Méthode FORM-SORM
La méthode FORM-SORM est une méthode utilisée en fiabilité pour déterminer la probabilité de défaillance d'un composant.
- FORM est l'acronyme de First Order Reliability Method, méthode de fiabilité du premier ordre ;
- SORM est l'acronyme de Second Order Reliability Method, méthode de fiabilité du second ordre.
Il s'agit de trouver le point de conception, c'est-à-dire le cas de défaillance du maximum de vraisemblance. La solution est obtenue par une procédure d'optimisation.
Présentation du problème
Une conception « au plus juste » — compromis entre le coût de fabrication, le coût de service (maintenance, garantie) et la satisfaction de l'utilisateur (sécurité, disponibilité du système) — nécessite d'avoir recours aux statistiques ; c'est le domaine de la fiabilité. On veut connaître la probabilité que la durée de vie T d'un système soit supérieure à une valeur t, R(t) = P(T ≥ t), ce qui revient à connaître la probabilité de défaillance avant t,
- F(t) = P(T ≤ t) ; F = 1 - R.
En particulier, on veut garantir que cette probabilité de défaillance est inférieure à une limite α, choisie en fonction des incertitudes et des conséquences d'une situation de défaillance :
- F(t) ≤ α, c'est-à-dire R(t) ≥ 1 - α.
On se place en général à la limite
- F(t) = α.
Cette durée de vie dépend de plusieurs facteurs : La notion de durée de vie implique celle de processus, c'est-à-dire de variable aléatoire indexée sur le temps, ce que la méthode FORM présentée ne prend pas en compte.
- des facteurs de charge, ou contraintes S (stress) : c'est ce que subit la machine, sollicitations mécaniques, humidité, température, intensité du courant électrique…
- des facteurs de fabrication, ou résistance R : dimensions des composants, propriétés de la matière, …
Tous ces facteurs, contraintes ou résistances, peuvent s'exprimer par des grandeurs chiffrées xi. Ces valeurs sont des réalisations de variables aléatoires Xi : tous les systèmes, même produits à la chaîne, sont différents les uns des autres, et ils ne subissent pas non plus les mêmes sollicitations.
Dans un certain nombre de cas, on peut définir une fonction de défaillance g(x1, x2, …, xn) pour exprimer la condition sur la durée de vie :
- F(t) ≤ α ⇔ g(x1, x2, …, xn) ≥ 0.
L'espace à n dimensions (x1, x2, …, xn) est donc coupé en deux demi-espaces :
- le domaine de défaillance F (failure), vérifiant l'équation g(x1, x2, …, xn) < 0 ;
- le domaine de bon fonctionnement, vérifiant l'équation g(x1, x2, …, xn) > 0 ;
la frontière entre les deux est une hypersurface d'équation g(x1, x2, …, xn) = 0 qui définit l'état limite.
Chaque variable aléatoire Xi suit une loi de probabilité dont la fonction de densité de probabilité est notée ƒi. La densité de probabilité d'avoir un n-uplet donné (x1, x2, …, xn) vaut donc
- y = ƒ1(x1)׃2(x2)ׅ׃n(xn)
La fonction y(x1, x2, …, xn) forme une hypersurface de l'espace (x1, …, xn, ƒ). Le maximum de y, le « sommet » de l'hypersurface, est le point le plus probable.
Pour déterminer la probabilité de défaillance Pf du système, il faut intégrer y sur la zone de défaillance F

La valeur de Pf est le « volume » — l'hypervolume — délimité par les hypersurfaces y et g = 0.
La solution analytique de cette intégrale est en général complexe, voire impossible. Une manière d'estimer Pf consiste à utiliser une méthode de Monte-Carlo : on génère un grand nombre de valeurs aléatoires (x1, x2, …, xn) suivant les lois statistiques connues, et l'on compte le nombre de cas pour lesquels g est négatif.
Toutefois, la majeure partie de l'information est contenue dans une petite zone de l'espace, dite « zone critique », qui est l'ensemble des n-uplet (x1, x2, …, xn) pour lesquels la densité de probabilité de défaillance est importante ; le point où la densité de probabilité de défaillance est maximale est appelée « point de conception » et noté x* (c'est un n-uplet). Or, si la conception est robuste, cette zone critique est loin du sommet de l'hypersurface y, puisque l'on veut que la plupart des situations soient des situations de bon fonctionnement. Donc, la méthode de Monte-Carlo génère beaucoup de n-uplet proche du maximum de y, c'est-à-dire loin de la zone d'intérêt.
Il faut donc un nombre considérable de simulations pour avoir une bonne estimation de Pf.
La méthode FORM-SORM est une méthode d'approximation consistant à trouver le point de conception, et de s'en servir pour déterminer la probabilité de défaillance Pf.
Méthode générale
La méthode FORM-SORM consiste à :
- Remplacer les variables aléatoires par des lois normales centrées réduites.
- Trouver le n-uplet (x1, x2, …, xn) de l'hypersurface d'état limite le plus proche de l'origine ; c'est alors le point de conception x*, le n-uplet de la zone de défaillance ayant la densité de probabilité maximale.
- Faire une approximation linéaire (FORM) ou quadratique (SORM) de g pour déterminer la probabilité de défaillance Pf.
Hypothèses
On suppose que les variables aléatoires ont une distribution normale.
Si les variables sont normales d'espérance μi et d'écart type σi, on les transforme également en variables de loi centrées réduites
- Ui = (Xi - μi)/σi
- Xi = σiUi + μi
Si les variables aléatoires Xi ne sont pas normales, on les transforme pour avoir des variables Ui suivant lois normales centrées réduites ; cette opération est la « transformation de Nataf et Rosenblatt » :
- Ui = Φ-1(Fi(Xi))
et réciproquement
- Xi = F-1(Φi(Ui))
où Φ (lettre grecque Phi) est la fonction de répartition de la loi normale centrée réduite, et Fi la fonction de répartition de Xi.
Méthode générale
Plus on est proche du sommet de l'hypersurface y, plus la densité de probabilité est élevée. Les fonctions de densité ƒi étant des courbes en cloche symétriques, y forme une « colline » : plus on s'éloigne du sommet, plus la densité de probabilité y diminue. Donc, le point le plus critique, le point de conception x*, est le point de la zone de défaillance F le plus proche du sommet.
La méthode FORM-SORM consiste à trouver le point de la zone frontière g(x1, …, xn) = 0 le plus proche du sommet. Dans l'espace centré réduit, le sommet de y se trouve à l'origine, le point de coordonnées (0, 0, …, 0). La fonction de défaillance devient alors g* :
- F(t) = α ⇔ g*(u1, …, un) ≥ 0.
La distance à l'origine est donc

et ainsi,
- la méthode consiste à minimiser d*(u1, …, un) avec pour contrainte g*(u1, …, un) = 0.
C'est une méthode d'optimisation quadratique : en effet, minimiser d* revient à minimiser d*2 (puisque la fonction carré est strictement croissante sur [0 ; +∞[), on doit donc minimiser une fonction quadratique ∑xi2 avec une contrainte linéaire.
La distance minimale trouvée est appelée indice de fiabilité et est noté β (lettre grecque bêta) :
- β = d*(x*).
Méthode FORM
On fait l'hypothèse que la fonction g est linéaire. Si ce n'est pas le cas, la méthode revient finalement à en prendre le développement limité du premier ordre.
La probabilité de défaillance vaut alors
- Pf = Φ(-β).


Méthode SORM
La méthode SORM est identique à la méthode FORM, mais si g* n'est pas linéaire, alors on utilise une approximation du second ordre pour déterminer Pf.
On définit les courbures principales κi (lettre grecque kappa) :

Elles sont au nombre de n - 1, puisque l'équation g* = 0 définit une hypersurface de dimension n - 1.
La probabilité de défaillance s'écrit alors :
- Pf = S1 + S2 + S3
avec :


![{\displaystyle \mathrm {S} _{3}=(\beta +1)(\beta \Phi (-\beta )-\varphi (\beta ))\left[\prod _{j=1}^{n-1}{\frac {1}{\sqrt {1+\beta \kappa _{j}}}}-\mathrm {Re} \left(\prod _{j=1}^{n-1}{\frac {1}{\sqrt {1-(\beta +i)\kappa _{j}}}}\right)\right]}](https://img.franco.wiki/i/e327f0e777483589fef773002a69b008568f7b7c.svg)
où Re est la partie réelle, i est l'imaginaire, et φ est la densité de probabilité de la loi normale centrée réduite.
La fonction S1 est l'approximation asymptotique de Pf lorsque β tend vers +∞ — c'est donc le terme prépondérant si la conception est robuste (le point de conception est loin de l'origine) —, et S2 et S3 sont des termes correctifs.
Application à un problème à deux variables normales
Présentation du problème

Dans la méthode contrainte-résistance, la condition sur la durée de vie
- F(t) ≤ α
s'exprime par une résistance R supérieure à une contrainte S (stress) :
- R ≥ S
ou plutôt en définissant la marge m = R - S :
- m ≥ 0.
Cette marge m est donc une fonction de défaillance :
- g(R, S) = m.
Si l'on dispose des distributions (densités de probabilité) ƒR et ƒS, on peut alors déterminer cette probabilité :
- F(t) = P(R ≤ S) = P(m ≤ 0)
La probabilité d'avoir une couple de valeurs dans un intervalle ([S, S + dS], [R, R+dR]) est donné par
- P([S, S + dS]∩[R, R+dR]) = P([S, S + dS])×P([R, R+dR]) = ƒS׃R×dS×dR.
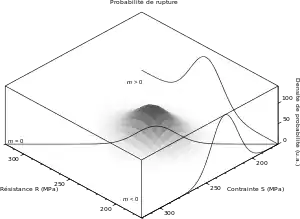
On peut tracer la surface y = ƒS׃R, ainsi que la ligne de séparation m = 0 : cette ligne marque l'état limite entre la situation de survie et la situation de défaillance. Une méthode simple d'estimer la probabilité P(m ≤ 0) consiste à utiliser une méthode de Monte-Carlo : on effectue N tirages aléatoires de couples (R, S), et l'on dénombre les n situations pour lesquelles m ≤ 0 :
- P(m ≤ 0) ≃ n/N.
Si l'on veut un risque α faible, cela signifie que le sommet de la surface doit être loin de l'état limite m = 0.
Le point que l'on veut le mieux connaître est le maximum de la courbe m = 0 ; c'est notre « point de conception ». Si le risque α est faible, alors le point de conception est loin du sommet de la surface. Cela signifie que lors du tirage aléatoire, peu de points seront proches du point de conception ; il faudra donc de très nombreux tirages — N devra être très grand — si l'on veut caractériser ce point.
Exemple
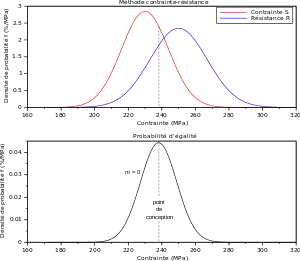
Nous avons représenté ci-contre une situation pour laquelle :
- la contrainte S suit une loi normale d'espérance μS = 230 MPa et un écart type σS = 14 Mpa ;
- la résistance R suit une loi normale d'espérance μR = 250 MPa et un écart type σR = 17 Mpa.
Graphiquement, on constate que le maximum de l'état limite se trouve à 238 MPa. Ce point est en général proche de l'intersection des courbes ƒS et ƒR.
Une méthode de Monte-Carlo avec un million de tirages et un intervalle de confiance de 5 %[1] donne 18,1 % ± 0,2 % de défaillance.
Le logiciel LibreOffice Calc est un tableur libre et gratuit.
La fonction ALEA (ou RAND en anglais)[2] donne un nombre aléatoire compris entre 0 et 1, mais avec une loi uniforme. Pour avoir une loi normale, il faut appliquer la fonction LOI.NORMALE.INVERSE (NORMINV)[3]. On compare simplement deux valeurs avec l'opérateur >, ce qui donne un booléen ; Calc calcule la moyenne (commande MOYENNE, MEAN) de booléens en prenant 1 pour « vrai » et 0 pour « faux ». Il faut ensuite étirer une boîte de… un million de lignes, ce qui n'est pas raisonnable, et touche les limites du logiciel[4].
On se limite ici à mille lignes, ce qui donne un résultat à ± 5 %.
| A | B | C | D | |
|---|---|---|---|---|
| 1 | R | S | ||
| 2 | mu | 250 | 230 | |
| 3 | sigma | 17 | 14 | |
| 4 | ||||
| 5 | n° | Valeur R | Valeur S | S>R |
| 6 | 1 | =LOI.NORMALE.INVERSE(ALEA() ; B$2 ; B$3) |
=LOI.NORMALE.INVERSE(ALEA() ; C$2 ; C$3) |
=C6>B6 |
| … | ||||
| 1006 | =MOYENNE(D6:D1005) | |||
| 1007 | ||||
| 1008 | epsilon | =RACINE(LN(2/0,005)/(2*1001)) | ||
Le logiciel R est un logiciel libre et gratuit, sous la forme d'un langage de programmation interprété, qui permet d'effectuer des calculs statistiques. La méthode de Monte-Carlo se fait de la manière suivante :
- On crée deux matrices R et S de un million de nombres tirés aléatoirement avec une loi normale (commandes
rnorm()). - On crée une matrice booléenne Mbool, contenant des « vrai » si la contrainte S est supérieure à la résistance R (opérateur
>). - On calcule la moyenne de cette matrice, les « vrai » étant comptés comme des 1 et les « faux » comme des 0 (commande
mean()).
N = 1e6 # nombre d'événements (tirs)
alpha = 0.005 # risque
# paramètres des lois
muR = 250
sigmaR = 17
muS = 230
sigmaS = 14
# calculs
R = rnorm(N, muR, sigmaR)
S = rnorm(N, muS, sigmaS)
Mbool = S>R
moyenne = mean(Mbool)
epsilon = sqrt(log(2/alpha)/(2*(N + 1)))
# affichage des résultats
print(moyenne)
print(epsilon)Scilab est un logiciel libre et gratuit de calcul scientifique. Il se présente comme un langage interprété.
Le tirage aléatoire de R et de S se fait avec la fonction rand() ; l'option "normal" indique qu'il utilise une loi normale centrée réduite. On détermine une matrice booléenne Mbool contenant des « vrai » si S est plus grand que R, avec l'opérateur >. La fonction sum() calcule la somme des éléments de la matrice en considérant les « vrai » comme des 1 et les « faux » comme des 0.
N = 1e6; // nombre d'événements (tirs)
alpha = 0.005; // risque
// Paramètres des lois
muR = 250;
sigmaR = 17;
muS = 230;
sigmaS = 14;
// Calculs
R = muR + sigmaR*rand(N, 1, "normal"); // résistance
S = muS + sigmaS*rand(N, 1, "normal"); // contrainte
Mbool = S>R; // comparaison des valeurs (matrice de booléens)
moyenne = sum(Mbool)/N; // les "vrai" comptent pour 1 et les "faux" pour 0
epsilon = sqrt(log(2/alpha)/(2*(N + 1)));
// Affichage des résultats
disp(string(100*moyenne)+" % +/- "+...
+string(100*epsilon)+" %") // affichage du résultat
Mise en œuvre de la méthode FORM
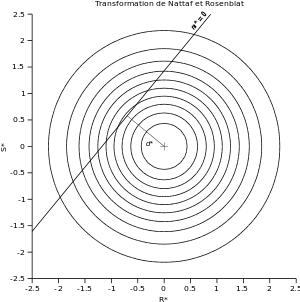
La méthode FORM est une méthode permettant d'obtenir une valeur approchée de la probabilité de défaillance à partir du point de conception. Elle suppose que les distributions de S et de R sont normales.
La première étape consiste à passer dans l'espace des lois centrées réduites : on transforme les coordonnées pour avoir des probabilités de densité d'espérance nulle et de variance 1. Cette étape est appelée « transformation de Nattaf et Rosenblatt ». Les nouvelles coordonnées sont appelées S* et R* :
- ;
- .


Le sommet de la surface ƒS*׃R* se trouve donc aux coordonnées (0 ; 0). La droite d'état limite m = 0 (R - S = 0) devient donc :

ce que l'on peut noter
- m* = 0
avec
- m*(R*, S*) = σR×R* + μR - (σS×S* + μS).
Le point de conception est le point de densité de probabilité maximale sur la droite m* = 0. Du fait des propriétés de symétrie de la surface ƒS*׃R*, c'est aussi le plus proche de l'origine (0 ; 0) — sommet de la surface —, c'est-à-dire celui pour lequel la quantité
- d*2 = R*2 + S*2
est minimale.
Pour trouver ce point, on part d'un couple (R*, S*) arbitraire, et l'on applique un algorithme d'optimisation (itératif) pour avoir le minimum de d* avec comme contrainte m* = 0.
La distance d* atteinte est alors l'indice de fiabilité β, et la probabilité de défaillance Pf s'obtient avec la fonction de répartition Φ de la loi normale centrée réduite :
- Pf = Φ(-β) ;
c'est la méthode FORM.
Notons que la surface obtenue avec la transformation de Nataff et Rosenblatt est toujours la même ; c'est la droite m* = 0 qui change d'un problème à l'autre.
Exemple
La transformation de Nattaf-Rosenblatt est :
- ;
- .


On a
- m* = 17×R* + 250 - (14×S* + 230) = 17×R* - 14×S* + 20.
L'optimisation nous donne le point de conception suivant :
- R* = -0,701 ; S* = 0,577 ; R = S = 238 MPa
- β = 0,908 ;
- Pf = 0,182 = 18,2 %.
Comme dans notre exemple les lois sont effectivement normales et g* est effectivement linéaire, nous avons un résultat « exact » aux arrondis près : l'approximation provient uniquement du fait que l'on a une résolution numérique.
Les logiciels ont en général deux types de solveurs. Certains utilisent un solveur non-linéaire « généraliste » ; il faut donc leur définir la fonction g, ainsi que la contrainte
- h = 0, avec h = σR×R* - σS×S* + (μR - μS).
Le solveur cherche à minimiser une fonction qui est la distance à laquelle on ajoute une fonction permettant de prendre en compte la contrainte (par exemple une pénalité qui augmente vers +∞ lorsque l'on s'éloigne des conditions de contrainte). C'est le cas des solveurs des tableurs, et du solveur constrOptim() du langage R.
Mais nous sommes ici en présence d'un problème d'optimisation quadratique, ce qui permet d'utiliser un solveur spécifique (Goldfarb et Idnani) ; c'est le cas de la fonction solve.QP du langage R, et de la fonction qpsolve de Scilab. Le problème s'écrit alors de manière matricielle

avec

avec une contrainte d'égalité unique :
- C×x = b
avec
- C = (σR ; -σS) ; b = (μS - μR).
Le problème est ici relativement simple, nous pouvons donc le résoudre « à la main ». Nous évoluons sur une droite m* = 0, soit d'équation
| expression littérale | application numérique | |
|---|---|---|
| 17×R* - 14×S* + 20 = 0 | ||
| ⇔ S* = (17/14)×R* + 20/14 |


On cherche à minimiser d*2 = R*2 + S*2, qui s'écrit
| expression littérale | application numérique | |
|---|---|---|
| d*2 = R*2 + ((17/14)×R* + 20/14)2 |

soit
| expression littérale | application numérique | |
|---|---|---|
| d*2 ≃ 2,474×R*2 + 3,469×R* + 2,041 |

Le minimum est là où la dérivée s'annule : (d*2)' = 0 ⇔
| expression littérale | application numérique | |
|---|---|---|
| 4,948×R* + 3,469 = 0 | ||
| ⇔ R* = -0,7010 |


et donc
| expression littérale | application numérique | |
|---|---|---|
| d* = 0,908 |

La table de valeurs de la fonction de répartition de la loi normale donne
- Φ(-0,908) = 1 - Φ(0,908) ≃ 1 - Φ(0,91) = 1 - 0,81859 ≃ 0,181.
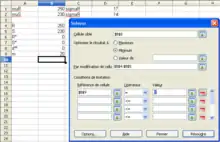
Le tableur libre LibreOffice Calc dispose d'un solveur.
On construit le tableau suivant :
| A | B | C | D | |
|---|---|---|---|---|
| 1 | muR | 250 | sigmaR | 17 |
| 2 | muS | 230 | sigmaS | 14 |
| 3 | ||||
| 4 | R | 250 | ||
| 5 | S | 230 | ||
| 6 | R* | =(B4 - B1)/D1 | ||
| 7 | S* | =(B5 - B2)/D2 | ||
| 8 | d*² | = B6^2 + B7^2 | ||
| 9 | m | = B4 - B5 |
Puis on va dans le menu Outil > Solveur, et dans la boîte de dialogue Solveur qui apparaît, on met :
- Cellule cible :
B8 - Optimiser le résultat à :
minimum - Par modification de cellules :
B4:B5 - Conditions de limitation :
- Référence de cellule :
B9 - Opérateur :
= - Valeur :
0
- Référence de cellule :
Le solveur d'optimisation utilisé est la commande constrOptim. C'est un solveur non-linéaire qui applique les contraintes par la méthode de la « barrière logarithmique ». La fonction optimisée est
- d*2 = R*2 + S*2
La contrainte linéaire est sous la forme
- u1×x - c1 ≥ 0
Bien que la méthode requiert une égalité dans la contrainte, l'inégalité est ici suffisante : le point le plus proche de l'origine est nécessairement sur la frontière g* = 0, il n'est pas nécessaire de contraindre la solution à rester sur cette frontière, elle s'y retrouvera nécessairement. Il faut par contre choisir le bon sens pour l'inégalité, pour être du côté des distances « élevées », donc la valeur calculée doit être positive pour S* > R*. Il faut donc prendre pour inégalité
- - σR×R* + σS×S* - (μR - μS) ≥ 0
donc u1 est le vecteur ligne (-σR ; σS), x est le vecteur colonne (R* ; S*) et c1 vaut μR - μS.
On lui passe en paramètres :
- le point de départ theta, qui doit être dans la « zone de faisabilité » u1×x - c1 ≥ 0 ; on choisit arbitrairement le point (0 ; 2) ;
- la fonction à optimiser ;
NULL, indiquant que l'on ne donne pas l'expression du gradient ;- les paramètres de la contrainte linéaire, ui et ci ;
- un paramètre de précision, mu.
Le résultat a est sous la forme d'une liste de vecteurs :
a$parest le vecteur (R*, S*) trouvé, c'est-à-dire le point de conception ;a$valueest la valeur de la fonction en ce point, β2.
# paramètres de la loi
muR <- 250
sigmaR <- 17
muS <- 230
sigmaS <- 14
# point de départ (R, S) de l'optimisation
theta <- rbind(0, 2)
# fonction à optimiser
detoile2 <- function(x) { # carré de la distance à l'origine, d*²
Retoile <- x[1]
Setoile <- x[2]
Retoile^2 + Setoile^2
# aperm(x) %*% x
}
# contrainte linéaire
u1 <- c(-sigmaR, sigmaS)
c1 <- muR - muS
# calcul
a <- constrOptim(theta, detoile2, NULL, u1, c1, mu=1e-3) # optimisation
x <- a$par # (R*, S*)
R <- x[1]*sigmaR + muR
#S <- x[2]*sigmaS + muS
detoile <- sqrt(a$value)
Pf <- pnorm(-detoile)
# affichage des résultats
print(paste("R* = ", x[1], " ; S* = ", x[2]))
print(paste("R = S = ", R))
print(paste("beta = ", detoile))
print(paste("Pf = ", Pf))S'agissant d'un problème de programmation quadratique, on peut également utiliser la fonction solve.QP de l'extension quadprog (qui est normalement installé par défaut).
#install.packages("quadprog")
library("quadprog")
# paramètres de la loi
muR <- 250
sigmaR <- 17
muS <- 230
sigmaS <- 14
# Optimisation
Dmat <- rbind(c(1, 0), c(0, 1))
dvec <- c(0, 0)
Cmat <- cbind(c(-sigmaR, sigmaS))
bvec <- c(muR - muS)
a <- solve.QP(Dmat, dvec, Cmat, bvec)
x <- a$solution # (R*, S*)
R <- x[1]*sigmaR + muR
#S <- x[2]*sigmaS + muS
detoile <- sqrt(2*a$value)
Pf <- pnorm(-detoile)
# affichage des résultats
print(paste("R* = ", x[1], " ; S* = ", x[2]))
print(paste("R = S = ", R))
print(paste("beta = ", detoile))
print(paste("Pf = ", Pf))Le logiciel libre Scilab dispose de fonctions d'optimisation.
C'est un cas de programmation quadratique avec une contrainte d'égalité unique (me = 1) ; il n'y a pas de limite inférieure ni supérieure. Le script utilisé est donc :
// Données
muR = 250;
sigmaR = 17;
muS = 230;
sigmaS = 14;
// Optimisation
Q = [1, 0 ; 0, 1];
p = [0 ; 0];
C = [sigmaR, -sigmaS];
b = muS - muR;
ci = [];
cs = [];
me = 1;
[x] = qpsolve(Q, p, C, b, ci, cs, me); // Solveur
// Exploitation des données
R = x(1)*sigmaR + muR;
d = norm(x);
Pf = cdfnor("PQ", -d, 0, 1); // fonction Phi
// Affichage
disp("R* = "+string(x(1))+" ; S* = "+string(x(2)));
disp("R = S = "+string(R));
disp("beta = "+string(d));
disp("Pf = "+string(Pf));
Notes et références
- l'erreur pour un risque α avec N tirages vaut
soit
- Fonctions mathématiques (aide lLibreOffice)
- Fonctions statistiques - Quatrième partie (aide LibreOffice 3.3)
- Quel est le nombre maximum de cellules dans une feuille de calcul LibreOffice ?, FAQ LibreOffice Calc


Voir aussi
Bibliographie
- (en) Shankar Sankararaman et Kai Goebel, « Uncertainty Quantification in Remaining Useful Life of Aerospace Components using State Space Models and Inverse FORM », IEEE Aerospace Conference, IEEE, (lire en ligne)
- (en) L. Cizelj, B. Mavko et H. Riesch-Oppermann, « Application of first and second order reliability methods in the safety assessment of cracked steam generator tubing », Nuclear Engineering and Design, Elsevier, no 147, (lire en ligne)