlin 1993, Section 12.3 : bipartite cardinality matching problem, p. 469–470.
- Maximal signifie qu'aucun chemin ne peut être ajouté. Cela ne veut pas dire que c'est le nombre maximum de tels chemins, problème qui serait autrement difficile à résoudre. Heureusement, l'algorithme se contente d'un ensemble maximal.
- Mahajan 2010
- Gabow et Tarjan 1991 et Blum 2001.
- Vazirani 2012.
Bibliographie
- [1993] Ravindra K. Ahuja, Thomas L. Magnanti et James B. Orlin, Network Flows: Theory, Algorithms and Applications, Prentice-Hall, .
- [1991] Helmut Alt, Norbert Blum, Kurt Mehlhorn et Manfred Paul, « Computing a maximum cardinality matching in a bipartite graph in time », Information Processing Letters, vol. 37, no 4, , p. 237–240 (DOI 10.1016/0020-0190(91)90195-N).
- [2006] Holger Bast, Kurt Mehlhorn, Guido Schafer et Hisao Tamaki, « Matching algorithms are fast in sparse random graphs », Theory of Computing Systems, vol. 39, no 1, , p. 3–14 (DOI 10.1007/s00224-005-1254-y).
- Norbert Blum, « A Simplified Realization of the Hopcroft-Karp Approach to Maximum Matching in General Graphs », Tech. Rep. 85232-CS, Computer Science Department, Univ. of Bonn, (lire en ligne).

- Jack Edmonds, « Paths, Trees and Flowers », Canadian J. Math, vol. 17, , p. 449–467 (DOI 10.4153/CJM-1965-045-4, MR 0177907).
- Harold N. Gabow et Robert E. Tarjan, « Faster scaling algorithms for general graph matching problems », Journal of the ACM, vol. 38, no 4, , p. 815–853 (DOI 10.1145/115234.115366).
- John E. Hopcroft et Richard M. Karp, « An n5/2 algorithm for maximum matchings in bipartite graphs », SIAM Journal on Computing, vol. 2, no 4, , p. 225–231 (DOI 10.1137/0202019).
- Meena Mahajan, « Matchings in Graphs », The Institute of Mathematical Sciences, (consulté le ).
- Silvio Micali et Vijay Vazirani, « An algorithm for finding maximum matching in general graphs », Symposium on Foundations of Computer Science-Proc. 21st IEEE Symp. Foundations of Computer Science, , p. 17–27 (DOI 10.1109/SFCS.1980.12).
- Paul A. Peterson et Michael C. Loui, « The general maximum matching algorithm of Micali and Vazirani », Algorithmica, vol. 3, nos 1-4, , p. 511–533 (DOI 10.1007/BF01762129).
- Rajeev Motwani, « Average-case analysis of algorithms for matchings and related problems », Journal of the ACM, vol. 41, no 6, , p. 1329-1356 (DOI 10.1145/195613.195663).

- João C. Setubal, « Sequential and parallel experimental results with bipartite matching algorithms », Tech. Rep. IC-96-09, Inst. of Computing, Univ. of Campinas, (lire en ligne).
- Vijay Vazirani, « An Improved Definition of Blossoms and a Simpler Proof of the MV Matching Algorithm », CoRR abs/1210.4594, (arXiv 1210.4594).
Articles connexes
- Couplage biparti
- Algorithme hongrois
- Problème d'affectation
- Algorithme d'Edmonds-Karp de calcul de flot maximum
Liens externes
- Algorithme de Hopcroft-Karp sur Brilliant
- Algorithme de Hopcroft-Karp sur TUM