Reconstruction 3D à partir d'images
La reconstruction 3D à partir d'images, image-based 3D reconstruction en anglais, désigne la technique qui permet d'obtenir une représentation en trois dimensions d'un objet ou d'une scène à partir d'un ensemble d'images prises sous différents points de vue de l'objet ou de la scène.
D'une manière plus générale, le problème appelé reconstruction 3D (en) est le suivant : on dispose d'une ou plusieurs représentations en 2D d'un objet et on souhaite déterminer les coordonnées des éléments visibles sur ces représentations dans un repère de l'espace réel 3D.
Dans le cadre plus spécifique de cet article où les représentations 2D sont des photographies, il s'agit de retrouver la profondeur des points visibles sur l'image, qui est perdue durant le processus de projection qui produit l'image.

Principe
Les points visibles sur les images sont les projections des points réels qu'on peut alors situer sur des droites. Si deux ou plusieurs vues de l'objet sont prises, la position dans l'espace des points réels peut alors être obtenue par intersection de ces droites : c'est le principe de triangulation fondamental de toute reconstruction 3D à partir d'images[1].
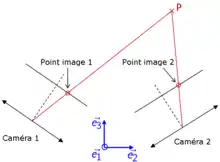
Pour obtenir, comme souhaité, les coordonnées des points de la scène, il faut cependant résoudre un certain nombre de problèmes :
- Problème de calibration ou comment se projettent les points de la scène sur l'image. Pour cela, le modèle de sténopé est utilisé et il est alors nécessaire de connaître des paramètres dits intrinsèques de la caméra (distance focale, centre de l'image...). Ensuite, il est nécessaire de connaître la position relative des caméras pour pouvoir déterminer les coordonnées des points de l'espace dans un repère de la scène non lié à la caméra. Ces paramètres, dit extrinsèques, sont la position et l'orientation de la caméra dans l'espace.
- Problème d'association (matching): il faut être capable de reconnaître et d'associer les points qui apparaissent sur plusieurs photos.
- Problème de reconstruction : il s'agit de déterminer les coordonnées 3D des points à partir des associations faites et des paramètres de calibration[Note 1].
À cela s'ajoute un autre problème : la densité de la reconstruction. Une fois obtenues les coordonnées d'un certain nombre de points dans l'espace, il faut trouver la surface à laquelle appartiennent ces points pour obtenir un maillage, un modèle dense. Sinon, dans certains cas, quand on obtient un grand nombre de points, le nuage de points formé suffit à définir visuellement la forme de l'objet mais la reconstruction est alors clairsemée (sparse).
Dans les sous-parties suivantes, nous étudierons chacune de ces difficultés.
Paramètres intrinsèques
La projection des coordonnées d'un point de l'espace sur l'image selon le modèle de sténopé est illustré ci-contre.
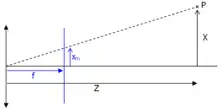
Ainsi, les coordonnées du point image de P dans le repère caméra sont :




En informatique, on exprime en général les coordonnées des points d'une image à partir du coin supérieur gauche. On a donc les coordonnées du centre optique sur l'image comme paramètres supplémentaires à déterminer.
Les relations s'écrivent matriciellement en faisant intervenir la matrice K, classiquement employée dans la littérature, dite de calibration interne : .

Paramètres extrinsèques
Il s'agit simplement d'un vecteur de position de la caméra dans le repère de la scène et de trois vecteurs définissant l'orientation de celle-ci. Avec ces paramètres, on est alors capable de positionner les points de vue de l'objet les uns par rapport aux autres.
Il est fréquent que les positions et orientations des caméras soient donnés relativement à la première caméra.
Méthodes d'obtention
Pour les paramètres intrinsèques, il est généralement possible de faire une estimation en amont des paramètres (qui sont des caractéristiques invariantes de l'appareil photo utilisé) en mettant en œuvre une technique de calibration qui consiste à photographier un objet bien connu (par exemple, un échiquier). Cependant, les techniques récentes de reconstruction savent estimer automatiquement les paramètres sans information a priori sur l'appareil photo[Note 2].
Pour les paramètres extrinsèques, on peut soit les estimer par calcul à partir des associations de points[Note 3], soit connaître précisément la position des caméras en faisant, par exemple, un montage spécifique. C'est ce que proposent Thomas T. Lu et Tien-Hsin Chao[2], avec un montage utilisant une unique caméra et deux points de vue simulés par deux miroirs et un prisme.
Chaque moitié de l'image obtenue fournit un point de vue différent de l'objet grâce aux miroirs et au prisme. On a ainsi l'avantage d'avoir un montage relativement simple à réaliser et ne nécessitant qu'une seule caméra. De plus, par principe, les paramètres de calibration extrinsèques sont connus et ce très précisément, sans estimation, d'où l'intérêt de la méthode.
Association
L'association des points images du même point de la scène sur différentes photos est le point clé de la reconstruction 3D. C'est cela qui permet la détermination des coordonnées 3D des points de la scène par triangulation et également, pour les méthodes récentes, la calibration des caméras.
Pour cela, il convient tout d'abord de bien choisir les points sur les images, c'est l'étape d'extraction de points d'intérêt (feature points). Il peut s'agir par exemple de coins sur l'image, faciles à localiser. Ensuite, des données caractéristiques de ces points d'intérêt doivent être calculées pour pouvoir les identifier d'une image à l'autre.
Le choix et l'association de points d'intérêt peut être réalisé à la main, mais il est plus efficace d'automatiser la procédure. Des algorithmes relativement récents, comme SIFT et SURF, excellent dans ce domaine et ont permis une réelle efficacité de l'acquisition 3D à partir de photos[3].
Géométrie épipolaire
Lorsque la position relative des caméras est connue (i.e. les paramètres extrinsèques de calibration), il est possible de ne rechercher les correspondances de points que sur les lignes épipolaires.
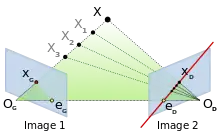
Sur la figure ci-contre sont représentées deux vues d'un point X. Les points et sont respectivement les projections du centre de la caméra de droite sur l'image de gauche et du centre de la caméra de gauche sur l'image de droite. Ces deux points sont appelés épipôles. On voit que si est l'image du point X sur l'image de gauche, alors l'ensemble des points images possibles sur l'image de droite est une droite passant par appelée ligne épipolaire. La recherche des correspondances est alors simplifiée en une recherche sur un ensemble 1D lorsque la géométrie épipolaire est connue. Lorsque les axes des caméras sont parallèles, les lignes épipolaires sont horizontales et les associations sont donc à rechercher sur les mêmes numéros de ligne des images.





Reconstruction avec calibration
L'obtention des coordonnées des points dans l'espace est quasiment immédiate si les paramètres de calibration sont connus. Si on note :
- les coordonnées du point de la scène dans le repère absolu,
- (resp. ) les coordonnées du point dans l'image 1 (resp. 2),
- (resp. ) les coordonnées du point dans le repère caméra 1 (resp. 2),
- (resp. ) la matrice de calibration interne de la caméra 1 (resp. 2),
- et (resp. et ) l'orientation et la position de la caméra 1 (resp. 2) dans le repère absolu,











alors on a :

et

Ainsi, la résolution de ces équations permet de trouver .
Algorithme Structure from Motion
Cette technique a pour but d'à la fois créer la reconstruction (Structure) et d'estimer le déplacement de la caméra entre les prises de vue (Motion)[1]. Le principe de la méthode est le suivant :
Tout d'abord, deux images sont sélectionnées parmi les différentes vues de l'objet et un repère de la scène initial est défini. Ensuite, la position et l'orientation des caméras à l'origine des autres images sont déterminés dans ce repère grâce aux associations de points. Des nouveaux points 3D sont alors ajoutés à la reconstruction. À chaque étape, la reconstruction est affinée et enrichie. Une fois la reconstruction effectuée et la position relative des caméras retrouvée, des ajustements peuvent être réalisés.
Grâce à cette méthode, on obtient une reconstruction et la position des caméras par rapport à celle-ci sans aucune hypothèse préalable. Tout ceci est fidèle à la réalité à un facteur d'échelle près.
Densité
Une fois que des points isolés sont obtenus par reconstruction, on peut soit conserver les points seulement, si ceux-ci suffisent à définir la forme de l'objet, soit vouloir une reconstruction dense, associée à un maillage.
Densification aidée par l'utilisateur
Comme suggéré ici[4], une fois les points reconstruits, on peut utiliser un algorithme pour trouver les formes primitives (plan, sphère, cylindre, surface de Bézier...) correspondant au mieux à la forme locale de l'objet. L'utilisateur peut alors sélectionner une zone de l'objet et demander à l'algorithme de trouver par exemple le plan qui s'adapte le mieux aux points. Ceci peut se faire simplement par une minimisation de distance des points à la surface cherchée.
Méthode Visual Hulls
La méthode Visual Hulls[5], qui peut être traduit par silhouettes visuelles, est une méthode de reconstruction qui permet, à partir d'images calibrées, d'obtenir un modèle solide dense de l'objet.
Son principe est totalement différent du principe général de reconstruction présenté auparavant. Ici, ce sont les silhouettes apparentes de l'objet sur chacune des vues qui sont étudiées.
Le premier travail consiste à isoler le contour de l'objet dans chaque image pour en déduire le cône de vue et, par intersection, la silhouette de l'objet. De nombreux travaux supplémentaires, que nous ne détaillerons pas ici, sont ensuite à réaliser pour affiner le modèle de l'objet.
Notes et références
Notes
- Cependant, certaines méthodes récentes s'attachent à déterminer également ces paramètres.
- C'est le cas d'ARC3D présenté par la suite
- Ce que font Structute from Motion et ARC3D, présentés par la suite.
Références
- Marc Pollefeys, « Visual 3D Modeling from Images »,
- (en) Thomas T. Lu et Tien-Hsin Chao, A high-resolution and high-speed 3D imaging system and its application on ATR.
- (en) Yasutaka Furukawa, Brian Curless, Steven M. Seitz et Richard Szeliski, Towards Internet-scale Multi-view Stereo.
- « 3D object reconstruction »
- (en) Yasutaka Furukawa et Jean Ponce, Carved Visual Hulls for Image-Based Modeling.