Union-find
En informatique, union-find est une structure de données qui représente une partition d'un ensemble fini (ou de manière équivalente une relation d'équivalence). Elle a essentiellement deux opérations trouver et unir et est appelée union-find, suivant en cela la terminologie anglo-saxonne :
- Find (trouver) : détermine la classe d'équivalence d'un élément ; elle sert ainsi à déterminer si deux éléments appartiennent à la même classe d'équivalence ;
- Union (unir) : réunit deux classes d'équivalence en une seule.
Une autre opération importante, MakeSet, construit une classe d'équivalence contenant un seul élément, autrement dit un singleton.
Afin de définir ces opérations plus précisément, il faut choisir un moyen de représenter les classes. L'approche traditionnelle consiste à sélectionner un élément particulier de chaque classe, appelé le représentant, pour identifier la classe entière.
Lors d'un appel, Find(x) retourne le représentant de la classe de x.
Implémentation utilisant des listes chaînées
La solution la plus immédiate pour le problème des classes disjointes consiste à construire une liste chaînée pour chaque classe.
On choisit alors l'élément en tête de liste comme représentant.
MakeSet crée une liste contenant un élément. Union concatène les deux listes, une opération en temps constant. Malheureusement, l'opération Find nécessite alors un temps Ω(n) avec cette approche.
On peut y remédier en ajoutant à chaque élément d'une liste chaînée un pointeur vers la tête de la liste ; Find est alors réalisée en temps constant (le représentant étant la tête de la liste). Cependant, on a détérioré l'efficacité de Union, qui doit maintenant parcourir tous les éléments d'une des deux listes pour les faire pointer vers la tête de l'autre liste, ce qui nécessite un temps Ω(n).
On peut améliorer cela en ajoutant toujours la plus petite des deux listes en queue de la plus longue, ce qui porte le nom d'heuristique de l'union pondérée. Cela nécessite de maintenir la longueur des listes au fur et à mesure des opérations. Avec cette solution, une séquence de m opérations MakeSet, Union et Find sur n éléments nécessite un temps O(m + nlog n).
Pour obtenir de meilleurs résultats, nous devons considérer une structure de données différente.
Implémentation utilisant des forêts
On considère maintenant une structure de données dans laquelle chaque classe est représentée par un arbre dans lequel chaque nœud contient une référence vers son nœud père. Une telle structure de forêt a été introduite par Bernard A. Galler et Michael J. Fisher en 1964[1], bien que son analyse détaillée ait attendu plusieurs années.
Principe
Dans une telle forêt, le représentant de chaque classe est la racine de l'arbre correspondant. Find se contente de suivre les liens vers les nœuds pères jusqu'à atteindre la racine. Union réunit deux arbres en attachant la racine de l'un à la racine de l'autre. Une manière d'écrire ces opérations est la suivante :
fonction MakeSet(x)
x.parent := null
fonction Find(x)
si x.parent == null
retourner x
retourner Find(x.parent)
fonction Union(x, y)
xRacine := Find(x)
yRacine := Find(y)
si xRacine yRacine
xRacine.parent := yRacine

Sous cette forme naïve, cette approche n'est pas meilleure que celle des listes chaînées, car les arbres créés peuvent être très déséquilibrés. Mais elle peut être améliorée de deux façons.
Amélioration de l'union
La première consiste à toujours attacher l'arbre le plus petit à la racine de l'arbre le plus grand, plutôt que l'inverse.
Pour évaluer quel arbre est le plus grand, on utilise une heuristique appelée le rang[2] : les arbres contenant un élément sont de rang zéro, et lorsque deux arbres de même rang sont réunis, le résultat a un rang plus grand d'une unité. Avec cette seule amélioration, la complexité amortie des opérations MakeSet, Union et Find devient au pire cas et au meilleur cas.
Voici les nouveaux codes de MakeSet et Union :


fonction MakeSet(x)
x.parent := x
x.rang := 0
fonction Union(x, y)
xRacine := Find(x)
yRacine := Find(y)
si xRacine yRacine
si xRacine.rang < yRacine.rang
xRacine.parent := yRacine
sinon
yRacine.parent := xRacine
si xRacine.rang == yRacine.rang
xRacine.rang := xRacine.rang + 1
Amélioration de find avec la compression de chemin
La seconde amélioration, appelée compression de chemin, consiste à profiter de chaque Find pour aplatir la structure d'arbre ; en effet, chaque nœud rencontré sur le chemin menant à la racine peut être directement relié à celle-ci ; car tous ces nœuds ont le même ancêtre. Pour réaliser cela, on fait un parcours vers la racine, afin de la déterminer, puis un autre parcours pour faire de cette racine la mère de tous les nœuds rencontrés en chemin. L'arbre résultant ainsi aplati améliore les performances des futures recherches d'ancêtre, mais profite aussi aux autres nœuds pointant vers ceux-ci, que ce soit directement ou indirectement. Voici l'opération Find améliorée :
fonction Find(x)
si x.parent x
x.parent := Find(x.parent)
retourner x.parent
Ces deux améliorations (fusion optimisée des racines et compression de chemin) sont complémentaires. Ensemble, elles permettent d'atteindre une complexité amortie en temps , où est la réciproque de la fonction et la fonction d'Ackermann dont la croissance est extrêmement rapide[3]. L'entier vaut moins de 5 pour toute valeur en pratique[4]. En conséquence, la complexité amortie par opération est de fait une constante.





Il n'est pas possible d'obtenir un meilleur résultat : Fredman et Saks ont montré en 1989 que mots en moyenne doivent être lus par opération sur toute structure de données pour le problème des classes disjointes. Dasgupta et al., dans leur livre d'algorithmique, présente une analyse de complexité amortie en utilisant le logarithme itéré[5].

Exemple
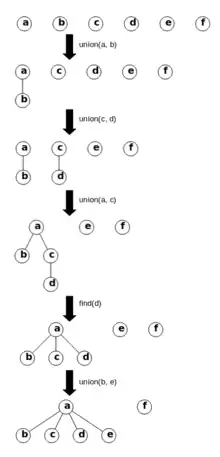
La figure à droite montre un exemple d'utilisation d'une structure de données union-find avec 6 éléments a, b, c, d, e, f. Au début, la forêt contient 6 arbres-racines : elle représente la relation d'équivalence où chaque élément est seul dans sa classe d'équivalence. L'opération union(a, b) connecte (par exemple), le nœud b à la racine a. L'opération union(c, d) connecte (par exemple), le noeud c à la racine d. L'opération union(a, c) connecte (par exemple) le nœud c au nœud a. L'opération find(d) retourne la racine a, mais au passage, il connecte d directement à la racine a (compression de chemins). L'opération union(b, e) commence par chercher les racines respectives a et e. Comme le rang de a est 1 et celui de e est 0, on connecte donc l'arbre e à l'arbre a.
Applications
Cette structure est souvent utilisée pour identifier les composantes connexes d'un graphe (voir l'article sur les algorithmes de connexité basés sur des pointeurs). Dans le même esprit, elle est utilisée pour étudier la percolation, avec l'algorithme de Hoshen-Kopelman.
Union-Find est également utilisée dans l'algorithme de Kruskal, pour trouver un arbre couvrant de poids minimal d'un graphe. Elle est enfin utilisée dans les algorithmes d'unification[7] - [8].
Voir aussi
Articles connexes
- La pile spaghetti, nom donné au type d’arbres mis en œuvre dans la structure union-find.
- L’union de deux ensembles mathématiques.
- La partition d’un ensemble mathématique en sous-ensembles disjoints.
Lien externe
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Disjoint-set_data_structure » (voir la liste des auteurs).
- Bernard A. Galler et Michael J. Fisher, « An improved equivalence algorithm, Communications of the ACM », ACM Digital Library, (consulté le ), Volume 7, Issue 5, pages 301-303.
- On pourrait l'appeler « profondeur », mais en présence de compression de chemin, ce concept perd son sens.
- Robert Endre Tarjan, « Efficiency of a good but not linear set union algorithm. », J. ACM, vol. 22, no 2, , p. 215–225
- (en) Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest et Clifford Stein, Introduction to Algorithms, MIT Press et McGraw-Hill, , 2e éd. [détail de l’édition]. « Chapter 21: Data structures for Disjoint Sets », pp. 498–524.
- Sanjoy Dasgupta, Christos H. Papadimitriou et Umesh Vazirani, Algorithms, McGraw-Hill, Inc., (ISBN 0073523402 et 9780073523408, lire en ligne)
- « Code source pour produire les images. »
- Sylvain Conchon, Jean-Christophe Filliâtre: A persistent union-find data structure. ML 2007: 37-46
- Kevin Knight, « Unification: A Multidisciplinary Survey », ACM Comput. Surv., vol. 21, , p. 93–124 (ISSN 0360-0300, DOI 10.1145/62029.62030, lire en ligne, consulté le )
Sources
- Zvi Galil et Giuseppe F. Italiano, « Data structures and algorithms for disjoint set union problems », ACM Digital Library, (consulté le ), Volume 23, Issue 3, pages 319-344
- J. A. Spirko and A. P. Hickman, « Molecular-dynamics simulations of collisions of Ne with La@C82 », (consulté le ), Phys. Rev. A 57, 3674–3682
- Arthur Charguéraud et François Pottier:, « Verifying the Correctness and Amortized Complexity of a Union-Find Implementation in Separation Logic with Time Credits », J. Autom. Reasoning, vol. 62, no 3, , : 331-365 (lire en ligne)