Apache Kafka
Apache Kafka est un projet à code source ouvert d'agent de messages développé par l'Apache Software Foundation et écrit en Scala. Le projet vise à fournir un système unifié, en temps réel à latence faible pour la manipulation de flux de données. Sa conception est fortement influencée par les journaux de transactions[3].

| Créateur | Neha Narkhede (en) |
|---|---|
| Développé par | Apache Software Foundation et LinkedIn |
| Première version | [1] |
| Dernière version | 3.5.0 ()[2] |
| Dépôt | github.com/apache/kafka et gitbox.apache.org/repos/asf/kafka.git |
| Écrit en | Java et Scala |
| Système d'exploitation | Multiplateforme |
| Type | Message-oriented middleware |
| Licence | Licence Apache version 2.0 et licence Apache |
| Site web | kafka.apache.org |
Histoire
Apache Kafka a été initialement développé par LinkedIn et son code a été ouvert début 2011[4]. Le projet intègre l'incubateur Apache Incubator le . En , plusieurs ingénieurs créateurs de Kafka chez LinkedIn créent une nouvelle société nommée Confluent[5] avec pour axe le logiciel Kafka.
Applications
Kafka est utilisé principalement pour la mise en place de « data pipeline » temps réel mais ce n'est pas sa seule application possible dans le monde de l'entreprise. Il est aussi de plus en plus utilisé dans les architectures micro services comme système d’échange, dans la supervision temps réel et dans l’IOT[16]. Kafka apporte sa capacité à ingérer et diffuser une grande quantité de données, couplé à un framework de data stream processing, il permet le traitement complexe et en temps réel des données.
Architecture
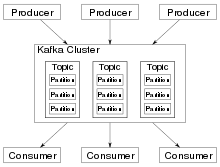
Kafka comprend cinq APIs de base :
- Producer API permet aux applications d'envoyer des flux de données aux topics du cluster Kafka.
- Consumer API permet aux applications de lire des flux de données à partir des topics du cluster Kafka.
- Streams API permet de transformer des flux de données en topic de sortie.
- Connect API permet d'implémenter des connecteurs qui récupèrent les données d'un système source ou d'une application vers Kafka ou qui poussent de Kafka vers une application.
- AdminClient API permet de gérer et d'inspecter les topics, les brokers, et les autres objets Kafka.
Notes et références
- « https://github.com/kafka-dev/kafka/commit/e8540b6b090fad4cbe5bfc9b78be35bc3b1ad2b6 » (consulté le )
- « Release 3.5.0 », (consulté le )
- The Log: What every software engineer should know about real-time data's unifying abstraction, LinkedIn Engineering Blog, accessed 5 May 2014
- (en-US) « Open-sourcing Kafka, LinkedIn's distributed message queue », sur blog.linkedin.com (consulté le )
- Primack, Dan.
- Doyung Yoon.
- Cheolsoo Park and Ashwin Shankar.
- Josh Baer.
- "Stream Processing in Uber".
- "Shopify - Sarama is a Go library for Apache Kafka".
- "Exchange Market Data Streaming with Kafka".
- "Présentation de l'utilisation de Kafka pour gérer les éventements sur le site Meetic"
- https://www.ovh.com/blog/selfheal-at-webhosting-the-external-part/
- https://medium.com/leboncoin-engineering-blog/cooling-down-hot-data-from-kafka-to-athena-5918a628bd98
- https://labs.criteo.com/2019/01/criteo-kafka-meetup-key-learnings/
- « Kafka, pierre angulaire des architectures Fast Data ? », sur Nexworld, (consulté le )
Articles connexes
Liens externes
- (en) Site officiel