Algorithme de parcours en largeur
L'algorithme de parcours en largeur (ou BFS, pour Breadth-First Search en anglais) permet le parcours d'un graphe ou d'un arbre de la manière suivante : on commence par explorer un nœud source, puis ses successeurs, puis les successeurs non explorés des successeurs, etc. L'algorithme de parcours en largeur permet de calculer les distances de tous les nœuds depuis un nœud source dans un graphe non pondéré (orienté ou non orienté). Il peut aussi servir à déterminer si un graphe non orienté est connexe.

| Découvreur ou inventeur | |
|---|---|
| Date de découverte | |
| Problèmes liés |
Uninformed search algorithm (d), parcours de graphe |
| Structure des données |
| Pire cas |
|---|

| Pire cas |
|---|

Principe
Un parcours en largeur débute à partir d'un nœud source. Puis il liste tous les voisins de la source, pour ensuite les explorer un par un. Ce mode de fonctionnement utilise donc une file dans laquelle il prend le premier sommet et place en dernier ses voisins non encore explorés. Les nœuds déjà visités sont marqués afin d'éviter qu'un même nœud soit exploré plusieurs fois. Dans le cas particulier d'un arbre, le marquage n'est pas nécessaire. Voici les étapes de l'algorithme :
- mettre le nœud source dans la file ;
- retirer le nœud du début de la file pour le traiter ;
- mettre tous ses voisins non explorés dans la file (à la fin) ;
- si la file n'est pas vide reprendre à l'étape 2.
L'algorithme de parcours en profondeur diffère du parcours en largeur car il continue l'exploration jusqu'à arriver dans un cul-de-sac. C'est seulement à ce moment-là qu'il revient en arrière pour explorer depuis un autre nœud voisin. L'utilisation d'une pile au lieu d'une file transforme l'algorithme du parcours en largeur en l'algorithme de parcours en profondeur.
Exemple
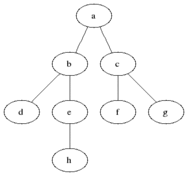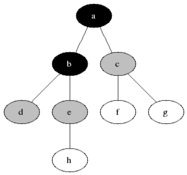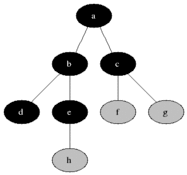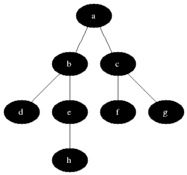
Sur le graphe suivant, cet algorithme va alors fonctionner ainsi :
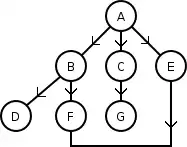
Il explore dans l'ordre les sommets A, B, C, E, D, F, G, contrairement à l'algorithme de parcours en profondeur qui cherche dans cet ordre : A, B, D, F, C, G, E.
Pseudo code
L'algorithme s'implémente à l'aide d'une file.
ParcoursLargeur(Graphe G, Sommet s):
f = CreerFile();
f.enfiler(s);
marquer(s);
tant que la file est non vide
s = f.defiler();
afficher(s);
pour tout voisin t de s dans G
si t non marqué
f.enfiler(t);
marquer(t);
Complexité
La complexité en temps dans le pire cas est en où est le nombre de sommets et est le nombre d'arcs. En effet, chaque arc et chaque sommet est visité au plus une seule fois. Montrons le. Soit un graphe G=(S, A), dont aucun sommet n'est marqué à l'appel de l'algorithme. Tous les sommets insérés dans la file sont marqués et l'instruction conditionnelle assure donc que les sommets seront insérés au plus une fois, comme l'insertion dans la file se fait en Θ(1), la complexité est en Θ(S). La boucle sur les voisins t d'un sommet s consiste à lister les voisins a une complexité en temps de l'ordre de grandeur du nombre de voisins de s (on parcourt la liste d'adjacence du sommet s). Comme la somme des longueurs des listes d'adjacence est |A| (le nombre d'arêtes), la complexité totale passée dans cette boucle pour tout s est Θ(A). Cormen et al. (voir p. 552 [1]) appelle une telle analyse une analyse par agrégat. La complexité totale est donc Θ(|S|+|A|)[1].



Applications
Le parcours en largeur explore tous les sommets accessibles depuis le sommet source. On peut utiliser cet algorithme pour calculer les composantes connexes d'un graphe non orienté avec une complexité linéaire en la taille du graphe.
De plus, lors de ce parcours, les sommets sont explorés par distance croissante au sommet source. Grâce à cette propriété, on peut utiliser l'algorithme pour résoudre le problème de cheminement suivant : calculer des plus courts chemins entre le sommet source et tous les sommets du graphe. L'algorithme de Dijkstra peut être vu comme une généralisation du parcours en largeur avec des arcs pondérés positivement.
Un raffinement appelé LexBFS permet de reconnaître rapidement certaines classes de graphes.
Évocation dans la littérature
- Dans son roman Le Nom de la rose, Umberto Eco fait expliquer par Guillaume de Baskerville un algorithme de parcours en largeur pour explorer méthodiquement un labyrinthe[2]:
« Pour trouver la sortie d'un labyrinthe, récita en effet Guillaume, il n'y a qu'un moyen. À chaque nœud nouveau, autrement dit jamais visité avant, le parcours d'arrivée sera marqué de trois signes. Si, à cause de signes précédents sur l'un des chemins du nœud, on voit que ce nœud a déjà été visité, on placera un seul signe sur le parcours d'arrivée. Si tous les passages ont été déjà marqués, alors il faudra reprendre la même voie, en revenant en arrière. Mais si un ou deux passages du nœud sont encore sans signes, on en choisira un quelconque, pour y apposer deux signes. Quand on en apposera deux autres, de façon que ce passage en porte trois dorénavant. Toutes les parties du labyrinthe devraient avoir été parcourues si, en arrivant à un nœud, on ne prend jamais le passage avec trois signes, sauf si d'autres passages sont encore sans signes. »
Notes et références
- Thomas Cormen, Charles Leiserson, Ronald Rivest, Clifford Stein, "Introduction à l'algorithmique", DUNOD, 2001, 3e éd. (1re éd. 1990), 1176 p. (ISBN 2-10-003922-9)
- Umberto Eco (trad. de l'italien par Jean-Noël Schifano), Le Nom de la rose, , Deuxième jour, « Nuit ».