Algorithme A*
En informatique, plus précisément en intelligence artificielle, l'algorithme de recherche A* (qui se prononce A étoile, ou A star en anglais) est un algorithme de recherche de chemin dans un graphe entre un nœud initial et un nœud final tous deux donnés[1]. En raison de sa simplicité il est souvent présenté comme exemple typique d'algorithme de planification, domaine de l'intelligence artificielle. L'algorithme A* a été créé pour que la première solution trouvée soit l'une des meilleures, c'est pourquoi il est célèbre dans des applications comme les jeux vidéo privilégiant la vitesse de calcul sur l'exactitude des résultats. Cet algorithme a été proposé pour la première fois par Peter E. Hart, Nils John Nilsson et Bertram Raphael en 1968[2]. Il s'agit d'une extension de l'algorithme de Dijkstra de 1959 (p. 30-31 dans [3]).

| Découvreurs ou inventeurs | |
|---|---|
| Date de publication | |
| Problèmes liés |
Algorithme de recherche, algorithme de recherche de chemin (d), algorithme de la théorie des graphes (d) |
| Structure des données | |
| Basé sur | |
| À l'origine de |
| Pire cas |
|---|

| Pire cas |
|---|

Histoire

En 1968, le chercheur en intelligence artificielle Nils Nilsson essayait d'améliorer la planification de Shakey le robot, un robot prototype qui se déplace dans une pièce avec des obstacles. L'algorithme pour trouver un chemin, que Nilsson appelait A1, était une version plus rapide que la méthode la plus connue à l'époque, l'algorithme de Dijkstra, pour trouver des plus courts chemins dans un graphe. Bertram Raphael a suggéré des améliorations, donnant lieu à la version révisée A2. Puis, Peter E. Hart a apporté des améliorations mineures à A2. Hart, Nilsson et Raphael ont alors montré que A2 est optimal pour trouver des plus courts chemins sous certaines conditions.
Présentation
L'algorithme A* est un algorithme de recherche de chemin dans un graphe entre un nœud initial et un nœud final. Il utilise une évaluation heuristique sur chaque nœud pour estimer le meilleur chemin y passant, et visite ensuite les nœuds par ordre de cette évaluation heuristique. C'est un algorithme simple, ne nécessitant pas de prétraitement, et ne consommant que peu de mémoire.
Intuition
Commençons par un exemple de motivation. On se trouve à l'intersection A et on veut se rendre à l'intersection B dont on sait qu'elle se trouve au nord de notre position actuelle. Pour ce cas classique, le graphe sur lequel l'algorithme va travailler représente la carte, où ses arcs représentent les chemins et ses nœuds les intersections des chemins.
Si on faisait une recherche en largeur comme le réalise l'algorithme de Dijkstra, on rechercherait tous les points dans un rayon circulaire fixe, augmentant graduellement ce cercle pour rechercher des intersections de plus en plus loin de notre point de départ. Ceci pourrait être une stratégie efficace si on ne savait pas où se trouve notre destination, comme la police recherchant un criminel en planque.
Cependant, c'est une perte de temps si on connaît plus d'informations sur notre destination. Une meilleure stratégie est d'explorer à chaque intersection la première directement qui va vers le nord, car le chemin le plus court est la ligne droite. Tant que la route le permet, on continue à avancer en prenant les chemins se rapprochant le plus de l'intersection B. Certainement devra-t-on revenir en arrière de temps en temps, mais sur les cartes typiques c'est une stratégie beaucoup plus rapide. D'ailleurs, souvent cette stratégie trouvera le meilleur itinéraire, comme la recherche en largeur le ferait. C'est l'essence de la recherche de chemin A*.
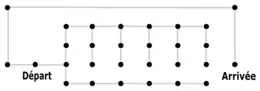
Toutefois, comme pour tous les algorithmes de recherche de chemin, leur efficacité dépend fortement du problème que l'on souhaite résoudre (c'est-à-dire : du graphe). Ainsi l'algorithme A* ne garantit pas de trouver un itinéraire plus rapidement qu'un autre algorithme, et dans un labyrinthe, la seule manière d'atteindre la destination pourrait être à l'opposé de la position de la destination, et les nœuds les plus proches de cette destination pourraient ne pas être sur le chemin le plus court, ce qui peut coûter beaucoup de temps de calcul.
Propriété
Un algorithme de recherche qui garantit de toujours trouver le chemin le plus court à un but s'appelle « algorithme admissible ». Si A* utilise une heuristique qui ne surestime jamais la distance (ou plus généralement le coût) du but, A* peut être avéré admissible. Une heuristique qui rend A* admissible est elle-même appelée « heuristique admissible ».
Si l'évaluation renvoie simplement toujours zéro, qui n'est jamais une surestimation, alors, A* exécutera une implémentation possible de l'algorithme de Dijkstra et trouvera toujours la solution optimale. La meilleure heuristique, bien qu'habituellement impraticable pour calculer, est la distance minimale réelle (ou plus généralement le coût réel) au but. Un exemple d'une heuristique admissible pratique est la distance à vol d'oiseau du but sur la carte.
On peut démontrer que A* ne considère pas plus de nœuds que tous les autres algorithmes admissibles de recherche, à condition que l'algorithme alternatif n'ait pas une évaluation heuristique plus précise. Dans ce cas, A* est l'algorithme informatique le plus efficace garantissant de trouver le chemin le plus court.
Description
A* commence à un nœud choisi. Il applique à ce nœud un « coût » (habituellement zéro pour le nœud initial). A* estime ensuite la distance qui sépare ce nœud du but à atteindre. La somme du coût et de l'évaluation représente le coût heuristique assigné au chemin menant à ce nœud. Le nœud est alors ajouté à une file d'attente prioritaire, couramment appelée open list.
L'algorithme retire le premier nœud de la file d'attente prioritaire (en raison du fonctionnement d'une file d'attente, le nœud à l'heuristique la plus basse est retiré en premier). Si la file d'attente est vide, il n'y a aucun chemin du nœud initial au nœud d'arrivée, ce qui interrompt l'algorithme. Si le nœud retenu est le nœud d'arrivée, A* reconstruit le chemin complet et s'arrête. Pour cette reconstruction on se sert d'une partie des informations sauvegardées dans la liste communément appelée closed list décrite plus bas.
Si le nœud n'est pas le nœud d'arrivée, de nouveaux nœuds sont créés pour tous les nœuds contigus admissibles ; la manière exacte de faire dépend du problème à traiter. Pour chaque nœud successif, A* calcule son coût et le stocke avec le nœud. Ce coût est calculé à partir de la somme du coût de son ancêtre et du coût de l'opération pour atteindre ce nouveau nœud.
L'algorithme maintient également la liste de nœuds qui ont été vérifiés, couramment appelée closed list. Si un nœud nouvellement produit est déjà dans cette liste avec un coût égal ou inférieur, aucune opération n'est faite sur ce nœud ni sur son homologue se trouvant dans la liste.
Après, l'évaluation de la distance du nouveau nœud au nœud d'arrivée est ajoutée au coût pour former l'heuristique du nœud. Ce nœud est alors ajouté à la liste d'attente prioritaire, à moins qu'un nœud identique dans cette liste ne possède déjà une heuristique inférieure ou égale.
Une fois les trois étapes ci-dessus réalisées pour chaque nouveau nœud contigu, le nœud original pris de la file d'attente prioritaire est ajouté à la liste des nœuds vérifiés. Le prochain nœud est alors retiré de la file d'attente prioritaire et le processus recommence.
Les deux structures open list et closed list ne sont pas nécessaires si on peut garantir que le premier chemin produit à n'importe quel nœud est le plus court. Cette situation surgit si l'heuristique est non seulement admissible mais aussi « monotone », signifiant que la différence entre l'heuristique de deux nœuds quelconques reliés ne surestime pas la distance réelle entre ces nœuds. Ce n'est possible que dans de très rares cas.
Pseudo-code
Voici une implémentation possible de l'algorithme, en pseudo-code, pour une recherche de chemin dans une carte qui est un tableau à deux dimensions tel que chaque case contient un état: traversable ou non.
Structure nœud = {
x, y: Nombre
cout, heuristique: Nombre
}
depart = Nœud(x=_, y=_, cout=0, heuristique=0)
Fonction compareParHeuristique(n1:Nœud, n2:Nœud)
si n1.heuristique < n2.heuristique
retourner 1
ou si n1.heuristique == n2.heuristique
retourner 0
sinon
retourner -1
Fonction cheminPlusCourt(g:Graphe, objectif:Nœud, depart:Nœud)
closedLists = File()
openList = FilePrioritaire(comparateur = compareParHeuristique)
openList.ajouter(depart)
tant que openList n'est pas vide
u = openList.defiler()
si u.x == objectif.x et u.y == objectif.y
reconstituerChemin(u)
terminer le programme
pour chaque voisin v de u dans g
si non( v existe dans closedLists
ou v existe dans openList avec un coût inférieur)
v.cout = u.cout +1
v.heuristique = v.cout + distance([v.x, v.y], [objectif.x, objectif.y])
openLists.ajouter(v)
closedLists.ajouter(u)
terminer le programme (avec erreur)
Variantes

WA* (weighted A*) est l'algorithme A* dans lequel l'heuristique h est multipliée par un poids w. L'algorithme est alors généralement plus rapide mais au prix de la garantie. Le poids du chemin trouvé est cependant au plus w multiplié par le poids minimal[4]. Il existe d'autres variantes :

Notes et références
- (en) « Near Optimal Hierarchical Path-Finding »
- (en) P. E. Hart, N. J. Nilsson et B. Raphael, « A Formal Basis for the Heuristic Determination of Minimum Cost Paths », IEEE Transactions on Systems Science and Cybernetics SSC4, vol. 4, no 2, , p. 100–107 (DOI 10.1109/TSSC.1968.300136)
- Steven M. LaValle, Planning Algorithms, (lire en ligne)
- (en) Judea Pearl, Heuristics : Intelligent Search Strategies for Computer Problem Solving, Addison-Wesley, , 382 p. (ISBN 978-0-201-05594-8)
- Ira Pohl « The avoidance of (relative) catastrophe, heuristic competence, genuine dynamic weighting and computational issues in heuristic problem solving » () (lire en ligne)
— « (ibid.) », dans Proceedings of the Third International Joint Conference on Artificial Intelligence (IJCAI-73), vol. 3, California, USA, p. 11–17 - Andreas Köll et Hermann Kaindl « A new approach to dynamic weighting » ()
— « (ibid.) », dans Proceedings of the Tenth European Conference on Artificial Intelligence (ECAI-92), Vienna, Austria, p. 16–17 - Judea Pearl et Jin H. Kim, « Studies in semi-admissible heuristics », IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), vol. 4, no 4, , p. 392–399
- (en) Bjørn Reese, « AlphA*: An ε-admissible heuristic search algorithm », Systematic Software Engineering A/S,
Annexes
Articles connexes
- Any-angle path planning (en) ;
- Jump point search, une optimisation d'A* pour les grilles à coût uniforme, réduisant son temps d'exécution d'un ordre de magnitude ;
- Rapidly-exploring random tree (en).