Systèmes de questions-réponses
Un système de questions-réponses (question answering system en anglais, ou QA system) est un système informatique permettant de répondre automatiquement à des questions posées par des humains, lors d'un échange fait en langue naturelle (comme le français). La discipline liée appartient aux domaines du traitement automatique de la langue et de la recherche d'information. Elle se démarque de l'interrogation de moteurs de recherche en cela qu'elle vise non seulement à récupérer les documents pertinents d'une collection de textes, mais également à formuler une réponse très ciblée à la question posée.
Généralités
Un outil de questions-réponses cherche à répondre à des requêtes, ou questions, telles « Quelle est la langue la plus parlée en Europe ? » ou « Quand est mort Louis XIV ? ». Le système utilise alors des techniques de traitement automatique des langues afin d'analyser la question et de rechercher une réponse adéquate à l'aide des documents auxquels il a accès.
En proposant une suite de documents classés selon l'estimation de leur intérêt, la méthode des moteurs de recherches « classiques » force l'utilisateur à faire lui-même un post-tri des documents pertinents, beaucoup des pages proposées ne répondant pas à la question, étant parfois incohérentes, réparties sur différentes pages, etc. Dans le cas d'un système de réponse aux questions, on cherchera en général à construire une réponse en langage naturel et non pas à proposer à l'utilisateur une liste parfois longue de documents.
Le système START (en anglais) peut être donné comme exemple de système de réponse aux questions en ligne[1].
Les systèmes de réponse aux questions ont donc 3 buts principaux :
- Comprendre les questions en langue naturelle
- Analyser la question, quel est son type ?
- Quelle est son domaine ? On parlera de question fermée pour une question se portant sur un domaine spécifique (médecine, informatique...), et de question ouverte pouvant porter sur n'importe quoi et pour lesquelles on pourra vouloir faire appel à des systèmes d'ontologies généraux et des connaissances sur le monde.
- Trouver les informations
- Soit au sein de base de données structurée (base de données spécialisées), soit au sein de textes hétérogènes (recherche sur internet)
- Répondre à la question
- Que ce soit par une réponse exacte, ou par la proposition de passages susceptibles de contenir la réponse.
Ils font pour cela appel à des stratégies issues de plusieurs domaines différents :
- la recherche d'information (reformulation des requêtes, analyse de documents, mesure de pertinence)
- le traitement automatique du langage naturel (analyse de l'adéquation de la question avec les documents, extraction d'informations, génération de langue pour former la réponse, analyse du discours)
- l'interaction homme-machine (modèles d'utilisateurs, présentation des réponses, interactions)
- l'intelligence artificielle (mécanismes inférentiels, représentation des connaissances, logique).
Fonctionnement des systèmes de réponse aux questions
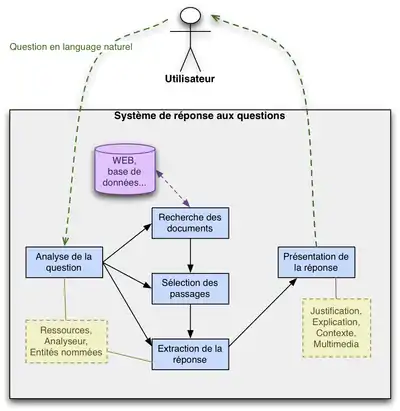
On distingue quatre étapes différentes menant à la réponse à une question dans un système de réponses aux questions : analyse de la question, recherche de documents, sélection des passages, extraction des réponses.
Analyse des questions
Dans une question, un certain nombre d'éléments sont à identifier avant de pouvoir être traités.
Le type de la question
Le type de la question est une catégorisation qui sera utilisée afin de sélectionner la stratégie pour répondre à la question.
On peut différencier de nombreux types de requêtes :
| Questions factuelles | « Où a été brûlée Jeanne d'Arc ? » |
|---|---|
| Questions booléennes (oui ou non) | « Hosni Moubarak est-il toujours président ? » |
| Définitions | « Que signifie le sigle IHM ? » |
| Causes/Conséquences | « Pourquoi la mer est-elle bleue ? » |
| Procédures | « Comment refaire sa carte d'identité ? » |
| Listes | « Citer 3 présidents américains » |
| Requêtes évaluatives/comparatives | « Quelle est la plus grande ville de France ? » |
| Opinions | « Que pensent les Français de Nicolas Sarkozy ? » |
Type de réponse attendu
Le type de la réponse attendue correspond à l'identification de l'objet de la question (souvent à partir de la reconnaissance du type d'entité nommée) ou du type de la phrase attendu.
| Personne | « Qui ... », « Quel ministre ... » |
|---|---|
| Organisation | « Qui ... », « Quelle compagnie ... » |
| Lieu | « Où ... », « Dans quelle région ... » |
| Date | « Quand ... », « En quelle année ... » |
| Explication | « Pourquoi ... », « Pour quelle raison ... » |
|---|---|
| Procedure | « Comment ... », « Quelles sont les étapes pour ... » |
Focus de la question
Le focus d'une question correspond à la propriété ou l'entité recherchée par la question.
- « Dans quelle région se trouve le Mont Saint-Michel ? »
- « Quel âge a Jacques Chirac ? »
Thème de la question
Le thème de la question (ou topic) est l'objet sur lequel se porte la question.
- « Quel âge a Jacques Chirac ? »
Recherche des documents
Après avoir analysé la question, l'objectif est de rechercher les documents susceptibles de répondre à la question.
La première étape de la recherche des documents est en général une recherche « classique ». On extrait les mots clés de la question, et on les utilise avec le moteur de recherche Google ou sur une base de données par exemple.
| Questions | Mots-clés |
|---|---|
| « Qui est Chuck Norris ? » | Chuck Norris |
| « Que fabrique l'entreprise Peugeot ? » | Peugeot; entreprise; fabriquer |
| « Quel pays l'Irak a-t-il envahi en 1990 ? » | Irak; envahir; 1990 |
| « Combien y avait-il d'habitants en France en 2005 ? » | France, habitants, 2005 |
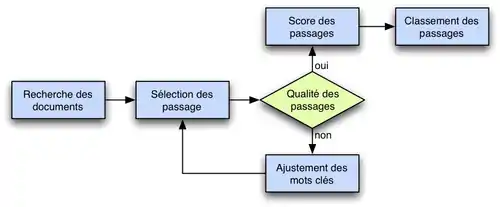
La seconde étape est ensuite de sélectionner les passages susceptibles de contenir la réponse.
Le schéma de droite illustre ce processus.
On commence par se servir du type de la réponse attendue, des mots-clés de la question, de ses entités nommées afin de sélectionner une première série de passages. Par la suite on estimera la qualité des passages afin de, au besoin, réajuster les mots-clés utilisés par la requête. On prend également en compte le nombre de passages obtenus. Si l'on en obtient trop, on restreindra le nombre de mots-clés, si au contraire il n'y en a pas assez, on étendra la requête.
Une fois une série de passages sélectionnés, on leur attribue un score afin de les classer.
On appelle passage candidat un passage sélectionné par le moteur de recherche. Un passage peut être composé d'une simple phrase ou d'un document entier. Un passage candidat peut contenir ou pas de réponses candidates. Généralement, ils sont classés à l'aide d'un score attribué par le moteur de recherche.
On appelle réponse candidate un mot ou groupe de mots généralement du même type que le type de réponse attendue et susceptibles de servir à sa construction.
| Question | Qui est le père de la reine Élisabeth II ? → Type personne |
|---|---|
| Passages candidats et réponses candidates |
|
Extraction des réponses
Il existe différentes techniques afin d'extraire une réponse candidate à partir d'un ou de plusieurs passages.
Patrons d'extractions
L'idée est de rechercher une séquence calque modélisant la réponse. L'élément cherché est placé sous forme de variable. Par exemple, si l'on est confronté à la question « Quelle est la capitale des USA ? », on pourra rechercher (entre autres) le patron « X est la capitale des USA ». Cette approche est héritée des techniques d'extraction d'information.
Cependant, à cause des variations linguistiques, il est en général indispensable d'utiliser de nombreuses variantes de chaque calque :
- Variation morphologique : « Où se trouve la capitale de l'Europe » ou « Où se trouve la capitale européenne ? »
- Variation lexicale : « Comment s'appelle la reine de Hollande » ou « Comment s'appelle la reine des Pays-Bas ? »
- Variation syntaxique : « Moscou compte 9 millions d'habitants » ou « Les 9 millions d'habitants de Moscou »
- Variation sémantique : « Comment Adolf Hitler est-il mort ? » où la réponse peut être « Adolf Hitler s'est suicidé »
- etc.
Le problème des patrons d'extraction est qu'ils sont extrêmement longs et couteux à faire à la main. Une des alternatives est d'utiliser des méthodes d'apprentissage permettant de les extraire automatiquement à partir de corpus. L'idée est de partir d'un patron déterminé, puis de remplacer un élément du patron par une variable (un prédicat ou un des arguments) puis on extrait du corpus un ensemble d'éléments pouvant instancier le patron.
Par exemple en partant de <person>Steve Jobs</person> dirige <company>Apple</company> et du corpus suivant :
- Steve Jobs dirige Apple
- Steve Jobs préside Apple
- Le PDG d'Apple, Steve Jobs
Il est possible d'obtenir les patrons Steve Jobs <dirige, préside> Apple et <le PDG de> Apple <,> Steve Jobs.
Toutefois, les anaphores et les expressions temporelles compliquent le problème.
| Anaphore | Andorre est un petit pays enclavé entre la France et l’Espagne dans le sud-ouest de l’Europe,
[...] Le tourisme est le secteur majeur de ce petit pays avec une économie saine, qui compte pour environ 80 % de son PNB.... |
Quel est le secteur économique majeur de l'Andorre ? |
|---|---|---|
| Expression temporelle |
L’Iran a envahi l’Irak le . Après 8 longues années de combat, la résolution 598 des Nations unies a mis fin à la guerre... |
Combien de temps a duré la guerre Iran-Irak ? |
La simple reconnaissance d'entités nommées pose également problème et peut mener à des incohérences. La modalité est difficile à définir (l'auteur prononce-t-il une vérité ou simplement une opinion voir une rumeur) et enfin les informations sur le web souvent peu fiables (blagues...).
Score et critères
L'idée est de calculer un score permettant de juger d'une réponse candidate.
On utilise pour cela en général quatre critères différents :
- Bon contexte global : on essaie d'évaluer la pertinence du passage d'où provient la réponse candidate. Pour cela on se fonde sur :
- le nombre de mots-clés présent dans le passage,
- le nombre de mots communs à la question et au passage,
- le classement du moteur de recherche pour le passage,
- etc.
- Bon contexte local : on essaie de juger l'adéquation du passage par rapport à la question :
- Distance moyenne entre la réponse candidate et les mots-clés présents dans le passage,
- Nombre de mots de la réponse candidate qui ne sont pas des mots-clés de la question,
- etc.
- Type sémantique correct : on s'assure que le type de la réponse candidate est soit le même soit un sous type du type de réponse attendue.
- Redondance : présence de la réponse dans le plus possible de passages sélectionnés.
Relations syntaxiques
L'idée est d'analyser la syntaxe de la question et des passages candidats.
On extrait des relations de type prédicat-argument:
| Questions | Relations |
|---|---|
| « Qui a écrit Les Misérables ? » | [X, écrire], [écrire, Les Misérables] |
| Réponse candidate | Relations |
| « Victor Hugo a écrit Les Misérables » | [Victor Hugo, écrire], [écrire, Les Misérables] |
De l'exemple précédent, le système peut déduire X = Victor Hugo.
Pour aller plus loin, on intègrera en général un peu plus d'analyse sémantique en introduisant le type de relations liant les éléments. En fait on construit, un arbre de dépendance à partir de la question.
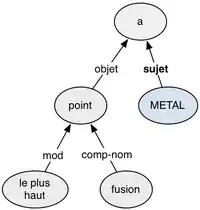
Par exemple, à partir de la phrase « Quel métal a le plus haut point de fusion ? », on obtient les relations représentées sur l'arbre à droite.
On recherche donc à remplir la variable METAL de type « métal ».
Par la suite, si la recherche nous permet d'obtenir le passage « Tungstène est un métal très dur et a le plus haut point de fusion. » Le type de réponse est bien « métal ». On compare alors les relations obtenues :
| Question | Passage |
|---|---|
|
|
<tungstène, métal, pred>
|
Ce qui nous permet d'obtenir la réponse Tungstène.
Utilisation de la logique
L'idée est de convertir la question en but puis de transformer le passage en formules logiques. On ajoute un certain nombre de prédicats permettant de représenter des règles de subsomption (permet de définir qu'un élément en implique un autre), des connaissances... Puis on essaie de prouver le but de la question à partir du passage.
Ainsi « Qui a assassiné John Lennon ? » est converti en : personne(X) & assassiner(X, Y) & John_Lennon(Y).
La réponse candidate « Mark Chapman a abattu John Lennon en 1980,... » sera convertie en Mark_Chapman(X) & abattre(X, Y) & John_Lennon(Y).
Ici on aura alors besoin de l'inférence lexicale abattre → assassiner.
Apprentissage machine
Des techniques d'apprentissage automatique supervisé sont employées pour entraîner des modèles qui tentent de repérer automatiquement où se trouve la réponse dans un ou plusieurs passages candidats. Les traits (features) employés pour faire ce genre de discrimination portent à la fois sur la question posée et sur la réponse candidate, et incluent :
- le type de question ;
- la présence de patrons d'extraction comme expliqué ci-dessus ;
- la distance entre les mots de la question et de la réponse candidate ;
- la localisation de la ponctuation (vrai si la réponse candidate suit immédiatement une ponctuation, faux autrement) ;
- etc.[2]
Il est également possible de repérer des réponses candidates à l'aide de l'apprentissage non supervisé, lorsque les documents pertinents sont suffisamment redondants, par exemple lorsqu'une vaste collection est interrogée. Le dallage par n-grammes permet par exemple de considérer et d'attribuer un poids à toutes les séquences de mots trouvées dans les extraits pertinents des documents repérés, l'idée étant que les séquences de mots les plus répétées font probablement partie de la réponse. Les séquences de mots contiguës les plus intéressantes composent la réponse[2].
Limites des approches actuelles
- Parfois la réponse à une question est répartie sur plusieurs documents ou plusieurs extraits épars. Est-il possible de construire une réponse à partir de différents documents candidats ? Les approches qui tentent de résoudre ce problème s'appellent notamment le multi-hop question answering, littéralement question-réponse en plusieurs bonds.
- Certaines questions demandent à être décomposées. Par exemple « Le président français est-il marié ? » implique « Qui est le président de la France ? » puis « Emmanuel Macron est-il marié ? ».
- Comment savoir si deux réponses sont la même (estimations, etc) ? Comment traiter les cas de variations (la taille d'un homme, la population d'un pays, la femme du président français, etc) ?
- En utilisant les systèmes de traductions automatiques, on peut imaginer de poser une question en français et de rechercher la réponse dans des documents en anglais.
- Comment présenter la réponse ? Quel format utiliser ? Liste, graphique, dialogue, carte...
- Le traitement de la langue n'est pas encore parfait, certains traitements ne fonctionnent pas ou de manière non optimal : le traitement des Anaphores, des synonymes, des paraphrases, des métonymies, de la négation, des quantifieurs (unités), la reconnaissance des figures de style...
- De nouvelles méthodes d'inférences peuvent être proposées. Par exemple prenons « Quelle est la plus grande ville de France ? ». On peut répondre à cette question par :
- Matching : on recherche « Paris est la plus grande ville de France » (ou une paraphrase). C'est la méthode utilisée en général
- On peut imaginer faire une recherche superlative : trouver la liste des villes françaises et leur population et trier, trouver les plus grandes villes du monde et choisir les villes françaises...
- Certaines réponses pourraient être déduites à partir d'heuristiques.
- Des systèmes d'inférences complexes : « Lille est la 2ème plus grande ville de France »; « Londres est plus grand que Lille »; « Paris est plus grand que Londres »; « Paris est en France ». Donc Paris > Londres > Lille, etc.
- L'utilisation d'un modèle utilisateur peut être envisagée. Elle permettrait ainsi, à partir de données en rapport avec l'utilisateur, de pouvoir résoudre les ambiguïtés des entités nommées (par exemple l'utilisateur recherche Chicago, parle-t-il de la ville, de la comédie musicale, du film ?), résoudre les problèmes de granularité (Où est Los Angeles ?, sur la planète Terre)...
- Résoudre des questions portant sur les relations : « Quelles sont les relations entre Nicolas Sarkozy et Angela Merkel ? »
- Implication textuelle : être capable de reconnaître qu'un passage peut en impliquer un autre. Par exemple « Nicolas Sarkozy a fait refaire un avion destiné à ses transports officiels » implique « Un avion est destiné aux voyages du président français ».
Évaluation d'un système de réponse aux questions
Il existe différentes campagnes visant à classer les meilleurs systèmes de réponse aux questions : TREC (anglais), CLEF (multilingue), EQUER (français), NTCIR (japonais), QUAERO (français, anglais). Les systèmes sont évalués autant à partir de domaine ouvert que de collections fermées (en général, des articles de journaux). Les types de questions analysées sont principalement des factoïdes et des définitions.
Il y a deux principales manières de juger d'une réponse. Le premier type de jugement est automatique : par Mean Reciprocal Rank (MRR). On va par exemple donner 1 point au système si la 1re réponse est correcte, 0,5 si la seconde l'est et 0,2 si elle est avant la 5e. Le second moyen de juger d'une réponse est d'utiliser le jugement humain. On se fonde alors sur la correction ou l'exactitude de la réponse ainsi que sa justification.
L'exactitude de la réponse à une question n'est cependant pas facile à juger :
- Quelle est la réponse d'une question avec erreur ? Par exemple accepte-t-on la réponse
néantà la question « Quand est mort Johnny hallyday ? » (il est toujours vivant !) ? - Quelle granularité doit-on accepter ? Par exemple « Où se trouve Los Angeles ? ». Sur la planète Terre ? En Amérique ? En Californie ? Aux États-Unis ? On peut alors avoir besoin d'utiliser un modèle utilisateur afin de tenter de déterminer ce qu'il attend comme réponse.
Une autre mesure importante est rappel et la précision. Le rappel mesure la proportion des documents pertinents sélectionnés parmi l'ensemble des documents pertinents (donc moins il y a de documents pertinents qui n'ont pas été sélectionnés, plus le rappel est bon). La précision mesure la proportion de documents pertinents sélectionnés parmi tous les documents sélectionnés (donc plus il y a de mauvais documents sélectionnés, plus la précision est mauvaise). En général, augmenter le rappel entraîne une baisse de la précision et vice versa.
Voir aussi
- Le système START
- Les campagnes d'évaluation TREC (anglais), CLEF (multilingue), EQUER (français), NTCIR (japonais), QUAERO (français, anglais)
- Stanford Question Answering Dataset
Bibliographie
- Boris Katz, Annotating the World Wide Web Using Natural Language, 1997
- (en) Daniel Jurafsky et James H. Martin, « Chapter 23 - Question Answering » (consulté le )