Cooccurrence
La cooccurrence[1] est la présence simultanée de plusieurs mots ou autres unités linguistiques dans le même énoncé, par exemple la phrase, le paragraphe, l'extrait.
Des disciplines comme l'histoire ou la géographie s'intéressent aussi à la cooccurrence de mots ou noms de lieu dans le temps et l'espace.
Un concept proche est la collocation, qui est une forme d'expression idiomatique causée par une cooccurrence systématique.
Éléments de définition
Le mot « cooccurrence » peut avoir plusieurs sens[2].
Pour le Larousse, il s'agit de l'apparition dans un même énoncé de plusieurs éléments linguistiques distincts, et de la relation entre ces éléments. Dans la phrase Le chien mange, chien est en relation de cooccurrence avec le et mange. La co-présence de ces deux mots et leur association construit le sens de la phrase (le tout devient plus que la somme des parties).
De manière générale, il peut s'agir de la présence simultanée de deux ou de plusieurs mots (ou autres unités linguistiques) dans un même énoncé (phrase, paragraphe, extrait en langage naturel[3]) ou dans une base de données, quand ces mots non-nécessairement liés par des relations formelles ou syntaxiques (syntagmes figés, expressions, collocations), par synonymie, antonymie ou contenance (hyperonymie ou méronymie) possèdent cependant un quelconque lien linguistique.
Pour le géographe ou le biogéographe, la cooccurrence est « le fait que des objets ou des individus qui se ressemblent sont en contacts ou proches. Elle s'oppose à une répartition aléatoire des observations, montrant que l'espace n'est pas isotrope »[4].
Les mots « cooccurrents » ne sont pas nécessairement liés par des relations formelles ou syntaxiques (syntagmes figés, expressions, collocations), par synonymie, antonymie ou contenance (hyperonymie ou méronymie) mais possèdent cependant forcément un quelconque lien linguistique.
Lorsque les deux mots - ou autres unités linguistiques - ont un rapport sémantique proche ou lointain, la notion de cooccurrence est à la base de celle de thématique, champ lexical ou isotopie.
Enjeux, utilisations
Cette notion est utilisée dans des domaines aussi variés que
- la sémantique, mais aussi :
- la linguistique, (étude du phrasé, des corpus linguistiques et lexicaux, instrumentation du discours, codes sociaux dans le discours, etc.)[5] - [6] ;
- l'histoire (co-présence temporelle, spatiotemporelle ou évènementielle[7]) ;
- la géographie (mesure d'autocorrélation spatiale ou spatiotemporelle, de ségrégation sociospatiale[4]...) ;
- le Droit (aide à l'analyse de rigueur ou pertinence de textes juridiques par l'association de termes appropriés[8].) ;
- les mathématiques (graphes de similitude, matrices de cooccurrences, métriques non euclidiennes [9]...) ;
- les statistiques (utilisation du clustering et des probabilités conditionnelles[10]... ;
- sociologie (comportements types, effet de communautés[11]...) ;
- les approches computationnelle (informatique, qui l'utilise par exemple pour la création de thésaurus documentaire[12], l'extraction de mots-clé[13], ou encore pour l'analyse des régularités et associations dans les textes[14] - [15]...) ;
- la philosophie [16].
Détection, analyse textuelle
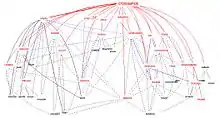
Lorsque les deux mots - ou autres unités linguistiques - ont un rapport sémantique proche ou lointain, la notion de cooccurrence est à la base de celle de thématique, champ lexical ou isotopie.
L'analyse de données textuelles insiste sur les relations statistiques que les deux cooccurrents doivent entretenir, et a proposé de nombreux indices pour calculer pertinemment l'attraction constatée. La cooccurrence devient alors la co-présence statistiquement significative de deux ou plusieurs unités dans la même fenêtre contextuelle.
Des logiciels de détection automatique d'idiomes et autres cooccurrences existent ; ce sont des logiciels de lexicométrie, textométrie, logométrie proposant de nombreuses représentations des cooccurrences dans des corpus textuels étiquetés ou de simples textes (ils extraient les cooccurrences sous forme de listes simples, de graphiques, de réseaux ou networks). Parmi ces logiciels, à titre d'exemple figurent :
Recherche
Des chercheurs tentent de mieux définir ce concept et ses enjeux selon les champs d'application (sciences exactes, humaines et sociales) et son échelle d'appréciation (spatiale, temporelle, abstraite)[18]. Ils cherchent aussi à développer des méthodes pour mieux l'évaluer qualitativement la cooccurrence et mieux la mesurer quantitativement[18].
Exemples de mots cooccurrents
- Élève et professeur
- Port et bateau
- nuit et noire
- Aéroport et avion
Notes et références
- Le terme s'écrit sans trait d'union en français.
- Matthias Tauveron, « De la cooccurrence généralisée à la variation du sens lexical », in La cooccurrence, du fait statistique au fait textuel, (Damon Mayaffre et Jean-Marie Viprey, eds), CORPUS, 11, 2012.
- (en) C. Manning, H. Schütze, Foundations of statistical natural language processing, Cambridge (Mass.), London, MIT Press, 1999.
- Foltête Jean-Christophe, « Reconstitution d’une diffusion spatiale à partir d’une succession d’états », L'espace géographique, 2003/2, tome 32, p. 171–183.
- Anne Salazar-orvig, Les mouvements du discours. Style, référence et dialogue dans des entretiens cliniques, Paris, L’Harmattan, 1999, 294 p.
- (en) Xu, J., & Croft, W. B. (1998) Corpus-based stemming using cooccurrence of word variants. ACM Transactions on Information Systems (TOIS), 16(1), 61-81.
- Veyne Paul, Comment on écrit l'histoire. Essai d'épistémologie Paris, Ed. du Seuil, 1971, 352 pages.
- Pisetta Vincent, Hacid Hakim, Bellal Fazia, Ritschard Gilbert et A. Zighed Djamel (2006) Traitement automatique de textes juridiques, in R. Lehn, M. Harzallah, N. Aussenac-Gilles, J. Charlet (eds), Semaines de la connaissance, SdC 2006, Nantes 26-30 juin (Actes numériques sur Cd-Rom)
- Matthias Tauveron (2012) De la cooccurrence généralisée à la variation du sens lexical, in La cooccurrence, du fait statistique au fait textuel, (Damon Mayaffre et Jean-Marie Viprey, eds), CORPUS, 11, 2012.
- Moalla Koubaa Ikram (2009) Caractérisation des écritures médiévales par des méthodes statistiques basées sur la cooccurrences. Thèse en informatique, INSA de Lyon.
- Moscovici Serge et Henry Paul (1968) Problèmes de l'analyse de contenu (, Langages, socio-linguistique, Vol. 3, no 11, p. 36-60
- Schütze, H., & Pedersen, J. O. (1997) A cooccurrence-based thesaurus and two applications to information retrieval. Information Processing & Management, 33(3), 307-318.
- Matsuo, Y., & Ishizuka, M. (2004). Keyword extraction from a single document using word co-occurrence statistical information. International Journal on Artificial Intelligence Tools, 13(01), 157-169.
- Globerson Amir, Chechik Gal, Pereira fernando, Naftali Tishby (2007) Euclidean Embedding of Co-occurrence Data, Journal of Machine Learning Research 8 (2007), p. 2265-2295 -
- Manning C., Schütze H.(1999) Foundations of statistical natural language processing, Cambridge (Mass.) ; London : MIT Press
- Prévost Marie & Debruille Jacques Bruno (2013) Cooccurrence des croyances religieuses, superstitieuses et de type délirant, Santé mentale au Québec, Volume 38, numéro 1, printemps 2013, p. 279-296.
- « Logiciel Alceste », sur www.image-zafar.com (consulté le )
- Josselin D (2014) Annonce du Séminaire transdiciplinaire “Cooccurrences & co.” (Avignon 5 décembre 2014), publié oct 2014
Voir aussi
Articles connexes
Notions proches
Selon les domaines, cette notion est plus ou moins proche ou liée à des notions proches, dont par exemple
- collocation ;
- coprésence ;
- Coréférence
- corrélation ;
- concomitance...
Bibliographie
- Baayen R.H. (2001). Word frequency distributions. Dordrecht : Kluwer Academic Publishers.
- Bertels A. and Speelman D. (2012) « La contribution des cooccurrences de deuxième ordre à l’analyse sémantique », Corpus 11, p. 147-166.
- Bolasco S. (2013). L'analisi automatica dei testi. Fare ricerca con il text mining. Roma : Carocci.
- É. Brunet (2012). « Nouveau traitement des cooccurrences dans Hyperbase », Corpus, 11, p. 219-248.
- Church K. W. & Hanks P. (1990). « Word Association Norms, Mutual Information, And Lexicography », Computational Linguistics, vol. 16(1), p. 177-210.
- Condamines A. (éd) (2005). Sémantique et corpus. Londres : Hermes
- CORPUS 2 (2003). « La distance intertextuelle » (sous la direction de X Luong).
- Firth J. (1957). « A Synopsis of Linguistic Theory 1930-1955 », Studies in Linguistic Analysis, p. 1-32.
- Fleury S. (2013). Annotations Rhapsodie pour le Trameur [(http://www.tal.univ-paris3.fr/trameur/bases/rhapsodie2trameur.pdf)]
- Halliday M. A. K. and Hasan R. (1976). Cohesion in English. London : Longman.
- Hanneman R. A. and Riddle M. (2005). Introduction to social network methods. Riverside : University of California, Riverside (published in digital form at http://faculty.ucr.edu/~hanneman/).
- Harris Z. S. (1957). « Co-occurrence and transformation in linguistic structure », Language, 33, p. 283-340.
- Heiden S. (2004). « Interface hypertextuelle à un espace de cooccurrences : implémentation dans Weblex », JADT 2004, édité par G. Purnelle, C. Fairon et A. Dister, Louvain : Presses universitaires de Louvain, p. 577-588.
- Heiden S. et Lafon P. (1998). « Cooccurrences. La CFDT de 1973 à 1992 », in Des mots en liberté, Mélanges Maurice Tournier, Paris, ENS Éditions, tome 1, p. 65-83.
- Keller D. B. and Schultz. (2012). « Morpheme networks reveal language dynamics », JADT 2012, édité par A. Dister, D. Longrée, G. Purnelle. Bruxelles : Université de Liège / Facultés Saint-Louis, p. 525-535.
- Lafon P. (1984). Dépouillements et Statistiques en Lexicométrie. Paris : Slatkine-Champion.
- Lafon P. et Tournier M. (1978). « Une Nouvelle approche lexicométrique des cooccurrences dans un texte », Travaux de lexicométrie et de lexicologie politique, 3, p. 135-148.
- Lauf A., Valette M. et Khouas L. (2012). « Analyse du graphe des cooccurrents de deuxième ordre pour la classification non-supervisée de documents », JADT 2012, édité par A. Dister, D. Longrée, G. Purnelle. Bruxelles : Université de Liège / Facultés Saint-Louis, p. 577-589.
- Lebart L. et Salem A. (1994). Statistique textuelle. Paris : Dunod.
- Legallois D. (2012). « La colligation : autre nom de la collocation grammaticale ou autre logique de la relation mutuelle entre syntaxe et sémantique ? », Corpus, 11, p. 31-54.
- Longrée D. et Mellet S. (2013). « Le motif : une unité phraséologique englobante ? Étendre le champ de la phraséologie de la langue au discours », Langages, 189, p. 65-79.
- Luong et al. (2010). « La cooccurrence, une relation asymétrique ? », JADT 2010, édité par S. Bolasco, I. Chiari, L. Giuliano, Milan : Edizioni Universitarie di Lettere Economia Diritto, p. 321-331.
- Martinez W. (2012). « Au-delà de la cooccurrence binaire… Poly-cooccurrences et trames de cooccurrence », Corpus, 11, p. 191-218.
- Martinez W. (2003). Contribution à une méthodologie de l’analyse des cooccurrences lexicales multiples dans les corpus textuels, Thèse de Doctorat, Université de la Sorbonne nouvelle-Paris 3, sous la direction d’A. Salem.
- Mayaffre D. (2008-a). « Quand “travail”, “famille”, “patrie” co-occurrent dans le discours de Nicolas Sarkozy. Étude de cas et réflexion théorique sur la co-occurrence », JADT 2008, édité par S. Heiden et B. Pincemin, Lyon : PUL, vol. 2, p. 811-822.
- Mayaffre D. (2008-b). « De l’occurrence à l’isotopie. Les co-occurrences en lexicométrie », Sémantique & Syntaxe, 9, p. 53-72. [Hal : http://hal.archives-ouvertes.fr/hal-00551114].
- Mayaffre D. (2014). « Plaidoyer en faveur de l’Analyse de Données co(n)Textuelles. Parcours cooccurrentiels dans le discours présidentiel français (1958-2014) », JADT 2014, Proceedings of the 12th International Conference on Textual Data Statistical Analysis, édité par E. Néé, M. Valette, J.-M. Daube et S. Fleury, Paris, Inalco-Sorbonne nouvelle, p. 15-32.
- Mellet S. et Longrée D. (2009). « Syntactical 'Motifs' and Textual Structures », Belgian Journal of Linguistics, 23, p. 161-173.
- Missen M., Boughanem M. et Gaume B. (2008). « The Small World of Web Network Graphs », International Multitopic Conference (IMTIC 2008), Vol. CCIS, Abdul Qadeer et al. (Eds.), Springer, CCIS, p. 133-145.
- Newman M. E. J. (2006). « Modularity and community structure in networks », Proc. Natl. Acad. Sci. USA, vol. 103, no 23, p. 8577–8582.
- Palmer (1933). Second Interim Report on English Collocations. Tokyo : Kaitakusha.
- Ratinaud P. et Marchand P. (2012). « Application de la méthode ALCESTE aux « gros » corpus et stabilité des « mondes lexicaux » : analyse du « CableGate » avec IRAMUTEQ », JADT 2012, édité par A. Dister, D. Longrée, G. Purnelle. Bruxelles : Université de Liège / Facultés Saint-Louis, p. 835-844.
- Reinert M. (1993). « Les "mondes lexicaux" et leur "logique" à travers l’analyse statistique d’un corpus de récits de cauchemars », Langage et société, 66, p. 5-39.
- Salem A. (1987). Pratique des segments répétés. Essai de statistique textuelle. Paris : Klincksieck.
- Sinclair J. M. (1991). Corpus, Concordance, Collocation. Oxford : Oxford University Press.
- Sinclair J. M. (2003). Reading concordances. Londres : Pearson Longman.
- Tauveron M. (2011). « De la cooccurrence généralisée à la variation du sens lexical », Corpus, 12, p. 219-248.
- Tournier M. (1980). « En souvenir de Lagado », Mots, 1, p. 5-9.
- Viprey J.-M. (1997). Dynamique du vocabulaire des Fleurs du mal. Paris : Champion.
- Viprey J.-M. (2006). « Structure non-séquentielle des textes », Langages, 163, p. 71-85.
- Watts D. J. et Strogatz S.H. (1998). « Collective dynamics of ‘small-world’ networks », Nature, 393 (6684), p. 440-442.
- Williams G. (1999). Les réseaux collocationnels dans la construction et l'exploitation d'un corpus dans le cadre d'une communauté de discours scientifique. Thèse de doctorat, Université de Nantes.