Text Encoding Initiative
La Text Encoding Initiative (abrégé en TEI, en français « initiative pour l’encodage du texte ») est un format de balisage et une communauté académique internationale dans le champ des humanités numériques visant à définir des recommandations pour l’encodage de ressources numériques, et plus particulièrement de documents textuels. Depuis 1987, le modèle théorique s’est adapté à différentes technologies, d’abord sous la forme d’une DTD SGML, puis XML. Dans sa version P5 (2007), le schéma TEI est représenté dans plusieurs langages, et notamment, Relax NG. Le schéma TEI est un noyau autour duquel gravitent beaucoup d’activités coordonnées sous forme de comités démocratiques et internationaux pour, notamment, conduire la maintenance et la croissance du schéma, rédiger la documentation, développer des outils génériques, assurer le support sur des listes de diffusions et faire connaître le format.
Text Encoding Initiative
| Extension |
.tei |
|---|---|
| Développé par | |
| Version initiale |
1987 |
| Type de format | |
| Basé sur | |
| Norme | |
| Site web |
Objectifs
Selon l'un de ses fondateurs, Lou Burnard, le but de la TEI est de « fournir des recommandations pour la création et la gestion sous forme numérique de tout type de données créées et utilisées par les chercheurs en Sciences humaines et sociales[1] ».
Les trois principales raisons d'utiliser la TEI sont selon lui les suivantes :
- « XML-TEI s'intéresse au sens du texte plutôt qu'à son apparence ».
- « XML-TEI est indépendant de tout environnement logiciel particulier ».
- « XML-TEI a été conçu par la communauté scientifique qui est aussi en charge de son développement continu ».
Origine : les « principes de Poughkeepsie »
Le projet TEI a commencé le aux environs de New York, à Poughkeepsie. Une conférence organisée avec un cofinancement de l’agence fédérale américaine pour la dotation des humanités (National Endowment for the Humanities)[2] et de l’Union européenne a résulté en un texte définissant ses objectifs. Bien avant la fondation du W3C, un groupe se proposait de définir des recommandations pour l’encodage des textes informatiques. Après plus de trente ans, ces principes restent d’actualité pour décrire l’intention de la TEI, tant dans ses documents et son code, que son organisation. Le plus simple est de proposer une traduction de ces principes pour comprendre de quoi il s’agit[3].
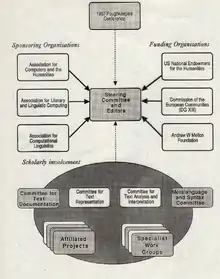
Les recommandations visent à fournir un format standard pour favoriser l’échange de textes dans les humanités et à suggérer des principes abstraits pour l’encodage des textes. Elles doivent définir une syntaxe recommandée pour ce format, définir un métalangage pour la description des structures d’encodage de textes, puis décrire ce format et ces structures, à la fois dans ce métalangage et en langage naturel. Les recommandations doivent également proposer des ensembles de conventions d’encodage adaptés à plusieurs applications différentes. Notamment, il faut qu'elles incluent un ensemble minimal de conventions pour l’encodage de nouveaux textes. Les recommandations seront rédigées par plusieurs commissions coordonnées par un comité d’organisation représentant les principaux organismes impliqués (financièrement ou pas). On distinguera la documentation (métadonnées) des textes (Committee for Text Documentation), la représentation des composants textuels (Committee for Text Representation), l’analyse et l’interprétation du texte (Committee for Text Analysis and Interpretation) et la définition du métalangage, ainsi que la description de structures textuelles proposées ou existantes (Metalanguage and Syntax Committee). La compatibilité avec des standards existants sera maintenue le plus longtemps possible. Plusieurs grandes bibliothèques de textes sont d’accord sur le principe de soutenir les recommandations de la TEI dans leur fonction de format d’échange, encourageant tous les commanditaires à soutenir le développement d’outils pour faciliter cet échange. La conversion de textes numériques existants vers ce nouveau format implique la traduction de leurs conventions dans la syntaxe du nouveau format. Aucune information supplémentaire n'est exigée pour la conversion dans ce nouveau format.
La TEI est donc une organisation qui se réunit pour définir un format d’encodage. Dès l’origine sont distingués la représentation des composants textuels, qui ne dépend pas d’un ou plusieurs chercheurs et peut valoir pour une communauté large sur le long terme, et l’interprétation propre à une expérience, un projet de recherche, une école, ou une discipline. Cette information s’est jusqu’ici inscrite sous forme de balises, dans un schéma XML (ou SGML) ; mais elle est aussi réfléchie comme des principes abstraits, indépendants de toutes technologies, afin de faciliter l’importation en provenance d’autres formats, ainsi que le transcodage dans les formats futurs.
Historique (schéma et organisation)
- 1988-1990 : TEI Proposal 1 (TEI P1), Guidelines for the Encoding and Interchange of Machine-Readable Texts, dir. Michael Sperberg-McQueen et Lou Burnard
- 1990-1992 : TEI P2, phase d’expansion
- 1993-1994 : TEI P3, considérée comme la première version complète.
- 1995-1999 : promotion et valorisation non financée.
- 2000 : naissance du TEI Consortium.
- 2001-2007 : TEI P4, introduction de XML (maintien de SGML).
- 2007-… : TEI P5 sur sourceforge[4] (abandon de SGML).

La TEI a été initiée en 1987 par trois sociétés savantes, l'Association for Computers and the Humanities[5], l'Association for Computational Linguistics[6] et l'Association for Literary and Linguistic Computing[7].
À l'heure actuelle, le « TEI Consortium » est une institution sans but lucratif financée par ses 64 membres [8], parmi lesquels on compte : le Research Technologies Service[9] à l'université d'Oxford (Royaume-Uni) ; le Scholarly Technology Group[10] à l'université Brown (États-Unis) ; un groupe francophone de recherche, à Nancy, composé de l'ATILF, de l'INIST, et du LORIA ; l'Electronic Text Center[11] et l'Institute for Advanced Technology in the Humanities[12] à l'université de Virginie (États-Unis) ; OpenEdition (France).
Le consortium s’organise en différentes instances[13]. La TEI Board of Directors[14] (conseil d’administration) décide de la direction stratégique et de la gestion financière. La TEI Technical Council[15] (conseil technique) maintient et développe les recommandations ainsi que les systèmes TEI. Les TEI Workgroups[16] (groupes de travail) sont des groupes spécialisés conduits par le conseil technique qui doivent faire des propositions concrètes pour les recommandations (ex : bibliographie, encodage de caractères…). Finalement, les TEI Special Interest Groups[17] (groupes d’intérêt spécifique) sont des groupes qui travaillent autour d’un sujet en lien avec la TEI mais pas nécessairement destiné à alimenter les recommandations (ex : outils, correspondances, enseignement…).
Exemple introductif
Pour illustrer la philosophie de la TEI, voici comment pourrait être codé un extrait du Cid de Pierre Corneille[18].
On cherche à représenter :
|
Avec le langage HTML, on aurait une codification limitée aux aspects « mise en page ».
<h1>Acte II, Scène 2</h1>
<br /> <b>DON RODRIGUE</b> À moi Comte, deux mots.
<br /> <b>LE COMTE</b> ... Parle
Avec le schéma TEI, on obtiendrait ceci :
<div type="act" n="II" xml:id="II"><head>Acte II</head>
<div type="scene" n="2" xml:id="II2"><head>Scène 2</head>
<sp><speaker>Rodrigue</speaker>
<l part="I">À moi, comte, deux mots.</l></sp>
<sp><speaker>Comte</speaker>
<l part="M">Parle</l></sp>
<sp><speaker>Rodrique</speaker>
<l part="F">Ôte-moi d'un doute</l></sp>
<sp><speaker>Comte</speaker>
<l part="I">Connais-tu bien Don Diègue ?</l></sp>
<sp><speaker>Comte</speaker>
<l part="M">Oui</l></sp>
<sp><speaker>Rodrigue</speaker>
<l part="F">Parlons bas, écoute.</l>
<l>Sais-tu que ce vieillard fut la même vertu,</l>
<l>La vaillance et l'honneur de son temps ? Le sais-tu ?</l></sp>
...
</div>
...
</div>
La TEI permet de décrire la structuration du texte tel qu'il a été conçu et non son rendu final (présentation). En fait, « les conventions élaborées dans le cadre du TEI visent à permettre la description de la manière dont un document a été créé ainsi que la façon dont il a été structuré : pages, paragraphes, lignes, chapitres, dialogues, soulignements, ajouts marginaux, ratures, etc. »[19].
Cet exemple montre notamment l'imbrication des actes et des paragraphes : deux éléments <div> imbriqués (avec un langage comme XPath, il est alors possible d'extraire un acte ou une scène), le découpage du dialogue par des éléments <sp>, la définition des interlocuteurs par des éléments <speaker> (il est possible facilement de lancer des requêtes pour localiser les endroits où Rodrigue cite Chimène) ainsi que la précision de la description de la versification par des éléments <l> (ligne) avec des indications sur la position d'un élément de dialogue en début, fin ou milieu de vers grâce aux attributs part.
Notion de balisages
Structure globale
<teiHeader>: métadonnées du fichier<text>: texte transcrit<front>: pièces pré-liminaires (privilège, dédicace, table des matières...) + page de titre <titlePage><body>: corps du texte<back>: pièces post-liminaires (privilège, index, errata...)
Structure des métadonnées
<titleStmt>(title statement) : ensemble des informations sur le titre du document numérique et ceux qui l’ont créé.<title>: titre du document numérique<author>: auteur du document numérique (si document natif)<editor>: responsabilité secondaire du document numérique (si document natif)<respStmt>: responsabilité intellectuelle (= collaborateurs sur le fichier numérique, ex. le transcripteur, l’encodeur etc.) <name> : nom de la personne concernée<resp>: fonction<date>: date
Comparaison avec d’autres schémas
La TEI n’est pas le seul langage de balisage de document. Sa naissance doit beaucoup à la normalisation officielle de SGML ISO 8879:1986 qui posait déjà les principes fondamentaux qui inspirent TEI. En effet, une application SGML doit distinguer strictement un schéma (DTD), une feuille de style isolant les informations de présentation, et des documents purement sémantiques, balisés selon ce schéma.
Vers la même époque sont apparues d’autres applications SGML dont certaines existent encore, DocBook (1991), EAD (1993), ou HTML (1993). Ces trois exemples permettront de mieux situer TEI par comparaison avec d’autres milieux et besoins s’emparant de la même norme SGML. Docbook, EAD et HTML permettent de bien situer la différence de TEI parce que beaucoup de membres de la communauté connaissent très bien ces autres schémas et se situent relativement à eux. S’intéressant d’abord à l’encodage des textes du patrimoine, ce schéma concerne surtout les milieux académiques, les institutions de conservation (bibliothèques, archives), et parfois un peu, les maisons d’édition.
Docbook
Dès sa naissance, Docbook s’est concentré sur la documentation technique, et plus particulièrement, informatique. En associant le développement logiciel UNIX (commercial et libre) avec un éditeur de livres informatique O'Reilly, le schéma s’est donné d’emblée plusieurs destinations à satisfaire automatiquement à partir d’un même document balisé : impression papier, man page (manuel UNIX pour la console), puis HTML. La communauté est organisée comme un projet logiciel libre, avec un comité qui se réunit régulièrement pour présider à la croissance ordonnée du schéma selon les propositions des utilisateurs.
Ce schéma est de taille comparable à TEI (v5, ~400 éléments), mais plus limité car plus précis dans ses objectifs. Docbook distingue par exemple explicitement les éléments <book>, <chapter>, <preface>, <article>, <section>… tandis que TEI a essentiellement un seul élément structurant à ce niveau <div>, qui peut être précisé par un attribut @type. La TEI ne suggère pas une liste de valeurs pour qualifier les types de divisions[20], si bien qu’une application TEI ne sait pas a priori comment traiter les divisions, ne serait-ce que pour en extraire une table des matières qui s’arrête au niveau des chapitres. Il faut cependant comprendre que DocBook se destine principalement à la production de nouveau documents, que le schéma peut être normatif, et imposer une définition limitée des composants d’un livre. La TEI permet de produire des documents nouveaux, mais sa mission première est l’encodage pérenne des textes du patrimoine. Or, un manuscrit, une correspondance, une pièce de théâtre, beaucoup de types de documents ne se structurent pas selon les notions de chapitres et de sections. Si tous les composants textuels de la tradition avaient produit un élément comme dans Docbook, le schéma risquait une inflation incontrôlable, avec des casse-têtes indécidables (ex : si une lettre est un chapitre structurant dans une correspondance, peut-on choisir le même élément pour une lettre citée dans un roman structuré en chapitres ?).
L’attention que la TEI porte au texte lui complique lourdement la tâche d’exploitation des documents. Le simple développement de feuilles de style ne donne pas des résultats satisfaisants pour toute la variété des documents possibles. Docbook, grâce à la restriction de ses objectifs, est un modèle de déploiement applicatif d’un schéma (ex : la plupart des distributions linux ont un paquet pour le schéma Docbook et les transformations XSLT).
EAD
Comme la TEI, l’EAD (Encoded Archival Description : description archivistique encodée) concerne les documents patrimoniaux ; mais il s’agit d’un schéma métier, restreint dans son approche et sa vision du document. C’est d’abord la transposition XML de la Norme générale et internationale de description archivistique, l’ISAD(G). L’EAD encode principalement des inventaires de fonds d’archives, mais elle dispose d’assez d’éléments et d’attributs pour transcrire le texte des documents.
EAD a beaucoup emprunté à la TEI <eadheader> : <fildesc>, <titlestmt>, <publicationstmt>, <profiledesc>, <creation>, <langusage> …, elle pourrait aussi lui apporter plus, par exemple par son appareil d’indexation des entités nommées (personnes, lieux, dates…). Si les deux schémas peuvent partager certains objets et éléments, les différences permettent de mieux qualifier la TEI. L’EAD ne comporte pas plus de 150 éléments car elle doit être intégralement comprise par les archivistes qui l’emploient. Même si l’EAD a une origine universitaire (1993, Berkeley), elle a ensuite été reprise par la société des archivistes américains, soutenue par la Bibliothèque du Congrès.
Elle est très stable dans le temps : la version 1 date de 1998 (SGML), la version 2 date de 2002 et consiste surtout à transposer la version 1 en XML, la troisième version a été publiée en 2016. L’EAD pourrait représenter une sorte d’idéal d’interopérabilité pour les documents XML patrimoniaux, mais ce résultat s’obtient par une grande limitation.
HTML
HTML s’affiche comme une application SGML[21], souhaitant respecter les principes de séparation entre sémantique et présentation, avec une centaine d’éléments. Cependant les éléments sémantiques <abbr> abréviation, <dfn> définition, <samp> exemple se mélangent souvent avec l’apparence <i> italic italique, <b> bold gras, <s> strike barré, <u> underline souligné, <body bgcolor="blue">, <table border="1">. Cette confusion était nécessaire parce qu’au commencement des navigateurs, il n’y avait pas de langage adapté à la définition de feuilles de style pour l’écran, ce que devinrent les CSS. Pour qu’un sous-ensemble de la TEI puisse être le format de l’Internet, il aurait fallu plus de liens avec l’industrie, que l’équilibre de son consensus puisse accepter des éléments comme <i>, <b>, <s>, <u>, conformément à un des principes de Poughkeepsie « les recommandations doivent inclure un ensemble minimal de conventions pour l’encodage de nouveaux textes ». Notons que Docbook n’a pas non plus été repris par le W3C, mais que depuis 2014, HTML5 reprend quelques leçons sémantiques de ces schémas en introduisant les éléments <article>, <section>, <header>, <footer>.
Pensée modulaire du schéma
Les 582 éléments de la TEI (en 2020) constituent un dictionnaire très important, avec une combinatoire potentiellement imprévisible. Cette complexité serait difficile à maîtriser dans sa totalité, tant par les utilisateurs que les développeurs, s’il n’y avait pas des regroupements et de la hiérarchie.
Comme n’importe quel langage de programmation, les syntaxes de schéma permettent de factoriser des déclarations répétitives. Soit par exemple la structure de contenu d’un paragraphe, il peut enchâsser du texte et des balises diverses : italique, noms de personnes, apparat critique… Un item de liste, une note de bas de page, ou une citation, bien d’autres éléments textuels peuvent partager une structure de contenu similaire à un paragraphe. Il ne serait pas rationnel de répéter la même déclaration pour chaque conteneur de niveau paragraphe, d’autant que cela compliquerait la maintenance du schéma (si par exemple un élément est introduit, il faudrait l’ajouter dans tous les lieux où il peut être pertinent). Dès SGML, les DTDs proposèrent le mécanisme des entités paramètres, sur le modèle des macros. Un langage de schéma XML permet donc de définir des raccourcis pour remplacer une déclaration plus importante.
Ainsi par exemple, la TEI a une macro.paraContent[22] qui définit le contenu de 52 éléments différents. Modulariser un gros schéma n’est pas spécifique à TEI, EAD a une macro para.content[23], HTML parle de flow content[24] et Docbook stipule que les paragraphes, comme les citations ou les titres, contiennent tous les éléments de niveaux caractère (inline). Par ailleurs, comme une macro peut contenir une macro, récursivement, un schéma peut devenir une véritable ontologie de l’objet qu’elle modélise. Ce qui est original à TEI, c’est de montrer ces macros dans la documentation, parce qu’elles ne sont pas seulement des commodités de développeurs, mais une tentative scientifique pour décrire tous les textes possibles.
Cet idéal d’organisation est cependant pondéré par l’effet social des groupes de travail à l’origine de la documentation. Selon les principes de “Poughkeepsie”, le schéma TEI se veut aussi bien décrit pour les machines que pour les humains. L’édifice s’est donc constitué en croisant l’effet de deux logiques appliquées aux textes : l’intelligence, concevant le plan général, et l’informatique, validant les détails. Il en résulte une structuration de la documentation qui apparait dès 1992, dans la table des matières de la TEI P2. L’ordre et l’organisation de ces chapitres a varié en une vingtaine d’années, mais pas les titres, que l’on retrouve presque à l’identique en 2015[25]. Chaque chapitre de prose documente un module du schéma presque indépendant, si bien que la TEI n’est pas un schéma, mais une bibliothèque de schémas librement combinables. Le consortium propose même un formulaire en ligne, Roma[26], pour que chacun puisse se construire son propre profil TEI, adapté à son corpus.
Par exemple, le noyau de balises Core Tags and General Rules comprend l’entête TEI ou la page de titre électronique (TEI Header) et les balises communes à tous les schémas (Tags Available in All TEI DTDs). Les balises spécifiques de description des textes Base Tag Sets comprend le Base Tag Set for Prose (prose), le Base Tag Set for Verse (poésie), le Base Tag Set for Drama (théâtre), le Base Tag Set for Transcriptions of Spoken Texts (oral), le Base Tag Set for Printed Dictionaries (dictionnaires), etc. Enfin, les autres balises Additional Tag Sets comprennent des outils d'interprétation de liens, de segmentation et d'alignement (Segmentation and Alignment), des degrés de confiance du balisage interprétatif (Certainty), de manuscrits (Manuscripts, Analytic Bibliography, and Physical Description of the Source Text), des entités nommées (Additional Tags for Names and Dates), des graphes (Graphs, Digraphs, and Trees), des figures comme les tables, formules, images, partitions, etc. (Graphics, Figures, and Illustrations ; Formulae and Tables) et des corpus linguistiques (Additional Tag Set for Language Corpora). Ces autres balises comprennent également des outils d'analyse linguistique des phrases, propositions, syntagmes, mots, etc. (Simple Analytic Mechanisms), des appareils pour d'autres analyses possibles comme la phonétique, la sémantique, les personnes, etc. (Feature Structure Analysis), ainsi que des apparats critiques (Text Criticism and Apparatus).
Pertinence de la modularité
Cette apparente liberté modulaire bute cependant sur la pertinence des divisions imposées. Depuis la TEI P4[27] (2001), la table des matières ne hiérarchise plus les chapitres, ce qui masque l’articulation de ces différents groupes de balises. On retrouve pourtant l’intention initiale de distinguer profondément ce qui relève de la description des textes, et de leur interprétation. Cette distinction reste hautement pertinente et toujours à rappeler, même s’il y a nécessairement de l’imprécision sur les franges.
Lorsque l’on entre dans le détail, les chapitres ne sont pas également heureux. Le chapitre sur les dictionnaires par exemple, signé par Nancy Ide (en) et Jean Véronis, est d’une qualité de modélisation toujours actuelle. Par contre, la distinction traditionnelle entre vers et prose bute frontalement sur la réalité des textes. Le théâtre classique est notoirement en vers ou en prose. Le roman semble par exemple un genre typique de la prose, pourtant Alice au pays des merveilles ou Le livre de le Jungle contiennent des chansons et donc des vers. Un roman français, par exemple Balzac, citera des lettres ou des affiches publicitaires. La critique littéraire peut citer du théâtre ou de la poésie. Lorsqu’on en vient à chercher les éléments les plus pertinents pour décrire un texte, il est nécessaire de piocher des exemples et des idées dans tous les chapitres. Les divisions de l’ontologie TEI ne fonctionnent pas vraiment. Cet ordre a été utile à la production de la documentation et reste assez logique comme plan d’exposition, mais il est à la fois trop contraignant, et pas assez, dès que l’on se met en contact avec les textes.
Les appareillages proposés pour l’interprétation sont très inégaux. Le chapitre sur les graphes, par exemple, semble désormais obsolète depuis la généralisation de RDF-OWL, largement plus employé, avec un grand support logiciel. En 1990, on pouvait comprendre que la TEI doive contenir tous les types d’outils de balisage. Depuis la spécification sur les espaces de noms XML (1999), il semble beaucoup plus pertinent d’insérer un langage spécialisé comme OWL dans du TEI.
L’universalité actuelle de HTML pourrait même suggérer d’en faire le noyau de la TEI, afin qu’elle se concentre sur son apport académique, plutôt que de répéter par exemple un même appareillage pour les tables, qui ne diffère de HTML que par les noms.
Cette science académique du texte informatisé mérite pourtant de devenir le standard de la révolution du livre électronique en cours dans l’édition, afin d’envisager l’encodage des textes à la source, dès la production.
Depuis 2015, une standardisation de la TEI se met en place dans l’édition académique, notamment en France via le développement de la chaîne d'édition multi-support Métopes[28], à l'initiative du pôle Document numérique[29] de la Maison de la recherche en sciences humaines de l'Université de Caen et via le logiciel d'édition numérique Lodel développé depuis 2010 par l'infrastructure OpenEdition Center[30] (USR 2004, anciennement Centre pour l'édition électronique ouverte, CLEO). La TEI intéresse aussi des maisons d’édition privées, par exemple la Librairie Droz, confrontée comme bien d’autres à la diffusion multi-support, tant papier que livre électronique, ou bien de bases de textes en ligne.
Le vocabulaire TEI se diffuse, et avec lui un désir de pérennité, pour que les textes qui s’encodent actuellement soient compris par les générations suivantes.
Notes et références
- Lou Burnard, « Introduction », dans Qu’est-ce que la Text Encoding Initiative ?, OpenEdition Press, coll. « Encyclopédie numérique », (ISBN 978-2-8218-5581-6, lire en ligne)
- (en) « Home », sur National Endowment for the Humanities (NEH) (consulté le )
- The Poughkeepsie Principles
- « Text Encoding Initiative », sur SourceForge (consulté le ).
- (en) « The Association for Computers and the Humanities | », sur ach.org (consulté le )
- (en) « ACL Member Portal | The Association for Computational Linguistics Member Portal », sur www.aclweb.org (consulté le )
- (en) « EADH - The European Association for Digital Humanities | », sur www.allc.org (consulté le )
- Information du 1 août 2013. Source : http://members.tei-c.org/Institutions
- (en) « Research support », sur www.oucs.ox.ac.uk (consulté le )
- (en-US) « Center for Digital Scholarship », sur www.stg.brown.edu (consulté le )
- (en) « About The Etext Center | University of Virginia Library Digital Production Group », sur dcs.library.virginia.edu (consulté le )
- « The Institute for Advanced Technology in the Humanities », sur www.iath.virginia.edu (consulté le )
- Activities - Text Encoding Initiative
- Board of Directors - Text Encoding Initiative
- http://www.tei-c.org/Activities/Council/index.xml
- (en) « Workgroups – TEI : Text Encoding Initiative », sur tei-c.org (consulté le ).
- http://www.tei-c.org/Activities/SIG/index.xml
- Exemple issu de Jacques Ducloy, « L'édition scientifique en numérique - illustrée avec Hamlet et Le Cid en TEI », sur le site du projet Appropriation par la recherche des technologies de l'IST (ARTIST), 3 février 2006.
- Grégory Fabre et Sophie Marcotte, Pratiques de l'édition numériques, Montréal, Presses de l'Université de Montréal, , 219 p. (ISBN 978-2-7606-3203-5, lire en ligne), chap. 10 (« L'organisation des métadonnées »), p. 175
- (en) « TEI element div (text division) », sur tei-c.org (consulté le ).
- « HTML 3.2 Reference Specification », sur w3.org (consulté le ).
- (en) « TEI macro macro.paraContent (paragraph content) », sur tei-c.org (consulté le ).
- http://obvil-dev.paris-sorbonne.fr/developpements/eadfr/def_m.para.content.html?nav
- « HTML Standard », sur w3.org (consulté le ).
- (en) « The TEI Guidelines », sur tei-c.org (consulté le ).
- « Roma : generating customizations for the TEI », sur tei-c.org (consulté le ).
- http://www.tei-c.org/Vault/P4/doc/html/
- « MÉTOPES Méthodes et outils pour l’édition structurée | Maison de la Recherche en Sciences Humaines », sur www.unicaen.fr (consulté le )
- « Accueil | Maison de la Recherche en Sciences Humaines », sur www.unicaen.fr (consulté le )
- « Présentation d'OpenEdition », sur www.openedition.org (consulté le )
Voir aussi
Articles connexes
Bibliographie
- Nancy M. Ide, C. Michael Sperberg-McQueen, « The Text Encoding Initiative: Its History, Goals, and Future Development », dans Computers and the Humanities. Edited by Nancy M. Ide and Jean Véronis, 1995.
- Elli Mylonas, Allen Renear, « The Text Encoding Initiative at 10: Not Just An Interchange Format Anymore – but a New Research Community », Computers and the Humanities 33, no 1-2, 1999 : (doi:10.1023/A:1001832310939).
- Christian Wittern, Arianna Ciula, Conal Tuohy, « The Making of TEI P5 », Literary and Linguistic Computing, 24, no. 3, 2009, p. 281-296.
- Lou Burnard, Qu’est-ce que la Text Encoding Initiative ?, Marseille, OpenEdition Press, 2015 (ISBN 9782821855816), DOI 10.4000/books.oep.1237
Liens externes
- (fr) Version française des Recommandations P5 de la TEI
- (fr) Liste de diffusion TEI-FR
- (en) Site web du consortium TEI
- (en) Wiki du consortium TEI
- (en) Recommandations TEI
- (en) Entrepôt GitHub du consortium TEI
- (en) Journal of the Text Encoding Initiative
- (fr) La TEI Lite : encoder pour échanger : une introduction à la TEI. Édition finale révisée pour la TEI P5, introduction à la TEI par Lou Burnard et C. M. Sperberg-McQueen, traduction française de Sophie David, Paris,
- (fr) Qu'est-ce que la TEI?, traduction d'un livre de Lou Burnard voulant introduire les débutants aux bases de la TEI