Données linguistiques liées ouvertes
Les Données Linguistiques Liées Ouvertes (Linguistic Linked Open Data -- LLOD) collectent et connectent des lexiques, des corpus, des ontologies linguistiques, des collections de métadonnées et d'autres ressources linguistiques ouvertes, en appliquant les principes du Web des Données liées.
Données Linguistiques Liées Ouvertes
Dans le Traitement automatique du langage naturel (TAL), en linguistique et dans les domaines connexes, les Données Linguistiques Liées Ouvertes décrivent une méthode et une communauté interdisciplinaire soucieuse de créer, partager et ré-utiliser les ressources linguistiques conformément aux principes du Web des Données liées.
L'Open Linguistics Working Group (OWLG) de l'Open Knowledge Foundation a conçu et maintient un catalogue de ces données sous forme d'un nuage de données linguistiques liées ouvertes qui est maintenant un point focal d'activité pour plusieurs groupes communautaires du W3C, projets de recherche et efforts d'infrastructure.
Les Données Linguistiques Liées Ouvertes réfèrent à la publication de données spécifiques à la linguistique et aux technologies du langage sur la base des principes suivants[1]:
- Selon la définition ouverte, les données doivent être sous licence open source, par exemple en utilisant des licences Creative Commons.
- Les éléments individuels d'un enregistrement de données doivent être clairement identifiés à l'aide d' identifiants uniformes de ressource (Uniform Resource Identifier URI).
- Les URI doivent pouvoir être résolus en tant qu'adresses Web afin que les utilisateurs puissent accéder à des informations supplémentaires à l'aide de navigateurs Web.
- L'accès de la machine à une ressource LLOD doit fournir des résultats basés sur des normes Web telles que le Resource Description Framework (RDF).
- Les données doivent maintenir des liens vers d'autres ressources pour permettre aux utilisateurs de trouver plus d'informations, telles que la signification des éléments du vocabulaire utilisé.
Les principaux avantages des Données Linguistiques Liées Ouvertes peuvent être résumés comme suit[2] :
- Représentation : Les graphes de connaissance liés constituent un format de représentation plus souple pour les données linguistiques.
- Interopérabilité : Les données basées sur des modèles RDF communs peuvent être facilement intégrés.
- Fédération : Les données provenant de plusieurs sources peuvent être facilement combinées.
- Écosystème : Les outils pour RDF et les données liées sont largement disponibles sous licence ouverte.
- Expressivité : L’existence de vocabulaires qui aident à exprimer les ressources linguistiques.
- Sémantique : Les hyperliens renvoyant à des ressources externes expriment clairement ce qui est signifié.
- Dynamique : L’accès aux données actualisées sur le Web est garanti.
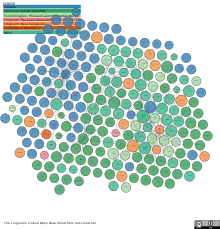
Une visualisation des données disponibles sous forme de LLOD est le diagramme de nuages LLOD actuellement disponible sur linguistic-lod.org[3]
Usage des Données Linguistiques Liées Ouvertes
Les Données Linguistiques Liées Ouvertes ont un champ d’application dans le cadre de divers domaines scientifiques:
- Dans toutes les branches de la linguistique empirique, de la philologie computationnelle et du traitement automatique du langage naturel, les annotations linguistiques et le balisage linguistique sont des éléments centraux du travail scientifique. Les progrès dans ces domaines sont cependant entravés par les problèmes d'interopérabilité résultant des différences de vocabulaire et de schémas utilisés par les différentes ressources langagières et les outils d'annotation ou d'analyse. La combinaison de ressources langagières avec des référentiels terminologiques et graphes de connaissances permet la réutilisation de vocabulaires communs et leur interprétation sur une base commune.
- En linguistique de corpus et en philologie informatique, les annotations qui se chevauchent représentent un problème notoire pour les formats XML conventionnels. Par conséquent, des modèles de données basés sur des graphes ont été proposés depuis la fin des années 1990[4]. Ceux-ci sont traditionnellement représentés au moyen de plusieurs fichiers XML interconnectés (annotations débarquées, XML standoff)[5], qui sont mal pris en charge par la technologie XML standard[6]. La modélisation d'annotations complexes telles que les données liées représente un formalisme sémantiquement équivalent au XML débarqué[7], mais élimine le besoin d'une technologie à usage spécifique et, à la place, s'appuie sur l'écosystème RDF existant.
- Ressources multilingues, y compris la mise en relation de ressources lexicales telles que WordNet telle que réalisée dans l'Index Interlingue de la Global WordNet Association[8] et l'interconnexion de ressources hétérogènes telles que WordNet et Wikipedia, comme cela a été fait dans BabelNet.
Les Données Linguistiques Liées Ouvertes sont par ailleurs étroitement associées au développement de:
- standards pour les ressources langagières, surtout en relation avec le vocabulaire OntoLex-Lemon (en), issu d'un Groupe Communautaire du W3C
- bonnes pratiques pour lier des données lexicales sur le web (pour les données publiées conformément aux conventions OntoLex)
- bonnes pratiques pour créer des annotations sur le Web (par exemple, en utilisant la norme d'annotation Web (en))
- bonnes pratiques pour la modélisation et le partage de ressources textuelles avec des balises qui se chevauchent
Une sélection de ressources présentes sur le nuage LLOD
En , les 10 ressources les plus fréquemment liées dans le diagramme LLOD sont (par ordre de nombre d'ensembles de données liés):
- Les ontologies de l'annotation linguistique (OLiA[9], liées à 74 ensembles de données) fournissent une terminologie de référence pour les annotations linguistiques et les métadonnées grammaticales;
- WordNet (lié à 51 ensembles de données), une base de données lexicale pour l'anglais et pivot pour développer des bases de données similaires pour d'autres langues, avec plusieurs éditions (édition Princeton liée à 36 ensembles de données; édition W3C liée à 8 ensembles de données; édition Université libre d'Amsterdam liée à 7 ensembles de données);
- DBpedia (lié à 50 ensembles de données) base de connaissances multilingue de connaissances mondiales générales, basée sur Wikipedia;
- lexinfo.net[10] (lié à 36 jeux de données) fournit une terminologie de référence pour les ressources lexicales;
- BabelNet (lié à 33 jeux de données) réseau sémantique lexicalisé multilingue, basé sur l'agrégation de diverses autres ressources, notamment WordNet et Wikipedia;
- lexvo.org[11] (lié à 26 jeux de données) fournit des identificateurs de langue et d'autres données liées à la langue. Plus important encore, lexvo fournit une représentation RDF des codes ISO 639-3 à 3 lettres pour les identificateurs de langue et des informations sur ces langues;
- Le registre des catégories de données ISO 12620 (ISOcat; édition RDF, lié à 10 ensembles de données) fournit un référentiel semi-structuré pour diverses terminologies liées au langage. ISOcat est hébergé par The Language Archive, respectivement, le projet DOBES (en), à l'Institut Max Planck de psycholinguistique, mais actuellement en transition vers CLARIN;
- UBY (en) (édition RDF lemon-Uby, liée à 9 ensembles de données), un réseau lexical pour l'anglais, agrégé à partir de diverses ressources lexicales;
- Glottolog (lié à 7 ensembles de données) fournit des identificateurs de langue à grain fin pour les langues à faibles ressources, en particulier, beaucoup non couvertes par lexvo.org;
- Liens Wiktionary-DBpedia (wiktionary.dbpedia.org, lié à 7 jeux de données), lexicalisations basées sur le Wiktionnaire pour les concepts DBpedia.
- DBnary version RDF de 23 éditions des Wiktionnaires, qui remplace maintenant la ressource précédente, abandonnée par les fondateurs de DBpedia.
Développements et Activités Communautaires
Le diagramme montrant le nuage de données linguistiques liées ouvertes (LLOD) est maintenu par l'Open Linguistics Working Group (OWLG) de l'Open Knowledge Foundation (depuis 2014 Open Knowledge), une équipe ouverte et interdisciplinaire d'experts en ressources linguistiques. Le OWLG organise des événements communautaires et coordonne les développements du LLOD et facilite la communication interdisciplinaire entre et parmi les contributeurs et les utilisateurs du LLOD. Plusieurs groupes d'entreprises et de communautés du W3C se concentrent sur des aspects spécialisés du LLOD:
- Le groupe communautaire W3C Ontology-Lexica (OntoLex) développe et maintient des spécifications pour les dictionnaires numériques et autres ressources linguistiques dans le nuage LLOD.
- Le "W3C Best Practices for Multilingual Linked Open Data Community Group" rassemble des informations sur les bonnes pratiques de production de données ouvertes multilingues liées[12].
- Le groupe communautaire des données liées du W3C pour les technologies linguistiques rassemble des cas d'utilisateurs et des exigences pour les applications de technologies linguistiques qui utilisent des données liées[13].
Le développement du LLOD est stimulé et documenté par une série d'ateliers internationaux, de datathons et de publications associées. Pour en nommer quelques-uns:
- Linked Data in Linguistics (LDL), atelier scientifique, commencé en 2012. La 7e édition en 2020.
- Données ouvertes multilingues liées aux entreprises (MLODE), réunion communautaire (2012, 2014, 2020)
- Datathon d'été sur les données ouvertes liées linguistiques (SD-LLOD), organisés en 2015, 2017 et 2019. Prochaine édition en 2021.
Les utilisations et le développement du LLOD ont fait l'objet de plusieurs projets de recherche, dont:
- LOD2. Creating Knowledge out of Interlinked Data (11 pays européens + Corée du Sud, 2010–2014)[14]
- MONNET. Multilingual Ontologies for Networked Knowledge (5 pays européens, 2010–2013)[15]
- LIDER. Linked Data as an enabler of cross-media and multilingual content analytics for enterprises across Europe (5 pays européens, 2013–2015)[16]
- LiODi. Linked Open Dictionaries (BMBF eHumanities Early Career Research Group, Goethe University Frankfurt, Germany, 2015-2020)[17]
- FREME. Open Framework of E-Services for Multilingual and Semantic Enrichment of Digital Content (6 pays européens, 2015-2017)[18]
- POSTDATA. Poetry Standardization and Linked Open Data (ERC Starting Grant, UNED, Spain, 2016-2021)[19]
- Linking Latin (ERC Consolidator Grant, Universita Cattolica del Sacro Cuore, Italy, 2018-2023)[20]
- ELEXIS -- European Lexicographic Infrastructure (2018-2021)[21]
- Prêt-à-LLOD (5 pays européens, 2019-2021)[22]
- NexusLinguarum. European network for Web-centred linguistic data science (COST Action, 35 pays "COST" + 3 autres pays, 2019-2023) [23]
Notes et références
- (en) « The Linguistic Linked Open Data Cloud from lod-cloud.net », (consulté le )
- Christian Chiarcos, John McCrae, Philipp Cimiano et Christiane Fellbaum, Towards open data for linguistics: Lexical Linked Data, Heidelberg, In: Alessandro Oltramari, Piek Vossen, Lu Qin, and Eduard Hovy (eds.), New Trends of Research in Ontologies and Lexical Resources. Springer, (lire en ligne)
- (en) « The Linguistic Linked Open Data Cloud from lod-cloud.net. » (consulté le )
- (en) Steven Bird et Mark Liberman, « Towards a formal framework for linguistic annotations », In: Proceedings of the International Conference on Spoken Language Processing, Sydney, 1998 (consulté le )
- (en) ISO 24612:2012, « Language resource management -- Linguistic annotation framework (LAF) », ISO (consulté le )
- (en) Richard Eckart, Choosing an XML database for linguistically annotated corpora, SDV. Sprache und Datenverarbeitung 32.1/2008: International Journal for Language Data Processing, Workshop Datenbanktechnologien für hypermediale linguistische Anwendungen (KONVENS 2008), Universitätsverlag Rhein-Ruhr, Berlin, Sep 2008, , 7–22 p. (lire en ligne)
- (en) Christian Chiarcos, « Interoperability of Corpora and Annotations », In: Christian Chiarcos, Sebastian Nordhoff, and Sebastian Hellmann (eds.) Linked Data in Linguistics. Representing and Connecting Language Data and Language Metadata, 2012 (consulté le )
- (en) The Global WordNet Association, « globalwordnet.org », globalwordnet.org, (consulté le )
- (en) « OLiA. » (consulté le )
- (en) « lexinfo.net » (consulté le )
- (en) « lexvo.org » (consulté le )
- (en) « Best Practices for Multilingual Linked Open Data Community Group » (consulté le )
- (en) « Linked Data for Language Technology Community Group » (consulté le )
- « lod2.okfn.org (archived version) » (consulté le )
- « Multilingual Ontologies for Networked Knowledge (Monnet) », European Commission, CORDIS EU research results (consulté le )
- « LIDER: Linked Data as an enabler of cross-media and multilingual content analytics for enterprises across Europe », European Commission, CORDIS EU research results (consulté le )
- « Linked Open Dictionaries (LiODi) » (consulté le )
- « Open Framework of E-Services for Multilingual and Semantic Enrichment of Digital Content » (consulté le )
- « POSTDATA – Poetry Standardization and Linked Open Data » (consulté le )
- « Linking Latin. Building a Knowledge Base of Linguistic Resources for Latin » (consulté le )
- « ELEXIS project home page » (consulté le )
- « Pret-a-LLOD project home page » (consulté le ) « Pret-a-LLOD », European Commission, CORDIS EU research results (consulté le )
- « CA18209 - European network for Web-centred linguistic data science », cost. European Cooperation in Science and Technology (consulté le )
{kind=link}
Articles connexes
- Traitement automatique des langues
- Web des données
- Open Knowledge Foundation
- World Wide Web Consortium
- Lexical markup framework (LMF), travaux de normalisation ISO des lexiques du TAL
- OntoLex (en), un vocabulaire pour les ressources lexicales dans le web de données (OntoLex-Lemon) et le nom abrégé du groupe communautaire W3C qui l'a créé (W3C Ontology-Lexica Community Group).