Document Object Model
Le Document Object Model (DOM) est une interface de programmation normalisée par le W3C, qui permet à des scripts d'examiner et de modifier le contenu du navigateur web[1]. Par le DOM, la composition d'un document HTML ou XML est représentée sous forme d'un jeu d'objets – lesquels peuvent représenter une fenêtre, une phrase ou un style, par exemple – reliés selon une structure en arbre[1]. À l'aide du DOM, un script peut modifier le document présent dans le navigateur en ajoutant ou en supprimant des nœuds de l'arbre[1].
| Dépôt | github.com/whatwg/dom |
|---|---|
| Type |
Modèle Interface de programmation |
| Licence | Creative Commons Attribution 4.0 International (d) |
| Site web | dom.spec.whatwg.org |
Description
Document Object Model (DOM) signifie « modèle d'objets de document »[2].
- Modèle
- Un modèle sert à représenter quelque chose, comme le plan d'une ville. Le DOM représente le document qui se trouve dans le navigateur[2].
- Objet
- En programmation, un objet est un conteneur qui comporte des propriétés et des méthodes – qui sont des variables et des actions concernant ce qu'il représente[2]. Les objets du DOM peuvent représenter une fenêtre, un document, une phrase, un style…[1]
- Document
- Le DOM concerne un document, tel qu'une page web affichée dans un navigateur[2]. Une page web commence par une balise
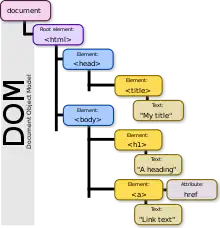
!DOCTYPEsuivi de la balise<html>dans laquelle se trouve le reste du document[2]. Le DOM représente le document affiché par une structure en arbre, comportant des nœuds (branches et feuilles)[2].
Histoire
À l'origine, le DOM (niveau 0, legacy) était un ensemble d'objets mis à disposition par Netscape Navigator, dont la version 4 parut en . Internet Explorer 4 suivit en octobre la même année. Ces deux navigateurs intégraient le support du DHTML[2], lequel requérait des extensions alors offertes par le DOM rudimentaire d'alors. Le document pouvait désormais être manipulé à travers le DOM ; cependant le même document n'était pas représenté de la même manière par les deux navigateurs. Ce problème a progressivement disparu avec l'adoption du DOM normalisé par le W3C[2]. Le DOM (niveau 4) est aujourd'hui incorporé dans la norme HTML5[1].
Mise en œuvre
La spécification du W3C stipule les objets ainsi que les méthodes et les propriétés qu'un navigateur web doit impérativement mettre à disposition[1].
Les principales catégories d'objet d'un arbre DOM sont le document, les éléments et les attributs[1] :
documentexpose les informations concernant l'ensemble du document HTML ainsi que la balise<html>[1] .- chaque
elementexpose une balise d'un document HTML ou XML, et comporte une propriétéattributesqui expose les attributs de la balise. Chaque élément comporte des méthodes permettant d'accéder aux éléments parent, enfant et frères de l'arbre DOM[1] . - chaque
textcontient le texte qui se trouve à l'intérieur d'une balise[1] .
Chaque navigateur met en œuvre le DOM dans son langage de programmation. La spécification du DOM est alignée avec le langage JavaScript, reconnu par tous les navigateurs web[1]. N'importe quelle partie d'une page web peut ainsi être modifiée par programmation, et le programme fonctionnera sur n'importe quel navigateur web conforme à la norme DOM[1].
Techniquement le DOM permet de lire et modifier n'importe quel document utilisant des balises, avec n'importe quel langage de programmation qui offre une interface de programmation DOM[2].
Évolution du DOM au sein des navigateurs web

Avant sa standardisation par le W3C, chaque navigateur web disposait de son propre Document Object Model. Si le langage de base destiné à manipuler les documents web a vite été standardisé autour de JavaScript, il n'en a pas été de même pour la série précise de fonctions à utiliser et la manière de parcourir le document. Par exemple, lorsque Netscape Navigator préconisait de parcourir un tableau indexé nommé document.layers[], Internet Explorer l'appelait plutôt document.all[], et ainsi de suite. En pratique, cela obligeait à écrire (au moins) deux versions de chaque morceau de script si l'on voulait rendre son site accessible au plus grand nombre.
La standardisation de ces techniques s'est faite en plusieurs étapes, lesquelles étendent chaque fois les possibilités précédentes sans jamais les remettre en cause.
DOM 1
La première est le DOM Level 1 publié en 1998 (le niveau 0 étant considéré comme l'implémentation de base figurant dans Netscape Navigator 2.0), où le W3C a défini une manière précise de représenter un document (en particulier un document XML) sous la forme d'un arbre. Chaque élément généré à partir du balisage comme, dans le cas de HTML, un paragraphe, un titre ou un bouton de formulaire, y forme un nœud. Est également définie une série de fonctions permettant de se déplacer dans cet arbre, d'y ajouter, modifier ou supprimer des éléments. En plus des fonctions génériques applicables à tout document structuré, des fonctions particulières ont été définies pour les documents HTML, permettant par exemple la gestion des formulaires. Le DOM Level 1 a été disponible dans sa plus grande partie dès les premières versions d'Internet Explorer 5 et de Netscape 6.
DOM 2
La seconde étape est le DOM Level 2 (publié en 2000), à présent constitué de six parties (en plus de Core et HTML, on trouvera Events, Style, View et Traversal and Range). Dans les évolutions de la brique de base (Core), on notera la possibilité d'identifier plus rapidement un nœud ou un groupe de nœuds au sein du document. Ainsi, pour obtenir un élément particulier on ne le recherchera plus dans un tableau comme dans les DOM propriétaires précédents, mais on appellera la fonction getElementById().
DOM 3
Le troisième niveau, publié au printemps 2004[3], a ajouté :
- le support de XPath,
- la gestion d'événements clavier,
- une interface de sérialisation de documents XML.
DOM 4
Le quatrième niveau a été publié en décembre 2015. Sa dernière mise à jour date de décembre 2020[4]
Aspects techniques
DOM permet de représenter la structure d'un document et de ses éléments sous forme d'un arbre. Il est donc préférable de parcourir et de mémoriser l'intégralité du document avant de pouvoir effectuer les traitements voulus. Pour cette raison, les programmes utilisant DOM ont souvent une empreinte mémoire volumineuse en cours de traitement. À l'inverse, à partir d'un arbre DOM donné, il est possible de générer des documents dans le langage de balisage voulu, qui pourront à leur tour être manipulés par l'interface DOM.
DOM est utilisé pour pouvoir modifier facilement des documents XML ou accéder au contenu des pages web. Dans les cas ne nécessitant pas de manipuler les documents XML, mais juste de les lire, la méthode SAX peut également être choisie car elle traite les éléments de façon successive sans charger le document en mémoire. Elle s'impose quand la taille du document excède la capacité de la mémoire.
Événements
La capture d'un événement consiste à exécuter une action (par exemple un programme en JavaScript) lorsque l'événement surveillé se produit dans le document. Les événements capturables du DOM sont[5] :
Événements page et fenêtre
onabort— s'il y a une interruption de chargementonerror— en cas d'erreur pendant le chargement de la pageonload— après la fin du chargement de la pageonbeforeunload— se produit juste avant de décharger la page en cours (par changement de page, en quittant)onunload— se produit lors du déchargement de la page (par changement de page, en quittant)onresize— quand la fenêtre est redimensionnée
Événements souris
onclick— sur un simple clicondblclick— sur un double cliconmousedown— lorsque le bouton de la souris est enfoncé, sans forcément le relâcheronmousemove— lorsque le curseur est déplacéonmouseout— lorsque le curseur sort de l'élémentonmouseover— lorsque le curseur se trouve sur l'élémentonmouseup— lorsque le bouton de la souris est relâchéonscroll— lorsque le scroll de la souris est utilisé
Événements clavier
onkeydown— lorsqu'une touche est enfoncéeonkeypress— lorsqu'une touche est pressée et relâchéeonkeyup— lorsqu'une touche est relâchée
Événements formulaire
onblur— à la perte du focusonchange— à la perte du focus, si la valeur a changéonfocus— lorsque l'élément obtient le focus (ou devient actif)onreset— lors de la remise à zéro du formulaire via un bouton ou une fonctionreset()onselect— quand du texte est sélectionnéonsubmit— quand le formulaire est validé via un bouton ou une fonctionsubmit()
Notes et références
- (en)Paul S. Wang, Dynamic Web Programming and HTML5, CRC Press, 2012, (ISBN 9781439871829)
- (en) Jeremy Keith et Jeffrey Sambells, DOM Scripting: Web Design with JavaScript and the Document Object Model, Apress - 2010, (ISBN 9781430233893)
- « Document Object Model (DOM) Level 3 Core Specification », sur w3.org (consulté le ).
- (en) « DOM », sur w3.org (consulté le ).
- « Document Object Model (DOM) Level 3 Events Specification », W3C, .
Liens externes
- (en) Site officiel
- (fr) Référence du DOM en français sur MDN
- (fr) Traduction française de la recommandation DOM Level 1 du W3C
- (fr) Traduction française des recommandations DOM Level 2 du W3C.
- (en) Introduction au DOM W3C, sur le site Quirksmode.org
- (en) Gecko DOM Reference, référence combinée sur DOM Level 1 et 2