Noyau polynomial
En apprentissage automatique, le noyau polynomial est une fonction noyau couramment utilisée avec les machines à vecteurs de support (SVMs) et d'autres modèles à noyaux. Il représente la similarité des vecteurs (échantillons d'apprentissage) dans un espace de degré polynomial plus grand que celui des variables d'origine, ce qui permet un apprentissage de modèles non-linéaires.
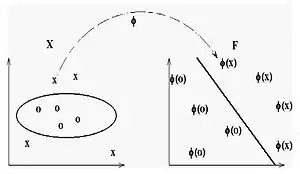




Intuitivement, le noyau polynomial ne tient pas compte uniquement des propriétés des échantillons d'entrée afin de déterminer leur similitude, mais aussi des combinaisons de ceux-ci. Dans le contexte de l'analyse de régression, de telles combinaisons sont connues comme les fonctionnalités d'interaction. L'espace caractéristique (implicite) d'un noyau polynomial est équivalent à celui de la régression polynomiale, mais sans l'explosion combinatoire du nombre de paramètres à apprendre. Lorsque les caractéristiques d'entrées sont des valeurs binaires (booléens), alors les caractéristiques correspondent à la conjonction logique des caractéristiques d'entrée[1].
Définition
Pour un polynôme de degré d, le noyau polynomial est défini comme[2] :

où x et y sont des vecteurs dans l' espace d'entrée, c'est-à-dire des vecteurs de caractéristiques calculées à partir d'échantillons d'apprentissage ou de test, et c ≥ 0 est un paramètre libre équilibrant l'influence des termes d'ordre supérieur par rapport aux termes d'ordre inférieur dans le polynôme. Lorsque c = 0, le noyau est appelé homogène[3]. (Un noyau polynomial plus généralisé divise xTy par un paramètre scalaire a spécifié par l'utilisateur[4].)
Comme noyau, K correspond à un produit scalaire dans un espace caractéristique basée sur une certaine application Φ :

La nature de Φ peut être vue à partir d'un exemple. Soit d = 2, nous obtenons donc le cas particulier du noyau quadratique. Après avoir utilisé le théorème multinôme de Newton (deux fois de l'application externe est le théorème du binôme de newton) et le regroupement,

il resulte que la fonctionnalité de l'application est donnée par :

Utilisation pratique
Bien que le noyau RBF soit plus populaire dans la classification SVM que le noyau polynomial, ce dernier est très populaire dans le traitement automatique du langage naturel (NLP)[1] - [5]. Le degré le plus commun est d = 2 (quadratique), car les grands degrés tendent à surapprendre sur les problèmes de NLP.
Différentes manières de calculer le noyau polynomial (à la fois exacte et approchée) ont été conçues comme des alternatives à l'usage des algorithmes de formation SVM non-linéaire, y compris :
- la pleine expansion du noyau avant l'apprentissage/test avec un SVM linéaire[5], c'est-à-dire le calcul complet de l'application Φ comme dans la régression polynomiale ;
- Règle d'association (à l'aide d'une variante de l'algorithme apriori) pour les plus fréquentes conjonctions de fonctionnalité en un ensemble de formation afin de produire une évaluation approximative de l'expansion[6] ;
- Index inversé des vecteurs de support[6] - [1].
Un problème avec le noyau polynomial est qu'il peut souffrir d'instabilité numérique : lorsque xTy + c < 1, K(x, y) = (xTy + c)d tend vers zéro avec l'augmentation de d, alors que quand xTy + c > 1, K(x, y) tend vers l'infini[4].
Références
- Yoav Goldberg and Michael Elhadad (2008). splitSVM: Fast, Space-Efficient, non-Heuristic, Polynomial Kernel Computation for NLP Applications. Proc. ACL-08: HLT.
- http://www.cs.tufts.edu/~roni/Teaching/CLT/LN/lecture18.pdf
- (en) Auteur inconnu, « Introduction to Machine Learning: Class Notes 67577 », .
- (en) Chih-Jen Lin « Machine learning software: design and practical use » () (lire en ligne)
—Machine Learning Summer School - (en) Yin-Wen Chang, Cho-Jui Hsieh, Kai-Wei Chang, Michael Ringgaard et Chih-Jen Lin, « Training and testing low-degree polynomial data mappings via linear SVM », Journal of Machine Learning Research, vol. 11, , p. 1471–1490 (lire en ligne)
- (en) T. Kudo et Y. Matsumoto « Fast methods for kernel-based text analysis » ()
—Proc. ACL