Very long instruction word
VLIW, initiales de very long instruction word en anglais, traduit littéralement par « mot d'instruction très long », dénote une famille d'ordinateurs dotés d'un processeur à mot d'instruction très long (couramment supérieur à 128 bits).
VLIW est une technologie reportant une partie de la gestion du pipeline d'exécution d'un processeur dans les compilateurs. Cette technologie, semblable à l'EPIC proposée par l'Itanium d'Intel va donc fournir une instruction longue qui sera une agrégation d'instructions courtes indépendantes.
Principe
Sur ces processeurs, chaque instruction peut faire 128, 256 bits de long, voire plus. Sont codées à l'intérieur de ces instructions les opérations à effectuer par les différentes unités de calcul disponibles dans l'unité centrale.
Il est de la responsabilité du compilateur de générer un code qui prend en compte la disponibilité des ressources et ne provoque pas de problèmes matériels lors de son exécution.
Un mot VLIW est parfois appelé un bundle, selon l'architecture. Chaque bundle peut contenir plusieurs instructions. Ces instructions sont positionnées à un certain emplacement du bundle : un slot. En général chaque slot correspond à un type d'instruction, c'est-à-dire que le compilateur ne peut pas affecter une multiplication flottante à un slot dédié aux instructions arithmétiques entières, par exemple.
Exemple
Prenons un exemple de source en assembleur VLIW pour illustrer le problème d'affectation des ressources. Le processeur pour lequel on génère du code n'a que 4 unités : une unité de calcul sur des entiers, une unité flottante, une unité de chargement/rangement (accès mémoire), et une unité de branchement (un mot VLIW ne pourra contenir plus de 4 instructions).
Code source :
… I1 ADD R1, R1, -2 I2 FMUL R2, R1, 10 I3 STORE R3, #100 I4 JE R2, FinCode I5 LOAD R4, R1(4) …
On voit ici une dépendance de type RAW (read after write, lecture après écriture), qui empêche d'exécuter I2 en même temps que I1. En revanche on peut paralléliser I1 et I3, car il n'y a pas de dépendance et parce qu'elles n'utilisent pas les mêmes ressources matérielles (l'unité entière pour I1 et l'unité de chargement pour I3).
Le fait que le processeur ne réorganise pas les données qu'il va exécuter le caractérise comme étant un processeur in-order (dans l'ordre).
Le compilateur a donc la charge d'organiser correctement les instructions parmi les bundles, tout en respectant les types de dépendances habituelles (aléa de donnée, etc.) qui sont normalement gérées au niveau matériel par les architectures classiques (en général via l'algorithme de Tomasulo). On simplifie donc la logique de décodage du processeur donc son nombre de transistors, et libère ainsi des ressources pour augmenter le nombre d'unités et/ou augmenter la fréquence, en contrepartie le compilateur nécessite une complexité importante et l'architecture est difficilement optimisable sans recompilation du code source (les unités supplémentaires ne pouvant être allouées par la logique du processeur si le compilateur ne lui en donne pas explicitement l'ordre).
Outre les instructions classiques (celles qui seront exécutées), le compilateur doit « remplir les slots vides du bundle » pour que chaque mot ait la taille idoine (128, 256, 384 bits). Pour ce faire, il y place des instructions ne faisant rien (NOP, pour no operation), comblant ainsi les emplacements vides.
La faible densité de code résultant de ces instructions très longues peut être compensée par une décompression à la volée du code au moment de son exécution.
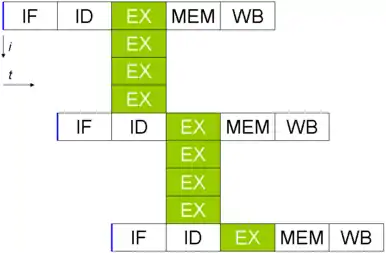
Pipeline interne
Ces architectures dépendent aussi d'un pipeline interne, dont on peut représenter la façon dont sont exécutées les opérations :
Implémentations commerciales
La première machine utilisant cette architecture a été produite par la société Multiflow entre les années 1984 à 1985. Malheureusement seules quelques centaines de machines ont été vendues, et la concurrence des processeurs RISC tua le concept à ce moment-là. Le modèle 7/300 possède des instructions de 256 bits, soit 8 groupes de 32 bits.
Cydrome connut le même sort avec son modèle Cydra-5, à mots de 256 bits codant 6 opcodes de 40 bits.
Plus récemment divers microprocesseurs utilisent les concepts du VLIW, comme le TriMedia de Philips, le Crusoe de Transmeta (128 bits), et même l'Itanium, du fondeur Intel (en fait il s'agit d'une architecture spéciale car les mots machines renseignent le compilateur sur les dépendances inter-instructions, et permettent de procéder à une exécution out-of-order). Les études menées lors de la conception de ces machines ont tout de même laissé un héritage non négligeable dans le domaine de la compilation.
Historique
On peut rapprocher les machines VLIW aux processeurs microprogrammés horizontalement, très en vogue dans les années 1960 - 1970 à travers les mainframes IBM 360 et 370 par exemple.
Notes et références
Annexes
Articles connexes
Lien externe
- Reservoir Labs la société créée par les employés de Multiflow