Lempel-Ziv-Welch
LZW (pour Lempel-Ziv-Welch) est un algorithme de compression de données sans perte. Il s'agit d'une amélioration de l'algorithme LZ78 inventé par Abraham Lempel et Jacob Ziv en 1978. LZW fut créé en 1984 par Terry Welch, d'où son nom.
L'algorithme LZW avait été breveté par la société Unisys[1] (un brevet logiciel valable uniquement aux États-Unis). Il a été utilisé dans les modems (norme V42 bis) et est encore utilisé dans les formats d'image numérique GIF ou TIFF et les fichiers audio MOD.
L’algorithme est conçu pour être rapide à coder, mais n’est la plupart du temps pas optimal car il effectue une analyse limitée des données à compresser.
Description de l'algorithme
L’algorithme de compression construit une table de traduction de chaînes de caractères à partir du texte à compresser. Cette table relie des codes de taille fixée (généralement 12 bits) aux chaînes de caractères. La table est initialisée avec tous les caractères (256 entrées dans le cas de caractères codés sur 8 bits). À mesure que le compresseur examine le texte, il ajoute chaque chaîne de 2 caractères dans la table en tant que concaténation de code et de caractères, avec le code correspondant au premier caractère de la chaîne. En même temps qu’il enregistre ces chaînes, le premier caractère est envoyé en sortie. Chaque fois qu’une chaîne déjà rencontrée est lue, la chaîne la plus longue déjà rencontrée est déterminée, et le code correspondant à cette chaîne avec le caractère concaténé (le caractère suivant du flux entrant) est enregistré dans la table. Le code pour la partie la plus longue de la chaîne de caractères rencontré est envoyé en sortie et le dernier caractère est utilisé comme base pour la chaîne suivante.
L’algorithme de décompression a seulement besoin du texte compressé en entrée. En effet il reconstruit une table chaîne de caractères / code identique à mesure qu’il régénère le texte original. Cependant un cas inhabituel apparaît chaque fois que la séquence caractère/chaîne/caractère/chaîne/caractère (avec le même caractère pour chaque caractère et la même chaîne de caractères pour chaque chaîne) est rencontrée en entrée et que caractère/chaîne est déjà présent dans la table. Quand l’algorithme de décompression lit le code pour caractère/chaîne/caractère, il ne peut pas le traiter car il n’a pas encore stocké ce code dans la table. Ce cas particulier peut être géré car le programme de décompression sait que le caractère supplémentaire est le précédent caractère rencontré[2].
Compression
Algorithme
FONCTION LZW_Compresser(Texte, dictionnaire)
w ← ""
TANT QUE (il reste des caractères à lire dans Texte) FAIRE
c ← Lire(Texte)
p ← Concaténer(w, c)
SI Existe(p, dictionnaire) ALORS
w ← p
SINON
Ajouter(p, dictionnaire)
Écrire dictionnaire[w]
w ← c
FIN TANT QUE
Exemple
La table suivante montre le résultat de l'exécution de l'algorithme de compression sur la chaîne suivante :
TOBEORNOTTOBEORTOBEORNOT
On suppose qu'on utilise un code ASCII de 256 caractères (8-bits) comme dictionnaire de base. La longueur de cette chaîne est de 24 caractères. Elle nécessite donc 24 * 8 = 192 bits d'espace de stockage.
| w | c | wc | sortie | dictionnaire |
|---|---|---|---|---|
| T | T | |||
| T | O | TO | T | TO = <256> |
| O | B | OB | O | OB = <257> |
| B | E | BE | B | BE = <258> |
| E | O | EO | E | EO = <259> |
| O | R | OR | O | OR = <260> |
| R | N | RN | R | RN = <261> |
| N | O | NO | N | NO = <262> |
| O | T | OT | O | OT = <263> |
| T | T | TT | T | TT = <264> |
| T | O | TO | ||
| TO | B | TOB | <256> | TOB = <265> |
| B | E | BE | ||
| BE | O | BEO | <258> | BEO = <266> |
| O | R | OR | ||
| OR | T | ORT | <260> | ORT = <267> |
| T | O | TO | ||
| TO | B | TOB | ||
| TOB | E | TOBE | <265> | TOBE = <268> |
| E | O | EO | ||
| EO | R | EOR | <259> | EOR = <269> |
| R | N | RN | ||
| RN | O | RNO | <261> | RNO = <270> |
| O | T | OT | ||
| OT | <263> |
Après la compression, nous obtenons une séquence de codes de 9 bits sur la sortie :
TOBEORNOT<256><258><260><265><259><261><263>
Elle nécessite 16 × 9 = 144 bits d'espace de stockage, au lieu des 192 bits de la chaine originale.
Exemple de compression
Cet exemple est construit avec {a,b,c} comme alphabet de base, ce qui donne un dictionnaire de taille 3 au début de la compression ou de la décompression (tableau indicé de 0 à 2).
On prend comme chaîne à compresser ababcbababaaaaaaa. Le déroulement de la compression sur cet exemple simple est détaillé dans les images ci-dessous.


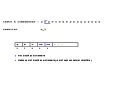
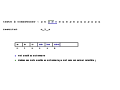







Décompression
Algorithme
FONCTION LZW_Décompresser(Code, dictionnaire)
n ← |Code|
v ← Lire(Code)
Écrire dictionnaire[v]
w ← chr(v)
POUR i ALLANT DE 2 à n FAIRE
v ← Lire(Code)
SI Existe(v, dictionnaire) ALORS
entrée ← dictionnaire[v]
SINON entrée ← Concaténer(w, w[0])
Écrire entrée
Ajouter(Concaténer(w,entrée[0]), dictionnaire)
w ← entrée
FIN POUR
Exemple
Le résultat de l'algorithme de décompression, sur la séquence compressée de codes de 9 bits, est présenté dans ce tableau :
TOBEORNOT<256><258><260><265><259><261><263>
| c | w | entrée | w+entrée[0] | sortie | dictionnaire |
|---|---|---|---|---|---|
| T | T | T | |||
| O | T | O | TO | O | TO = <256> |
| B | O | B | OB | B | OB = <257> |
| E | B | E | BE | E | BE = <258> |
| O | E | O | EO | O | EO = <259> |
| R | O | R | OR | R | OR = <260> |
| N | R | N | RN | N | RN = <261> |
| O | N | O | NO | O | NO = <262> |
| T | O | T | OT | T | OT = <263> |
| <256> | T | TO | TT | TO | TT = <264> |
| <258> | TO | BE | TOB | BE | TOB = <265> |
| <260> | BE | OR | BEO | OR | BEO = <266> |
| <265> | OR | TOB | ORT | TOB | ORT = <267> |
| <259> | TOB | EO | TOBE | EO | TOBE = <268> |
| <261> | EO | RN | EOR | RN | EOR = <269> |
| <263> | RN | OT | RNO | OT | RNO = <270> |
Exemple de décompression
À chaque étape on décode le code en cours de décompression:on cherche la chaîne correspondante dans le dictionnaire et on la concatène au résultat déjà obtenu. Puis on concatène la chaîne décodée juste avant(en rouge) avec la première lettre de la chaîne qui vient d'être décodée(en vert) et on l'ajoute au dictionnaire si c'est un nouveau mot.
Pour certaines étapes de la décompression(code 7, 9 et 10) on sera dans le cas particulier où le code à décompresser n'est pas encore dans le dictionnaire. Dans ce cas, comme expliqué dans l'article, on prend la chaîne de caractère décodé juste avant(en rouge) et on le concatène avec son premier caractère pour obtenir la chaîne correspondante au code en cours de décompression et le mot à ajouter au dictionnaire.
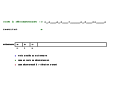
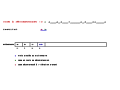
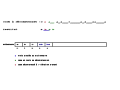
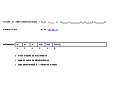

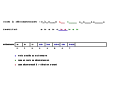



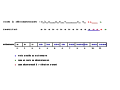
Codes spéciaux
Des codes spéciaux peuvent exister selon les applications, par exemple pour signaler la fin du flux de données (code <257> pour la compression LZW des images TIF), pour effectuer un nettoyage partiel du dictionnaire, etc.
Accroissement de la taille des codes
Lorsque le dictionnaire s'agrandit, le numéro des codes finit par dépasser la limite du nombre de bits permettant leur écriture. Le codeur augmente alors le nombre de bits écrits par code. Par exemple, avec la largeur de 9 bits par code de l'exemple ci-dessus, la première augmentation de largeur sera nécessaire à l'ajout de la 511e entrée dans le dictionnaire. Le décodeur procèdera de même lorsqu'il ajoutera la 511e entrée dans son dictionnaire. L'augmentation se reproduit à chaque franchissement des puissances de 2 (1023, 2047, …).
Accroissement de la taille du dictionnaire
Afin d'éviter au dictionnaire de croître démesurément (le nombre de bit à écrire par code devient rédhibitoire pour conserver une compression efficace) il peut être prévu un nombre d'entrées maximum dans le dictionnaire. Lorsque ce nombre est atteint, le codeur insère un code spécial et vide complètement le dictionnaire. Le processus de codage recommence alors comme pour le premier caractère. Le décodeur purgera son dictionnaire quand il rencontrera ce code spécial.
Ce code spécial est la valeur <256> pour la compression LZW des images TIF, et est exclu des entrées « normales » des dictionnaires
Notes et références
- Unisys: LZW Patent Information
- Welch, T. A. (June 1984). « A technique for high-performance data compression. », Computer, vol. 17, p. 8-19.
Voir aussi
Articles connexes
- Programmes associés