Dimension de Vapnik-Chervonenkis
Dans la théorie de l'apprentissage automatique, la dimension VC (pour dimension de Vapnik-Chervonenkis suivant la translittération anglaise souvent utilisée en français ou en translittération française pour dimension de Vapnik-Tchervonenkis) est une mesure de la capacité d'un algorithme de classification statistique. Elle est définie comme le cardinal du plus grand ensemble de points que l'algorithme peut pulvériser. C'est un concept central dans la théorie de Vapnik-Tchervonenkis. Il a été défini par Vladimir Vapnik et Alexeï Tchervonenkis.
Présentation
De manière informelle, la capacité d'un modèle de classification correspond à sa complexité. Par exemple, considérons comme modèle de classification la fonction de Heaviside d'un polynôme de degré élevé : si en un point donné la valeur du polynôme est positive, ce point est étiqueté positif ; sinon, il est étiqueté négatif. Un polynôme de degré assez grand peut être très sinueux et bien correspondre à un échantillon de points d'apprentissage. Mais du fait de cette sinuosité élevée, on peut penser que ce modèle de classification donnera des évaluations fausses pour d'autres points. Un tel polynôme aura une capacité élevée. Si maintenant, nous remplaçons dans ce modèle ce polynôme de degré élevé par une fonction linéaire, le modèle obtenu peut ne pas bien correspondre à l'échantillon d'apprentissage, car sa capacité est faible. Nous décrivons cette notion de capacité de manière plus rigoureuse ci-dessous.
Définition formelle
Pour des ensembles
On se place dans un ensemble U[1]. Soit H une famille (finie) de sous-ensembles (finis) de U, et C un sous-ensemble de U.
La trace de H sur le sous ensemble C de U est :

On dit que H pulvérise C si la trace de H sur C est égale à l'ensemble des parties de C, i.e:
ou de manière équivalente avec l'égalité des cardinaux .


La dimension VC de H est alors le cardinal de l'ensemble C le plus grand qui peut être pulvérisé par H.
En apprentissage
On dit qu'un modèle de classification , prenant comme paramètre un vecteur θ, pulvérise un ensemble de données () si, pour tout étiquetage de cet ensemble de données, il existe un θ tel que le modèle ne fasse aucune erreur dans l'évaluation de cet ensemble de données.


On appellera alors dimension VC d'un modèle le cardinal du plus grand ensemble pulvérisé par .
En notant la dimension VC du modèle , on a donc :


Exemple
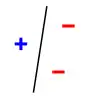
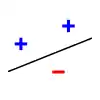
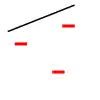
Par exemple, prenons comme modèle de classification une droite. On étudie si la ligne peut séparer les données positives (+) des données négatives (-). Si on prend 3 points non alignés, la ligne peut les pulvériser. Cependant, la ligne ne peut pas pulvériser 4 points. Ainsi, la dimension VC de la droite est de 3. Il est important de se rappeler qu'on peut choisir les positions des points qu'on va pulvériser avec la droite, mais qu'on ne peut pas ensuite modifier ces positions lorsqu'on permute leur étiquetage. Ci-dessous, pour la pulvérisation de 3 points, on montre seulement 3 des 8 étiquetages possibles (1 seule possibilité de les étiqueter tous les 3 positifs, 3 possibilités d'en étiqueter 2 sur 3 positifs, 3 possibilités d'en étiqueter 1 sur 3 positif, 1 possibilité de n'en étiqueter aucun positif).
 |
 |
 |
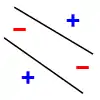 |
| Pulvérisation de 3 points | Lorsqu'il y a 4 points, la pulvérisation est impossible | ||
Applications
La dimension VC est utilisée en théorie de l'apprentissage automatique pour calculer la valeur de la marge d'erreur probable maximum d'un test de modèle de classification. Pour le test d'un modèle de classification sur des données extraites de l'échantillon d'apprentissage de manière indépendante et identiquement distribuée, cette valeur est calculée d'après la formule suivante :
Erreur d'apprentissage +

avec la probabilité de , où est la dimension VC du modèle de classification, et la taille de l'échantillon d'apprentissage. Cette formule n'est valide que lorsque .




Articles connexes
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « VC dimension » (voir la liste des auteurs).
- Olivier Gascu, LA DIMENSION DE VAPNIK-CHERVONENKIS Application aux réseaux de neurones, p. 252
Voir aussi
- [PDF] Cours sur la théorie de l’apprentissage statistique (selon V. Vapnik) de François Denis, de l'Équipe Bases de Données et Apprentissage du Laboratoire d’Informatique Fondamentale de Marseille
- (en) cours sur la dimension VC de Andrew Moore
- (en) V. Vapnik et A. Chervonenkis. On the uniform convergence of relative frequencies of events to their probabilities. (De la convergence uniforme des fréquences relatives des événements vers leur probabilité) Theory of Probability and Its Applications (Théorie de la probabilité et ses applications), 16(2):264--280, 1971.
- (en) A. Blumer, A. Ehrenfeucht, D. Haussler, et M. K. Warmuth. Learnability and the Vapnik-Chervonenkis dimension. (Capacité d'apprentissage et dimension de Vapnik-Chervonenkis) Journal of the ACM, 36(4):929--865, 1989.