Single instruction multiple data
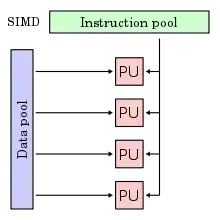
Single Instruction on Multiple Data (signifiant en anglais : « instruction unique, données multiples »), ou SIMD, est une des quatre catégories d'architecture définies par la taxonomie de Flynn en 1966 et désigne un mode de fonctionnement des ordinateurs dotés de capacités de parallélisme. Dans ce mode, la même instruction est appliquée simultanément à plusieurs données pour produire plusieurs résultats.
On utilise cette abréviation par opposition à SISD (Single Instruction, Single Data), le fonctionnement traditionnel, MIMD (Multiple Instructions, Multiple Data), le fonctionnement avec plusieurs processeurs aux mémoires indépendantes ou SPMD (single program, multiple data). Il existe également le terme de SIMT (Single Instruction, Multiple Threads) qui est une amélioration de SIMD en l'adaptant au calcul multithread.
Historique
Défini par la taxonomie de Flynn en 1966, l'une des premières mises en application sera dans le supercalculateur Cray-1 en 1976[1].
Au début des années 1990, les micro-ordinateur Macintosh d'Apple et BeBox sont équipés de processeurs RISC PowerPC, ceux-ci comportent l'instruction fmadd (de l'anglais floating multiply-add, signifiant addition-mulitiplication flottante) et fmsub (de l'anglais floating multiply-substract, signifiant soustraction-multiplication flottante), capable de multiplier deux registres, puis de l'additionner ou soustraire à un troisième et de mettre le résultat dans un quatrième, ceux-ci pouvant être choisis à volonté sur les registres flottant double précision du FPU. Celles-ci, comme la majorité des autres instructions flottantes prennent sur les processeurs de technologie RISC, trois à quatre cycles d’horloge pour leur exécution, mais jusqu'à trois peuvent être effectuées en parallèle, grâce au système de pipeline[2].
Le , Intel sort le premier microprocesseur doté de la technologie MMX, le Pentium MMX à 166 MHz (P166MX) c'est la première fois qu'un SIMD est ajouté à un processeur de technologie CISC. Plus tard dans l'année 1997 , AMD lance également un processeur X86 compatible MMX (sous licence Intel) comprenant un jeu SIMD supplémentaire, le 3DNow! Intel ajoutera un nouveau jeu SIMD en 1999 avec la technologie SSE, incompatible avec 3DNow!.
Le VFP d'ARM est un processeur vectoriel introduit dans les SoC dans les années 2000, cela a permis de les introduire dans les téléphones mobiles et autres appareils mobiles de très faible consommation. En 2009, ARM introduit une évolution majeure avec la technologie NEON dans sa nouvelle gamme de processeurs ARM Cortex-A, avec le premier modèle, le Cortex-A8, augmentant les performances dans ce type d'appareil.
Utilisation
Le modèle SIMD convient particulièrement bien aux traitements dont la structure est très régulière, comme c'est le cas pour le calcul matriciel. Généralement, les applications qui profitent des architectures SIMD sont celles qui utilisent beaucoup de tableaux, de matrices, ou de structures de données du même genre. On peut notamment citer les applications scientifiques, ou de traitement du signal.
Implémentation matérielle
L'implémentation matérielle du paradigme SIMD peut se faire de diverses façons :
- via l’utilisation d'instructions SIMD, généralement en micro-code interprété sur du CISC ou câblé sur du RISC ;
- par des processeurs vectoriels ;
- par des processeurs de flux (en) ;
- ou via des systèmes comportant des processeurs multicœurs ou plusieurs processeurs.
Dans les trois premiers cas, un seul processeur peut naturellement exécuter une opération identique sur des données différentes.
Dans le dernier cas, chaque processeur va effectuer une seule opération sur une donnée. Le parallélisme SIMD vient donc de l’utilisation de plusieurs processeurs.
Instructions SIMD
Ces instructions sont des instructions qui peuvent effectuer plusieurs opérations en parallèle, sur des données différentes.
Les opérations en question peuvent être :
- des opérations bit à bit, comme des et, ou, not bitwise ;
- des additions ;
- des soustractions ;
- des multiplications ;
- éventuellement des divisions ;
- ou des opérations mathématiques plus complexes.

Toutes ces instructions SIMD travaillent sur un ensemble de données de même taille et de même type. Ces données sont rassemblées dans des blocs de données, d'une taille fixe, appelés vecteurs. Ces vecteurs contiennent plusieurs nombres entiers ou nombres flottants placés les uns à côté des autres.
Une instruction SIMD va traiter chacune des données du vecteur indépendamment des autres. Par exemple, une instruction d'addition SIMD va additionner ensemble les données qui sont à la même place dans deux vecteurs, et placer le résultat dans un autre vecteur, à la même place. Quand on exécute une instruction sur un vecteur, les données présentes dans ce vecteur sont traitées simultanément.
Tous les processeurs modernes contiennent des extensions à leur jeu d'instructions, comme le MMX, le SSE, etc. Ces extensions ont été ajoutées aux processeurs modernes pour pouvoir améliorer la vitesse de traitement sur les calculs. Les instructions SIMD sont composées notamment des jeux d'instructions :
- Sur processeur x86 : MMX, 3DNow!, SSE, SSE2, SSE3, SSSE3, SSE4, SSE4.1, SSE4.2, AVX, AVX2 et AVX512 ;
- Sur processeur PowerPC : AltiVec ;
- Sur processeur ARM : VFP, VFPv2, VFPv3lite, VFPv3, NEON, VFPv4 ;
- Sur processeur SPARC : VIS et VIS2 ;
- Sur processeur MIPS : MDMX et MIPS-3D.
Registres SIMD
Les vecteurs traités par ces instructions sont souvent placés dans des registres à part, spécialisés dans le stockage des vecteurs. Ceux-ci ont souvent une taille assez importante, environ 128 à 256 bits.
Toutefois, certains processeurs utilisent leurs registres généraux pour stocker ces vecteurs. Ils ne disposent donc pas forcément de registres spécialisés, et les registres normaux sont utilisés pour maintenir des vecteurs. Les instructions SIMD travaillent alors sur les mêmes registres que leurs congénères non-SIMD. On appelle cette forme d'instructions SIMD du micro-SIMD.
Usage pour l'optimisation
Les programmes qui sont optimisés avec ce genre d'instructions sont ceux qui demandent beaucoup de ressources processeur : compression de données, codec pour la lecture de son et/ou de vidéo, calcul sur de grands nombres entiers (cryptographie notamment), etc.
En général, ces instructions sont utilisées directement par les programmeurs. Ceux-ci écrivent des morceaux de code assembleur dans leurs programmes afin de pouvoir profiter au maximum des optimisations permises par les instructions SIMD. Ceux-ci commencent par développer un code générique qui fonctionnera partout. Quand l'algorithme est correct, ils écrivent une version spécialisée pour une extension d'un processeur donné. L'utilisation de ces instructions demande donc beaucoup de travail et des connaissances approfondies en assembleur.
Certains compilateurs et certaines bibliothèques permettent de bénéficier de ces optimisations sans coder en assembleur. On peut noter que le projet Mono par exemple profite de ces optimisations processeur si l'on utilise les classes adaptées. Mais il faut toutefois signaler que l'optimisation manuelle, effectuée par des programmeurs donne de meilleurs résultats que des optimisations effectuées par le compilateur[3].
Processeurs vectoriels
Les processeurs vectoriels peuvent être vus comme des processeurs incorporant des instructions SIMD, avec quelques améliorations annexes. Par exemple, ces processeurs n'imposent pas de restrictions d'alignement pour les instructions SIMD d'accès mémoire. De plus, les instructions d'accès mémoire supportent des modes d'accès à la mémoire supplémentaires, comme les accès entrelacés ou en scatter-gather.
Stream Processing
Le Stream Processing, ou calcul par flux, permet d'utiliser différents types d'unités pour le calcul, c'est ce que permet par exemple, le standard de bibliothèque de calcul OpenCL.
Paradigme logiciel
Afin de faciliter l'utilisation des architectures SIMD, divers langages ont été inventés. Ces langages cherchent à rendre le parallélisme de donnée utilisable plus facilement par les compilateurs.
Dans les langages procéduraux actuels, les compilateurs ont du mal à déterminer si des instructions travaillent sur des données indépendantes ou non. En conséquence, les compilateurs peuvent rater certaines opportunités d'utilisation d'instructions SIMD ou d'instructions vectorielles. C'est pour éviter au maximum ce genre de situations que certains langages SIMD ont été inventés.
Parmi ces langages, on peut citer :
- Le langage CUDA. Ce langage permet l'utilisation des cartes graphiques pour le calcul numérique, et on y trouve de nombreuses instructions qui agissent sur plusieurs données en même temps.
- Le standard de bibliothèque de calcul OpenCL, permet de paralléliser sur tous les processeurs disponibles du système ; CPU, GPU (ou gpGPU), DSP, SIMD, FPU, etc.
- La bibliothèque OpenMP est une bibliothèque de calcul parallèle hétérogène, devenu un standard de fait sur les architectures comprenant plusieurs ordinateurs. Elle comporte depuis la version 4.0 des fonctions spécialisées dans l'utilisation des unités SIMD[4].
- Les logiciels de calcul numérique, comme Matlab, Maple, Octave ou l'extension de Python SciPy, permettent aussi le calcul matriciel par des opérations SIMD.
- On peut enfin citer la bibliothèque BLAS très utilisée en Fortran et en C/C++ pour l'algèbre linéaire. Cette bibliothèque fournit de nombreuses primitives de calcul matriciel et d'algèbre linéaire, qui opèrent toutes sur plusieurs données (des matrices ou des flottants).
Enfin, des compilateurs comme GCC ou LLVM (et CLANG), permettent l'auto-vectorisation de boucles de calcul sur la plupart des SIMD existant.
Références
- (en) Use of SIMD Vector Operations to Accelerate Application Code Performance on Low-Powered ARM and Intel Platforms, université de Griffith, en Australie.
- (en)PowerPC 603e and EM603e RISC Microprocessor Family User's Manual, sur IBM.com – chapitre « 2.3.4.2.2 Floating-Point Multiply-Add Instructions », page 2-26 et chapitre « 6.4.3 Floating-Point Unit Execution Timing », page 6-17
- « Impact des compilateurs sur les architectures CPU x86/x64 », sur hardware.fr (consulté le ).
- (en) OpenMP 4.0 Specifications Released