R-arbre
Les R-arbres sont des structures de données sous forme d'arbre utilisées comme méthodes d'exploration spatiale. Elles servent à indexer des informations multidimensionnelles (coordonnées géographiques, rectangles ou polygones). Inventés par Antonin Guttman[1] en 1984, les R-arbres sont utilisés aussi bien dans des contextes théoriques qu'appliqués[2]. Un cas d'utilisation typique des R-arbres est le stockage d'informations géographiques : par exemple l'emplacement des restaurants dans une ville, ou les polygones constitutifs des dessins d'une carte (routes, bâtiments, côtes, etc.), et de pouvoir par la suite répondre à des requêtes du type de "trouver tous les musées dans un rayon de 2 kilomètres", "afficher toutes les routes situées à moins de 5 kilomètres" ou "trouver la station-service la plus proche de ma position", par exemple dans une application de navigation.
Les R-arbres peuvent également êtres utilisés pour accélérer la recherche des K plus proches voisins[3], en particulier pour certaines métriques comme la distance du grand cercle[4].
Fonctionnement
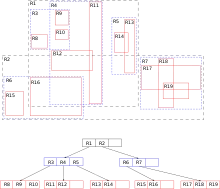
L'idée principale derrière la structure de donnée est de représenter les objets proches par leur rectangle englobant au niveau immédiatement supérieur de l'arbre (le "R" de R-arbre est l'initiale de "rectangle"). En d'autres termes, dans un nœud donné de l'arbre sont stockés les rectangles englobants de chaque sous-arbre dont il est le parent. Ainsi, lorsqu'on recherche une information spatiale, il suffit de vérifier pour chaque branche si la position recherchée intersecte le rectangle correspondant, et d'ignorer les branches associées à un rectangle pour lequel il n'y a pas d'intersection. Chaque feuille de l'arbre décrit un seul objet, et chaque niveau supérieur décrit un rassemblement d'un nombre toujours plus important d'objets.
À l'instar d'un arbre B, les R-arbres sont des arbres de recherches équilibrés (toutes les feuilles sont à la même distance de la racine) dont les données sont organisées en pages, et sont spécialement indiqués pour le stockage sur disque, par exemple dans le cas d'une base de données. Chaque page a une capacité maximale, notée M (une page a au plus M entrées), et l'arbre garantit un taux de remplissage minimal de chaque page (à l'exception de la racine). Cette organisation en pages est adaptée à un grand volume de données : chaque page peut être chargée en mémoire lorsqu'on en a besoin, même si l'arbre entier était trop gros pour être stocké en mémoire.
La plupart des opérations de recherche spatiale (intersection, inclusion, recherche des plus proches voisins) sont simplifiées par la structure du R-arbre : on utilise le rectangle englobant d'une branche pour déterminer si on y poursuit l'exploration, ce qui permet d'éliminer la plupart des nœuds non pertinents.
La difficulté de mise en œuvre des R-arbres provient de la nécessité de garder l'arbre équilibré tout en évitant que les rectangles englobants ne couvrent trop d'espace vide ou que plusieurs rectangles ne recouvrent la même zone. Sans cela, les opérations de recherche spatiales risqueraient d'explorer trop de nœuds inutilement, ce qui aurait un effet sur les performances. Initialement, l'insertion des éléments se faisait en plaçant l'élément dans le sous-arbre dont la boite englobante grandirait le moins en y ajoutant le nouvel élément. Si une page est pleine, on divise ses éléments en cherchant à minimiser l'aire des rectangles correspondants aux deux sous-ensembles. La plupart des recherches concernant les R-arbres cherchent à optimiser les performances d'un arbre construit à partir d'une seule source de données (bulk loading) ou au contraire d'optimiser l'arbre dans le cas où les données sont ajoutées de manière incrémentale.
Bien que les R-arbres n'offrent pas de bonnes performances théoriques dans le pire des cas, ils sont très efficaces en pratique[5]. Il existe des variantes offrant des garanties d'optimalité même dans le pire cas pour le bulk-loading[6], mais la complexité de leur mise en œuvre limite leur usage dans les applications pratiques.
La possibilité de retrouver rapidement les objets situés à une distance r d'un point donné ou ses k plus proches voisins (au sens de n'importe quelle norme-p) à l'aide d'une opération de jointure spatiale[7] sert de base à de nombreux algorithmes qui reposent sur une implémentation efficace de ces opérations, par exemple pour le clustering ou la détection d'anomalies.
Notes et références
- A. Guttman, Proceedings of the 1984 ACM SIGMOD international conference on Management of data – SIGMOD '84, , 47 p. (ISBN 0-89791-128-8, DOI 10.1145/602259.602266, lire en ligne), « R-Trees: A Dynamic Index Structure for Spatial Searching »
- Y. Manolopoulos, A. Nanopoulos et Y. Theodoridis, R-Trees : Theory and Applications, Springer, , 194 p. (ISBN 978-1-85233-977-7, lire en ligne)
- (en) Nick Roussopoulos, Stephen Kelley et Frédéric Vincent, « Nearest neighbor queries », Proceedings of the 1995 ACM SIGMOD international conference on Management of data - SIGMOD '95, ACM Press, , p. 71–79 (ISBN 9780897917315, DOI 10.1145/223784.223794, lire en ligne, consulté le )
- Erich Schubert, Arthur Zimek et Hans-Peter Kriegel, « Geodetic Distance Queries on R-Trees for Indexing Geographic Data », dans Advances in Spatial and Temporal Databases, vol. 8098, Springer Berlin Heidelberg, (ISBN 9783642402340, DOI 10.1007/978-3-642-40235-7_9, lire en ligne), p. 146–164
- Sangyong Hwang, Keunjoo Kwon, Sang K. Cha et Byung S. Lee, « Performance Evaluation of Main-Memory R-tree Variants », dans Advances in Spatial and Temporal Databases, vol. 2750, Springer Berlin Heidelberg, (ISBN 9783540405351, DOI 10.1007/978-3-540-45072-6_2., lire en ligne), p. 10–27
- (en) Lars Arge, Mark de Berg, Herman J. Haverkort et Ke Yi, « The Priority R-tree: a practically efficient and worst-case optimal R-tree », Proceedings of the 2004 ACM SIGMOD international conference on Management of data - SIGMOD '04, ACM Press, , p. 347 (ISBN 9781581138597, DOI 10.1145/1007568.1007608, lire en ligne, consulté le )
- (en) Thomas Brinkhoff, Hans-Peter Kriegel et Bernhard Seeger, « Efficient processing of spatial joins using R-trees », ACM SIGMOD Record, vol. 22, no 2, , p. 237–246 (DOI 10.1145/170036.170075, lire en ligne, consulté le )