Passage à l'échelle d'une application web
Le passage à l'échelle[1], anglicisme pour le redimensionnement et la mise à l'échelle, est la faculté qu’a un système à pouvoir changer de taille ou de volume selon les besoins des utilisateurs.
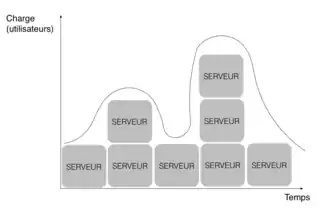
La disponibilité et la latence (temps de réponse) font partie des critères de qualité d'un site web. Le nombre d’utilisateurs d’un site variant de jour en jour, il s’avère difficile et coûteux de prévoir les ressources nécessaires au bon fonctionnement du site. Ainsi, posséder la faculté d'être capable de passer facilement l’application à l’échelle s'avère donc un atout majeur pour un site.
Le cloud computing répond à ce besoin. Il permet d’ajuster les ressources matérielles de manière dynamique et transparente en fonction de la charge utilisateurs pour assurer une disponibilité continue du site et un délai de réponse correct.
Avantages du cloud
Le cloud computing répond aux besoins suivants :
- Élasticité des ressources[2] : le système est capable d'ajuster les ressources matérielles (stockage, réseaux, serveurs) automatiquement en fonction des demandes.
- Pay-per-use[2] : les ressources sont facturées sur l’intervalle de temps durant lequel elles sont utilisées.
- Haute disponibilité[3] : le système doit toujours répondre aux demandes même en cas de panne d'une ressource.
- Tolérance aux pannes[3] : même en cas de panne d'une ressource, le système reste cohérent et ne perd aucune donnée.
Introduction au passage à l'échelle
Lorsque les capacités d'une machine qui héberge une application web, appelée serveur, sont trop limitées pour supporter le nombre de requêtes utilisateurs, plusieurs solutions sont envisageables :
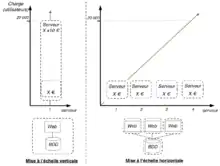
- La première solution consiste à augmenter les capacités matérielles de la machine. Cette méthode est connue sous le nom de "mise à l'échelle verticale" (scale up/scale vertically). Cette solution présente plusieurs inconvénients :
- L'ajout de ressources supplémentaires entraîne une indisponibilité de l'application sur un temps donné.
- Cette solution est onéreuse.
- Si le serveur tombe en panne, l'application est indisponible.
- La seconde solution consiste à lancer l'application sur plusieurs serveurs distincts possédant éventuellement les mêmes capacités matérielles de façon à répartir la charge de travail entre ces serveurs. Cette méthode est alors appelée "mise à l'échelle horizontale" (scale out/scale horizontally). Cette solution résout les inconvénients de la "mise à l'échelle verticale".
Pour une mise à l'échelle optimale, une application basée sur le cloud doit être distribuée. Une architecture distribuée est une architecture qui divise une application en plusieurs éléments (appelés couches) logiques indépendants. L'architecture n-tier est un exemple d'architecture logicielle distribuée. Les architectures distribuées permettent de déployer chaque couche du logiciel sur un ensemble de machines différentes (appelé cluster) diminuant ainsi la charge de chaque machine. On pourra donc appliquer la scalabilité horizontale sur chacune de ces couches[4].
Répartition de la charge
Dans le cas du cloud, la mise à l'échelle horizontale est privilégiée. Ainsi, plusieurs serveur web sont capables de répondre à la demande de l'utilisateur. Afin de répartir la charge équitablement entre plusieurs serveurs, un composant appelé Load balancer sert d'interface entre l'utilisateur et les serveurs web. Ce composant a la responsabilité d'orienter une requête utilisateur vers l'un des serveurs web.
Infrastructure élastique (auto-scaling)
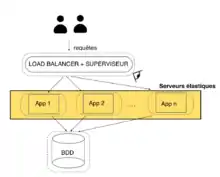
L'auto-scaling consiste à optimiser le coût de l'hébergement de l'application tout en maximisant sa disponibilité et en conservant un délai de réponse qui satisfait l'utilisateur. Pour cela, les hébergeurs adaptent dynamiquement et sans intervention humaine le nombre de serveurs selon la charge de l'application à un moment donné[5]. Une application élastique a la capacité :
- de passer à l'échelle horizontalement ou verticalement dynamiquement sans intervention humaine en cas de sous-approvisionnement ou sur-approvisionnement ;
- d'analyser la charge de chaque serveur afin de prendre une décision de passage à l'échelle.
Le processus d'auto-scaling, appelé MAPE loop du système, se déroule en quatre étapes :
- la surveillance (monitor) : un système de contrôle collecte des informations sur le système et l'état de l'application.
- l'analyse (analyze) : analyse des informations collectées.
- la planification (plan) : il utilise les informations récupérées afin de faire des estimations, pour connaître quelles seront les ressources à utiliser. Il prévoit ensuite une modification des ressources qui ont été identifiées (par exemple, la suppression d'une machine virtuelle ou l'ajout de mémoire).
- l'exécution (execute) : modification des ressources.
Monitor
Un système d'auto-scaling a besoin d'un système de monitoring fournissant des informations sur la demande utilisateurs et l'état/statut de l'application.
- Les infrastructures du cloud fournissent via une API, l'accès à des informations au fournisseur (par exemple, vérifier le bon fonctionnement de l'infrastructure).
- Un système d'auto-scaling s'appuie sur la mise à jour des indicateurs de performance. En effet, la performance de l'auto-scaler dépendra de la qualités des mesures/informations disponibles et des coûts de l'obtention de ces mesures.
Pour analyser l'état du système, le moniteur observe au niveau :
- de l'équilibreur de charge (répartiteur) le nombre, de sessions utilisateurs actuelles, de demandes refusées, d'erreurs ;
- des serveurs web, l'utilisation du processeur par machine virtuelle, le nombre de threads totaux, de threads actifs, de sessions, la mémoire utilisée, les demandes traitées, en attente, abandonnées, le temps de réponse ;
- des serveurs de bases de données, le nombre de threads actifs, de transactions dans un état particulier (écrire, rollback) ;
- de la communication (file d'attente), le nombre moyen de demandes dans la file d'attente, le temps d'attente.
Analyze
La phase d'analyse consiste à traiter les données rassemblées lors de l'étape de Monitoring. Il existe deux types d'auto-scaler :
- réactif : ce système renvoie juste l'état du système à un instant donné. Il réagit aux variations de la charge de travail seulement lorsque ces changements ont été détectés, en utilisant les dernières valeurs obtenues à partir de l'ensemble des informations récoltées lors de l'étape de "Monitor".
- proactif : ce système effectue de la prédiction sur de futures demandes afin d'organiser suffisamment tôt les ressources. L'anticipation est très importante car il y a toujours un délai entre le moment où le système décide de se mettre à l'échelle et celui où celle-ci prendra effet.
Plan
Une fois l'état de l'application connu, l'auto-scaler est chargé de planifier la mise à l'échelle des ressources.
Execute
Cette étape passe en exécution le passage à l'échelle des ressources trouvées dans l'étape précédente. L'exécution du passage à l'échelle des serveurs peut prendre un certain temps non négligeable (démarrage des serveurs, installations des logiciels, modifications réseaux).
Ainsi, les auto-scaler proactifs ont pour objectif d'anticiper ce temps de mise en place pour répondre au mieux à la demande. Cette étape est réalisée par une API du fournisseur du cloud.
Le stockage
Les demandes des utilisateurs sont maintenant réparties entre plusieurs serveurs Web utilisant un mécanisme de répartition de charge. Les serveurs web font ensuite appel à la base de données pour obtenir les informations persistantes. Par conséquent, la base de données doit aussi être étudiée pour pouvoir traiter les demandes entrantes avec une latence acceptable.
Fichiers statiques
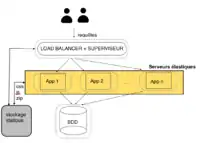
Les applications web contiennent souvent du contenu statique, par exemple des images, des vidéos, des fichiers javascript, des documents pdf. Pour pouvoir réduire au maximum la charge des serveurs d'application exécutant du code dynamique, les applications de cloud utilisent un serveur dédié à stocker des fichiers statiques volumineux. Sur ce serveur, les données sont organisées dans une hiérarchie de dossiers similaires à un système de fichiers ordinaire. Chaque fichier statique reçoit un identificateur unique composé de son emplacement dans la hiérarchie du dossier et le nom du fichier[6].
Base de données
La mise à l'échelle d'une base de données est caractérisée par la scalabilité en écriture, en lecture et en stockage données. Plusieurs techniques permettent de mettre à l'échelle les différents types de base de données :
- la réplication
- la duplication
Réplication
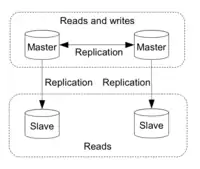
La réplication est une technique permettant de dupliquer une instance de base de données en plusieurs instances identiques (possédant les mêmes données). Elle est utilisée pour la mise à l'échelle en lecture des données. Cette technique améliore la disponibilité d'une application. En effet, si l'une des répliques est indisponible, il est toujours possible pour les autres instances de répondre à une demande de lecture. Toutes les répliques étant capable de répondre, les requêtes de lecture peuvent être distribuées entre chacune d'elles. Ainsi la charge de travail de chaque serveur et par conséquent la latence d'une réponse diminue[7].
Cette solution possède plusieurs inconvénients :
- Chaque instance de la base de données contient les mêmes valeurs. Ainsi, si la base de données est très volumineuse, tous les serveurs de base de données devront posséder une capacité de stockage suffisante.
- Lorsqu'une écriture a lieu sur une instance, elle doit être répliquée sur chaque instance pour que chaque serveur possède les mêmes données à tout moment.
- Les réplications de la base de données permettent de mettre à l'échelle la capacité de lecture des données car chaque réplication peut répondre à une demande de lecture, mais ne permettent pas de mettre à l'échelle la capacité en écriture des données.
Il existe deux types principaux de réplication[8] :
- la réplication maître-esclave : Un nœud est désigné comme "maître". Les autres sont appelés "esclave". Seul le nœud maître peut traiter et diriger des requêtes d'écriture. Les changements de données se propagent du nœud maître aux esclaves. On utilise cette réplication lorsque l'on souhaite faire de la scalabilité en lecture car cela permet aux nœuds esclaves d'accepter les requêtes en lecture. Par contre il est impossible de réaliser de la scalabilité en écriture car seul le nœud maître s'occupe des requêtes en écriture.
- la réplication multi-maître : Plusieurs nœuds peuvent traiter et diriger des requêtes d'écriture. La propagation des données peut se faire dans plusieurs directions. On peut se servir de cette réplication pour la scalabilité en lecture et écriture puisque chaque nœud est capable de gérer les deux types de requêtes en lecture et en écriture.
Partition
Le partitionnement permet de mettre à l'échelle la capacité en écriture d'une base de données en séparant les données en partitions (ou shards). Le partitionnement permet de séparer les données dans différents serveurs indépendants[9]. Il existe deux types de partitionnement :
- Le partitionnement vertical dont les données sont partagées en ensembles de colonnes.
- Le partitionnement horizontal (appelé Database Sharding), qui est le partitionnement le mieux adapté pour distribuer les bases de données. Les données sont divisées en ensembles de lignes.
Cette méthode permet d’améliorer les performances des bases de données et de simplifier la gestion de bases de données de très grande ampleur. Le partitionnement augmente les performances des requêtes puisque les ensembles de données sont plus petits comparés à une table unique de grande taille (scalabilité en lecture, écriture et stockage)[10].
Bases de données relationnelles
Les bases de données relationnelles respectent plusieurs caractéristiques principales regroupées sous l'acronyme ACID. Les bases de données relationnelles sont facilement réplicables. Cependant, partitionner ce type de base de données s'avère complexe. De plus, garantir la consistance des données est souvent incompatible avec les performances. Ainsi, le passage à l'échelle horizontal est délicat pour ce type de base de données. Comme le modèle relationnel ne semble pas adapté aux environnements nécessitants de grosses architectures distribuées et que les propriétés ACID des bases de données ne permettent généralement pas de passer à l'échelle de manière horizontale et optimale[11], les concepteurs du cloud computing et de grands sites communautaires ont proposé un nouveau modèle de base de données : NoSQL[12].
Bases de données NoSQL
Les bases de données NoSQL se basent sur le théorème CAP, mieux adapté aux données massivement partagées, qui déclare qu'il est impossible sur un système informatique de calcul distribué de garantir en même temps les trois contraintes suivantes[13] :
- la cohérence (Consistency) : Tous les serveurs de base de données du système possèdent exactement les mêmes données au même moment.
- la disponibilité (Availability) : Une réponse sera forcément renvoyée pour chaque requête reçue, même s'il y a une défaillance d'un serveur.
- la tolérance au partitionnement (Partition Tolerence) : Même si le système fait face à une défaillance d'un composant, il doit être capable de répondre correctement à toutes les requêtes qu'il aura reçues.
La première propriété (la cohérence) du théorème CAP est parfois intéressante à supprimer car elle permet d'augmenter les performances de manière non négligeable[11]. Ainsi, certains sites préfèrent optimiser la disponibilité et la latence de l'application au détriment de ne pas fournir une réponse identique pour une même requête. Le fait d'accepter des données inconsistantes est connu sous le nom de BASE (Basically Available, Soft-state, Eventually consistent) en opposition aux propriétés ACID. Si la cohérence est importante pour certaines données du système, il est d'usage d'isoler ces données dans des bases relationnelles et de placer les autres données dans des bases NoSQL.
Les bases de données NoSQL facilitent le passage à l'échelle en utilisant plusieurs systèmes qui mettent en œuvre les propriétés citées par le théorème CAP. Les voici :
- Le passage à l'échelle horizontal avec ce type de base de données est très simple à réaliser. Ainsi, elles permettent de répartir la charge de travail et par conséquent d'assurer une grande disponibilité.
- Elles possèdent en général un système de réplication et de partitionnement qui assurent la disponibilité et la tolérance au partitionnement.
- Elles utilisent en général, simultanément l'indexation et la RAM afin de trouver les données recherchées. Grâce à l'indexation, on connaît rapidement le serveur sur lequel est présent la RAM qui stocke les données que l'on souhaite quérir. De plus, les données sont conservées en RAM, permettant ainsi de les récupérer très rapidement puisque le temps d'accès à la RAM est très performant. Ainsi on peut dire que la disponibilité et la tolérance au partitionnement sont garanties par ces deux points.
Base de données clé-valeur (Key-value store)
Ce type de base de données est considérée comme la plus élémentaire et la plus simple à utiliser. On y trouve un ensemble de couples clé-valeur représentant chacun une donnée. Chacune des valeurs stockées dans la base de données peut avoir un type différent. Mais ce type est opaque, sa nature est donc masquée. Il est alors impossible de connaître et de modifier le contenu de la valeur. On peut simplement la stocker et la transmettre dans une base de données. Afin d'identifier chaque valeur sans ambiguïté, celle-ci est alors associée à une clé unique. C'est grâce à cette clé que l'on pourra connaître et modifier le contenu de la valeur. Les clés et les valeurs ne sont pas obligatoirement du même type.
Ces bases de données sont très efficaces dans le stockage de données distribuées. Elles sont ainsi performantes pour :
- synchroniser les données sur chacune des bases de données à un moment donné;
- répliquer les données mises à jour, modifiées, supprimées dans une base de données sur les autres bases de données lorsque plusieurs utilisateurs souhaitent accéder à la même donnée.
Par contre, le type opaque des valeurs empêche de manier les requêtes au niveau données et de faciliter l'accès aux données à l'aide de l'indexation sur les données puisqu'il est impossible de récupérer ou de changer le contenu d'une valeur. Ces bases de données sont seulement capables de lancer des requêtes sur les clés. De plus elles sont dans l'obligation d'utiliser des applications clientes car elles n'ont pas la possibilité de gérer les relations entre les différentes données[14].
Base de données orientée document
Tout comme les bases de données clé-valeur, le système de stockage d'une base de données orientée document se fait toujours sous forme d'un couple clé-valeur. Par contre, la valeur est représentée à l'aide d'un document dont le format n'est pas imposé. Le plus souvent, ils seront de type JSON. Il n'est pas obligatoire que tous les documents d'une base de données orientée document possèdent la même structure.
Les bases de données orientées document peuvent grâce à la clé primaire, générer des requêtes et indexer les documents. Elles peuvent également le faire à l'aide de la valeur puisque son type est connu, il n'est pas opaque.
Mais elles n'ont pas la capacité à sauvegarder des relations entre les données, les obligeant ainsi à faire appel à des applications clientes[15].
Base de données orientée colonne
Contrairement aux bases de données relationnelles qui stockent les données par ligne, celles-ci le font par colonne. L'ensemble des données est enregistré dans un ensemble de lignes. Chacune d'entre elles corresponde à une clé primaire. Les bases de données orientées colonne sont constituées d'un ensemble de famille de colonnes qui contiennent toutes les valeurs.
Grâce aux ensembles de famille de colonnes, ce type de base de données offre de puissantes capacités de génération de requêtes et d'indexation des données. Mais elles ne possèdent pas l'aptitude à stocker les différentes relations entre les données[15].
Base de données orientée graphe
Une base de données orientée graphe s'appuie sur la théorie des graphes. Les données sont décrites par des nœuds. Quant aux relations entre les différentes données, celles-ci sont symbolisées via les arcs du graphe.
Contrairement aux autres bases de données, elles peuvent stocker efficacement les relations entre les différentes données. Elles sont également spécialisées dans le traitement des données interconnectées[16].
Communication : messages asynchrones (files)
Les composants d'une application distribuée sont hébergés sur plusieurs ressources du cloud et doivent échanger des informations entre eux. Le mode de communication privilégié est la file de message car elle permet l'échange de messages asynchrones.
L'utilisation des files de messages (structure FIFO) permet de mettre en attente les messages envoyés lorsque le receveur n'est plus capable de traiter les messages reçus, facilitant ainsi la flexibilité de traitement du receveur[17]. Ce système de communication permet de se prémunir contre la surcharge du serveur destinataire. De plus, l'observation de l'état de la file de messages permet d'obtenir des informations sur l'état du serveur.
Il existe plusieurs variantes de file de messages dont la file de messages avec messages prioritaires. Ce type de communication est souvent utilisé dans le cloud entre les serveurs logiques et les serveurs de base de données.
Traitement : map reduce
Maintenant que les données sont distribuées à l'aide des mécanismes de réplication et de partition sur plusieurs instances de bases de données, il est nécessaire de traiter les données de façon distribuée. Il faut donc synchroniser les données entre les différents serveurs de bases de données tout en diminuant leur charge de travail. Cela implique de répartir d'une certaine manière, le travail entre les différents serveurs.
Afin de gérer et traiter un grand volume de données, un framework nommé MapReduce a été mis en œuvre. Il permet de simplifier le traitement parallèle des données grâce à deux interfaces: map et reduce[18]. L'interface map partage le travail alors que l'interface reduce synchronise les données entre les différents nœuds du cluster[19].
Le framework MapReduce possède ainsi des propriétés importantes dans le passage à l'échelle[20] :
- la gestion des grands volumes de données : il le réalise en simplifiant le traitement parallèle des données.
- la flexibilité : les interfaces map et reduce sont implémentées par le fournisseur du cloud. Le comportement de traitement des données peut donc différer en fonction de l'utilisateur contrairement à la pratique SQL.
- l'efficacité : il n'a pas besoin de charger les données en base de données. Il est donc très performant pour des applications qui ont besoin de manipuler qu'une ou quelques fois des données.
- la tolérance aux pannes : l'interface map partage chaque tâche en plusieurs petites qui sont affectées aux différents nœuds du cluster. Même si l'une des tâches échoue car un nœud est tombé, elle peut être transférée à un autre nœud puisque chaque tâche est répliquée et conservée dans un système de fichier distribué. On retrouve le même dispositif pour l'interface reduce.
Notes et références
- Nagendra 2014, p. 85.
- Fehling, Leymann, Retter et Schumm 2011, p. 1.
- Grolinger et al. 2013, p. 2.
- Vaquero, Rodero-Merino et Buyya 2011, p. 45.
- Lorido-Botran, Miguel-Alonso et Lozano 2014, p. 2.
- Fehling, Leymann, Mietzer et Schupeck 2011, p. 30.
- Thandar Thant et Naing 2013, p. 4-5.
- Grolinger et al. 2013, p. 13-14.
- Grolinger et al. 2013, p. 10.
- Grolinger et al. 2013, p. 8.
- Cattell 2010, p. 12-13.
- Pokorny 2011, p. 279.
- Thandar Thant et Naing 2013, p. 2.
- Grolinger et al. 2013, p. 5.
- Grolinger et al. 2013, p. 6.
- Grolinger et al. 2013, p. 6-7.
- Maheshwari, Tang et Liang 2004, p. 525.
- Li et al. 2014, p. 1.
- Li et al. 2014, p. 3-4.
- Li et al. 2014, p. 2.
Annexes
Bibliographie
- [Burtica et al. 2012] (en) Ruxandra Burtica, Eleonora Maria Mocanu, Mugurel Ionuţ Andreica et Nicolae Ţăpuş, « Practical application and evaluation of no-SQL databases in Cloud Computing », dans IEEE International'12 on Systems Conference (SysCon), Vancouver, BC, IEEE Computer Society Washington, DC, USA, (ISBN 978-1-4673-0748-2, DOI 10.1109/SysCon.2012.6189510).
- [Cattell 2010] (en) Rick Cattell, « Scalable SQL and NoSQL Data Stores », ACM SIGMOD Record, vol. 39, no 4, (DOI 10.1145/1978915.1978919, lire en ligne [PDF]).
- [Fehling, Leymann, Mietzner et Schupeck 2011] (en) Christoph Fehling, Frank Leymann, Ralph Mietzner et Walter Schupeck, « A Collection of Patterns for Cloud Types, Cloud Service Models, and Cloud-based Application Architectures », iaas, (lire en ligne).
- [Fehling, Leymann, Retter et Schumm 2011] (en) Christoph Fehling, Frank Leymann, Ralph Retter, David Schumm et Walter Schupeck, « An Architectural Pattern Language of Cloud-based Applications », dans PLoP '11 Proceedings of the 18th Conference on Pattern Languages of Programs Article No. 2, ACM New York, NY, USA, (ISBN 978-1-4503-1283-7, DOI 10.1145/2578903.2579140).
- [Grolinger et al. 2013] (en) Katarina Grolinger, Wilson A. Higashino, Abhinav Tiwari et AM Miriam Capretz, « Data management in cloud environments: NoSQL and NewSQL data stores », Journal of Cloud Computing: Advances, Systems and Applications 2013, 2:22, , p. 1-24 (lire en ligne).
- [Homer et al. 2014] (en) Alex Homer, John Sharp, Larry Brader, Masashi Narumoto et Trent Swanson, « Cloud Design Patterns », msdn.microsoft.com, (lire en ligne).
- [Li et al. 2014] (en) Feng Li, Beng Chin ooi, M. Tamer Özsu et Sai Wu, « Distributed data management using MapReduce », ACM Computing Surveys (CSUR), ACM New York, NY, USA, vol. 46, no 31, , p. 1-41 (DOI 10.1145/2503009).
- [Lorido-Botran, Miguel-Alonso et Lozano 2014] (en) Tania Lorido-Botran, Jose Miguel-Alonso et Jose A. Lozano, « A Review of Auto-scaling Techniques for Elastic Applications in Cloud Environments », Journal of Grid Computing, vol. 12, , p. 559-592 (DOI 10.1007/s10723-014-9314-7, lire en ligne [PDF]).
- [Maheshwari, Tang et Liang 2004] (en) Piyush Maheshwari, Hua Tang et Roger Liang, « Enhancing Web Services with Message-Oriented Middleware », dans IEEE International Conference on Web Services., IEEE, (ISBN 0-7695-2167-3, DOI 10.1109/ICWS.2004.1314778, lire en ligne), p. 524-531.
- [Nagendra 2014] (en) Rupesh Nagendra, « Performance Evaluation in Web Architectures », Oriental Journal of Computer Science & Technology, Oriental Scientific Publishing Co., India, vol. 7, no 1, , p. 83-90 (ISSN 0974-6471, lire en ligne).
- [Pokorny 2011] (en) Jaroslav Pokorny, « NoSQL Databases: a step to database scalability in Web environment », dans iiWAS '11 Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services, ACM New York, NY, USA, , 278-283 p. (ISBN 978-1-4503-0784-0, DOI 10.1145/2095536.2095583).
- [Thandar Thant et Naing 2013] (en) Phyo Thandar Thant et Thinn Thu Naing, « Improving the Availability of NoSQL Databases for Cloud Storage », academia, (lire en ligne).
- [Vaquero, Rodero-Merino et Buyya 2011] (en) Luis Miguel Vaquero, Luis Rodero-Merino et Rajkumar Buyya, « Dynamically Scaling Applications in the Cloud », Newsletter ACM SIGCOMM Computer Communication Review, ACM New York, NY, USA, vol. 41, no 1, , p. 45-52 (DOI 10.1145/1925861.1925869).