GraphQL
GraphQL[1] (pour Graph Query Language) est un langage de requêtes et un environnement d'exécution, créé par Facebook en 2012, avant d'être publié comme projet open-source en 2015[2]. Inscrit dans le modèle Client-Serveur, il propose une alternative aux API REST[1]. La requête du client définit une structure de données, dont le stockage est éventuellement distribué, et le serveur suit cette structure pour retourner la réponse[3]. Fortement typé, ce langage évite les problèmes de retour de données insuffisants (under-fetching) ou surnuméraires (over-fetching).
| GraphQL | ||
| Date de première version | 2012 (Facebook) | |
|---|---|---|
| Paradigmes | déclaratif, procédural, orienté objet | |
| Développeurs | The GraphQL Foundation | |
| Influencé par | JavaScript Object Notation Hypertext Transfer Protocol |
|
| Implémentations | Facebook, ArangoDB, Credit Karma, GitHub, Intuit, PayPal, New York Times | |
| Écrit en | JavaScript, Ruby, Scala, Python entre autres. | |
| Système d'exploitation | Multiplateforme | |
| Licence | Open-source (depuis 2015) | |
| Site web | graphql.org | |
| Extension de fichier | graphql | |
Principe
Une API GraphQL permet de récupérer des données en fonction de la requête client. En REST, c'est la méthode de requête HTTP (GET, POST,...), l'URL ou encore les paramètres envoyés qui définissent les fonctions métiers à appeler et la nature du retour. GraphQL le fait directement avec la requête envoyée en POST. Comme les requêtes POST ne sont pas mises en cache côté serveur, les requêtes GraphQL doivent être mises en cache côté client[4].
Langage de requêtes
La particularité de GraphQL est que la structure de la réponse du serveur est fixée par le client (conformément aux limites de l'API). Par exemple, c'est lui qui décide des champs qu'il souhaite pour chaque Objet, et dans quel ordre il veut les recevoir.
Prenons la situation d'un fournisseur de fruits & légumes. Il dispose d'une API GraphQL lui permettant d'obtenir toutes les commandes qu'on lui a effectué et leurs détails. Lorsqu'il consulte sa plateforme de gestion, son navigateur adresserait la requête suivante via la méthode POST :
{
orders {
id
productsList {
product {
name
price
}
quantity
}
totalAmount
}
}
Après traitement de la réponse par l'API (dont le client n'a pas forcément connaissance), le serveur répondrait comme suit :
{
"data": {
"orders": [
{
"id": 0,
"productsList": [
{
"product": {
"name": "orange",
"price": 1.5
},
"quantity": 100
}
],
"totalAmount": 150
}
]
}
}
Dans cet exemple, un produit peut posséder beaucoup plus d'attributs que simplement le nom et le prix. Mais dans notre situation, le fournisseur n'a pas besoin de plus d'informations que ça. De cette manière, l'utilisation de GraphQL a permis au client de se passer des informations inutiles, et donc de gagner du temps et des ressources. Le problème de données surnuméraires, dit over-fetching, a ainsi été évité. De même, l'API GraphQL a garanti l'obtention de toutes les informations nécessaires à la consultation du fournisseur, ce qu'une API REST n'aurait pas forcément permis en une requête seulement. Cette fois, c'est le problème de données insuffisantes, ou under-fetching, qui a été évité.
Environnement d'exécution
Une API GraphQL est organisée grâce aux Types et Champs. Pour déclarer l'ensemble de ces éléments, le fournisseur de données doit construire le squelette de l'API. C'est ce schéma qu'il partagera avec tous les clients qu'il souhaite, sans qu'ils aient besoin de savoir comment les données ont été récupérées. Dans l'exemple précédent, le schéma pourrait être celui-ci :
type Query {
orders: [Order]
}
type Product {
id: Int!
name: String
weight: Float
price: Float
}
type Order {
id: Int!
productsList: [
product: Product
quantity: Int
]
totalAmount: Int
}
Le premier Type, Query, contient toutes les requêtes de consultation admises par l'API. Dans l'exemple, on retrouve la règle orders, qui permet de recevoir un ensemble d'objets Order. Un autre Type existe aussi, Mutation, contenant toutes les règles de mise à jour des données, comme les insertions par exemple. Les deux blocs suivants définissent les structures de objets Product et Order. Comme expliqué dans la section précédente, le client pourra demander tous les attributs de chaque type, ou moins.
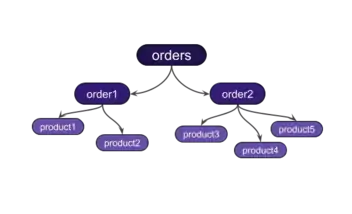
À travers la déclaration du squelette de l'API, on comprend mieux l'appellation du langage : GraphQL. En effet, une réponse conforme au schéma de l'exemple peut être représentée par l'arbre ci-contre. Un premier niveau de l'arbre contient toutes les commandes (orders). À chaque branche order, on retrouve d'autres sous-divisions product, correspondant aux champs productsList. Dans une API REST, il aurait par exemple fallu demander la liste des commandes, puis pour chaque commande, demander les produits qui y appartiennent. Dans l'idée, la structure arborescente de GraphQL devient plus avantageuse quand l'arbre devient plus profond. Le langage a peu de limites puisqu'il est capable de prendre en charge des relations beaucoup plus complexes, avec des objets interdépendants par exemple.
Attention à la confusion : le nom de Graph Query Language ne vient pas du fait que GraphQL est destiné aux bases de données orientées graphes, mais bien de la structure arborescente des réponses aux requêtes. Il ne faut donc surtout pas confondre GraphQL avec GQL.
Utilisations
GraphQL a été implémenté pour de nombreux langages, par exemple Graphene[5] pour Python, Apollo[6] et Relay[7] pour Javascript. Il est utilisé par certaines bases de données orientées graphe comme ArangoDB en tant que langage de requête[8].
Facebook est le premier instigateur de GraphQL. En effet, les applications iOS étaient souvent confrontées à des saturations de la consommation des données. Une application mobile doit donc prendre en compte la possibilité que l'utilisateur ait une faible bande passante, ce qui se traduit par un besoin de réduire au minimum le nombre d'appels à une API ainsi que la quantité de données transmises. Le principal avantage de GraphQL est ainsi de pouvoir fournir une application via une requête unique, en déléguant au serveur la tâche de structurer les données. On épargne ainsi au client des échanges réseau multiples, ce qui autorise un gain de temps appréciable.
Inconvénients
Du fait que la structure d'une réponse d'une API GraphQL est personnalisable par le client, l'utilisation d'un cache côté serveur est peu envisageable. En effet, les requêtes et leurs réponses dépendent du client.
Références
- (en) « GraphQL: A query language for APIs. »
- « GraphQL: A data query language »
- Romain Calamier, « GraphQL: Et pour quoi faire ? », sur blog.octo.com,
- « GraphQL & Caching : The Elephant in the Room », sur Apollo GraphQL Blog (consulté le ).
- « GraphQL in Python made simple »
- (en) « Page d'accueil d'Apollo GraphQL »
- (en) « Introduction to Relay », sur https://facebook.github.io/
- « Using GraphQL with NoSQL database ArangoDB »