Gestionnaire de mémoire virtuelle
Le gestionnaire de mémoire virtuelle est un circuit électronique (MMU) qui permet de réaliser le mécanisme de la mémoire virtuelle, à savoir la translation des adresses virtuelles en adresses physiques.
Le concept de mémoire virtuelle est assez ancien, il a été implémenté dans les années 1960 et il est toujours très utilisé. Son but est d'augmenter la taille de la mémoire utilisable, de mettre en place des mécanismes de protection et de faciliter l'allocation de la mémoire utilisée par un processus en simplifiant le travail des développeurs. L'origine de cette découverte est la différenciation entre l'espace d'adressage virtuel et l'espace d'adressage physique.
Même si les mécanismes mis en jeu rendent de grands services, ils ont un coût en matière de performance, celle-ci est un enjeu important actuellement ; les internautes sont très sensibilisés aux temps de réponse. Le paradoxe est le suivant : Les applications sont de plus en plus complexes et demandeuses de mémoire toutefois, les utilisateurs sont de plus en plus exigeants en ce qui concerne la performance.
L'autre défi majeur relevé par la mémoire virtuelle, c'est la protection de la mémoire. De fait, une étanchéité entre les différents programmes doit être assurée. Le problème actuel est de garantir cette sécurité face aux différentes attaques (attaques par relais, par codes arbitraires).
Le concept de Mémoire Virtuelle est en constante évolution, il est remis en cause dans certains types d'architectures tels que : Les Big Memory Server (en) ou les Systèmes Big Data car trop coûteux en temps.
Généralités
Définitions
Principe de base : toutes les informations d’un programme ne peuvent être référencées par le processeur que lorsqu’elles se trouvent en Mémoire centrale. L’information qui a besoin d’être référencée rapidement doit résider en mémoire centrale et toutes les autres informations doivent être en mémoire auxiliaire (mémoire de masse). Il serait trop couteux en ressource de charger l'intégralité des programmes exécutés par un ordinateur en mémoire, c'est une des raisons pour lesquelles le procédé de mémoire virtuelle a été mis au point à la fin des années 1950[1] - [2].
Les mémoires
La mémoire physique correspond à la mémoire physiquement installée, c'est-à-dire principalement à la mémoire vive dynamique, la RAM[3]. Il s'agit d'une zone de stockage temporaire, une mémoire de travail, dans laquelle sont chargés les données et les programmes[4] - [5] qui seront traitées par le processeur. On utilise également d'autres dispositifs, tels que les disques durs, les disques SSD comme espace d'échange (zone de swap).
Une hiérarchie des mémoires s'établit suivant les principales caractéristiques qui sont : le temps d'accès, la persistance des données, l'espace d'adressage.
Les mémoires vives (RAM) sont dites volatiles et possèdent un temps d'accès aux données de quelques dizaines de nanosecondes, et les mémoires comme celle du disque dur ont des accès plus lents : quelques millisecondes, on les appelle aussi Mémoire de masse[6].
Espace d'adressage
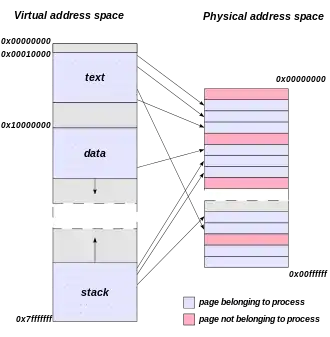
L'espace adressable par le processeur se distingue de l'espace réellement adressable dans la mémoire physique :
- L'espace d'adressage virtuel (Virtual address space) est généré par le processeur au moment de l’exécution des instructions. C'est l'espace accessible, qui dépend donc du nombre de bits utilisés par le processeur pour coder les adresses[7]. Cet espace d’adressage est constitué du code, des données, de la pile d’exécution (stack) ;
- L'espace d'adressage physique (Physical address space) correspond aux adresses chargées réellement en mémoire centrale, physique, pour qu'un programme puisse s'exécuter[8].
Un processus pour qu'il puisse s'exécuter doit être chargé en mémoire centrale. Si plusieurs programmes sont concurrents, il est nécessaire :
- d'allouer suffisamment de place en mémoire centrale pour le code et les données de chaque processus ;
- de garantir un espace d’adressage étanche pour chaque processus[9].
Les mécanismes de la mémoire virtuelle permettent de répondre à ces deux besoins principaux.
Unité de Gestion Mémoire
La MMU (Memory Management Unit ou PMMU Paged Memory Management Unit) est le circuit électronique qui rend possible la mémoire virtuelle, c'est par son intermédiaire que seront converties (en anglais mapping) les adresses mémoires virtuelles en adresses physiques[10] - [11].
TLB (Translation Lookaside Buffer)

Pour améliorer le temps d'accès à la mémoire, un ensemble de registres attachés à la MMU, met en œuvre une mémoire cache : TLB (Translation Lookaside Buffer)[12] - [11] - [13].
Le TLB mémorise les dernières correspondances entre les adresses virtuelles et les adresses physiques pages, cadres utilisées par un processus.
Cette mémoire cache contient les numéros de page ainsi que l'adresse de la case contenant la plus récemment accédée. La MMU cherche en premier lieu dans le cache s'il existe une déjà une correspondance entre la page et l'adresse d’implantation de la case[14].
Principe de la Pagination
Les données sont organisées dans la mémoire virtuelle sous forme de pages ou de segments, il y a aussi un autre mode d'organisation qui combine les deux.
Dans la mémoire physique elles sont organisées sous forme de cadres, une page correspond à un cadre. Donc quand un programme a besoin d'être chargé en mémoire centrale, il faut donc placer les pages dans n’importe quelle case (ou cadre) disponible.
La correspondance entre les pages de la mémoire virtuelle et les cases de la mémoire centrale se fait par la table de pages[15].
- Tables de pages

La taille d'une page est en moyenne de 4Ko. Les adresses des données dans une page sont constituées d'un couple numéro de page et déplacement à partir du début de cette page.
La MMU permet d'associer une adresse virtuelle à une adresse mémoire physique[16]. Elle reçoit en entrée une adresse virtuelle et vérifie qu'elle correspond bien à une adresse physique si c'est le cas, elle transmet l'information à la mémoire physique sinon il se produit ce qu'on appelle un défaut de page[17] - [18].
S'il n'existe plus de cases mémoire disponible en mémoire physique, la mémoire virtuelle peut combiner ces mécanismes avec le swapping, pour trouver de la disponibilité mémoire sur le disque[19] - [20].
Il y a de nombreux mécanismes pour traduire les adresses virtuelles en adresses mémoire physiques, cela dépend de la manière dont sont stockées les données en mémoire : sous forme de pages de taille fixe, ou en segments de tailles variables ou en segments divisés en pages[21].
La MMU a aussi pour rôle de protéger le Système d'exploitation des accès non autorisés à des zones de la mémoire. Dans la table des pages, on trouve pour chaque entrée, un bit de validité qui indique s'il existe bien une page physique correspondant à la page virtuelle demandée, ainsi que des informations sur les droits d'accès en écriture ou en exécution, à l'accès autorisé en mode utilisateur ou non[22] - [23].
Le mécanisme de conversion d'adresse s'effectue grâce à la table des pages. Dès qu'un processus est chargé en mémoire principale sa table de page est chargée aussi, son rôle est de conserver l'information suivante : Les adresses de pages (numéro de pages + numéro de déplacement dans la page) et les adresses de cadres correspondants à ce même processus, il faut noter qu'on se sert du numéro de page comme index dans la table des pages[24].
- Quelles sont les étapes dans la traduction de page ?
Une fois l'adresse virtuelle générée par le processeur, on vérifie d'abord en mémoire cache TLB, s'il existe une correspondance entre la page et la case (TLB hit), l'adresse physique est directement accessible en mémoire centrale.
Si aucune correspondance n'est trouvée (TLB miss), il faut alors se rendre dans la table de page pour déterminer l'adresse physique[26] - [13].
Une fois l'adresse physique déterminée, si le cadre de page existe, l'adresse physique est alors accessible en mémoire centrale. Si le cadre de page n'est pas trouvé en mémoire il se produit un défaut de page (page fault), il faut alors utiliser l'un des algorithmes de remplacement de page.
Pagination 64 bits
Une adresse virtuelle est divisée en un numéro de page et un déplacement (Offset). Le numéro de page est ensuite lui-même divisé en une séquence d'index, chaque index pointant vers l'entrée de la table suivante et ainsi de suite jusqu'à la dernière table. Au fur et à mesure que la taille des adresses virtuelles augmente, le nombre de table de pages augmente également (Par exemple, il y a quatre niveaux de table pour un processeur AMD Opteron de façon à prendre en charge une adresse virtuelle 64 bits, voir ci-dessous). À chaque décennie, la profondeur du nombre de tables augmente d'un niveau[27] - [28].
Illustration de la pagination en mode 64 bits
Ci-dessous la répartition des tables de pages sur 4 niveaux pour les processeurs AMD et Intel[29] - [30] :

- Niveau 0 PML4 (Page Map Level 4 Offset)
- Niveau 1 PDP (Page Directory- Pointer Offset)
- Niveau 2 PD (Page Directory Offset)
- Niveau 3 PT (Page Table Offset)
Le registre CR3 est utilisé pour pointer vers l'adresse de base de la table de traduction de page du plus haut niveau.
Une fois que cette adresse de base est trouvée, la MMU prend les bit 39 à 47 (total de 9 bits) comme un index dans la table de page PML4. La valeur dans cet index donne l'adresse de base de la page de la table PDP.
De même, les prochains 9 bits (30 à 38) donnent l'index dans la table de page PDP qui donne l'adresse de base de la table de page d'entrée PD.
De la même façon, on trouve l'index dans la table PD pour l'adresse de base de la table PT en utilisant les 9 bits suivants (21 à 29). Les 9 bits suivants (12 à 20) donnent l'index dans la table PTE qui donne l'adresse de base de la page physique réelle contenant les données et le code du processus[31].
Les 12 derniers bits correspondent au décalage (Offset) dans les 4Ko de la mémoire physique.
| Bits | Affectation des bits | ||
|---|---|---|---|
| 4 KiB Page | 2 MiB Page | 1 GiB Page | |
| 63... 48 | Inutilisés | ||
| 47... 39 | Index dans la table PML4 (engl. page mapping layer 4) | ||
| 38... 30 | Index dans la table PDP (engl. page directory pointer) | ||
| 29... 21 | Index dans la table PD (engl. page directory) | 30-Bit-Offset | |
| 20... 12 | Table de page PT (engl. page table) | 21-Bit-Offset | |
| 11... 0 | 12-Bit-Offset | ||
La mémoire virtuelle : Réponse à plusieurs besoins
Comme l'indique Peter J. Denning (en) dans un article de 2008, la mémoire virtuelle répond à plusieurs besoins[32]. Principalement, elle permet :
- la gestion automatique de l’allocation de mémoire : permet de résoudre le problème du manque d'espace mémoire physique disponible dans un ordinateur, c'est ce qui est à l'origine de cette découverte ;
- la protection : Comme indiqué dans le chapitre protection de la mémoire virtuelle. La mémoire virtuelle met en jeu des mécanismes afin que deux processus ne puissent pas écrire en même temps dans le même espace d'adressage ;
- la modularité des programmes : Les programmes sont développés sous forme des modules séparés partageables et réutilisables qui seront liés entre eux qu'au moment de l'exécution dans un espace d'adressage unique ;
- pour les programmes orientés objets : elle permet de définir des objets et des classes que le gestionnaire de mémoire peut accéder et modifier ;
- la programmation de données centralisées : d'après Peter Denning « le monde du Web consiste en une multitude de process qui naviguent à travers un espace d'objets partagés mobile ». Les objets peuvent être liés à un traitement sur demande . En effet en cliquant sur un lien on déclenche un traitement dans le navigateur (Applets Java) mais celui-ci ne doit pas avoir d'impact sur les objets locaux ;
- le calcul parallèle sur plusieurs Ordinateurs : la mémoire virtuelle partagée dans les systèmes distribués est une architecture qui permet de partager des espaces d'adressage virtuels pour 2 processeurs différents faisant référence à deux entités Mémoire Physique qui sont vues comme un seul espace d'adressage : elle est décrite dans la section DVSM[33] et plus précisément ici Distributed shared memory (en).
Mémoire virtuelle et performances
Évaluation de la performance
La pagination peut affecter significativement la performance d'un ordinateur.
D'après Silberschatz, si on définit[34]:
- effective access time (le temps d'accès effectif);
- la probabilité d'un défaut de page avec ;
- le temps d'accès à la mémoire;
- page fault time (le temps associé à un d'un défaut de page).





Quand il y a peu de défaut de pages, la probabilité d'un défaut de page tend vers :

- Le temps d'accès effectif est égal au temps d'accès à la mémoire .
Sinon :

Comme décrit dans Thrashing : Its causes and prevention par Denning, lorsque le nombre de défaut de page augmente significativement, le système effectue des opérations d'écroulement ou thrashing entraînant inévitablement une réduction de la performance. Le traitement d'un grand nombre de défauts de page peut provoquer un effondrement du système quand le celui-ci passe plus de temps à traiter les défauts de page qu'à exécuter des processus[35].
Algorithmes de remplacement de pages
À la suite d'un défaut de page, le système doit ramener la page manquante en mémoire centrale ; s'il n'y a plus de place en mémoire il faut alors retirer une Page et la mettre en mémoire auxiliaire : le disque, par exemple. C'est ce mécanisme qu'on appelle le « remplacement de page ». Il existe de nombreux algorithmes de remplacement de page pour circonscrire ce phénomène d'écroulement[17]:
Working set
Le working set (en) permet d'estimer la quantité de mémoire qu'un processus requiert dans un intervalle de temps donné.Suivant ce modèle, un processus ne pourra être chargé en RAM que si et seulement si l'ensemble des pages qu'il utilise peut y être chargé. Dans le cas contraire, le processus est swappé de la mémoire principale vers la mémoire auxiliaire de façon à libérer de la mémoire pour les autres processus[36].
Algorithme de remplacement LRU
Least Recently Used est l'algorithme le plus fréquemment utilisé : Toutes les pages en mémoire figurent dans une liste chainée, avec en tête de liste la plus récemment utilisée, quand le défaut de page survient , l'algorithme retire la page la moins récemment utilisée : celle qui est en queue. C'est un algorithme complexe difficile à implémenter qui nécessite son exécution par un matériel spécifique car il faut un mécanisme qui tienne compte du temps[37].
Algorithme FIFO (First In First Out)
First In First Out (Premier entré, premier sorti) est un algorithme qui constitue une liste chaînée avec les pages présentent en mémoire. Quand un défaut de page intervient il retire la plus ancienne, donc celle qui est en début de file.Ce mécanisme ne tient pas compte de l'utilisation des pages ; une page peut être retirée et tout de suite après rechargée en mémoire car un processus en a besoin[38].
NRU remplacement de la page Non Récemment Utilisée
Cet algorithme quant à lui utilise les bits R et M pour définir la page à retirer.
- R = Le Bit de Référence
- M = Le Bit de Modification
Le Bit R est positionné à 1 lorsqu'une page est Référencée et 0 lorsque la page n'est pas référencée. Le bit M est positionné à 1 lorsque la page est Modifiée et 0 lorsqu'elle ne l'est pas.
Quand un défaut de page intervient l'algorithme NRU retire en premier la page non référencée et non modifiée en premier :
- - R=0 et M=0
- sinon la page non référencée et modifiée :
- - R=0 et M=1
- sinon la page référencée et non modifiée :
- - R=1 et M=0
- sinon il retire la page référencée et modifiée ;
- - R=1 et M=1
Dans ce dernier cas la page sera sauvegardée sur disque avant d'être transférée en mémoire[39].
Clock
Dans l'algorithme Clock, les pages sont mémorisées dans une liste circulaire en forme d'horloge, Un indicateur pointe sur la page la plus ancienne. Lorsqu'un défaut de page se produit, la page pointée par l'indicateur est examinée. Si le bit R de la page pointée par l'indicateur est à 0, la page est retirée, la nouvelle page est insérée à sa place et l'indicateur avance d'une position. Sinon, il est mis à 0 et l'indicateur avance d'une position.
Cette opération est répétée jusqu'à ce qu'une page ayant R égal à 0 soit trouvée. À noter que lorsqu'une page est ajoutée, on met son bit de référence à 1.
Cet algorithme est aussi appelé algorithme de la seconde chance.
Performance dans une architecture Numa
Numa (Non Uniform Memory Access) est conçu pour les systèmes multiprocesseur dans lequel les zones mémoires sont séparées. L'architecture Numa sert à améliorer l'efficacité d'accès par les processeurs à tout l'espace mémoire, en effet, cet accès s'effectue par des Bus différents ce qui évite les baisses de performance liées aux éventuels accès concurrents par deux processeurs. Il existe aussi un autre type de gestion de la mémoire sur les multiprocesseurs : SMP (Symetric Multiprocessing), où il existe une seule mémoire partagée.
Un mécanisme d’ordonnancement dynamique des tâches a été mis au point par Chiang, Yang et Tu (DTAS) qui réduit les phénomènes de contention dans les systèmes Multi-Cœur NUMA. Pour éviter ce problème, les cœurs des processeurs qui partagent les ressources sont programmés pour exécuter des tâches complémentaires[40].
Les tâches sont classifiées comme étant de type traitement ou de type mémoire, chaque processeur est dédié à un type de tâche. Si l'énergie doit être économisée, la fréquence d'horloge du processeur effectuant des tâches liées à la Mémoire est diminuée pour réduire la consommation. À l'inverse, on peut augmenter la fréquence d'horloge d'un processeur qui doit faire plus de traitement, dans un souci d'efficacité. Ce mécanisme a été implémenté sur un système avec un noyau Linux.
Une amélioration de la performance de ce système a été constatée ainsi qu'une baisse de la consommation d'énergie en réduisant le taux de contentions entre les différents cœurs de processeurs.
Les Benchmaks révèlent une amélioration de 28 % des performances sur des systèmes avec un noyau linux 3.11.0 (tests effectués sur 1000 instructions).
Performance dans un environnement virtualisé
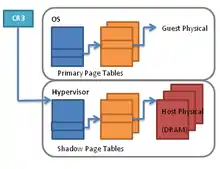
Shadow Page Table
Plusieurs tables de pages sont utilisées dans le déroulement des translations d'adresses dans les technologies de virtualisation, c'est ce qui est mis en œuvre avec les shadow page tables[41].
Une table sert à convertir les adresses virtuelles invitées (gva guest virtual address) en adresses physiques invitées (gpa guest physical address). L'autre pour convertir les adresses physiques invitées (gpa guest physical address) en adresses physiques hôte (hpa host physical address)[42].
Une table de pages appelée Shadow Page Tables mappe les adresses virtuelles invitées directement vers les adresses physiques hôte en Dram[43].
Slat
Pour des raisons de performance, Slat (en) (Second Level Address Translation) se substitue à la technique des Shadow Page Tables[44].
La mémoire physique invitée est considérée comme un sous-ensemble de la mémoire physique de l'hôte. Les tables de pages sont utilisées à plusieurs niveaux, la table de page d'hôte peut être considérée conceptuellement comme imbriquée (nested) dans la table de page d'invités. Cela réduit les recherches dans le stables de pages, et par là même la charge du processeur.
Extended Page Table (EPT) ou Table de Page étendue pour Intel, Nested Page Table (NPT) ou Table de Page Imbriquée pour AMD repose sur le même principe[45].
Élasticité de la mémoire : le ballooning
Memory balloon[46] est une technique de gestion de la mémoire qui permet à un hôte physique de récupérer de la mémoire inutilisée sur ses machines virtuelles invitées (VM). Cela permet à la quantité totale de RAM requise par une VM invitée de dépasser la quantité de RAM physique disponible sur l'hôte. Lorsque le système hôte ne possède pas suffisamment de ressources physiques en RAM, une partie de la mémoire est affectée aux différents ordinateurs virtuels. Cela répond au besoin d’équilibrer les charges mémoire, l'hyperviseur réaffecte la mémoire inutilisée par certaines machines virtuelles pour permettre à d’autres machines plus consommatrices d’obtenir de meilleures performances[47] - [48]
SwapCached
L'idée principale de SwapCached est la mise en cache des pages mémoires de des machines invitées dans la machine hôte de façon à augmenter la performance de la plateforme entière.
SwapCached est composé de trois modules : Cache Pool, Agent et Sensor. Les deux premiers composants sont dans l'hôte et contiennent les pages swappées et le dernier est localisé dans chaque machine invitée.Le prototype utilisé a été implémenté dans une plateforme Xen et a permis d'améliorer la performance globale de la plateforme de l'ordre de 10 % à 80 % en fonction des différents types de VM[49].
Performance dans un environnement mobile
Le mécanisme de swapping (backing store[50]) n'est pas implémenté dans les mobiles, par exemple pour les terminaux sous iOS : chaque programme possède bien son propre espace de mémoire virtuelle, mais la quantité d'espace de mémoire disponible se limite à la mémoire physique. Ceci conduit à gérer la mémoire liée aux applications de façon spécifique : si la quantité de mémoire disponible descend en dessous d'un certain seuil, le système demande aux applications en cours de libérer de l'espace mémoire[51] : sur iOS, la gestion de la mémoire liée aux applications est gérée par jetsam, et de façon identique par OOM (Out Of Memory) sous Android[52] - [53] - [54] - [55].
Dans ce contexte, Geunsik Lim propose dans Virtual memory partitioning for enhancing application performance in mobile platforms de mettre en place une gestion originale des applications en priorisant les applications natives, plutôt que les applications dont les sources sont moins fiables. Le mécanisme Virtual Memory Node, Vnode met en œuvre une isolation complète des applications peu fiables et réduit le nombre d'opérations des LMK/OOMK même quand les ressources mémoires sont critiques. La performance des applications natives est ainsi renforcée[56].
Pour autant, la mémoire à changement de phase (PCM) pourrait être amenée à être utilisée comme périphérique de swap. Yoo et Bahn présentent un nouvel algorithme de remplacement de page : DA-Clock (Dirtiness-Aware Clock). Les résultats expérimentaux montrent que l'algorithme améliore les performances de 24 à 74 % en minimisant le trafic en écriture sur la PCM, cet algorithme prolonge également la durée de vie de la mémoire de 50 % en moyenne[57].
Ce nouvel algorithme de remplacement de pages fonctionne sur les systèmes embarqués mobile qui utilisent de la DRAM comme mémoire principale et de la mémoire PCM comme périphérique de swap. Il s'inspire de l'algorithme Clock. Il garde la trace des pages et sous-pages dites dirty qui sont des pages contenant des données devant être écrites sur un support de stockage stable et se trouvant dans un cache avant d'être réclamées. Est remplacée la page la moins sale parmi les pages qui ont été le moins récemment utilisées. Pour ce faire, on utilise une liste circulaire et plusieurs listes de dirty pages dans lesquelles on sélectionne une page victime.
Une autre équipe a testé une nouvelle technologie appelée Cows (Copy On Write Swap-in) qui augmente les performances .
Dans cette technologie le mécanisme du swap a été totalement repensé pour les smartphones équipés de NVM (Non Volatile Memory). Au lieu d'utiliser de la mémoire flash on utilise la NVM comme zone se swap. Le mécanisme de copy-on-write swap-in évite des opérations de copies de la mémoire non nécessaires.
Sur les Smartphones il se produit souvent un phénomène particulier : les processus sont tués en permanence, ceci est dû au fait que la mémoire est saturée et le swapping est désactivé sur les téléphones pour des raisons de performance. Une expérience de 2014 a révélé que sur un Téléphone Google Nexus 5 avec l'option swap activée, sur 30 Minutes de test, le nombre de process « tués » a diminué de 66 % à 91 % grâce à trois éléments :
- Le NVM-swap ;
- Le copy-on-wrtite swap-in ;
- Le Heap-wear : un algorithme qui permet d'augmenter la durée de vie des NVM de 50 %[58].
Compression de la mémoire
La compression augmente la performance en permettant de réaliser la pagination en utilisant un bloc en mémoire RAM plutôt que sur le disque[59].
La zone de swap se trouve alors basée sur la RAM et fournit ainsi une forme de compression de mémoire virtuelle, permettant une performance accrue due au meilleur temps d'accès fourni par la RAM, le disque ayant un temps d'accès bien plus long. Il est dès lors d'autant plus important d'optimiser l'occupation de la mémoire principale. Srividya et Denakar proposent alors un mécanisme de dé-duplication de pages compressées : si une page compressée s'avère identique, au lieu d'être swappée, elle sera partagée[60].
Une nouvelle hiérarchie de la mémoire
Les mémoires non volatiles (NVM) comme STT-RAM (Magnetoresistive RAM) ou Mémoire à changement de phase (PCM).
Il existe d'abondantes recherches sur l'utilisation de la PCRAM comme remplacement des DRAM actuelle en tant que mémoire principale. Lee et al.[61] ont démontré qu'implémenter une architecture de mémoire basée exclusivement sur les PC-RAM serait environ 1,6 fois moins rapide et nécessiterait 2.2 fois plus d'énergie qu'une mémoire principale basée sur la DRAM, principalement en raison de la surcharge demandée par les opérations d'écriture. Pour améliorer cela, il propose d'organiser les buffers de la mémoire différemment de façon à diminuer la consommation d'énergie due aux opérations d'écriture. Qureshi[62] a proposé un système de mémoire principale hybride composée de PCM et de DRAM de façon à pouvoir tirer parti des avantages de la latence des DRAM et des avantages de la capacité de PCM. Cette architecture hybride pourrait réduire le nombre de défaut de page par 5 et améliorer la rapidité de traitement. Une étude similaire menée par Zhou[63] a démontré qu'une mémoire à base de PC-RAM ne consomme que 65 % de l'énergie totale de la mémoire principale de DRAM. Tous ces travaux démontrent la possibilité d'utiliser la PC-RAM comme mémoire principale[64] - [65] - [66] - [67].
Protection apportée par la mémoire virtuelle
La mémoire virtuelle garantit qu'aucun processus n'écrive dans l'espace d'adressage d'un autre processus ou du système d'exploitation sans y avoir été expressément autorisé. Elle permet ainsi de se prémunir contre les erreurs des autres programmes car chaque programme possède son propre espace d'adressage, mais également d'actions malveillantes éventuelles : sans cette protection, les virus informatiques seraient très largement répandus.
Pour autant, divers types d'attaque ont pu mettre au jour des failles et permettent de contourner les mécanismes de sécurité apportés par la mémoire virtuelle :
Attaque DMA
DMA est une méthode de transfert des données d'un périphérique vers la mémoire principale sans passer par le processeur, ce qui permet d'améliorer les performances de l'ordinateur[68].
Une application ne peut pas accéder à des emplacements de mémoire non explicitement autorisés par le contrôleur de mémoire virtuelle (MMU), ceci pour prévenir les dommages que causeraient des erreurs logicielles ou des manipulations malveillantes.
Toutefois, pour permettre aux périphériques (par exemple un caméscope, une carte réseau) d'obtenir une vitesse de transfert maximale, le système d'exploitation autorise un accès direct à la mémoire principale. Le principe de l'attaque DMA, est alors de profiter de cette vulnérabilité pour accéder directement à une partie ou à la totalité l'espace d'adressage de la mémoire physique de l'ordinateur, et réussir ainsi à lire des données, ou les corrompre[69]. Il est ainsi possible de contourner l'identification par mot de passe demandée par l'ordinateur avec l'outil Inception[70].
Contre-mesure à l'attaque DMA : IOMMU
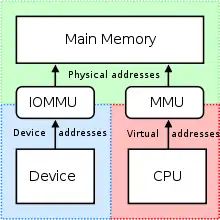
Une unité de gestion de mémoire d'entrée-sortie (IOMMU) est une unité de gestion de mémoire (MMU) qui connecte un bus des périphériques d'entrées/sortie d'accès direct à la mémoire (DMA) à la mémoire principale. Un exemple de IOMMU est la table des adresses graphiques (GART) utilisée par les cartes graphiques AGP et PCI Express sur les architectures Intel et AMD.
Une IOMMU de la même façon qu'une MMU, traduit les adresses virtuelles en adresses physiques[71]. C'est donc une technologie qui applique le concept de mémoire virtuelle aux périphériques.
Elle est utilisée aussi pour protéger la mémoire système contre des attaques véhiculées par les périphériques d'entrée-sortie comme l'attaque DMA. Cette protection devient critique dans les environnements virtualisés, parce que des machines virtuelles invitées partagent la même mémoire physique sur la machine hôte. Une VM malveillante pourrait corrompre une autre VM par une attaque DMA[72] - [69].
L'IOMMU est composé d'un ensemble de DMA Remapping Hardware Units (DRHU) qui sont responsables de la traduction des adresses des périphériques vers des adresses physiques en mémoire hôte. Le DRHU identifie d'abord une demande DMA par le bus BDF-ID (Bus Device Function Number), puis il utilise le BDF-ID pour localiser les tables de page associées avec le contrôleur d'entrée sortie. Finalement, il traduit l'adresse virtuelle DMA (DVA) en adresse physique hôte (HPA), tout comme l'effectuerait une MMU classique. Bien que l'IOMMU offre une protection efficace contre les attaques DMA, il doit être configuré correctement de façon à prévenir ces attaques. Plusieurs techniques permettent en effet de contourner les défenses apportées par une IOMMU[73].
Par exemple, en se concentrant sur la technologie Intel VT-D, Lacombe et al. démontrent qu'aucun contrôle d'intégrité n'étant effectué sur le champ source-id, il est alors possible d'usurper l'identité d'un périphérique, celui partageant le même bus PCI Express avec tous les autres périphériques, ils ont pu mener une attaque de type ARP-poisoning[74].
Attaque par martèlement de mémoire

Yoongu et al. ont démontré qu'il était possible de profiter d'une vulnérabilité des mémoires vives (DRAM), déjà étudiée dans les travaux de Huang[75], pour modifier la valeur des bits mémoire en sollicitant les cellules de façon répétée. Cette faille matérielle (rowhammer bug), martèlement de mémoire, est lié à la charge des condensateurs qui a sans cesse besoin d'être rafraîchie pour éviter que les cellules ne passent à 0. En martelant certaines zones, à des fréquences spécifiques, des chercheurs en sécurité de Project Zero de Google, Mark Seaborn et Halvar Flake, ont exploité cette particularité pour modifier les droits d'accès à la mémoire et manipuler ainsi les données de diverses manières. En particulier, ils ont pu rompre l'isolement entre le mode utilisateur et le mode noyau : une application localise les cellules mémoires vulnérables et force le système d'exploitation à remplir la mémoire physique à partir des entrées de la table de page (PTE) qui définit les stratégies d'accès aux pages de mémoire et de prendre le contrôle d'un ordinateur[76] - [77].
D. Gruss et C. Maurice ont pu déclencher le bug rowhammer à distance avec une application sous JavaScript. Pour autant, ils n'ont pas pu s'attribuer les droits root comme Seaborn l'avait fait, ce qui fera l'objet d'études ultérieures[78].
Une autre méthode d'attaque sur les DRAMs, basée sur du reverse engineering par les chercheurs Schwartz et al. a pu permettre de voler des données sensibles d'une machine virtuelle, en utilisant du code JavaScript (Code Reverse Engineering).Ils ont également amélioré l'attaque Rowhammer et a montré que, contrairement à ce que l'on pensait auparavant, la méthode fonctionnait aussi contre des RAMs de type DDR4[76] - [79] - [80].
Contre-mesure à l'attaque par martèlement de mémoire
La première méthode, baptisée B-CATT (Bootloader CAn't Touch This), ne nécessite aucune modification de l'OS et peut être utilisée sur tous les systèmes x86. B-CATT localise et désactive la mémoire physique vulnérable après l'avoir identifiée.
La seconde méthode, G-CATT (Generic CAn't Touch This), n'empêche pas toutes les inversions de bits induites par une attaque Rowhammer, mais empêche celles qui seraient en mesure d'affecter la mémoire appartenant à des domaines de sécurité élevé comme celui du noyau.
Selon les tests effectués par les chercheurs Ferdinand Brasseur et al., ces deux méthodes n'affectent ni la performance en ce qui concerne le temps d'accès à la mémoire ni en ce qui concerne la stabilité du système et permettraient de contrevenir à tous les types d'attaque rowhammer. Les deux mécanismes de protection n'ont eu que peu d'impact en ce qui concerne la latence et le débit sur les plateformes testées (SPEC CPU 2006 et Phoronix)[81].
Contrôle d'accès
En même temps que le processeur utilise la table d'entrée de pages (PTE) pour mapper les adresses virtuelles en adresses physiques, il utilise les informations de contrôle d'accès (Bits de protections) de cette même table, pour vérifier si un processus accède à la mémoire avec les autorisations adéquates.
L'accès aux zones mémoire peut en effet être restreint pour plusieurs raisons :
- Le système d'exploitation ne permet pas à un processus d'écrire des données sur son code exécutable.
- En revanche, les pages contenant des données peuvent être écrites mais tenter d'exécuter ces mêmes données comme du code exécutable ne doit pas être permis[82] - [83].
La plupart des processeurs ont au moins deux modes d'exécution: le mode noyau et le mode utilisateur. On ne doit pas permettre que le code du noyau soit exécuté par un utilisateur ou que des structures de données du noyau soit accessibles.
En mode noyau, le microprocesseur peut accéder à la mémoire physique, mais l’accès à un espace d’adressage virtuel (ou à toute autre zone de mémoire non définie) est interdit, il génère une interruption MMU.
En mode utilisateur, le microprocesseur peut accéder à la mémoire virtuelle (plus précisément aux pages de mémoire virtuelle autorisées par la MMU), mais l’accès à la mémoire physique (ou à toute autre zone de mémoire non définie) génère une interruption[84].
Chaque processus possède son propre espace de mémoire virtuelle (4 Go) qui mappe la mémoire physique par le biais des tables de pages. La mémoire virtuelle est principalement divisée en deux parties: 3 Go pour l'utilisation du processus et 1 Go pour l'utilisation du noyau (Pour Linux) (Pour Windows 2 Go/2 Go) La plupart des données qui se trouvent dans la première partie de l'espace d'adressage représente l'espace utilisateur. La seconde partie correspond à l'espace du noyau commun à tous les processus.
64-Bit-(Page directory entry) Bits: 63 62… 52 51… 32 Content: NX reserved Bit 51… 32 base address Bits: 31… 12 11… 9 8 7 6 5 4 3 2 1 0 Content: Bit 31… 12 base address AVL ig 0 ig A PCD PWT U/S R/W P
- Le Bit P indique si la page est en mémoire physique.
- Le Bit R/W indique si la page peut être lue ou écrite.
- Le Bit U/S indique si la page est accessible en mode utilisateur (user mode) ou en mode superviseur (supervisor mode').
Protection de la mémoire virtuelle contre un dépassement de tampon
D'après Smashing the stack for fun and profit par Elias Levy (en)[85], les attaques par débordement de tampon (buffer overflow, parfois également appelées dépassement de mémoire tampon) ont pour principe l'exécution de codes arbitraires par un programme qui remplit le tampon par plus de données qu'il ne peut en recevoir. Le système d'exploitation répond alors par une erreur de segmentation, et met fin au processus en générant une exception[86] - [87].
Une parade contre l'exécution de ce code arbitraire consiste à protéger l'espace exécutable. Cette technique est implémentée sur différents systèmes d'exploitation.
Par exemple, dans une architecture Intel, le bit 'NX' ou non exécutable bit, qui est le bit 63 des entrées de la table des pages (PTE) permet d'empêcher une tentative d'exécution sur des données d'une page alors qu'elle est marquée comme non exécutable (no execute). Ceci permet de limiter l'exécution de codes malicieux[88].
Protection de la mémoire virtuelle contre un shellcode
A la suite d'un dépassement de tampon, un shellcode peut être exécuté pour prendre le contrôle d'un ordinateur. Les chercheurs de l'université de Colombus, Gu et al., proposent dans Malicious Shellcode Detection with Virtual Memory Snapshots une nouvelle méthode de détection de shellcodes malveillants. Des captures instantanées (snapshots) sont prises sur les données et permettent une analyse en temps réel des données.
L'architecture mise en place repose sur trois modules :
- Le premier module est un Analyseur de protocole qui extrait les en-têtes des messages ;
- Le deuxième module est un Analyseur de Shellcode chargé de détecter les codes malicieux ;
- Le troisième module est un environnement émulé qui fait l'interface avec l'environnement d'exécution réél[89].
Chiffrement des échanges avec la zone de Swap
Plusieurs méthodes ont été mises en avant pour renforcer les mécanismes de sécurité de la MMU. Le chiffrement de l'espace de swap est utilisé pour protéger les informations sensibles. Pour une application qui échange des mots de passe, tant que ceux-ci demeurent en mémoire physique, ils seront effacés après un redémarrage. En revanche, si le système d'exploitation commence à échanger des pages mémoire pour libérer de l'espace pour d'autres applications, les mots de passe pourront être écrits sur l'espace disque sans être cryptés. Le cryptage et le décryptage des données avec la zone d'échange de Swap peut donc être une solution[90].
Gilmont et al. proposent d'implémenter une architecture basée sur une unité de gestion de la sécurité du matériel SMU, renforçant les mécanismes de sécurité, intégrité et confidentialité, apportés par l'Unité de gestion de mémoire classique qu'est la MMU. La SMU (Security Management Unit) permet au processeur d'exécuter du code chiffré et de manipuler des données chiffrées. Sa mémoire interne non volatile (NVM) est utilisée pour stocker des clés de chiffrement et des données critiques[91] - [92].De façon à ne pas perdre en performance en chiffrant toutes les données indistinctement, Rahmattolah Amirsoufi a mis en œuvre un dispositif spécifique (ESAVM : Efficient Secure-Aware Virtual Memory) qui ne crypte et décrypte uniquement vers ou depuis la zone de swap, que les données spécifiquement confidentielles[93].
Consommation énergétique
Les différents états de la mémoire vive

La mémoire vive peut avoir 4 états[94] :
- L'état ACT : ACT est l'état de la mémoire quand elle est en cours de lecture ou d'écriture ;
- L'état PRE : PRE lorsque la mémoire est prête à être interrogée au prochain cycle d'horloge ;
- L'état PD : PD ou Power Down, quand la mémoire est désactivée ;
- L'état SR : SR est l'état de la mémoire quand celle-ci est désactivée ainsi que son PLL.
Les transitions entre état se font obligatoirement entre l'état PRE et un autre. Chaque état à une consommation énergétique qui lui est propre.
Comme chaque type de transition s'effectue par un temps mesurable, il a donc fallu réfléchir à diverses méthodes de gestion de la mémoire pour baisser la consommation énergétique de celles-ci.
L'enjeu est donc de trouver des méthodes qui ne ralentissent pas les durées de traitement tout en diminuant la consommation, sinon le gain énergétique sera nul.
Pour donner un ordre d'idée, la consommation électrique de la mémoire sur un serveur équipé de deux processeurs Intel Xeon X5667 avec 64 Go de mémoire Micron DDR2-800 est de 35 % de la consommation totale tandis que sur un smartphone Samsung Galaxy S3, elle est de 20 % en veille et 6 % téléphone actif[95].
Dans les environnements mobile
Dans les mobiles, du fait de l'alimentation sur batterie, la gestion de l'énergie est un des aspects sur lesquels travaillent le plus les constructeurs. En regardant les fiches techniques des téléphones des gammes Samsung Galaxy S ou Google Nexus, on peut constater que la quantité de mémoire a été en constante évolution depuis l'arrivée des smartphones (de 0.5 à 3 voire 4 Go en cinq ans).
D'une manière générale, pour éviter de mauvaises performances, l'utilisation du swap est désactivée sur les smartphones et un système LMK (Low Memory Killer) tue les processus qui utilisent de la mémoire[96].
Consommation en environnement virtualisé
Dans un environnement virtualisé, la mémoire est gérée par l'hyperviseur, voici différentes manières de gérer les mémoires :
- ALL (Always On) - Tous les rangs de mémoire sont à l'état PRE, et il n'y a aucune gestion de l’énergie, c'est le système standard;
- PAVM (Power-Aware Virtual Memory) - Les rangs de mémoire affectés à des machines virtuelles sont à l'état PRE, les autres rangs sont à l'état SR ; En matière de performances, le mode PAVM permet de garder les mêmes qu'en ALL, tout en réduisant dépense énergétique de 30 %
- ODSR (On Demand Self-Refresh) - Tous les rangs sont à l'état SR, et passent à l'état PRE, puis ACT seulement en cas I/O ; Le mode ODSR est inexploitable étant donné les temps d’exécution qui sont augmentés de 565 %.
- ODPD (On-Demand Power-Down) - Tous les rangs sont à l'état PD, et passent à l'état PRE, puis ACT seulement en cas I/O ; Avec le mode ODDP, les temps d'exécution sont augmentés de 5 %, mais la consommation est réduite de presque 60 %.
- DPSM (Dynamic Power State Management) - Un algorithme tente de définir le meilleur état de la mémoire ; On perd 0,6 % efficacité avec le mode DPSM, la consommation est réduite d'encore 4,4 % par apport au mode ODPD.
- OPT (Optimised mechanism) - L'état des rangs de mémoire est défini de manière optimisée et dynamique par des seuils ; Le mode OPT ne fait perdre que 0,2 % de temps d'exécution, tout ayant une consommation proche de celle de DPSM[97].
Il est à noter que la quantité de mémoire dans le serveur peut faire varier ses chiffres, plus il y aura de mémoire dans un serveur, plus la différence de consommation sera grande entre le mode standard ALL et les autres[98].
Rappels historiques
Le premier système intégrant la mémoire virtuelle est un serveur ASTRA conçu par un groupe d'Ingénieurs à Manchester en Angleterre en 1961. À la base de leur idée le concept "d'adresses", en effet, il devient évident à cette époque que l'adresse d'un process et son emplacement physique en mémoire sont deux notions à considérer de manière totalement distincte.
Dans le milieu des années 1960 l'implémentation de la mémoire virtuelle dans l'architecture de la plupart des gros systèmes est devenue très courante. On la retrouve dans des ordinateurs tels que : IBM 360/85 et CDC 7600 et Burroughs B6500. Ce qui a amené les ingénieurs à trouver une solution au problème de taille de la Mémoire Physique c'est la complexité des programmes et l'arrivée de la multiprogrammation. En effet, les développeurs qui avaient , par le passé, à gérer les problèmes d'allocation mémoire dans leurs programmes devaient désormais consacrer plus de temps à rendre leurs traitements plus performants et efficaces[99].
La gestion de la mémoire devait donc, être sous traitée au Matériel : La MMU, afin qu'elle soit effectuée de manière automatique et totalement transparente pour les utilisateurs et les développeurs.
Dans les années 1964 apparaissent les premiers systèmes Multics, Ce système révolutionnaire pour l'époque utilise le temps partagé, il est multiutilisateur et multitâches, Il est conçu avec un gestionnaire de mémoire virtuelle à segmentation.
Les systèmes Multics seront vendus jusqu'en 2000 laissant la place aux systèmes UNIX. Le système BSD (Berkeley Software Distribution) fut le premier système UNIX à utiliser la Mémoire Virtuelle Paginée en 1977 sur Machine VAX 11/780.
Perspectives
La gestion de la mémoire virtuelle est très pratique mais a ses limites. Les systèmes à grande capacité mémoire font peu ou pas de Swapping car ils hébergent des applications critiques qui ne peuvent se permettre d'attendre les I/O disque. Google, par exemple, a constaté qu'une latence de quelques secondes entraine une baisse du trafic utilisateur de 20 % due à une insatisfaction des usagers. Ce qui a conduit les grands sites comme Facebook, Google, Microsoft Bing et Twitter à garder les données d'interface utilisateur en mémoire[100].
L'accès rapide aux données en mémoire est un enjeu très important pour l'avenir.
Un groupe de chercheurs pour pallier les échecs du TLB proposent pour les Big Memory Server de translater une partie des adresses virtuelles de l'espace d'adressage avec un Segment Direct. Le segment direct est peu couteux au niveau hardware et permet de faire correspondre des zones contiguës de l'espace d'adressage virtuel avec des zones contiguës de l'espace d'adressage physique.
Sur les Big Memory Server on observe 3 Éléments Importants :
- La plupart de ces systèmes n'ont pas besoin du swapping, de la fragmentation et une protection fine comme la fournit habituellement la mémoire virtuelle. L'utilisation de la mémoire est stable ;
- Coût important en temps de la gestion de la mémoire par pages, des pertes importantes de performance sont provoquées par les échecs de TLB ;
- Ces systèmes tournent 24h/24 et 7j/7 (Ils ont peu de bénéfices à utiliser le gestionnaire de mémoire virtuelle, car c'est au démarrage du système que le gain de temps s'effectue).
De plus ils sont dimensionnés pour être en adéquation avec la mémoire physique. Ils ont un ou plusieurs processus primaires (ce sont ces processus qui sont les plus gros consommateurs de ressources mémoire).
Tous ces éléments font que le système de Gestion de la mémoire virtuelle par page n'est pas adaptée et réduit l'efficacité sur ces Gros Systèmes[100].
Big Memory Server
Sur les anciennes machines avec processeur 32 bits, la taille de page mémoire était de 4 ko. Mais les nouveaux systèmes, permettent de gérer des pages de plus grande taille, par exemple des pages de 1 Go. Les serveurs qui nécessitent de grandes quantités de mémoire RAM (Big Memory), et qui sont très gourmands en mémoire telles que les bases de données, les applications à hautes performances utilisées par exemple dans le big data peuvent utiliser des larges pages appelées encore huge pages pour Linux, large pages Windows, super page pour BSD. L'utilisation des pages de grande taille limite les échecs (TLB miss) lors de la recherche des pages en mémoire cache de la TLB. En effet, quand la taille d'une page est grande, une seule entrée du tampon TLB correspond à une grande portion de mémoire.
Dans Large Pages on Steroids: Small Ideas to Accelerate Big Memory Applications D. Jung, S. Li, J. Ho Ahnn révèlent que pour les Big Memory Serveurs la solution pour rendre la gestion de la mémoire plus performante est l'implémentation des larges pages ou bien la segmentation directe[101].
RTMMU
Bönhert et Scholl ont mis au point une nouvelle technique le RTMMU (Real Time MMU), elle combine la gestion dynamique de mémoire et la gestion de la mémoire virtuelle dans un contexte de système en temps réel. Cette approche est conçue pour des systèmes qui ont de fortes contraintes de délais. Il fournit à l'usager la flexibilité des deux, la gestion dynamique et la gestion virtuelle de la mémoire.
Cette technique est basée sur un nouveau composant du système d'exploitation et un nouveau matériel, le gestionnaire de mémoire virtuelle temps-réel : RTMMU. C'est un composant qui se situe entre la CPU et la Mémoire Centrale.
Son but est de[102] :
- s'adapter aux changements dynamiques du système ;
- d'avoir une gestion optimisée et rationnelle de la mémoire (réduire le temps d'inutilisation de la mémoire) ;
- d'implémenter la gestion de la mémoire virtuelle qui permet, la protection de la mémoire et prévient la fragmentation de la mémoire physique ;
Les résultats expérimentaux décrits dans A Dynamic Virtual Memory Management under Real-Time Constraints () démontrent la faisabilité de ce concept et confirment un temps constant en matière de gestion des opérations mémoire et une réduction de l'empreinte mémoire.
Voici les résultats obtenus à la suite des tests :
| RTMMU | Traditionnel | |||||
| Programmes | Allocation | Désallocation | Memory FootPrint | Allocation | Désallocation | Memory Footprint |
| Synthetic | 339 | 945 | 2791 | 237 | 4 145 462 | 180 132 |
| Avconv | 327 | 547 | 621 | 233 | 2 263 | 781 |
| FFT | 326 | 524 | 6 263 | 233 | 94 305 | 6 263 |
| mc | 336 | 747 | 206 | 232 | 2 899 292 | 96 035 |
| sharpSAT | 327 | 702 | 4 522 | 233 | 73 454 | 4 718 |
| PHP | 322 | 437 | 476 | 233 | 1 423 306 | 476 |
Distributed Shared Virtual Memory (DSVM)

C'est en 1986, que Kai Li (en) a publié un thèse de doctorat, Shared Virtual Memory on Loosely Coupled Microprocessors ouvrant ainsi un champ de récherche sur ce qui est convenu d'appeler le DSVM (en)[103].
Dans les systèmes distribués, les différentes mémoires physiques sont logiquement partagées sur un grand espace d'adressage (mémoire virtuelle). Ainsi, les processus en cours accèdent à la mémoire physique à travers ces espaces d'adresses logiquement partagés. Le modèle de mémoire partagée fournit un espace d'adressage virtuel partagé entre tous les nœuds. Le terme «partagé» ne signifie pas qu'il existe une seule mémoire centralisée, mais essentiellement que c'est l'espace d'adressage qui est partagé. (la même adresse physique sur deux processeurs fait référence au même emplacement en mémoire).
La performance dans les architectures distribuées avec DSVM (en) est un problème délicat, de nombreux chercheurs ont cherché à améliorer les problèmes de latence et de congestion car la DSVM utilise le réseau pour échanger des pages entre différents nœuds[104].
Différentes approches sont utilisées pour améliorer la performance de cette architecture. La méthode est basée sur la division des nœuds du système en différents groupes (clusters), chaque cluster comprend un nœud maître qui gère certaines fonctionnalités au travers d'un nouvel algorithme permettant de détecter l'état de la mémoire du système et de distribuer des pages sur tous les nœuds, effectuant ainsi une répartition de charge équilibrée[105].
Remote Memory Model
Les systèmes qui utilisent les mécanismes de la mémoire virtuelle utilisent des disques comme support de stockage.
Au lieu de connecter un disque à chaque station de travail, les systèmes distribués permettent aux clients sans disque (en),de partager une ressource de stockage sur un serveur via le réseau. Le modèle de mémoire à distance (Remote Memory Model) fournit une nouvelle base pour l'architecture des systèmes distribués.Le modèle se compose de plusieurs machines clientes, de différentes machines serveurs, d'une ou plusieurs machines dédiées appelées serveurs de mémoire à distance et d'un canal de communication interconnectant toutes les machines.Pour améliorer les performances des échanges (délai) entre les clients et le serveur de mémoire à distance, on utilise un protocole de communication Xinu Paging Protocol (XPP), et Negative Acknowledgement Fragmentation Protocol (NAFP)[106].
Ce même principe est employé dans les équipements mobiles et les systèmes embarqués possédant une connexion réseau. La spécificité pour ces matériels étant de fonctionner avec des ressources mémoires restreintes. L'implémentation de la NVM (Network Virtual Memory) offre des contraintes quant à la rapidité de liens[107].
Bibliographie
Publications historiques
- (en) Peter J. Denning, « Virtual Memory in computing Survey », ACM Computing survey, vol. 2, no 3, , p. 153-180 (ISSN 0360-0300, DOI 10.1145/356571.356573)
- (en) Peter J. Denning, « Virtual Memory », ACM Computing survey, vol. 28, no 1, , p. 213-216 (ISSN 0360-0300, DOI 10.1145/234313.234403)
- (en) Irving L. Traiger, « Virtual Memory Management for Database System », ACM SIGOPS Operating Systems Review, vol. 16, no 4, , p. 26-48 (ISSN 0163-5980, DOI 10.1145/850726.850729)
- (en) Shin-Jeh Chang et P.T. Zacharias Kapauan, « Modeling and analysis of using memory management unit to improve software reliability », IEEE Software reliability Engeneering, (ISSN 1071-9458, DOI 10.1109/ISSRE.2001.989462)
- (en) A. Bensoussan, C.T. Clingen et R.C. Daley, « The Multics Virtual Memory : Concept and Design », ACM, vol. 5, no 5, , p. 308-318 (ISSN 0001-0782, DOI 10.1145/355602.361306)
Publications relatives à la mise en œuvre de la gestion de la mémoire virtuelle
- (en) Bruce Jacob, « Virtual Memory Issues of Implementation Computing Practices », Computer, IEEE, , p. 33-43 (ISSN 0018-9162, DOI 10.1109/2.683005, lire en ligne)
- (en) Allen B. Tucker, Computer Science Handbook, Second Edition, CRC Press, , 2752 p. (ISBN 0-203-49445-8, lire en ligne)
- (en) David A Patterson et John L Hennessy, Computer organization and design : the hardware/software interface, , 914 p. (ISBN 978-0-08-088613-8, lire en ligne)
- (en) Linda Null et Julia Lobur, The Essentials of Computer Organization and Architecture, , 799 p. (ISBN 978-0-7637-3769-6, lire en ligne)
- (en) Editions ENI, L'Ordinateur portable : découverte & premier pas, Editions ENI, , 208 p. (ISBN 978-2-7460-4252-0 et 2-7460-4252-5, lire en ligne)
- (en) Scott Mueller, Le PC : Architecture, maintenance et mise à niveau, Pearson Education France, , 1223 p. (ISBN 978-2-7440-4087-0 et 2-7440-4087-8, lire en ligne)
- (en) Lei Yang, Transparent Memory Hierarchy Compression and Migration, ProQuest, (ISBN 978-0-549-89746-0 et 0-549-89746-1, lire en ligne)
- (en) William Stallings, Operating Systems : Internals and Design Principles., (ISBN 978-0-13-380591-8)
- (en) Jerome H. Saltzer et M. Frans Kaashoek, Principles of Computer System Design : An Introduction, Morgan Kaufmann, , 560 p. (ISBN 978-0-08-095942-9 et 0-08-095942-3, lire en ligne)
- Joëlle Delacroix, Linux - 4e éd. Programmation système et réseau : Cours et exercices corrigés, dunod, , 384 p. (ISBN 978-2-10-074855-6, lire en ligne)
- (en) Mohamed Rafiquzzaman, Microprocessors and Microcomputer-Based System Design, CRC Press, , 800 p. (ISBN 0-8493-4475-1, lire en ligne)
- (en) Wai-Kai Chen, Memory, Microprocessor, and ASIC, CRC Press, , 384 p. (ISBN 0-203-01023-X, lire en ligne)
- (en) Peter J. Denning, Virtual Memory, Denninginstitute, (lire en ligne)
- Alain Cazes et Joëlle Delacroix, Architecture des machines et des systèmes informatiques - 5e éd., Dunod, , 544 p. (ISBN 978-2-10-073771-0 et 2-10-073771-6, lire en ligne)
- Stéphane Gill et Mohand Atroun, Linux pour tous, Presses Université Laval, , 218 p. (ISBN 978-2-7637-8507-3 et 2-7637-8507-7, lire en ligne)
- (en) Avi Silberschatz, Peter Galvin et Greg Gagne, Operating System Concepts, (ISBN 978-1-118-06333-0, lire en ligne), p. 1 - 1

- Gérard Blanchet et Bertrand Dupouy, Architecture des ordinateurs : principes fondamentaux, Paris, Hermès science publications-Lavoisier, , 365 p. (ISBN 978-2-7462-3914-2), p. 1 - 1
- (en) M. Milenkovic, « Microprocessor memory management units », IEEE, , p. 77 (ISSN 0272-1732, DOI 10.1109/40.52948)
- (en) W. Barr, « Translation Caching: Skip, Don’t Walk (the Page Table) », Sigarch Comput. Archit. News, ACM, , p. 48 (ISSN 0163-5964, DOI 10.1145/1816038.1815970)
- (en) M. Talluri, « A new page table for 64-bit address spaces », Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles, ACM, , p. 184-200 (ISBN 0-89791-715-4, DOI 10.1145/224057.224071)
- (en) Timo O. Alanko1983 et A.Inkeri Verkamo, « Segmentation, paging and optimal page sizes in virtual memory », ELSEVIER, (ISSN 0167-7136, DOI 10.1016/0167-7136(83)90150-6)
- (en) Anton M. van Wezenbeek et Willem Jan Withagen, « A survey of memory management », Elsevier, (ISSN 0165-6074, DOI 10.1016/0165-6074(93)90254-I)
- (en) Niels Provos, Encrypting Virtual Memory, Usenix, (lire en ligne)
- (en) AMD, AMD64 Architecture Programmer’s Manual Volume 2 : System Programming, AMD, (lire en ligne)
- (en) Intel, Intel® 64 and IA-32 Architectures Software Developer’s Manual, Intel (lire en ligne)
- (en) Peter J. Denning, Virtual Memory, denninginstitute, (lire en ligne)
Publications relatives à la performance
- (en) Seunghoon Yoo, « An efficient page replacement algorithm for PCM-based mobile embedded systems », 2016 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), IEEE, , p. 183-188 (DOI 10.1109/SNPD.2016.7515898, lire en ligne)
- (en) Geunsik Lim, « Virtual memory partitioning for enhancing application performance in mobile platforms », IEEE Transactions on Consumer Electronics, IEEE, , p. 786-794 (ISSN 0098-3063, DOI 10.1109/TCE.2013.6689690, lire en ligne)
- (en) Eyad Alkassar et Ernie Cohen, « Verifying shadow page table algorithms », Software : IEEE, , p. 267 - 270 (ISBN 978-0-9835678-0-6, lire en ligne)
- (en) Liu Haikun et Liao Xiaofei, « Hotplug or Ballooning: A Comparative Study on Dynamic Memory Management Techniques for Virtual Machines », IEEE Transactions on Parallel and Distributed Systems, IEEE, , p. 1350-1363 (ISSN 1045-9219, DOI 10.1109/TPDS.2014.2320915)
- (en) M.L. Chiang, C.J. Yang et S.W. Tu, « Kernel mechanisms with dynamic task-aware scheduling to reduce resource contention in NUMA multi-core systems », Journal of Systems and Software, Elsevier, , p. 72 - 87 (ISSN 0164-1212, DOI 10.1016/j.jss.2016.08.038)
- (en) Zhang Pengfei et Chu Rui, « SwapCached: An Effective Method to Promote Guest Paging Performance on Virtualization Platform », 2013 IEEE Seventh International Symposium on Service-Oriented System Engineering, IEEE, , p. 379-384 (ISBN 978-1-4673-5659-6, DOI 10.1109/SOSE.2013.62)
- (en) Srividya et Dinakar, « Optimize In-kernel swap memory by avoiding duplicate swap out pages », 2016 International Conference on Microelectronics, Computing and Communications (MicroCom), IEEE, , p. 1-4 (DOI 10.1109/MicroCom.2016.7522551)
- (en) Apam Qasem et Josh Magee, « Improving TLB performance on current chip multiprocessor architectures through demand-driven superpaging », Software : practice and experience, , p. 705-729 (ISSN 0038-0644, DOI 10.1002/spe.2128)
- (en) Abraham Silberschatz, Peter B. Galvin et Greg Gagne, Operating System Concepts, Seventh Edition, 7th Edition, (ISBN 0-201-50480-4, lire en ligne)
- (en) Peter J. Denning, « Thrashing: its causes and prevention », Proceedings of the December 9-11, 1968, Fall Joint Computer Conference, Part I, ACM, (DOI 10.1145/1476589.1476705)
- (en) Peter J. Denning et Stuart C. Schwartz, Properties of the Working-Set Model, ACM, (DOI 10.1145/361268.361281, lire en ligne), p. 191-198
- (en) Godbole, Operating System 3E, Tata McGraw-Hill Education, , 665 p. (ISBN 978-1-259-08399-0 et 1-259-08399-3, lire en ligne)
- (en) Ganesh Chandra Deka, Handbook of Research on Securing Cloud-Based Databases with Biometric Applications, IGI Global, , 434 p. (ISBN 978-1-4666-6560-6 et 1-4666-6560-2, lire en ligne)
- (en) Teofilo Gonzalez, Jorge Diaz-Herrera et Allen Tucker, Computing Handbook, Third Edition : Computer Science and Software Engineering, CRC Press, , 2326 p. (ISBN 978-1-4398-9853-6 et 1-4398-9853-7, lire en ligne)
- (en) Apple, Memory Usage Performance Guidelines, Apple, (lire en ligne)
- (en) Jonathan Levin, No pressure, Mon! : Handling low memory conditions in iOS and Mavericks, newosxbook, (lire en ligne)
- (en) Jonathan Levin, Mac OS X and iOS Internals : To the Apple's Core, Wrox, , 828 p. (ISBN 978-1-118-05765-0, lire en ligne)
- (en) James J. Jong Hyuk Park, Yi Pan, Han-Chieh Chao et Gangman Yi, Ubiquitous Computing Application and Wireless Sensor : UCAWSN-14, Springer, , 742 p. (ISBN 978-94-017-9618-7 et 94-017-9618-1, lire en ligne)
- (en) Kan Zhong, Duo Liu, Tianzheng Wang, Xiao Zhu, Linbo Long, Weichan Liu, Shao Zili et Edwin H.-M. Sha, « Building high-performance smartphones via non-volatile memory: the swap approach », Proceedings of the 14th International Conference on Embedded Software, ACM, , p. 1-14 (ISBN 978-1-4503-3052-7, DOI 10.1145/2656045.2656049)
- (en) Mauro Conti, Matthias Schunter et Ioannis Askoxylakis, Trust and Trustworthy Computing - 8th International Conference, TRUST 2015, Heraklion, Greece, August 24-26, 2015, Proceedings, springer, , 328 p. (ISBN 978-3-319-22846-4 et 3-319-22846-3, lire en ligne)
Publications relatives au gestionnaire de mémoire dans un environnement virtualisé
- (en) Vmware, Understanding Memory Resource Management in VMware® ESX™ Server, Vmware, (lire en ligne)
- (en) Xiaolin Wang, Jiarui Zang, Zhenlin Wang et Yingwei Luo, « Revisiting memory management on virtualized environments », ACM Trans. Archit. Code Optim., ACM, , Volume 10 Numéro 4 (ISSN 1544-3566, DOI 10.1145/2541228.2555304)
- (en) Xiaolin Wang, Jiarui Zang, Zhenlin Wang, Yingwei Luo et Xiamonig Li, « Selective Hardware/Software Memory Virtualization », SIGPLAN Not., ACM, , p. 217-226 (ISSN 0362-1340, DOI 10.1145/2007477.1952710)
- (en) Jayneel Gandhi, Basu Arkaprava, Mark D. Hill et Michael M. Swift, « Efficient Memory Virtualization: Reducing Dimensionality of Nested Page Walks », 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, IEEE, , p. 1-12 (ISSN 1072-4451, DOI 10.1109/MICRO.2014.37)
Publications relatives à la sécurité
- (en) A. F. Harvey, DMA Fundamentals on Various PC Platforms, UMASS Boston, (lire en ligne)
- (en) Ole Henry Halvorsen et Douglas Clarke, OS X and iOS Kernel Programming, apress, , 484 p. (ISBN 978-1-4302-3537-8 et 1-4302-3537-3, lire en ligne)
- (en) Paul Willmann et Scott Rixner, Protection Strategies for Direct Access to Virtualized I/O Devices, Usenix, (lire en ligne)
- (en) Miroslaw Kutylowski et Jaideep Vaidya, Computer Security : ESORICS 2014, springer, , 545 p. (ISBN 978-3-319-11203-9 et 3-319-11203-1, lire en ligne)
- (en) Fernand Lone Sang, Eric Lacombe, Vincent Nicomette et Yves Deswarte, Analyse de l’efficacité fournie par une IOMMU, Symposium sur la sécurité des technologies de l'information et des communications, (lire en ligne)
- (en) Huang, « Alternate hammering test for application-specific DRAMs and an industrial case study », IEEE, , p. 1012-1017 (ISBN 978-1-4503-1199-1, lire en ligne)
- (en) Yoongu Kim, Ross Daly, Jeremie Kim, Chris Fallin, Ji Hye Lee, Donghyuk Lee, Chris Wilkerson, Konrad Lai et Onur Mutlu, « Flipping Bits in Memory without accessing them », 2014 ACM/IEEE 41st International Symposium on Computer Architecture (ISCA), IEEE, , p. 361-372 (ISSN 1063-6897, DOI 10.1109/ISCA.2014.6853210)
- (en) Amirsoufi Rahmatollah, « Efficient Security-Aware Virtual Memory Management », IEEE, , p. 208-211 (ISBN 978-1-4244-5330-6, DOI 10.1109/SoCPaR.2009.50)
- (en) Patterson, « Computer Organization and Design: The Hardware/Software Interface Revised », Elsevier, , p. 508-509 (ISBN 0080550339, lire en ligne)
- (en) Gu, Xiaole Bai, Zhimin Yang, Adam C. Champion et Dong Xuan, « Malicious Shellcode Detection with Virtual Memory Snapshots », 2010 Proceedings IEEE INFOCOM, IEEE, (ISSN 0743-166X, DOI 10.1109/INFCOM.2010.5461950, lire en ligne)
- (en) Hector Marco Gisbert et Ismael Ripol, « On the Effectiveness of NX, SSP, RenewSSP, and ASLR against Stack Buffer Overflows », 2014 IEEE 13th International Symposium on Network Computing and Applications, IEEE, , p. 145 - 152 (DOI 10.1109/NCA.2014.28)
- (en) Tanguy Gilmont, Jean-Didier Legat et Jean-Jacques Quisquater, « Architecture of security management unit for safe hosting of multiple agents », Proc. SPIE, SPIE, (DOI 10.1117/12.344697)
- (en) Tanguy Gilmont, Jean-Didier Legat et Jean-Jacques Quisquater, « Enhancing security in the memory management unit », Proceedings 25th EUROMICRO Conference. Informatics: Theory and Practice for the New Millennium, IEEE, (ISSN 1089-6503, DOI 10.1109/EURMIC.1999.794507)
- (en) « Advanced Micro Devices, Inc.; Patent Issued for Input/Output Memory Management Unit with Protection Mode for Preventing Memory Access by I/O Devices », ProQuest,
- (en) Alex Markuze, Adam Morrison et Dan Tsafrir, « True IOMMU Protection from DMA Attacks: When Copy is Faster than Zero Copy », SIGARCH Comput. Archit. News, ACM, (ISSN 0163-5964, DOI 10.1145/2954680.2872379)
- (en) Dongkyun Ahn et Gyungho Lee, « Countering code injection attacks with TLB and I/O monitoring », 2010 IEEE International Conference on Computer Design, IEEE, (ISSN 1063-6404, DOI 10.1109/ICCD.2010.5647696)
- (en) Seongwook Jin et Jaehyuk Huh, « Secure MMU: Architectural support for memory isolation among virtual machines », 2011 IEEE/IFIP 41st International Conference on Dependable Systems and Networks Workshops (DSN-W), IEEE, , p. 1-6 (ISSN 2325-6648, DOI 10.1109/DSNW.2011.5958816)
- (en) Boxuan Gu et Xiaole Bai, « Malicious Shellcode Detection with Virtual Memory Snapsh », 2010 Proceedings IEEE INFOCOM, IEEE, , p. 1 - 9 (ISSN 0743-166X, DOI 10.1109/INFCOM.2010.5461950)
- (en) Mark Seaborn et Thomas Dullien, Exploiting the DRAM rowhammer bug to gain kernel privileges, Google, (lire en ligne)
- (en) Daniel Gruss, Clémentine Maurice et Stefan Mangard, Rowhammer.js : A Remote Software-Induced Fault Attack in JavaScript, Cornell University Library, (lire en ligne)
- (en) Mark Seaborn et Thomas Dullien, Exploiting the DRAM rowhammer bug to gain kernel privileges, blackhat, (lire en ligne)
- (en) Michael Schwarz, DRAMA : Exploiting DRAM Buffers for Fun and Profit, blackhat, (lire en ligne)
- (en) Peter Pessl, Daniel Gruss, Clémentine Maurice, Michael Schwarz et Stefan Mangard, DRAMA : Exploiting DRAM Addressing for Cross-CPU Attacks, Usenix, (lire en ligne)
- (en) Ferdinand Brasser, Lucas Davi, David Gens, Christopher Liebchen et Ahmad-Reza Sadeghi, CAn't Touch This : Practical and Generic Software-only Defenses Against Rowhammer Attacks, Cornell University Library, (lire en ligne)
- (en) Bill Blunden, The Rootkit Arsenal : Escape and Evasion, Jones & Bartlett Publishers, (ISBN 978-0-7637-8284-9 et 0-7637-8284-X, lire en ligne)
- Alain Bron, Systèmes d'exploitation 2.8, Lulu.com, (ISBN 978-1-326-73267-7 et 1-326-73267-6, lire en ligne)
- (en) Jonathan Corbet, Alessandro Rubini et Greg Kroah-Hartman, Linux Device Drivers : Where the Kernel Meets the Hardware, O'Reilly, , 640 p. (ISBN 0-596-55538-5, lire en ligne)
- (en) Elias Levy, Smashing The Stack For Fun And Profit, (lire en ligne)
- (en) Aaron R. Bradley, Programming for Engineers : A Foundational Approach to Learning C and Matlab, springer, , 238 p. (ISBN 978-3-642-23303-6 et 3-642-23303-1, lire en ligne)
- Jean-François Pillou et Jean-Philippe Bay, Tout sur la sécurité informatique 4e édition, dunod, , 276 p. (ISBN 978-2-10-074609-5 et 2-10-074609-X, lire en ligne)
- Cédric Llorens, Laurent Levier, Denis Valois et Benjamin Morin, Tableaux de bord de la sécurité réseau, eyrolles, , 562 p. (ISBN 978-2-212-08415-3 et 2-212-08415-3, lire en ligne)
Publications relatives à la consommation énergétique
- (en) Benjamin Lee, « Architecting phase change memory as a scalable dram alternative », SIGARCH Comput. Archit. News, ACM, (ISSN 0163-5964, DOI 10.1145/1555815.1555758)
- (en) Moinuddin Qureshi, « Scalable high performance main memory system using phase-change memory technology », Sigarch Comput. Archit. News, ACM, (ISSN 0163-5964, DOI 10.1145/1555815.1555760)
- (en) Ping Zhou, « A durable and energy efficient main memory using phase change memory technology », Sigarch Comput. Archit. News, ACM, (ISSN 0163-5964, DOI 10.1145/1555815.1555759)
- (en) Mohammad A. Ewais et Mohamed A. Omran, « A virtual memory architecture to enhance STT-RAM performance as main memory », 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), IEEE, , p. 1 - 6 (DOI 10.1109/CCECE.2016.7726657)
- (en) Yunjoo Park et Hyokyung Bahn, « Management of Virtual Memory Systems under High Performance PCM-based Swap Devices », 2015 IEEE 39th Annual Computer Software and Applications Conference, IEEE, , p. 764 - 772 (DOI 10.1109/COMPSAC.2015.136)
- (en) Su-Kyung Yoon et Do-Heon Lee, « Designing virtual accessing adapter and non-volatile memory management for memory-disk integrated system », 2014 IEEE/ACIS 13th International Conference on Computer and Information Science (ICIS), IEEE, , p. 99 - 104 (DOI 10.1109/ICIS.2014.6912115)
- (en) Han-Lin Li, « Energy-Aware Flash Memory Management in Virtual Memory System », IEEE Transactions on Very Large Scale Integration (VLSI) Systems, IEEE, , p. 952 - 964 (ISSN 1063-8210, DOI 10.1109/TVLSI.2008.2000517)
- (en) Xiangrong Zou et Peter Petrov, « Heterogeneously tagged caches for low-power embedded systems with virtual memory support », ACM Trans. Des. Autom. Electron. Syst., ACM, (ISSN 1084-4309, DOI 10.1145/1344418.1344428)
- (en) Xiangrong Zou et Peter Petrov, « Direct address translation for virtual memory in energy-efficient embedded systems », ACM Trans. Embed. Comput. Syst., ACM, (ISSN 1539-9087, DOI 10.1145/1457246.1457251)
- (en) Xiangrong Zou et Peter Petrov, « Low-power and real-time address translation through arithmetic operations for virtual memory support in embedded systems », IET Computers Digital Techniques, IEEE, , pp.75-85 (ISSN 1751-8601, DOI 10.1049/iet-cdt:20070090)
- (en) Mickael Lanoe et Eric Senn, « Energy modeling of the virtual memory subsystem for real-time embedded systems », 2010 Conference on Design and Architectures for Signal and Image Processing (DASIP), IEEE, (DOI 10.1109/DASIP.2010.5706244)
- (en) Lei Ye, Chris Gniady et John H. Hartman, « Energy-efficient memory management in virtual machine environments », 2011 International Green Computing Conference and Workshops, IEEE, , p. 1-8 (DOI 10.1109/IGCC.2011.6008556)
- (en) Kan Zhong, Duo Liu, Liang Liang, Xiao Zhu, Linbo Long et Yi Wang, « Energy-Efficient In-Memory Paging for Smartphones », IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, IEEE, , p. 1-14 (ISSN 0278-0070, DOI 10.1109/TCAD.2015.2512904)
- (en) Aaron Carroll et Gernot Heiser, « The systems hacker's guide to the galaxy energy usage in a modern smartphone », Proceedings of the 4th Asia-Pacific Workshop on Systems, ACM, , p. 1-14 (ISBN 978-1-4503-2316-1, DOI 10.1145/2500727.2500734)
Publications relatives aux nouvelles techniques de la gestion de la mémoire
- (en) Kathryn S. McKinley, « Next Generation Virtual Memory Management », Sigplan Not., ACM, , Pages 107-107 (ISSN 0362-1340, DOI 10.1145/3007611.2892244)
- (en) Daejin Jung, Sheng Li et Jung Ho Ahn, « Large Pages on Steroids: Small Ideas to Accelerate Big Memory Applications », IEEE Computer Architecture Letters, IEEE, , p. 1 - 1 (ISSN 1556-6056, DOI 10.1109/LCA.2015.2495103)
- (en) Martin Bonhert et Cristoph Choll, « A dynamic virtual memory management under real-time constraints », 2014 IEEE 20th International Conference on Embedded and Real-Time Computing Systems and Applications, IEEE, , p. 1-10 (ISSN 2325-1271, DOI 10.1109/RTCSA.2014.6910522)
- (en) Xialoin Wang, Lingmei Weng et Zhenlin Wang, « Revisiting memory management on virtualized environments », ACM Trans. Archit. Code Optim., ACM, (ISSN 1544-3566, DOI 10.1145/2541228.2555304)
- (en) James E. Smith et Ravi Nair, « Versatile Platform for System and Processes », Elsevier, , Chapitre 8.3.1 pages 397-410 (ISBN 978-1-55860-910-5)
- (en) Liu Lei, Li Yong et Ding Chen, « Rethinking Memory Management in Modern Operating System: Horizontal, Vertical or Random? », IEEE Transactions on Computers, IEEE, , p. 1921 - 1935 (ISSN 0018-9340, DOI 10.1109/TC.2015.2462813)
- (en) Sudarsun Kannan, Ada Gavrilovska, Karsten Schwan et Dejan Milojicic, « Optimizing Checkpoints Using NVM as Virtual Memory », 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, IEEE, , p. 29-40 (ISSN 1530-2075, DOI 10.1109/IPDPS.2013.69)
- (en) Carter, « Distributed shared memory: where we are and where we should be headed », Proceedings 5th Workshop on Hot Topics in Operating Systems (HotOS-V), IEEE, (DOI 10.1109/HOTOS.1995.513466)
- (en) Gerndt, « A rule-based approach for automatic bottleneck detection in programs on shared virtual memory systems », Proceedings Second International Workshop on High-Level Parallel Programming Models and Supportive Environments, IEEE, , p. 93-101 (DOI 10.1109/HIPS.1997.582960)
- (en) Saed, « A novel approach to enhance distributed virtual memory », A novel approach to enhance distributed virtual memory, Elsevier, , p. 388-398 (ISSN 0045-7906, DOI 10.1016/j.compeleceng.2011.11.006)
- (en) Arkaprava Basu, Jayneel Gandhi, Jichuan Chang, Mark D. Hill et Michael M. Swift, « Efficient virtual memory for big memory servers », SIGARCH Comput. Archit. News, ACM, , p. 238 (ISSN 0163-5964, DOI 10.1145/2508148.2485943)
- (en) Douglas Comer, A New Design for Distributed Systems : The Remote Memory Model, University of Kentucky Laboratory for Advanced Networking, , 15 p. (lire en ligne)
- (en) Emanuele Lattanzi, Andrea Acquaviva et Alessandro Bogliolo, « Proximity services supporting network virtual memory in mobile devices », Proceedings of the 2Nd ACM International Workshop on Wireless Mobile Applications and Services on WLAN Hotspots, ACM, , p. 1 (ISBN 1-58113-877-6, DOI 10.1145/1024733.1024749)
Notes et références
- Tucker 2004, p. 85-2
- Denning 1996, p. 213
- Null 2006, p. 342
- ENI 2008, p. 24
- Mueller 2008, p. 334
- Silberschatz, p. 25
- Saltzer 2009, p. 248
- Delacroix 2016, p. 143
- Denning 1996, p. 4
- Rafiquzzaman 1995, p. 476
- Denning 2014, p. 9 - 54.6.1
- Chen 2003, p. 11-12
- Jacob, p. 35
- Cazes 2015, p. 374
- Cazes 2015, p. 370
- Gill 2007, p. 199
- Bron 2016, p. 39
- Silberschatz, p. 321
- Silberschatz 2004, p. 466
- Bron 2016, p. 38
- Denning 1970, p. 186
- Milenkovic 2002, p. 77
- Silberschatz, p. 295
- Milenkovic 2002, p. 71
- Stallings 2014
- Silberschatz 2004, p. 293
- Talluri 1995, p. 184
- Barr 2010, p. 48
- amd 2013, p. 132
- Intel 2016, p. Chapitre 4.4.1 Figure 4.8
- Jacob, p. 36
- Denning 2008, p. 7
- Denning 1996, p. 216
- Silberschatz 2004, p. 323
- Denning 1968, p. 912-922
- Denning 1972, p. 191-198
- Denning 1970, p. 180
- Denning 1970
- Godbole 2011, p. 339
- Chiang 2016, p. 72-87
- Smith 2005, p. 397-410
- Vmware 2009, p. 4
- Alkassar 2010, p. 267
- Conti 2015, p. 263
- Wang 2011, p. 217
- Memory balloon
- Haikun 2015, p. 2
- Pengfei 2013, p. 379
- Pengfei 2013, p. 379-384
- Backing store
- Apple 2013, p. 1
- Levin 2013, p. 1
- Levin 2012, p. 140
- Levin 2012, p. 546
- Park 2015, p. 144
- Geunsik 2013, p. 786,793
- Yoo 2016, p. 183
- Zhong 2014, p. 10
- Deka 2014, p. 480
- Sviridya 2016, p. 1-4
- Lee 2009, p. 2
- Qureshi 2009, p. 24
- Zhou 2009, p. 14
- Ewais 2016, p. 1
- Park 2015-2, p. 764-772
- Yoon 2014, p. 99- 104
- Li 2008, p. 952-964
- Harvey 1991, p. 1-19
- Markuze 2016, p. 249
- Outil Inception
- Halvorsen 2011, p. 198
- Willmann 2008, p. 1
- Kutylowski 2014, p. 219
- Sang 2010, p. 1-26
- Huang 2012, p. 1012-1017
- Seaborn 2015, p. 1-71
- Seaborn 2015-2, p. 1
- Gruss 2015, p. 7
- Schwarz 2016, p. 1-85
- Pessl 2016, p. 1-18
- Brasser 2016, p. 9
- Blunden 2009, p. 91
- Jacob, p. 34
- Bron 2016, p. 32
- Levy 1996, p. 1-28
- Bradley 2011, p. 12
- Pillou 2016, p. 72
- Llorens 2010, p. 445
- Gu 2010, p. 4
- Provos 2000, p. 1
- Gilmont 1999, p. 473
- Gilmont 1999-2, p. 1-8
- Rahmatollah 2009, p. 2
- Ye 2011, p. 2
- Carroll 2013, p. 3
- Zhong 2016, p. 2
- Ye 2011, p. 5
- Ye 2011, p. 8
- Denning 1970, p. 153-180
- Basu 2013, p. 238
- Jung 2015, p. 1
- Bonhert 2014, p. 93-101
- Carter 1995
- Gerndt 1997, p. 93-101
- Saed 2011, p. 388-398
- Comer 1990, p. 1-15
- Lattanzi 2004, p. 1