Observatoire linguistique
L’Observatoire linguistique (en anglais : Linguasphere Observatory ; en gallois : Wylfa leithoedd) est un organisme transnational de recherche linguistique, responsable du Registre de la Linguasphère et du site d'information http://www.linguasphere.info (voir ci-dessous). Ses premiers objectifs sont élaborés au Québec en 1983, à l'Université Laval[1], et l'Observatoire s’est par la suite établi et déclaré en Normandie en tant qu’association loi de 1901 à but non lucratif [2], sous la présidence d’honneur de feu Léopold Sedar Senghor, poète de langue française et premier président du Sénégal.
L’Observatoire a pour fondateur et directeur actuel David Dalby, ancien directeur franco-britannique de l’International African Institute/Institut Africain International, émérite de l'université de Londres (School of Oriental and African Studies), et eut pour premier secrétaire de recherches Philippe Blanchet, poète de langue provençale et actuel professeur de sociolinguistique à l’Université de Rennes 2. Entre 2010 et 2015,le directeur-adjoint de l’Observatoire et développeur de son site internet « linguasphere.info » est Pierrick le Feuvre, webmestre du site « ouiaubreton.com » de 2006 à 2010[3] et du site « pacte des langues » en 2007[4]. Le président du conseil de recherche de l'Observatoire linguistique est le géolinguiste Roland Breton, professeur émérite à Paris VIII et l'auteur de l’Atlas des langues du monde et de l’Atlas des minorités linguistiques dans le monde[5].
Les cellules de recherches de l’Observatoire se situent actuellement dans l’Union Européenne, depuis 1996 dans le Carmarthenshire au Pays de Galles (précédemment à Cressenville dans le Vexin normand), et depuis août 2010 à Paris (précédemment à Marseille). Leurs travaux de recherche sont bénévoles et aux buts scientifiques et éducatifs, sans intérêt commercial, sectaire ou politique.
Depuis sa création[6], l'Observatoire linguistique est un organisme bilingue qui utilise ou le français ou l'anglais pour la présentation de ses travaux sur la « linguasphère » (voir ci-dessous) et sur les langues individuelles du monde. Actuellement, il cherche le soutien matériel nécessaire pour la préparation et la publication de toutes ses informations en ligne dans un format bilingue (français + anglais), voire multilingue.
Le concept de la linguasphère
Depuis les années 1990, l’Observatoire linguistique explore le concept de la linguasphère « perçue comme une réalité fondamentale dans l’évolution de l’humanité et de la planète ». Selon l'Observatoire, « la linguasphère constitue le continuum planétaire des voix de l’humanité, englobant toutes les langues et tous les systèmes d’enregistrement et de communication parlée et écrite. En préservant et en transmettant l’héritage collectif du savoir humain, la linguasphère a permis à notre espèce de construire à travers les siècles un foyer de connaissances autour d'une planète plurilingue, sous le toit des langues entrelacées, des arts et des sciences sans frontières, des sports et du droit internationaux. L’achèvement d’une linguasphère orbitale au début du XXIe siècle offre enfin à l’humanité tout entière les clefs de ce foyer commun[7]. »
Le « Registre de la Linguasphère »
Parmi les programmes de recherche de l'Observatoire, le plus important est son « Registre de la Linguasphère » (répertoire des langues et communautés linguistiques du monde), y compris le cadre et le codage de référence géolinguistique élaborés pour ce registre.
L’Observatoire linguistique a mis au point un système innovant de classification philologique, où toute langue naturelle, parlée ou écrite, trouve sa place à l’intérieur d’une table de référence globale, à l’aide d’un système de codage géolinguistique. Cette échelle de codage ou « linguascale » est composée d'un préfixe décimal de deux chiffres, suivi d'une série d'une jusqu'à six lettres (voir plus bas), afin d’enregistrer les strates de relations linguistiques ou le manque de relations évidentes parmi les langues individuelles.
Une première introduction aux travaux du Registre et de son échelle de codage, est présentée en Normandie en 1990 et publiée en Wallonie en 1992. Les principes de classification décrits dans cette étude restent constants, même si des raffinements terminologiques sont intervenus depuis[8].
Le premier fascicule de l'éventuel Registre est également publiée en français, à Cressenville en 1993, consacrée aux langues de France et des pays et régions limitrophes[9].
Au Pays de Galles en 1999/2000, l’Observatoire Linguistique publie en anglais l'édition fondatrice du Linguasphere Register of the world's languages and speech communities (en français : le Registre Linguasphère des langues et communautés linguistiques du Monde) conçu et compilé par David Dalby, avec la participation de David Barrett et Michael Mann[10].
Des critiques de cet ouvrage ont été publiées en anglais par Edward J. Vajda dans la revue Language[11] et par Anthony P. Grant dans le Journal of the Royal Anthropological Society[12].
L’Observatoire présente actuellement en ligne une édition révisée du Registre de la Linguasphère, la première d’une série de mises à jour prévues tous les dix ans. L’édition actuelle (LSR1), qui comprend les textes de l’édition fondatrice de 2000, est publiée en ligne depuis 2011 à titre de ressource publique librement accessible, et de base de données en ligne, constituée et coordonnée par David Dalby et Pierrick le Feuvre. Les dispositions nécessaires sont prises pour permettre l’engagement par la même plateforme internet d’informations supplémentaires et enrichies, et une discussion ouverte, à l’aide de propositions et de critiques de la part des utilisateurs du site.
Le Cadre de référence du « Registre »
L'encadrement du « Registre de la Linguasphère » est fourni par un système de référence géolinguistique qui vise à recouvrir toutes les langues vivantes ou enregistrées du monde, tel que publié dans le « Linguasphere Register » en 1999/2000 et par la suite affiné. Ce système est construit autour de sa propre échelle de codage alphanumérique, la « linguascale », qui sert à situer chaque langue et chaque variété linguistique au sein de la totalité des langues écrites ou parlées du monde.
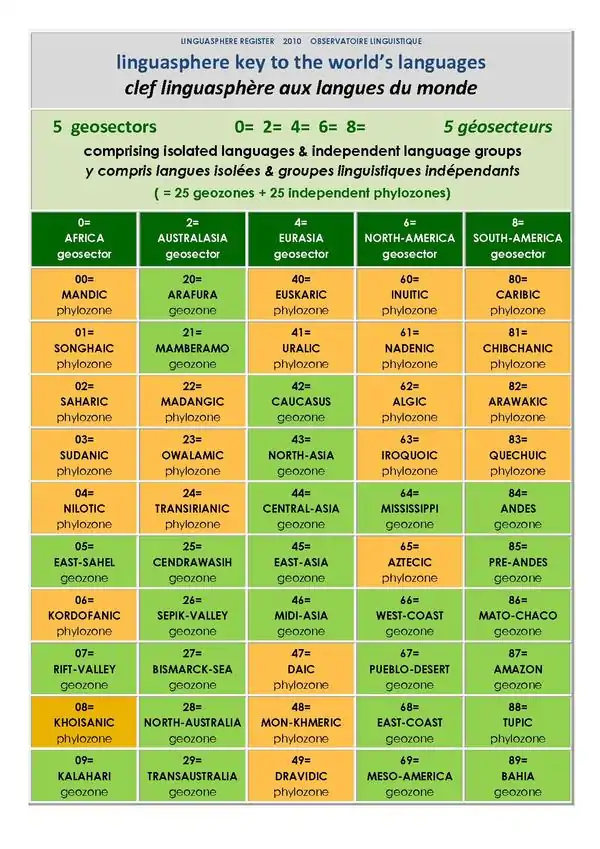
La Clef « Linguasphère » des secteurs et zones
La première composante de cette linguascale est la classification décimale évoquée plus haut, basée sur un préfixe de deux chiffres qui se rapporte à une des cent zones géolinguistiques appropriées, chiffrées de 00. jusqu'à 99.
Le premier des deux chiffres désigne l’un des dix secteurs référentiels entre lesquels les langues du monde sont classées d'abord. Le système de référence choisit parmi ces dix « secteurs », un total de cinq grandes familles ou phyla linguistiques. Ces cinq « phylosecteurs » ou aires d’affinité transcontinentale ou intercontinentale réunissent ensemble les langues maternelles de 85 % de l’humanité, suivant l'estimation de l’Observatoire dans sa publication de 1992.
Les langues isolées ou groupes de langues indépendants qui ne sont pas inclus dans les limites généralement reconnues de l’une des cinq grandes familles – y compris les langues dont l’appartenance est incertaine ou inconnue – sont renvoyées selon des critères géographiques à l’une de cinq « géosecteurs » ou aires de référence continentale.
Le « Registre Linguasphère » divise ainsi le monde en dix tiroirs conventionnels, ou secteurs de référence, à l’intérieur desquels chaque langue trouve sa place : dans l’une des cinq catégories linguistiques ou phylozones, ou dans l’une des cinq catégories géographiques pour les autres. Le premier chiffre de son code Linguasphère représente donc le secteur de référence de toute langue, de tout groupement de langues ou de toute variété linguistique.
Ces dix secteurs, classés alphabétiquement, sont chiffrés de manière que les cinq géosecteurs soient représentés par des chiffres pairs, et les cinq phylosecteurs par des chiffres impairs, comme suit. Pour les géosecteurs, les appellations choisies sont des noms géographiques (terminant toujours par –a en anglais), ou pour les phylosecteurs, des noms linguistiques (terminant toujours par –an en anglais).
| GÉOSECTEURS | PHYLOSECTEURS |
| 0= AFRIQUE / AFRICA | 1= AFRO-ASIEN / AFRO-ASIAN (= "Afro-Asiatic") |
| 2= AUSTRALASIE (OCÉANIE) / AUSTRALASIA | 3= AUSTRONÉSIEN / AUSTRONESIAN |
| 4= EURASIE / EURASIA | 5= INDO-EUROPÉEN / INDO-EUROPEAN |
| 6= AMÉRIQUE DU NORD / NORTH-AMERICA | 7= SINO-INDIEN / SINO-INDIAN (="Sino-Tibetan") |
| 8= AMÉRIQUE DU SUD / SOUTH-AMERICA | 9= TRANSAFRICAIN / TRANSAFRICAN (= "Volta-Congo" moins "Mande") |
Le second chiffre sert à distinguer une des dix zones à l'intérieur desquelles chaque secteur est partagé à des fins pratiques de référencement mondial à deux niveaux. Les zones qui le composent, tout comme les géosecteurs ou les phylosecteurs, sont décrites soit comme des « géozones » soit comme des « phylozones », suivant la nature des liens qui existent entre les langues qui les constituent.
Bien que les secteurs fournissent une division naturelle du monde linguistique en dix parties, exploitable pour la commodité d’un référencement numérique, il est évident que leur sous-division ultérieure en 10 x 10 zones a nécessité des variations quantitatives entre ces zones, en ce qui concerne leur complexité linguistique relative. Toutefois, les variations de proximité linguistique parmi les langues de chaque géozone ou phylozone sont mesurées et présentées en termes d’une échelle alphabétique complémentaire à la clef (voir ci-dessous).
Ce système décimal a été conçu avec l'objectif (à évaluer et à adapter par ses utilisateurs!) de faciliter la navigation et l'exploration linguistiques de la Terre, ainsi que l’enseignement de la géographie actuelle des langues. La grille ci-dessous de cent zones n’a pas été proposée par l’Observatoire comme tableau des relations préhistoriques et historiques parmi les langues, mais comme cadre de référence et clef de codage sur la base duquel ces relations peuvent être présentées et si nécessaire réévaluées. Plus pertinent encore serait l’application potentielle de cette grille comme cadre comparatif et statistique des langues du monde au cours du XXIe siècle.

L'Échelle de proximité linguistique
À la suite de la clef numérique, et à l’intérieur de chaque zone, la deuxième composante de l’échelle des langues est constituée de trois lettres majuscules à partir de –AAA-. Cette partie des « codes-langues » sert à représenter les strates successives de relations linguistiques progressivement convergentes parmi les langues classées dans la même zone.
Dans le système Linguasphère, chaque zone est partagée initialement entre un ou plusieurs ensembles linguistiques, et la première majuscule de chaque code-langue sert à désigner l’ensemble concerné. Chaque ensemble se répartit ensuite entre une ou plusieurs chaînes, désignées par la seconde majuscule, et chaque chaîne fait de même entre un ou plusieurs réseaux, matérialisés par la troisième majuscule. Cette répartition des langues d’une zone entre ensembles, chaînes et réseaux reflète des degrés relatifs de proximité linguistique, tels qu’ils ont été déterminés en principe par l’estimation de la proportion de vocabulaire de base qu’elles partagent. En moyenne, les géozones sont divisées en davantage de séquences que les phylozones, puisque les liens entre les langues à l’intérieur de ces dernières sont par définition plus évidents et plus serrés.
La troisième et dernière composante de la linguascale peut être décomposée jusqu’à trois lettres minuscules, à partir de –aaa, afin de préciser aussi finement que possible les niveaux les plus proches de variation linguistique. La première et la deuxième lettres de cette série représentent successivement une « unité externe » et une « unité interne » (termes préférés depuis 2010 à la précédente appellation « langue externe » ou « langue interne », afin d’éviter l’usage aux connotations trop fluctuantes et souvent émotives des termes « langue » et « dialecte »). Les éventuelles variétés linguistiques à l’intérieur d'une unité interne sont codées à l’aide de la troisième minuscule.
[texte à compléter]
Exemple
L’emploi de l’échelle des langues peut être illustré par les exemples concrets ci-dessous, choisi parmi les langues romanes.
Ainsi le code qui recouvre toutes les formes du Français est 51-AAA-i, où le 5 désigne le phylosecteur indo-européen et le 51 la phylozone romane (et historiquement italique). Ensuite, 51-A représente l’ensemble roman, et 51-AA (la chaîne) est dans ce cas identique à 51-AAA, c'est-à-dire le réseau continu des langues romanes occidentales, à partir des variétés du portugais jusqu’aux variétés romanes en Italie.
À l’intérieur de ce réseau, les unités externes 51-AAA-a. Português+ Galego jusqu’à 51-AAA-t. Vegliot+ Ragusan comprennent la séquence :
51-AAA-h. Langues d’Oïl périphériques (nommées « Gallo+ Wallon », avec 110 unités internes ou variétés : -haa … -hqb)
51-AAA-i. Français (Langue d’Oïl centrale, avec 86 unités internes ou variétés : -ia … -iie)
51-AAA-j. Langues dites « franco-provençales » ou Arpitan (nommées « Lyonnais+ Valdotain », avec 41 unités internes ou variétés : -jaa … -jfm)
Applications du « Registre » depuis 2000
- À partir de 2000, une collaboration s’est établie entre l’Observatoire linguistique et l’équipe des Langues du monde/Языки Мира à l’Institut de Linguistique de l’Academie des Sciences Russe, y compris un échange de visites de chercheurs (Moscou/Pays de Galles en 2001). Voir la discussion en russe et en anglais par Yura Koryakov & Timur Maisak sur la méthodologie du Registre de la Linguasphère (Реестру Лингвосферы), dans le contexte de l’étude et de la cartographie des langues caucasiennes et romanes (Zones 42= & 51=). Cette discussion comprend une comparaison en russe des approches de l’Ethnologue du SIL et du Registre de l’Observatoire[13].
- Le Registre et sa linguascale trouvent dès l’an 2000 une application dans l'étude d'un environnement urbain linguistiquement complexe - les Langues de Londres/Languages of London. Cette étude fournit le cadre de référence pour des enquêtes successives de plus de 200 langues (autres que l'anglais) parlées par les enfants plurilingues dans les écoles municipales de Londres (représentant un peu moins de 40 % du nombre total d'enfants scolarisés dans la capitale britannique). Voir les rapports de recherche publiés en 2000 par Philip Baker & John Eversley[14] et en 2010 by John Eversley et al.[15] La première de ces deux études (Multilingual Capital, p.3) enregistre le fait que la première de ces enquêtes linguistiques à Londres a débuté comme élément d'un programme de cartographie linguistique lancé conjointement en 1993 par l'Observatoire et la School of Oriental and African Studies de Londres (David Dalby & Tony Allan).
- Entre 2001 et 2005, l’Observatoire Linguistique s’est impliqué activement, en collaboration avec la BSI (British Standards Institution) et avec ISO/TC 37 dans l’élaboration d’un code de quatre lettres (alpha-4) qui recouvrirait — potentiellement — toutes les variétés de langages répertoriées dans le monde. L’Observatoire n’a pas été, cependant, associé à ou responsable de la norme finale ISO 639-6, approuvée et publiée par l’ISO en 2009, qui fut un résultat partiel de cette collaboration. La politique d'indépendance de l’Observatoire le conduit à poursuivre sa propre codification du langage, en parallèle et de façon complémentaire aux travaux de l’ISO sur les normes linguistiques internationales nommées ISO 639.
« Dans la galaxie des langues, la voix de chaque personne est une étoile »
La devise de l’Observatoire linguistique est créée en 1990, à l'occasion du premier d'une série de débats sur le thème de Nos Langues et l’Unité de l’Europe[16], animée par l’Observatoire en 1990-1991 à Fleury-sur-Andelle en Haute-Normandie, à Maillane en Provence et à Huy en Wallonie, grâce au soutien des trois régions concernées. L’invité d’honneur au premier débat est André Martinet (1908-1999), doyen de la linguistique transatlantique.
En 1994, la devise de l'Observatoire apparaît dans une présentation plurilingue romane :
Dans la galaxie des langues, la voix de chaque personne est une étoile.
Nella galaxia delle lingue, la vox di ogni persona è una stella[17].La devise de l’Observatoire linguistique est plus tard adoptée, et adaptée, par l’Unesco (« Dans la galaxie des langues, chaque mot est une étoile », traduite en 2000 dans plus de 60 langues parlées par le personnel international de l’Unesco à Paris). Cette version de la devise est utilisée comme slogan de la Journée internationale de la langue, le 21 février 2002, représentée dans de nombreuses langues sur une affiche multicolore de l'Unesco, et par la suite adoptée comme devise (en anglais) pour plusieurs programmes linguistiques en Asie[18].
« Langues de la Liberté/Languages of Liberty »
Pour le bicentenaire de la Révolution française en 1989, l’Observatoire linguistique crée une exposition bilingue Langues de la Liberté / Languages of Liberty, qui retrace la diffusion transnationale des principes de la liberté individuelle grâce à l’interaction sur tous les continents de deux langues pourtant impériales et rivales, le français et l’anglais. Au début d'une série de 34 triptyques illustrés, l'attention est attirée sur le rôle historique d'autres langues transnationales dans le développement de ces mêmes principes, y compris le grec et l'allemand[19].
Cette exposition est parrainée par le gouvernement du Canada, ainsi que par l’Agence internationale de la francophonie (l'ACCT) et par la Région de Haute-Normandie. Elle est inaugurée le 6 juin 1989 au Centre Georges-Pompidou à Paris, où elle reste pendant l’été 1989 en tant que contribution officielle du Canada à la célébration du bicentenaire de la Révolution française. Le poète et romancier québécois Émile Martel, alors ministre à l'ambassade du Canada à Paris, a joué un rôle central dans l’encouragement et le soutien de cette exposition bilingue.
Lors de la présentation ultérieure de l'exposition à l’Hôtel de Région à Rouen (Haute-Normandie) du 23 septembre au 21 octobre 1989, l’Observatoire linguistique et la Bibliothèque publique de Rouen organisent la première présentation publique de l’unique copie en langue vernaculaire de la Grande Charte d’Angleterre ou Magna Carta, conservée en Normandie. Cette formulation légale en français du XIIIe siècle, jusqu'à 1989 peu connue, est la source vraisemblable du texte formel de la Grande Charte en latin[20].
Grâce au soutien continu du gouvernement canadien, l’exposition est ensuite présentée par l’Observatoire linguistique en Belgique, au Palais des Congrès à Liège, puis en Angleterre au "Commonwealth Institute" de Londres en 1990, et enfin en Australie, à "Old Parliament House" à Canberra en mai 1991.
Notes et références
- pendant le séjour à Québec de David Dalby, chercheur invité au Centre international de Recherches sur le bilinguisme à l'Université Laval en 1983, et à la suite de discussions au Centre impliquant et inspirées par les professeurs William Mackey, Jean-Denis Gendron et Lorne Laforge, et par Grant McConnell, directeur de recherche et des publications au Centre international de recherche en aménagement linguistique à Laval (voir les séries bilingues du Centre : Composition linguistiques des nations du monde et Les langues écrites du monde).
- La première cellule de recherche de l’Observatoire linguistique s’est établie à Cressenville en Haute-Normandie en décembre 1983. L’Association normande de l’Observatoire linguistique (« institut bilingue d’observation, de recherche et de publication au carrefour des langues, de l’éducation et des médias ») est créée le 5 février 1988, et ses statuts déposés le 8 février à la sous-préfecture des Andelys : voir le Journal officiel de la république française du 29 avril 1988, p.886.
- voir http://ouiaubreton.com pour la promotion de la langue bretonne, ainsi que http://daktu.plefeuvre.net, site d'information bilingue français-breton dont le Feuvre est cofondateur et développeur
- voir http://pactedeslangues.plefeuvre.net
- Roland Breton, Atlas des langues du monde, avec préface de Joshua A. Fishman, Éditions Autrement, Collection Atlas/Monde : Paris, 2003 (ISBN 2 7467 0400 5) ; suivi de Roland Breton, Atlas des minorités linguistiques dans le monde, Éditions Autrement, Collection Atlas/Monde : Paris, 2008 (ISBN 9782746710917)
- À partir de cette création de « l’Observatoire linguistique » (Linguasphere Observatory) dans les années 1980, au moins onze « observatoires linguistiques » sont créées avec titres en français, en Europe, au Canada ou mondialement, dont (suivant l’ordre de création) : 2. « l’Observatoire linguistique de l’Office de la Langue et la Culture d’Alsace » (1994, Elsassisches Sprochàmt); 3. « l’Observatoire linguistique, observatoire des politiques linguistiques en Europe » (1996, Association de l’Observatoire linguistique, Besançon); 4. « l'Observatoire des pratiques linguistiques de la DGLFLF » (1999, Direction générale de la langue française et des langues de France); 5. « l’Observatoire des indicateurs stratégiques sur les langues et les cultures dans la société de l'information » (2003, Organisation internationale de la Francophonie dans le cadre des “trois espaces linguistiques” espagnole, portugaise et française); 6. « l’Observatoire “économie, langues, formation” » (2003, Université de Genève); 7. « l’Observatoire de linguistique Sens-texte, OLST » (2004, Université de Montréal); 8. « l’Observatoire européen du plurilinguisme » (2005, Assises européennes du plurilinguisme); 9. « l’Observatoire des pratiques linguistiques de l’Office de la langue bretonne » (2010, Ofis ar Brezhoneg); 10. « l’Observatoire international des droits linguistiques » (2010, Université de Moncton); 11. « l’Observatoire sur le multilinguisme » (ouvert en 2012, Réseau européen des instituts culturels nationaux)
- http://www.linguasphere.info (voir Liens Externes ci-dessous)
- David Dalby, Le répertoire des langues : théorie et pratique dans Philippe Blanchet (éd.), Diversité linguistique, idéologie et pluralisme démocratique, Cahiers de l'Institut linguistique de Louvain (CILL) 18, 1-2, 1992, pp.141-182
- David Dalby, Les Langues de France et des pays et régions limitrophes au XXe siècle (essai de classification des langues et parlers endogènes de France, des Iles anglo-normandes, de Belgique et du Luxembourg, ainsi que des régions limitrophes en Espagne, Italie, Suisse, Allemagne et aux Pays-Bas, précédé d'une introduction théorique et pratique), l'Observatoire linguistique en association avec le Centre international des industries de la langue et du développement (université Paris-X) avec l'appui de l'Agence de coopération culturelle et technique: Cressenville, 1993 (ISBN 2 9502097 5 0)
- David Dalby, The Linguasphere Register of the World's Languages and Speech Communities (foundation edition), avec préfaces de Colin Williams de l'Université de Cardiff (tome 1) et de Roland Breton (tome 2), Gwasg y Byd Iaith pour l'Observatoire linguistique : Hebron, Wales, 1999-2000 (tome 1, 300 pp.) (ISBN 0 953291 9 1 X) & (tome 2, 743 p.) (ISBN 0 953291 9 2 8)
- Edward J. Vajda dans Language (Linguistic Society of America), Vol.77, 3 (septembre 2001) pp.606-608
- Anthony P.Grant dans Journal of Royal Anthropological Society (juin 2003)
- http://lingvarium.org/ (en russe)
- Philip Baker & John Eversley, Multilingual Capital: the languages of London’s schoolchildren and their relevance to economic, social & educational policies, Battlebridge for Corporation of London : London 2000 (ISBN 1 903292 00 X) (also Philip Baker & Jeehoon Kim, Global London, Battlebridge : London 2003 (ISBN 1 903292 09 3))
- John Eversley, Dina Mehmedbegović, Antony Sanderson, Teresa Tinsley, Michelle vonAhn & Richard D.Wiggins, Language Capital : Mapping the languages of London’s schoolchildren, CILT National Centre for Languages : London 2010 (ISBN 9781904243960)
- Philippe Blanchet (éd), Nos Langues et l'Unité de l'Europe : Actes des colloques de l'Observatoire Linguistique (Fleury-sur-Andelle & Maillane, 1990), avec préface d'André Martinet, Peeters pour l'Observatoire Linguistique et l'Institut de Linguistique de Louvain : Louvain-la-Neuve, 1992 [bilingue fr./provençal]
- Un repertorio de las lenguas del mundo / Un répertoire des langues du monde / Un repertorio delle lingue del mondo, micRomania (Belgique), 2.94, 1994, pp.3-17
- http://unesdoc.unesco.org/images/0011/001190/119098mo.pdf; http://www.unesco.org/education/imld_2002/imgs/imld_poster.pdf
- Les textes bilingues des triptyques de l'exposition sont présentés dans : David Dalby, Le Français et l'anglais : Langues de la Liberté, Observatoire linguistique et la Région de Haute-Normandie : Cressenville 1989 (ISBN 2 950209 74 2). Voir également : Langues des Droits de l'Homme / Languages of the Rights of Man, catalogue de l'exposition Français et l’anglais : Langues de la Liberté (bilingue) avec Introduction par SE Claude T. Charland, Ambassadeur du Canada en France, Observatoire linguistique et Bibliothèque publique d'Information du Centre Georges Pompidou : Cressenville et Paris : 1989 (ISBN 2 950209 73 4)
- L’Observatoire envisage de revenir au thème de la Grande Charte d'Angleterre en 2015, à l’occasion du 8e centenaire de la promulgation de sa version latine à Runnymede sur la Tamise en 1215. contact@linguasphere.info
Liens externes
- Site officiel avec accès au codage des langues du monde (comprenant 32 800 noms de référence et plus de 70 900 noms linguistiques) et les textes d'origine en anglais du Registre Linguasphère (LSR1).